









文章目录
01 Gpy的简介与安装
相关资料推荐:
- Gpy官方文档:https://pytorch-geometric.readthedocs.io/en/latest/index.html
- GDL Blogs:https://geometricdeeplearning.com/blogs/
- colab教程:
- 介绍:https://colab.research.google.com/drive/1h3-vJGRVloF5zStxL5I0rSy4ZUPNsjy8?usp=sharing
- 节点分类:https://colab.research.google.com/drive/14OvFnAXggxB8vM4e8vSURUp1TaKnovzX#scrollTo=dszt2RUHE7lW
- 图分类:https://colab.research.google.com/drive/1I8a0DfQ3fI7Njc62__mVXUlcAleUclnb
- 缩放图神经网络:https://colab.research.google.com/drive/1XAjcjRHrSR_ypCk_feIWFbcBKyT4Lirs#scrollTo=KDy46FIQ6OWN
1.0 PyG *(PyTorch Geometric)*简介
PyG *(PyTorch Geometric)*是一个建立在 PyTorch上的库,便于写和训练在结构化数据中具有广泛应用的图神经网络(Graph Neural Networks, GNNs)。
在图上或者其他不规则结构上的深度学习有多种方法,在大量论文中也被称为几何深度学习(geometric deep learning, http://geometricdeeplearning.com/)。另外,它包括容易使用的小批次加载器:
- 用于操作很多小的且单一的巨大图
- 支持多GPU(https://github.com/pyg-team/pytorch_geometric/tree/master/examples/multi_gpu)
- 数据流(https://github.com/pyg-team/pytorch_geometric/blob/master/examples/datapipe.py)
- 基于Quiver(https://github.com/pyg-team/pytorch_geometric/tree/master/examples/quiver)的分布式图学习
- 大量常用的基准测试数据集(基于简单的接口你可以创建你自己数据集)
- 使用GraphGym(https://pytorch-geometric.readthedocs.io/en/latest/notes/graphgym.html)的实验管理器
- 有用的转化(对学习任意图形以及三维网格或者点云都有帮助)。
1.2 安装
查看CUDA的版本:
nvidia-smi ##gpu17和gpu18上的版本均为11.2.
输出为:
nvcc: NVIDIA ® Cuda compiler driver
Copyright © 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
使用Anaconda来安装PyG。如果你已经有PyTorch>=1.8.0安装了,只需要运行:
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=10.2 -c pytorch
##conda create -n pyg pyg -c pyg
pip3 install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0%2Bcu102.html
pip3 install torch-sparse -f https://pytorch-geometric.com/whl/torch-1.11.0%2Bcu102.html
pip3 install torch-cluster -f https://pytorch-geometric.com/whl/torch-1.11.0%2Bcu102.html
pip3 install torch-spline-conv -f https://pytorch-geometric.com/whl/torch-1.11.0%2Bcu102.html
pip3 install torch-geometric
**直接conda conda create -n pyg pyg -c pyg 可能出现的报错:**OSError: …/torch_sparse/_version_cuda.so: undefined symbol: _ZN5torch3jit17parseSchemaOrNameERKSs
解决办法参考:
- https://colab.research.google.com/drive/1h3-vJGRVloF5zStxL5I0rSy4ZUPNsjy8?usp=sharing#scrollTo=zF5bw3m9UrMy
- 中文教程:https://blog.youkuaiyun.com/qq_40329272/article/details/111801695
- 如何安装pytorch_geometric库【粉丝3k多】: https://yunxingluoyun.blog.youkuaiyun.com/article/details/109731397
