






 本文介绍了如何检查Linux系统的CPU使用情况,包括核数、利用率及负载平均值,以及如何通过top、iostat等工具分析磁盘IO和网卡带宽的使用状况,以判断系统是否存在性能瓶颈或资源紧张问题。
本文介绍了如何检查Linux系统的CPU使用情况,包括核数、利用率及负载平均值,以及如何通过top、iostat等工具分析磁盘IO和网卡带宽的使用状况,以判断系统是否存在性能瓶颈或资源紧张问题。
我们看待设备性能的时候应该关注哪些指标,或者说我们获取系统参数并不难, 难得是看到这些系统数据你也不知道是这个节点是不是健康的?
1. cpu
1.1 cpu核数(快速查看)
# cpu 核数
xd@xd:~$ cat /proc/cpuinfo| grep "processor"| wc -l
2 # cpu核数
# 快速知道核数的命令 1
xd@xd:~$ sar 1
Linux 4.19.136 (xd) 03/16/2023 _x86_64_ (2 CPU) # cpu核数
04:20:56 PM CPU %user %nice %system %iowait %steal %idle
04:20:57 PM all 52.49 0.00 3.01 0.68 0.00 43.82
# 快速知道核数的命令 2
xd@xd:~$ iostat
Linux 4.19.136 (xd) 03/16/2023 _x86_64_ (2 CPU)
# 快速命令 3
xd@xd:~$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 45 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
.
.
.
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS Not affected
Srbds: Unknown: Dependent on hypervisor status
Tsx async abort: Not affected
1.2 cpu指标(top 完我该看什么)
xd@xd:~$ top
top - 16:24:56 up 262 days, 4:58, 1 user, load average: 73.99, 75.04, 76.95 # 关注点在这里
Tasks: 1074 total, 5 running, 469 sleeping, 0 stopped, 0 zombie
# 关注点是下面的 id 值(如果这个值时常小于5一下认为cpu超载)
# 关注下面的wa值,这个值越大说们等待越多,这个一般给磁盘读写相关
%Cpu(s): 11.9 us, 0.7 sy, 0.0 ni, 87.3 id, 0.1 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 79187104+total, 2936760 free, 55309996+used, 23583430+buff/cache
KiB Swap: 0 total, 0 free, 0 used. 22631310+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
93618 search 20 0 0.372t 0.116t 0.056t S 378.6 15.7 2809:48 qsrchd
1.3 具体某一个cpu的使用率是多少(为了效果明显加大了系统配置)
如果大家的程序不是绑定CPU的,一般很少关注具体的cpu使用率,如果想关注可以使用 htop
xd@xd:~$ htop
1 [|||||||||| 41.5%] 25 [||||||||| 36.9%] 49 [||||||||||| 46.2%] 73 [||||||||||| 44.3%]
2 [|||||||||| 40.6%] 26 [|||||||||| 40.4%] 50 [|||||||||| 41.8%] 74 [||||||||||| 42.2%]
3 [|||||||||||| 50.0%] 27 [||||||||||| 45.8%] 51 [|||||||||| 40.0%] 75 [|||||||||| 40.1%]
4 [||||||||||| 44.3%] 28 [|||||||||||| 50.0%] 52 [||||||||| 36.9%] 76 [|||||||| 31.4%]
5 [|||||||||| 40.4%] 29 [|||||||||| 40.8%] 53 [|||||||||||| 46.1%] 77 [||||||||||| 46.7%]
6 [||||||||||| 45.8%] 30 [||||||||||| 46.2%] 54 [||||||||||| 46.4%] 78 [||||||||||| 44.0%]
7 [|||||||||| 39.4%] 31 [||||||||||| 43.1%] 55 [|||||||||| 40.7%] 79 [|||||||||| 40.1%]
8 [||||||||||| 43.5%] 32 [|||||||||| 42.9%] 56 [|||||||||| 38.9%] 80 [||||||||||| 43.5%]
