




 本文探讨深度卷积神经网络在图像分类任务中的表现,分析了Scattering网络如何通过滤波、非线性及池化操作实现图像的平移不变性和变形不敏感性。进一步研究了不同非线性函数的特性,以及网络深度与特征能量衰减的关系。
本文探讨深度卷积神经网络在图像分类任务中的表现,分析了Scattering网络如何通过滤波、非线性及池化操作实现图像的平移不变性和变形不敏感性。进一步研究了不同非线性函数的特性,以及网络深度与特征能量衰减的关系。
STATS385
Lecture03: Harmonic Analysis of Deep Convolutional Neural Networks
- 深度学习在ImageNet图像分类、image captioning的成绩;
- 图像分类的一般步骤:特征提取+线性分类器。对于线性不可分的数据,需要用非线性特征提取;
- 图像分类的要求:translation invariance, deformation insensitivity;
- Scattering network在设计时就考虑了这两点并将这种机制融入到模型本身中,并没有利用滤波、非线性和pooling的操作(课件有问题?)。其结构如下图所示
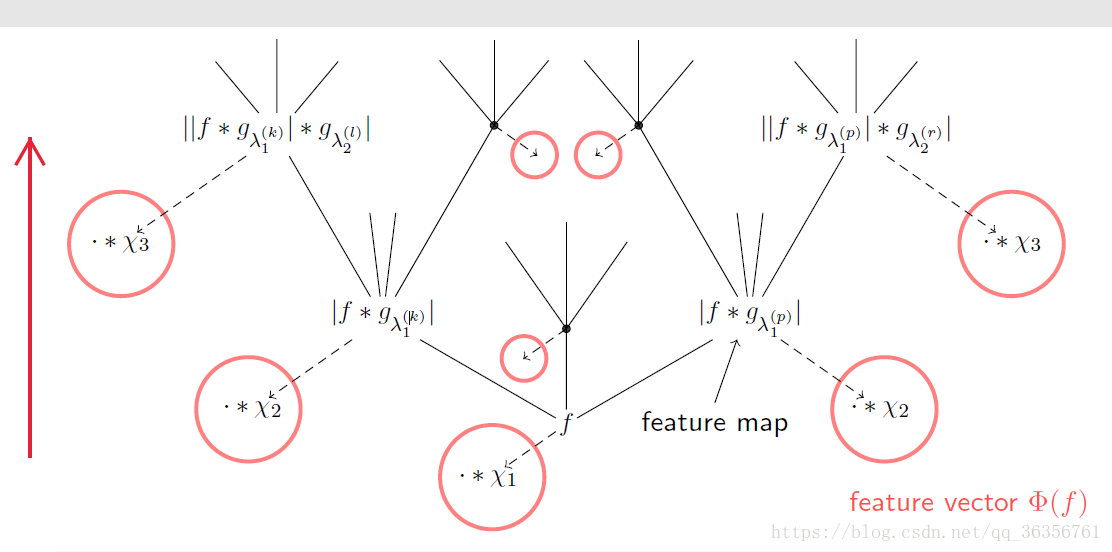
f f 代表输入图像。该模型自底向上传播,在每一个节点都扩散到若干个子节点。每一个节点都进行一个卷积-求模(绝对值)-卷积操作。抽象出来就是滤波-非线性-pooling,如下图所示
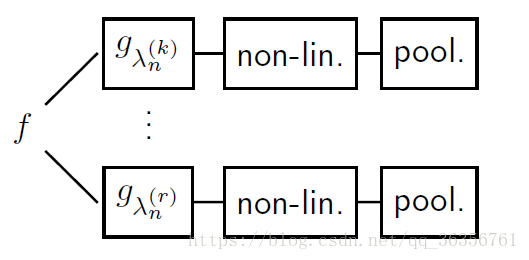
这样,每个节点的输出再与 χn χ n 进行卷积,就得到了相应层的feature。
由Parseval定理知,这些滤波器满足
∃An,Bn>0,s.t.An∥f∥22≤∥f∗χn∥22+∑λn∈Λn∥f∗gλn∥22≤Bn∥f∥22 ∃ A n , B n > 0 , s . t . A n ‖ f ‖ 2 2 ≤ ‖ f ∗ χ n ‖ 2 2 + ∑ λ n ∈ Λ n ‖ f ∗ g λ n ‖ 2 2 ≤ B n ‖ f ‖ 2 2
而这些point-wise非线性函数应满足Lipschitz-continuous条件,即
∥Mn(f)−Mn(h)∥2≤Ln∥f−h∥,∀f,h∈L2(Rd) ‖ M n ( f ) − M n ( h ) ‖ 2 ≤ L n ‖ f − h ‖ , ∀ f , h ∈ L 2 ( R d )
而该条件是能被现如今几乎所有被应用在深度学习中的非线性函数所满足的,如对于ReLU, Ln=1 L n = 1 ,对于sigmoid, Ln=14 L n = 1 4 (易证)
对于pooling层而言,满足
f↦Sd/2nPn(f)(Sn⋅) f ↦ S n d / 2 P n ( f ) ( S n ⋅ )
