









 本文详细介绍使用JMeter进行压力测试的方法,包括测试环境搭建、测试场景设计及结果分析。同时,深入探讨Java应用程序性能调优技巧,如JVM参数调整、内存泄漏排查及CPU异常分析。
本文详细介绍使用JMeter进行压力测试的方法,包括测试环境搭建、测试场景设计及结果分析。同时,深入探讨Java应用程序性能调优技巧,如JVM参数调整、内存泄漏排查及CPU异常分析。
1.https://jmeter.apache.org 下载压力工具
2.测试工程,放到tomcat启动

3.使用工具
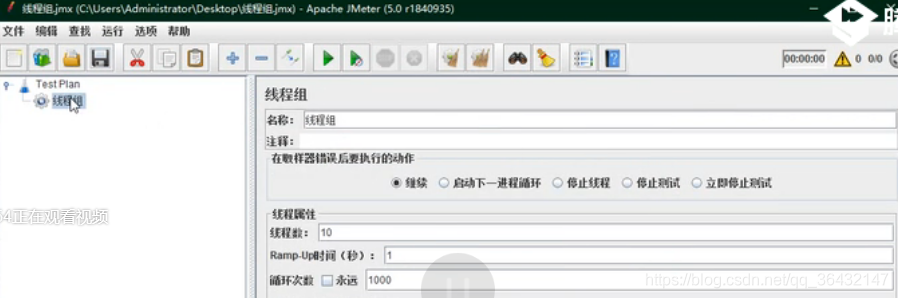
3.1 添加线程组,1S启动10个线程,每个线程访问1000次
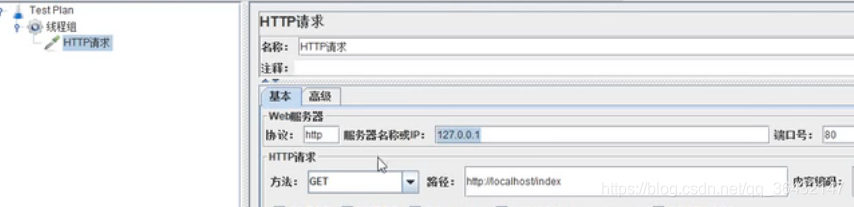
3.2 设置http请求
3.3 设置jvm配置

3.3 设置聚合报告,主要看吞吐量:Throughput


总结:
1.用压力测试工具JMeter,在估计的最大访问流量情况下,反复测试。通过吞吐量和平均响应时间两个参数评估各种gc回收器的选择方案。平均响应时间越短说明gc过程中,暂时时间越短,吞吐量越大,说明gc过程中对应用性能影响越小
2.通过jmap和jstat等实时内存查看工具,分析堆内存的各个模块的使用情况。分析应用中的三种对象:马上死的,死不掉的,不会马上死,又不会存活太久的。根据eden、survivor、old区域中的数量来分析,决定三个区域的大小分配,这些大小分配,又决定gc回收器的选择
3.疑点:


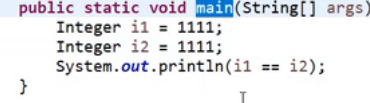
对上面5种整形的,当i1==i2=1,是放到常量池中,i1=i2=128,自动装箱,new Integer(128),是放到堆内存中,所以以下为fasle
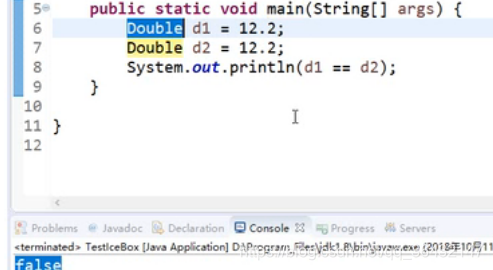
而剩余几种,类似与double,Float是自动装箱,boolean,因为字节数小,一直是放到常量池中,一直为true
四、如何现场分析CPU异常情况
1.linux环境下,用top命令,查看各进程cpu使用情况,例如pid为23344的java进程占用了40%的cpu
2.使用top -Hp 23344查看该进程的各线程的cpu使用情况,例如pid为25077的线程占用了10%的cpu
3.jstack pid(进程):查看该进程下所有线程的堆栈情况(jstack下的是线程数是十六进制,需转换)
情况1、内存泄漏
堆栈情况下出现"VM Thread":指的是垃圾回收的线程,基本可以确定垃圾回收过于频繁,导致gc停顿时间较长。
通过jstat -gcutil 9 1000 10可以看到里面的指标FGC(Full GC),高达6793,且不断增长,证实这一点。然后dump出内存日志,用eclpse的mat工具,查看哪个对象,大量消耗内存
情况二、代码中,比较耗时的计算
jstack得到一个线程具体的堆栈信息,里面指向具体的代码类,再结合top命令查看该线程的cpu有90%,就可以直接定位该代码,是什么原因导致计算量太高
情况三、不定时出现的接口耗时现象:例如一个接口访问经常需要2—3秒返回结果
这种情况,消耗cpu不多,占用的内存不高。一般通过压测工具,增大访问量。如果有一个接口的位置特别耗时,那么大多数线程最终会阻塞于该点,这样通过多个线程的相同堆栈日志,可以定位该接口中,比较耗时的位置
情况四、一个线程进入waiting状态
因为大多数线程都是waiting状态,所以隔10s,导出文件查看,多个文件,找到其中共同的waiting的线程,因为正常线程不会半分钟还会waitting
五、死锁情况
通过jstack很容易发现情况,发现2个线程都在等另一个线程释放锁
五、tomcat运行,查看异常情况
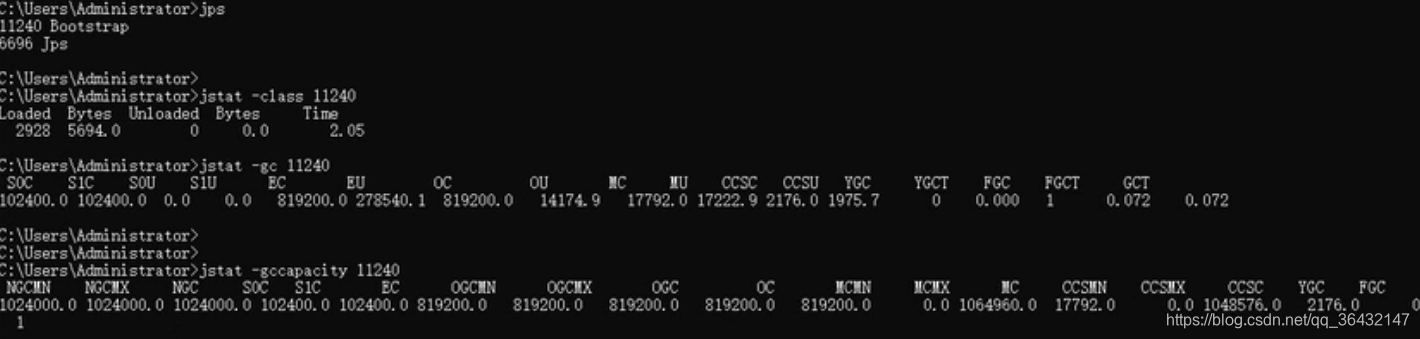
1.在cmd输入jsp,查看当前进程,例如11240
2.使用jstat -class 11240 查看类加载信息
3.jstat -gc 11240 查看gc回收信息
4.jstat -gccapacity 11240 查看堆内存统计
5.jmap-heap 11240:查看堆的情况(例如,新生代,老年代的内存及已使用的比例)
6.jmap -dump:live,format=b,file=d:/bbb.bin 11240:创建了二进制文件,可以用eclipse的插件分析


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









