







 当在Windows系统中输入英文时遇到字母间出现空格的问题,可以通过调整输入法状态来解决。只需将全角模式切换为半角模式,具体步骤为:右键点击任务栏右下角的输入法图标,选择设置,然后将输入状态从全角改为半角,即可恢复正常英文输入。
当在Windows系统中输入英文时遇到字母间出现空格的问题,可以通过调整输入法状态来解决。只需将全角模式切换为半角模式,具体步骤为:右键点击任务栏右下角的输入法图标,选择设置,然后将输入状态从全角改为半角,即可恢复正常英文输入。
平时生活中,偶尔会遇到windows输入法输入英文字母中间有空格
解决方法:将输入法全角修改成半角即可
1.在电脑右下角输入法中英文上,鼠标右键
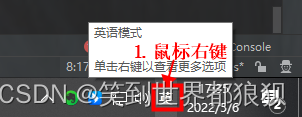
2.右键后会出现如下图所示弹框。将全角修改成半角

经过如上操作后,在输入英文,就变正常了
平时生活中,偶尔会遇到windows输入法输入英文字母中间有空格
解决方法:将输入法全角修改成半角即可
1.在电脑右下角输入法中英文上,鼠标右键
2.右键后会出现如下图所示弹框。将全角修改成半角
经过如上操作后,在输入英文,就变正常了
 1159
3114
4112
1159
3114
4112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