即先对图像 f f 进行 Pn P n 变换,然后对变换后的图像坐标进行尺度为 Sn S n 的伸缩,最后乘上一个系数,其中pooling factor Sn≥1,Pn:L2(Rd)→L2(Rd) S n ≥ 1 , P n : L 2 ( R d ) → L 2 ( R d ) 是 Rn R n -Lipschitz连续的。无独有偶,该条件也能被大部分现行的深度网络中的pooling层满足,如降采样层满足 Pn(f)=f,Rn=1 P n ( f ) = f , R n = 1 ,max pooling层满足 Pn(f)=f∗ϕn,Rn=∥ϕn∥1,ϕn=ones() P n ( f ) = f ∗ ϕ n , R n = ‖ ϕ n ‖ 1 , ϕ n = o n e s ( )
关于垂直平移不变性有如下定理
Theorem T h e o r e m 假设滤波器、非线性函数和pooling层满足 Bn≤min{1,L−2nR−2n},Sn≥1,∀n∈N B n ≤ min { 1 , L n − 2 R n − 2 } , S n ≥ 1 , ∀ n ∈ N ,则 ∥Φn(Ttf)−Φn(f)∥=O(∥t∥∏1≤i≤nSi)∀f∈L2(Rd),t∈Rd,n∈N ‖ Φ n ( T t f ) − Φ n ( f ) ‖ = O ( ‖ t ‖ ∏ 1 ≤ i ≤ n S i ) ∀ f ∈ L 2 ( R d ) , t ∈ R d , n ∈ N
即越是深层的pooling层,其特征受到垂直平移算子 Tt T t 的影响就越小,这就从理论上保证了scattering network对输入的垂直平移不变性。而该定理的前提条件也很容易满足,只要对滤波器进行归一化就行了。另外水平平移不变性也有类似的定理。
非线性变换/算子: Fτf=f(x−τ(x)),τ∈Rd→Rd F τ f = f ( x − τ ( x ) ) , τ ∈ R d → R d 。对于给定的非线性变换,变形的程度与函数 f f 有很大的关系
变形稳定性边界
∥ΦW(Fτf)−ΦW(f)∥≤C(2−J∥τ∥∞+J∥Dτ∥∞+∥D2τ∥∞)∥f∥W,∀f∈HW⊂L2(Rd) ‖ Φ W ( F τ f ) − Φ W ( f ) ‖ ≤ C ( 2 − J ‖ τ ‖ ∞ + J ‖ D τ ‖ ∞ + ‖ D 2 τ ‖ ∞ ) ‖ f ‖ W , ∀ f ∈ H W ⊂ L 2 ( R d ) ,其中 W W 是小波。该式表明,对于小的形变,图像的特征不会有较大的变化。 - CNN
非线性函数为求模函数的卷积层具有解调效应
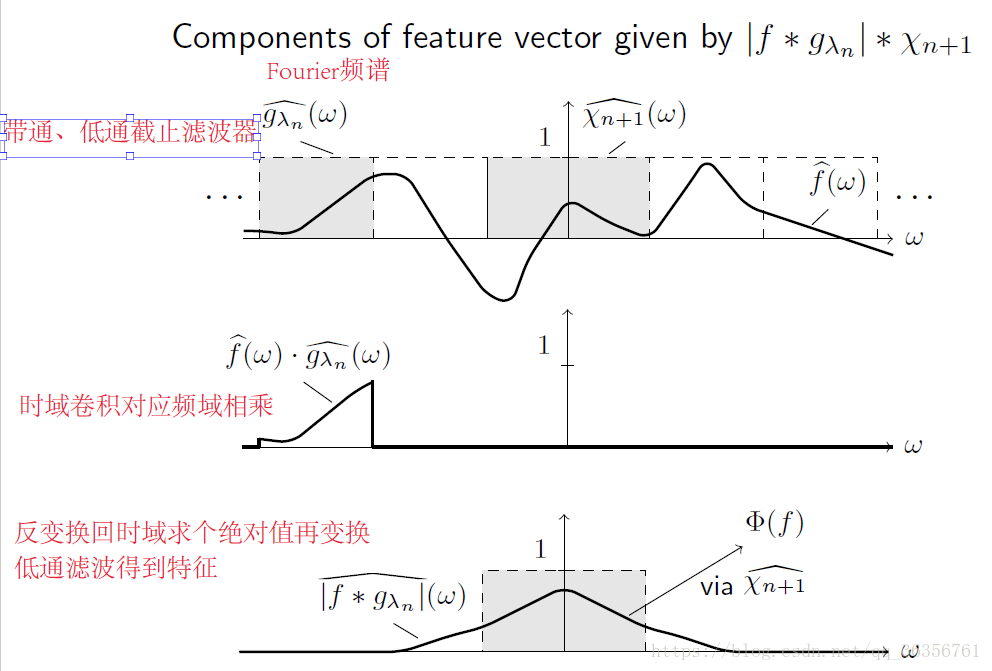
那所有的非线性函数都有解调功能吗?对于求模函数当然如此;对于模平方函数则更是如此,而且它的高频抑制更强,但是该函数不是Lipschitz连续的;而对于ReLU函数则不是。
接下来我们重点讨论以下4个问题:
1、Determine how fast the energy contained in the propagated signals (a.k.a. feature maps) decays across layers.
首先对滤波器进行一些假设:1、滤波器是解析的,即 ∃Rd ∃ R d 的一个超卦限(不必正则) Hλn H λ n 使得 supp(gλnˆ)⊂Hλn s u p p ( g λ n ^ ) ⊂ H λ n ;2、滤波器是高通的。这两个条件包含了大部分的WH(Weyl-Heisenberg)滤波器、小波等
