










 本文介绍使用Scrapy爬取智联招聘Java工程师招聘信息的过程。首先创建Scrapy项目,通过Anaconda Prompt输入代码完成创建,接着在Pycharm中导入项目,在spider下新建spiderexample.py文件,最后在Anaconda Prompt选定项目运行,实现爬取。
本文介绍使用Scrapy爬取智联招聘Java工程师招聘信息的过程。首先创建Scrapy项目,通过Anaconda Prompt输入代码完成创建,接着在Pycharm中导入项目,在spider下新建spiderexample.py文件,最后在Anaconda Prompt选定项目运行,实现爬取。
Scrapy爬取智联招聘java工程师招聘信息
爬取此页面的招聘信息:
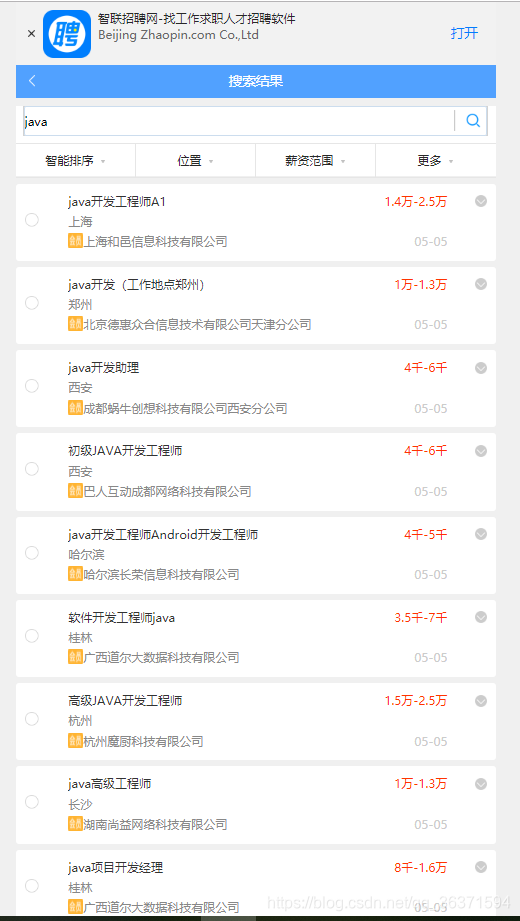
***************************点击此处直达原网页
创建一个scrapy 项目:
打开Anaconda Prompt
输入代码:
scrapy startproject crapyDemo
enter:
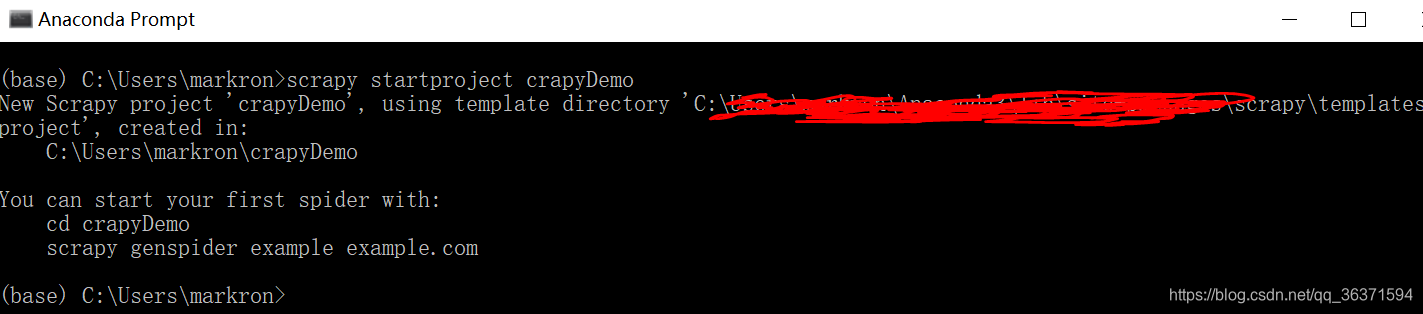
创建成功!