9 [||||||||| 36.9%] 33 [|||||||||| 39.9%] 57 [|||||||||| 40.5%] 81 [|||||||||| 41.2%]
10 [||||||||||| 43.7%] 34 [||||||||||| 46.7%] 58 [|||||||||| 41.7%] 82 [||||||||||| 43.0%]
11 [||||||||||| 43.7%] 35 [|||||||||| 41.0%] 59 [||||||||||| 43.1%] 83 [|||||||||| 40.7%]
12 [||||||||| 37.6%] 36 [||||||||||| 42.3%] 60 [||||||||||| 46.1%] 84 [||||||||||| 43.5%]
13 [||||||||||||| 52.4%] 37 [||||||||| 34.7%] 61 [||||||||| 36.9%] 85 [||||||||||| 42.8%]
14 [||||||||||| 44.3%] 38 [||||||||||| 45.2%] 62 [|||||||||| 38.5%] 86 [||||||||| 38.5%]
15 [|||||||||| 38.1%] 39 [||||||||||| 45.6%] 63 [|||||||||| 42.0%] 87 [||||||||||| 47.0%]
16 [|||||||||| 42.4%] 40 [|||||||||||| 47.9%] 64 [||||||||||| 43.8%] 88 [||||||||||| 46.4%]
17 [|||||||||| 43.7%] 41 [||||||||||| 45.6%] 65 [||||||||||| 46.1%] 89 [||||||||||| 45.0%]
18 [||||||||| 36.7%] 42 [||||||||| 37.3%] 66 [|||||||||| 41.9%] 90 [||||||||||||| 54.1%]
19 [|||||||||||| 50.6%] 43 [||||||||||| 47.0%] 67 [|||||||||| 39.1%] 91 [||||||||| 35.5%]
20 [|||||||||||| 49.4%] 44 [|||||||||| 40.1%] 68 [||||||||| 37.5%] 92 [|||||||||||| 47.9%]
21 [|||||||||| 42.0%] 45 [|||||||||||| 47.0%] 69 [||||||||||| 44.6%] 93 [|||||||||| 42.5%]
22 [|||||||||| 38.8%] 46 [||||||||||| 43.5%] 70 [||||||||||| 44.8%] 94 [||||||||||| 44.3%]
23 [||||||||||| 42.9%] 47 [|||||||| 34.7%] 71 [||||||||||| 43.1%] 95 [||||||||||||||||100.0%]
24 [||||||||||| 43.7%] 48 [|||||||| 33.1%] 72 [||||||||||| 46.4%] 96 [||||||||||||||||100.0%]
Mem[|||||||||||||||||||||||||||||||||||||||||||548G/755G] Tasks: 239, 7394 thr; 82 running
Swp[ 0K/0K] Load average: 99.78 108.83 113.31
Uptime: 262 days(!), 21:59:09
1.4 cpu最近忙不忙,有多少任务在等着运行
-
CPU 有没有满负荷运行
- cpu的id值越大越闲
- 越接近于100越忙
- 如果是100就是满负荷运行
-
有多少任务等着执行(这里的等待说的是可能是等cpu,io,网络),或者说系统是否已经超负荷运行
- 我们需要关注 load average的值,越大说明等待执行的task越多
-
如果我们的任务不是在等cpu,那它是在等等什么呢?
我们一般用load average / CPU核数 这个值大于1并且cpu的idle 小于1,说明没有task的等待不是在等cpu,这时候需要关注磁盘或者网络
2.磁盘(我的磁盘满了吗,有存储空间为什么写文件不成功)
2.1 磁盘满了吗?
-
磁盘还有空间吗?
xd@xd:~$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda1 300G 76G 225G 26% / devtmpfs 16G 0 16G 0% /dev tmpfs 16G 4.0K 16G 1% /dev/shm tmpfs 16G 857M 15G 6% /run tmpfs 16G 0 16G 0% /sys/fs/cgroup tmpfs 3.2G 0 3.2G 0% /run/user/0 tmpfs 3.2G 0 3.2G 0% /run/user/48758 -
磁盘还有inode吗?