# Install required packages.
import os
import torch
os.environ['TORCH'] = torch.__version__
print(torch.__version__) ##1.10.2
##pip中,-q表示quiet, -f解析连接找到.tar.gz或者.whl文件。
##参考链接:https://data.pyg.org/whl/torch-1.12.0%2Bcu113.html
os.system("pip install -q torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}.html") ##链接有点不一样了。
os.system("pip install -q torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}.html")
os.system("pip install -q git+https://github.com/pyg-team/pytorch_geometric.git")
**报错:**OSError: libcudart.so.10.2: cannot open shared object file: No such file or directory
在.bashrc文件中,最后加上想要加的路径。
export PATH=/share/apps/CUDA/cuda-11.0/bin:$PATH
export LD_LIBRARY_PATH=/share/apps/CUDA/cuda-11.0/lib64:$LD_LIBRARY_PATH
02. 基于案例的介绍
我们将通过独立的示例简短地介绍PyG的基本概念。PyG的核心功能如下:
- Data Handling of Graphs
- Common Benchmark Datasets
- Mini-batches
- Data Transforms
- Learning Methods on Graphs
- Exercises
2.1 图上的数据处理
图被用于对象(nodes)之间成对关系(edge)建模。PyG中简单的图可以通过 torch_geometric.data.Data实例化,该函数默认获取如下属性:
data.x: 形状为[num_nodes, num_node_features]的节点特征矩阵。data.edge_index: 形状为[2, num_edges]且类型为torch.long坐标形式的图连接。data.edge_attr: 形状为[num_edges, num_edge_features]的边特征矩阵。data.y: 训练的目标,形状为[num_nodes, *]的节点水平的目标或者形状为[1, *]的图水平的目标。data.pos: 形状为[num_nodes, num_dimensions]节点位置矩阵。
这些性状都不是必须的。实际上,Data对象甚至不限制这些属性。我们可以用data.face来拓展它,用形状为 [3, num_faces] 且类型为 torch.long的张量来保存来自3D网格的三角形连接性。
注意:
PyTorch和
torchvision定义了图片和目标的元组作为案例。我们在PyG中省略了这个说明,因为其可以用一种干净的可以理解的方式用于各种数据结构。
我们展示了一个包括3个节点、4条边的无向图和有向图的案例。每个节点恰好包括一个特征:
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)

注意edge_index, 该张量定义了所有边的起始节点和终止节点, 而不是索引元组的列表。如果你想要的通过这种方式写你的索引,你可以在将它们传递给数据构建器前,将其转置并且调用contiguous函数。
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1],
[1, 0],
[1, 2],
[2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index.t().contiguous())
尽管这个图只有两条边,但是我们需要制定四个索引元组来说明每条边的正向和方向。
注意: 任何时候你都可以打印你的数据对象,并且接收关于其属性和形状的短信息。
除了接收一些节点水平、边水平或图水平的属性,Data还提供了一些有用的函数,例如:
print(data.keys) ##查看data中包括哪些数据类型。
>>> ['x', 'edge_index']
print(data['x']) ##获取节点属性矩阵。
>>> tensor([[-1.0],
[0.0],
[1.0]])
for key, item in data:
print(f'{key} found in data') ##遍历data类型中的key和value.
>>> x found in data
>>> edge_index found in data
'edge_attr' in data ##判断数据中是否含有某个属性。
>>> False
data.num_nodes
>>> 3
data.num_edges
>>> 4
data.num_node_features
>>> 1
data.has_isolated_nodes()
>>> False
data.has_self_loops()
>>> False
data.is_directed()
>>> False
# Transfer data object to GPU.
device = torch.device('cuda')
data = data.to(device)
你可以再 torch_geometric.data.Data中找到所有方法的完整列表。
2.2 常用的benchmark数据集
PyG包含了大量常见的基准测试数据集,例如:
- all Planetoid datasets (Cora, Citeseer, Pubmed):参考https://blog.youkuaiyun.com/qq_32797059/article/details/106577815
- Cora: 由机器学习论文组成,论文被分为七类。每一篇论文都引用或者被至少一篇其他论文引用。
- Citeseer:从CiteSeer数字论文图书馆中选取的一部分论文。
- Pubmed:包括来自Pubmed数据库的19717篇关于糖尿病的科学出版物。
- all graph classification datasets from http://graphkernels.cs.tu-dortmund.de and their cleaned versions
- TUDataset数据集包括来自各种应用程序的120多个不同大小的数据集组成。
