







MySQL排序查询和分组查询
排序查询
语法:
select 查询列表
from 表名
【where 筛选条件】
order by 排序的字段或表达式;
order by 特点:
1、asc代表的是升序,默认就是升序,所以可以省略,desc代表的是降序
2、order by子句可以支持 单个字段、别名、表达式、函数、多个字段
3、order by子句在查询语句的最后面,除了limit子句
以下表举例说明:
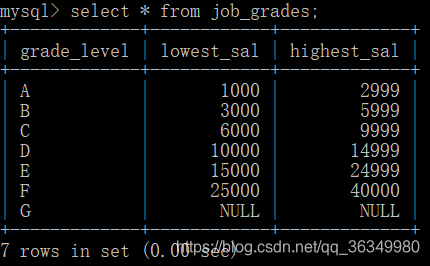
1.单个字段排序
按最低工资升序排序,默认就是asc升序,所以可以省略。
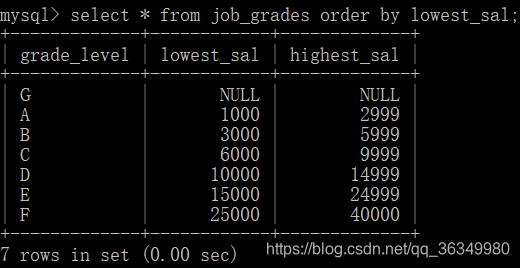
按最低工资降序排序:
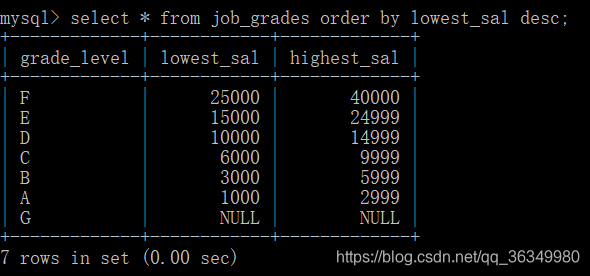
2.多个字段排序
按最低工资升序排序,最高工资降序排序:
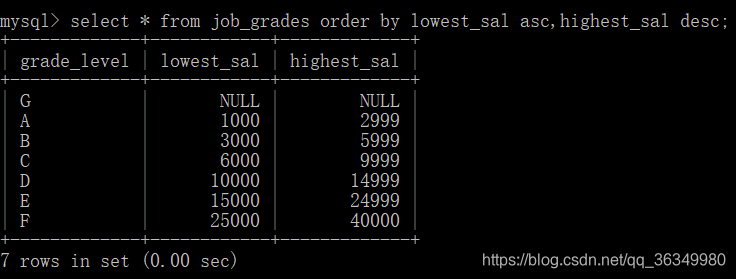
意思为先按最低工资升序排序,如果最低工资一样,就按最高工资的降序排序,因为这里最低工资没有一样的,所以结果显示不明显。
3.别名
给lowest_sal起了”最低工资"的别名,然后用别名进行降序排序。
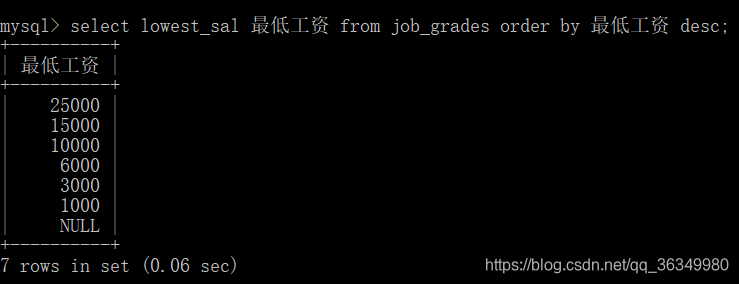
4.表达式排序
将最低工资乘以2后进行降序排序
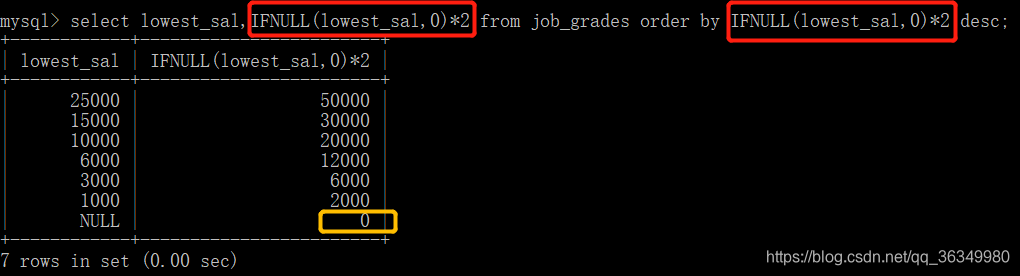
因为该表中lowest_sal和highest_sal都有null值,如果直接将上述红框改成lowest_sal*2,会发现黄框的结果为NULL,因为在MySQL中,NULL对任意数值进行加减乘除都是为NULL的,所以为了避免这种情况就调用了IFNULL()函数。
