







 本文介绍了统计指标函数的应用,包括如何获取最大值和最小值的位置、计算平均值、中位数及方差等。同时,还解释了在不同维度(如列和行)上进行计算的方法。
本文介绍了统计指标函数的应用,包括如何获取最大值和最小值的位置、计算平均值、中位数及方差等。同时,还解释了在不同维度(如列和行)上进行计算的方法。
统计指标函数
返回最大值和最小值所在位置
平均值,中位数,方差

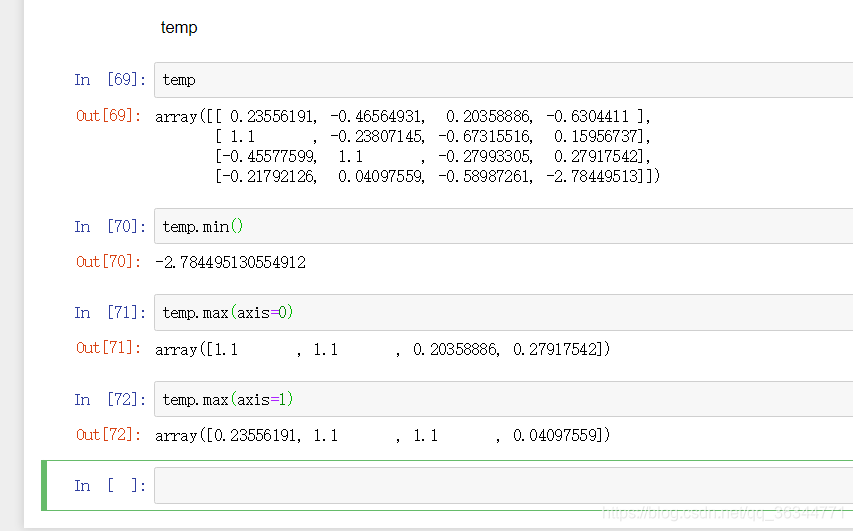
axis=0是按列
axis=1是按行
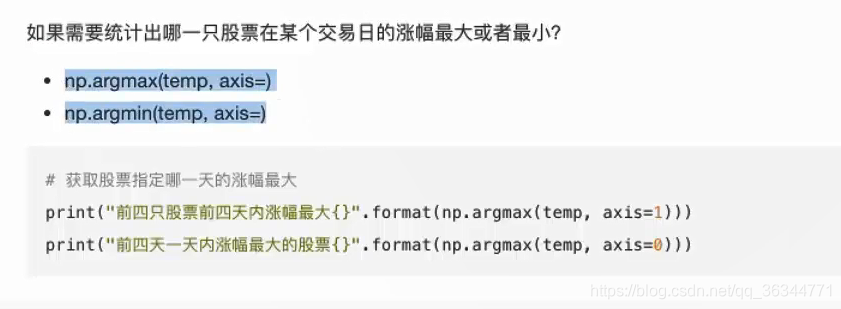
最大值和最小值的位置

















 1898
1898
评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包

 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