-
如果你有很多小文件,可能是磁盘还有空间但是没有inode了,导致写失败
xd@xd:~$ df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda1 157285872 105860 157180012 1% / devtmpfs 4094794 369 4094425 1% /dev tmpfs 4097478 3 4097475 1% /dev/shm tmpfs 4097478 457 4097021 1% /run tmpfs 4097478 16 4097462 1% /sys/fs/cgroup tmpfs 4097478 1 4097477 1% /run/user/0 tmpfs 4097478 1 4097477 1% /run/user/48758
3. 磁盘IO(有什么依据证明你的磁盘不满足需求)
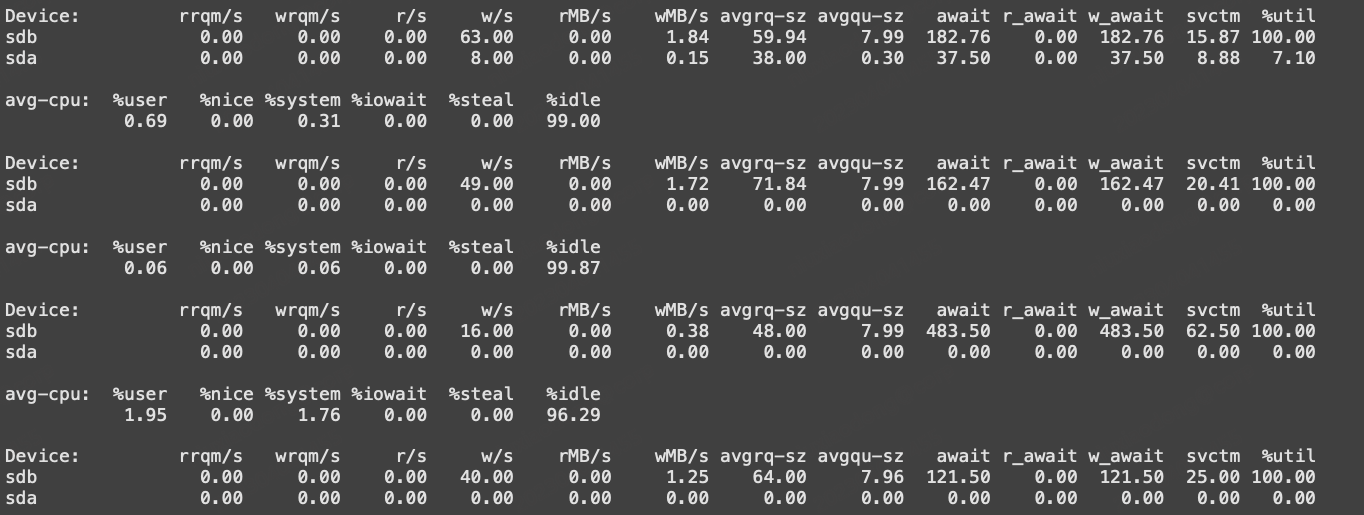
3.1 用iostat查看完磁盘IO以后,通常我门需要关注的数据有哪些,他的指标值处于多少认为节点正常?
xd@xd:~$ iostat -m -x 1
Linux 4.19.136 (xd) 03/16/2023 _x86_64_ (96 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
11.91 0.00 0.74 0.09 0.00 87.26
# 对于磁盘来说这里主要关注 %util 这个值越高说明对应的磁盘IO越忙,达到100%
# 其次关注avgqu-sz 这个值是等待操作这磁盘的对列内有多少个等待任务,这个数越大表示等待的越多
# 有时候还需要关注磁盘的读写速度 MB/每秒(这个显示单位主要是iostat里面参数的 -m在起作用),这次事故的主要元凶就是这个字段的最大值被限制在了5MB,
# 这个值达到5MB的时候 %util 就到了100%
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
nvme0n1 0.00 0.00 33006.00 1.00 275.22 0.00 17.08 3.56 0.11 0.11 0.00 0.02 62.10
nvme1n1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme2n1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme3n1 0.00 0.00 265.00 0.00 2.61 0.00 20.17 0.03 0.09 0.09 0.00 0.04 1.10
sda 0.00 0.00 9.00 5.00 0.09 0.00 12.57 0.00 0.14 0.22 0.00 0.07 0.10
dm-0 0.00 0.00 9.00 5.00 0.09 0.00 12.57 0.00 0.07 0.11 0.00 0.07 0.10
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
3.2 怎么快速知道你的磁盘io上线是多少
方式很多,我们只介绍最简单的方法
# 方法一: stress 这个参数经常容易记不清,可以不记
# 方法二: cp 一个大文件
cp a b
# 这个尽管简单,但是如果这个文件较小,效果不明显,一时间可能不好找一个超过10g的文件
# 方法三: cat 一个超过10M的文件到另外一个文件,如果文件太小需要写好多次缓冲区才写文件可能效果也不明显
while true
do
cat ttt >> t
done
例外:
有时候你看到你读写文件的量并不大,但是从盘的util就到达了100%
这里我遇到这个情况的原因是ceph达到了瓶颈
3.3 如果你已经知道你的磁盘io高了,怎么知道是谁在写磁盘
# 下面这个命令需要root权限
xd@xd:~$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 1003.11 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 127.81 K/s
# 默认以IO高低排序,下面这就是占用io最多的进程
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
23721 be/4 caigou 0.00 B/s 116.19 K/s 0.00 % 0.36 % ./iostress
23777 be/4 yarn 0.00 B/s 886.92 K/s 0.00 % 0.00 % curl http://*****/ws/v1/cluster/apps
13824 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % fh_supervisord -c /usr/local/arkit/1484041341382955011/arkit/supervisord/supervisord.conf
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 21
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