再介绍一个概念—— s s 阶Sobolev函数:
Hs(Rd)={f∈L2(Rd)|∫Rd(1+|ω|2)s|f^(ω)|2dω<∞},s≥0 H s ( R d ) = { f ∈ L 2 ( R d ) | ∫ R d ( 1 + | ω | 2 ) s | f ^ ( ω ) | 2 d ω < ∞ } , s ≥ 0 。大部分信号都符合该条件。
这样就能得到对于小波滤波器和WH滤波器,每一层特征的能量随着模型深度指数衰减的定理,并且信号越光滑、pooling层降采样率越大,特征的能量衰减越快。而对于一般的滤波器,则为多项式衰减。
2、Guarantee trivial null-space for feature extractor Φ Φ
Φ Φ 具有简单零空间指 Φ(x)=0⇔x=0 Φ ( x ) = 0 ⇔ x = 0 。否则后续的线性分类器将在其非零零点处不可分。
为了满足该条件, Φ Φ 应该满足 ∃A,B>0,s.t.A∥f∥22≤∥Φ(f)∥22≤B∥f∥22 ∃ A , B > 0 , s . t . A ‖ f ‖ 2 2 ≤ ‖ Φ ( f ) ‖ 2 2 ≤ B ‖ f ‖ 2 2
“能量守恒”:所有层信号特征的能量是和信号本身的能量同级别的( Θ(⋅) Θ ( ⋅ ) )。由此也可以得到1中特征能量对深度衰减到0的结论。
3、Specify the number of layers needed to have “most” of the input signal energy be contained in the feature vector
定理表明,为了在一定程度上保持所有层特征的能量,模型的深度不能小于某个阈值。同时这也保证了每一层的 Φ Φ 的简单零空间性质,因为后面加上去的每一层都是有能量的,这样就避免特征函数在非零处取零的情况。
由于一般的滤波器的特征能量是多项式级别衰减的,所以为了保持相同的信号能量,由一般的滤波器构成的模型需要的深度比小波或WH滤波器的大。回忆ResNet152,对于小波和WH滤波器而言,只需要11层和14层就够了。
4、For a fi xed (possibly small) depth, design CNNs that capture “most” of the input signal energy
定理表明,要想降低模型的深度,必须增加第一层特征的channel数,这是depth-width之间的一种trade-off。
最后,作者还给出了在MNIST上的测试结果,结果表明求模运算和ReLU比tanh和logsig性能要好,而且加pooling层的效果和不加pooling效果相当,但是显著降低了计算量。但是最近的模型都在往有方向、不可分小波、去pooling和更高的计算复杂度的趋势发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