- the QM7 and QM9 dataset
- QM7数据集:
- QM9数据集:
- and a handful of 3D mesh/point cloud datasets like FAUST, ModelNet10/40 and ShapeNet
- FAUST:包含10个不同人物的300个高分辨率非水密网格。其中每个人包含30个不同姿态下的扫描。参考:https://zhuanlan.zhihu.com/p/452437241
- ModelNet10/40:一个3d图像分类的一个数据集,它里面的图像全部都是CAD手工绘制的点云图像。参考:https://blog.youkuaiyun.com/weixin_47142735/article/details/120223827
- ShapeNet:https://blog.youkuaiyun.com/weixin_47142735/article/details/120697897
初始化一个数据集是非常直接的。初始化一个数据集会自动下载它的原始文件,然后将它们处理为前面描述的Data格式。例如,加载ENZYMES数据集(包括6种类型的600个图),需要输入:
from torch_geometric.datasets import TUDataset
##Downloading https://www.chrsmrrs.com/graphkerneldatasets/ENZYMES.zip
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')
>>> ENZYMES(600)
len(dataset)
>>> 600
dataset.num_classes
>>> 6
dataset.num_node_features
>>> 3
我们现在能够获取数据集中所有600个图:
data = dataset[0]
>>> Data(edge_index=[2, 168], x=[37, 3], y=[1])
data.is_undirected()
>>> True
我们可以看到数据集中的第一个图包括37个节点,每个节点有3个特征。有168/2 = 84条无向边,这个图被分为第一种类型。另外,该数据对象能够接收图水平的目标。
我们能够使用slices, long or bool张量来划分数据集,例如创建一个90/10的训练集和测试集划分,如下所示:
train_dataset = dataset[:540]
>>> ENZYMES(540)
test_dataset = dataset[540:]
>>> ENZYMES(60)
如果你不确定数据集在你划分之前是否已经打乱了,你可以通过运行如下代码来随机置换该数据集:
dataset = dataset.shuffle()
>>> ENZYMES(600)
这等同于进行:
perm = torch.randperm(len(dataset))
dataset = dataset[perm]
>> ENZYMES(600)
让我们尝试另外一个数据集。让我们来下载Cora, 一个用于半监督图节点分类的基准测试数据集。
报错:http.client.RemoteDisconnected: Remote end closed connection without response
解决办法:https://blog.youkuaiyun.com/PolarisRisingWar/article/details/116399648
数据集相关的代码位于:
ll ~/tools/miniconda3/envs/pyg/lib/python3.9/site-packages/torch_geometric/datasets修改:把planetoid.py里面第48行的 url = ‘https://github.com/kimiyoung/planetoid/raw/master/data’ 改成 url=‘https://gitee.com/jiajiewu/planetoid/raw/master/data’
from torch_geometric.datasets import Planetoid
##Downloading https://github.com/kimiyoung/planetoid/raw/master/data/ind.cora.x
dataset = Planetoid(root='/tmp/Cora', name='Cora')
>>> Cora()
len(dataset)
>>> 1
dataset.num_classes
>>> 7
dataset.num_node_features
>>> 1433
这个数据集只包含单个无向的论文引用图:
data = dataset[0]
>>> Data(edge_index=[2, 10556], test_mask=[2708],
train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
data.is_undirected()
>>> True
data.train_mask.sum().item()
>>> 140
data.val_mask.sum().item()
>>> 500
data.test_mask.sum().item()
>>> 1000
这一次Data对象包含每个节点的标签,以及额外的节点水平的属性:train_mask, val_mask和test_mask。其中:
- train_mask:定义了用于训练的节点(140个节点)。
- val_mask:定义了哪些节点用于验证,例如进行早期停止(500个节点)。
- test_mask:定义哪些节点用于测试(1000个节点)。
2.3 Mini-batches(最小批次)
神经网络通常以分批的方式进行训练。PyG通过创建稀疏块对角邻接矩阵(由edge_index定义)并在节点维度上连接特征矩阵和目标矩阵来实现小批处理的并行化。这种组合允许在一个批处理中有不同数量的节点和边:
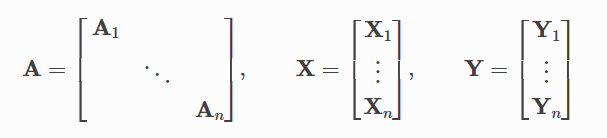
PyG包含一个torch_genometric.loader.DataLoader, 其能够完成这个串联过程。让我们通过一个例子来学习它:
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader:
batch
>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
batch.num_graphs
>>> 32
torch_geometric.data.Batch 继承自 torch_geometric.data.Data,包含了一个名为 batch的额外属性.