3 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
// io stress demo
package main
import (
"log"
"os"
)
func main() {
for true {
if err := os.WriteFile("file.txt", []byte("Hello GOSAMdddfnsgnsjngsjngsjgnsjkngsjfngsjngjsngsnjsngfsjdnjfjnsfgnsfngjsnsjnsj fsfngsjfnsjfnsfjnsfjbvn sfjbv sjfb sjb s" +
"njfgnskjfgnsjkfbsjfbsjfbnjksfbjksbfjnfjsnjnjfnsnjknfjvsnkPLES!"), 0666); err != nil {
log.Fatal(err)
}
}
}
4. 网卡(我的网卡存在瓶颈吗?上限在哪里)
4.1 网卡带宽是多少
# 先找到网卡名称
xd@xd:~$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.149.140 netmask 255.255.255.0 broadcast 192.168.149.255
inet6 fe80::20c:29ff:fe84:80cb prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:84:80:cb txqueuelen 1000 (Ethernet)
RX packets 970252 bytes 1032686513 (1.0 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 229135 bytes 44136154 (44.1 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 16837486 bytes 1268304181 (1.2 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 16837486 bytes 1268304181 (1.2 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 执行
xd@xd:~$ ethtool ens33
Settings for bond4:
Supported ports: [ ]
Supported link modes: Not reported
Supported pause frame use: No
Supports auto-negotiation: No
Supported FEC modes: Not reported
Advertised link modes: Not reported
Advertised pause frame use: No
Advertised auto-negotiation: No
Advertised FEC modes: Not reported
Speed: 50000Mb/s #带宽
Duplex: Full
Port: Other
PHYAD: 0
Transceiver: internal
Auto-negotiation: off
Cannot get wake-on-lan settings: Operation not permitted
Link detected: yes
4.2 指定网卡上带宽使用量
- 需要注意的是直接执行iftop 显示出来的带宽未必是你所关心网卡的带宽,需要加上 -i 指定网卡名称
xd@xd:~$ iftop -i ens33
interface: ens33
IP address is: 192.168.149.140
MAC address is: 00:0c:29:84:80:cb
12.5Kb 25.0Kb 37.5Kb 50.0Kb 62.5Kb
└─────────────────┴─────────────────┴─────────────────┴─────────────────┴─────────────────
xd => 192.168.149.1 800b 1.35Kb 1.98Kb
<= 160b 352b 480b
xd => _gateway 0b 0b 234b
<= 0b 0b 508b
──────────────────────────────────────────────────────────────────────────────────────────
TX: cum: 4.43KB peak: 5.19Kb rates: 800b 1.35Kb 2.21Kb
RX: 1.93KB 4.43Kb 160b 352b 988b
TOTAL: 6.36KB 8.08Kb 960b 1.69Kb 3.18Kb
# 说明:
# cum : iftop启动到现在的流量汇总
# peak: 峰值速率
#rates: 2s、10s、40s的平均流量

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