打开Pycharm:
file->open:
找到你创建的crapyDemo的位置,点击OK导入,在spider下新建spiderexample.py文件。
spiderexample.py代码:
import scrapy
class SpiderexampleSpider(scrapy.Spider):
name = 'spiderexample'
start_urls = ['https://m.zhaopin.com/sou/undefined--?keyword=java&provinceCode=undefined&city=undefined']
def parse(self, response):
detailxpath='//div[@class="title-info"]';
items=response.xpath(detailxpath);
for item in items:
job=item.xpath('./div/text()').extract_first();
jobsal=item.xpath('./div[2]/div[1]/text()').extract_first();
if job is not None:
print("职位:"+job+"----工资:"+jobsal)
打开Anaconda Prompt,选定你创建的项目scrapyDemo
cd scrapyDemo
输入:
scrapy srawl scrapydemo
enter,
运行:
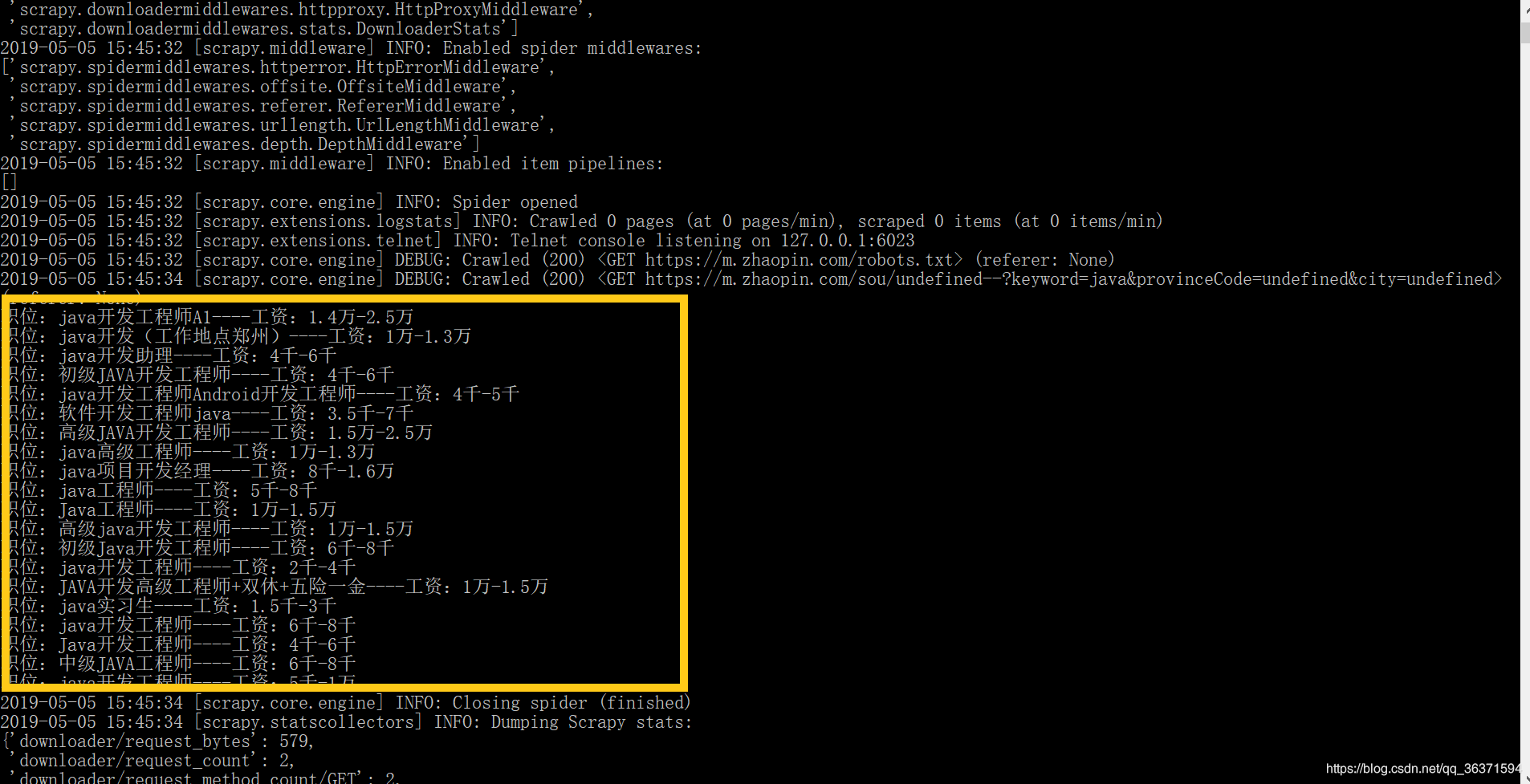
爬取成功。

















 1940
1940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