batch是一个列向量,其对应着批次中各个图的每个节点。
b
a
t
c
h
=
[
0
⋯
0
1
⋯
n
−
2
n
−
1
⋯
n
−
1
]
⊤
\mathrm{batch} = {\begin{bmatrix} 0 & \cdots & 0 & 1 & \cdots & n - 2 & n -1 & \cdots & n - 1 \end{bmatrix}}^{\top}
batch=[0⋯01⋯n−2n−1⋯n−1]⊤
你可以使用它来平均每个图中节点维度的节点特征:
from torch_scatter import scatter_mean
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for data in loader:
data
>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
data.num_graphs
>>> 32
x = scatter_mean(data.x, data.batch, dim=0)
x.size()
>>> torch.Size([32, 21])
你可以学到更多PyG的内部批次步骤,例如,如何改变它的行为,参考https://pytorch-geometric.readthedocs.io/en/latest/notes/batching.html。对于散布操作的文档,感兴趣的话可以看torch-scatter的文档:https://pytorch-scatter.readthedocs.io/
2.4 数据转化(Data Transforms)
在torchvision中,变换是一种常用的对图像进行变换和增强的方法。PyG自带转换,这些转换需要一个Data对象作为输入,并返回一个新的转换后的Data对象。可以使用torch_geometric.transforms.Compose将转换链接在一起, 可在将处理过的数据集保存到磁盘(pre_transform)之前或在访问数据集中的图(transform)之前应用。
让我们看一个案例,我们对ShapNet数据集应用转化。该数据集包括17,000个3D形状点云,每个点的标签来自16个形状类型。
- 斯坦福大学ShapeNet数据集:https://blog.youkuaiyun.com/weixin_47142735/article/details/120697897
- ShpaeNet是点云中一个比较常见的数据集,它能够完成部件分割任务,即部件知道这个点云数据大的分割,还要将它的小部件进行分割。它总共包括十六个大的类别,每个大的类别有可以分成若干个小类别(例如,飞机可以分成机翼,身体等小类别),总共有五十个小类别。
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'])
dataset[0]
>>> Data(pos=[2518, 3], y=[2518])
我们可以通过变换从点云生成最近邻图,将点云数据集转换为图数据集:
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6))
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
**注意:**在将数据保存到磁盘之前,我们使用
pre_transform对数据进行转换(从而加快加载时间)。请注意,下一次数据集初始化时,它将已经包含图边,即使您没有通过任何转换。如果pre_transform与已经处理过的数据集中的不匹配,将会给出一个警告。
此外,我们可以使用transform参数随机增加一个Data对象,例如,将每个节点位置转换为一个小数字:
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6),
transform=T.RandomTranslate(0.01))
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
最新版本中是torch_geometric.transforms.RandomJitter, torch-geometric==2.0.4版本中,使用的属性是:torch_geometric.transforms.RandomTranslate。
2.5 在图上训练和评估模型
已经学习了PyG中的数据处理、数据集、加载器和数据转化,是时候来实现我们的第一个图神经网络了。
我们将使用简单的图神经网络层,来复现Cora引用数据集上的实验。关于图神经网络的更多解释,可参考相关博客:http://tkipf.github.io/graph-convolutional-networks/
首先加载Cora数据集:
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
>>> Cora()
注意,我们不需要使用转化或者数据加载器。让我们用一个两层的GCN来实现。
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
##https://pytorch-geometric.readthedocs.io/en/latest/_modules/torch_geometric/graphgym/models/layer.html#GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16) ##输入层的维数是节点特征数目,输出层维数是16。
self.conv2 = GCNConv(16, dataset.num_classes) ##输入层维数是16, 输出层维数是论文的7个类别。
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index) ##输入为每个batch的节点特征矩阵和边(节点-节点关联)的信息。
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index) ##这一步输入时,节点的特征只剩下16个。
return F.log_softmax(x, dim=1) ##最后返回7个论文分类特征。
构造函数定义了两个GCNConv层,在网络的前向传递中调用它们。注意,非线性在conv调用中没有集成,因此需要在之后应用(PyG中的所有操作符都是一致的)。在这里,我们选择使用ReLU作为中间非线性,并最终输出关于类数量的softmax分布。让我们在训练节点上训练这个模型200个epoch:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
最后,我们在训练数据集上评估我们的模型:
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
>>> Accuracy: 0.8150
这就是实现第一个图神经网络所需的全部内容。了解更多关于图神经网络(Graph Neural Networks)的最简单的方法是研究examples/目录中的示例,并浏览torch_geometry.nn。黑客快乐!