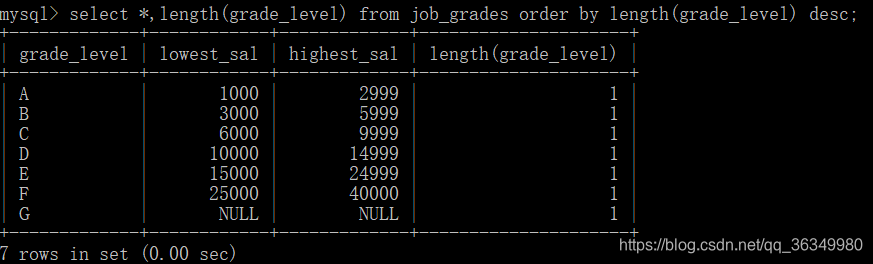
5.函数排序
按grade_level的长度降序排序
这里只是为了演示order by是支持函数排序的,对于结果无需太过关注。。。因为长度都是1,所以其实此排序是没有意义的(其实是懒)
分组查询
语法:
select 查询列表
from 表
【where 筛选条件】
group by 分组的字段
【order by 排序的字段】;
特点:
1、和聚合函数一同查询的字段必须是group by后出现的字段
2、筛选分为两类:分组前筛选和分组后筛选
3、分组可以按单个字段也可以按多个字段
4、可以搭配着排序(order by)使用
| 筛选类型 | 针对的表 | 位置 | 连接的关键字 |
|---|---|---|---|
| 分组前筛选 | 原始表 | group by 前 | where |
| 分组后筛选 | group by后的结果集 | group by 后 | having |
以下表举例说明:
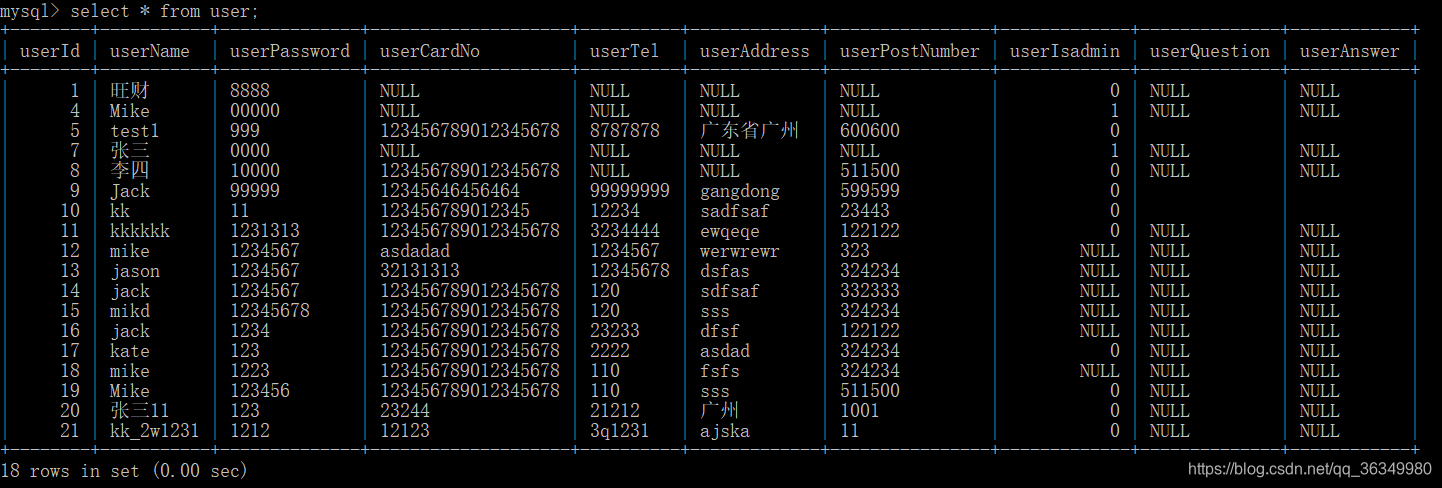
1.查询每个userIsadmind的个数(单个字段分组)。
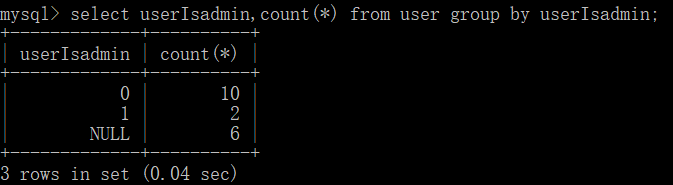
这里应证了特点1,和聚合函数count(*)一同查询的字段必须是group by后出现的字段,即userIsadmin。
其实可以写上其他字段,如下举例所示
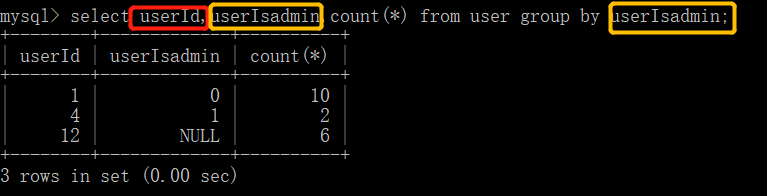
这里没有报错,但是,这样的数据是没有任何意义的。因为我是对每个userIsadmin计算个数,而查询的userId没有任何意义。所以我们应遵照特点1去写语句。
2.查询userPostNumber不为空的每个userIsadmin的个数(分组前筛选)

对于不好理解的同学,大家可以了解一下MySQL解析SQL语句的过程,这样有助于理解MySQL语句
MySQL语句解析过程:
from–>on–>join–>where–>group by–>聚合函数–>having–>select–>distinct–>order by–>limit
从上面可以理解上述语句:先找到user表,然后解析userPostNumber不为空的值拿出来,然后对userIsadmin进行分组,然后通过聚合函数计算count(*),然后在查询出userIsadmin的值。就得到上述结果。
3.查询userPostNumber不为空的每个userIsadmin的个数小于8(分组后筛选)

这里看过MySQL语句解析过程后再理解这句语句其实也是很简单了。。。
顺便 也说一下把,其实可以先不看having count(*) <8这句,直接运行having前面的语句就会出现结果集,再此结果集上再次进行条件筛选就是having 的作用了。
4.多字段排序意味着group by后面的字段一样的为一组,任意一个不一样都不行。
例如group by 字段1,字段2; 那(字段1,字段2)两个字段对应都一样的为一组。注意理解,
不是字段1=字段2的为一组。
这里就不演示了,因为该表不好弄。。。。
至于后面可以跟order by排序也不演示了,就是分组后再排序显示。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