**实际运行报错:**OSError: /lib64/libm.so.6: version `GLIBC_2.27’ not found (required by …python3.9/site-packages/torch_spline_conv/_basis_cuda.so)
错误说明:https://github.com/pyg-team/pytorch_geometric/issues/3593
解决办法:
pip uninstall torch-spline-conv
最终结果与官方教程一致。

反思:
-
Cora数据集有何特点?参考:https://blog.youkuaiyun.com/yeziand01/article/details/93374216
from torch_geometric.datasets import Planetoid dataset = Planetoid(root='/tmp/Cora', name='Cora') print(dataset) >>>Cora() print(dataset[0]) >>>Data(x=[2708, 1433], ##该数据集共包括2708个节点,每个节点包括1433个节点特征。 edge_index=[2, 10556], ##共包括10556条边。 y=[2708], ##节点层次的目标。 train_mask=[2708], ##用于训练的节点。 val_mask=[2708], ##用于验证的节点。 test_mask=[2708]) ##用于测试的节点。 ##在python环境下测试 >>> data = dataset[0] >>> print(data.x) tensor([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) >>> print(data.edge_index) tensor([[ 0, 0, 0, ..., 2707, 2707, 2707], [ 633, 1862, 2582, ..., 598, 1473, 2706]]) >>> print(data.y) tensor([3, 4, 4, ..., 3, 3, 3]) >>> print(data.train_mask) tensor([ True, True, True, ..., False, False, False]) >>> print(data.val_mask) tensor([False, False, False, ..., False, False, False]) >>> print(data.test_mask) tensor([False, False, False, ..., True, True, True]) ### >>> data.train_mask.sum().item() ##用于训练的节点有140个。 140 >>> data.val_mask.sum().item() ##用于验证的节点有500个。 500 >>> data.test_mask.sum().item() ##用于测试的节点有1000个。 1000 -
图神经网络要达到什么目的呢?
- 预测论文的分类(即预测节点的分类)。
-
上述代码,为什么能够实现该目的?
- 主要参考:https://pytorch-geometric.readthedocs.io/en/latest/_modules/torch_geometric/graphgym/models/layer.html#GCNConv
2.6 练习
-
What does
edge_index.t().contiguous()do?**解答:**参考pytorch中对张量操作的解释https://pytorch.org/tutorials/beginner/basics/tensorqs_tutorial.html。
import torch from torch_geometric.data import Data edge_index = torch.tensor([[0, 1], [1, 0], [1, 2], [2, 1]], dtype=torch.long) x = torch.tensor([[-1], [0], [1]], dtype=torch.float) data = Data(x=x, edge_index=edge_index.t().contiguous()) ##python >>> print(edge_index) tensor([[0, 1], [1, 0], [1, 2], [2, 1]]) >>> print(edge_index.t()) ##t的作用是张量转置。 tensor([[0, 1, 1, 2], [1, 0, 2, 1]]) >>> print(edge_index.t().contiguous()) ##contiguous tensor([[0, 1, 1, 2], [1, 0, 2, 1]]) ##When you call contiguous(), it actually makes a copy of the tensor such that the order of its elements in memory is the same as if it had been created from scratch with the same data. -
Load the
"IMDB-BINARY"dataset from theTUDatasetbenchmark suite and randomly split it into 80%/10%/10% training, validation and test graphs.]解答:
>>> from torch_geometric.datasets import TUDataset >>> dataset = TUDataset(root='/share/inspurStorage/home1/jialh/01tutorial/01python/02pyg/datasets/IMDB-BINARY', name='IMDB-BINARY') Downloading https://www.chrsmrrs.com/graphkerneldatasets/IMDB-BINARY.zip Extracting /share/inspurStorage/home1/jialh/01tutorial/01python/02pyg/datasets/IMDB-BINARY/IMDB-BINARY/IMDB-BINARY.zip Processing... Done! >>> print(dataset) IMDB-BINARY(1000) ###探索数据集的相关性质。 >>> data = dataset[0] >>> print(data) Data(edge_index=[2, 126], y=[1], num_nodes=15) >>> print(data.edge_index) tensor([[ 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 7, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 12, 12, 12, 12, 12, 12, 12, 12, 13, 13, 13, 13, 13, 13, 13, 13, 14, 14, 14, 14, 14, 14, 14], [ 1, 2, 5, 6, 10, 11, 14, 0, 2, 5, 6, 10, 11, 14, 0, 1, 5, 6, 10, 11, 14, 4, 5, 7, 8, 9, 11, 12, 13, 3, 5, 7, 8, 9, 11, 12, 13, 0, 1, 2, 3, 4, 6, 7, 8, 9, 10, 11, 12, 13, 14, 0, 1, 2, 5, 10, 11, 14, 3, 4, 5, 8, 9, 11, 12, 13, 3, 4, 5, 7, 9, 11, 12, 13, 3, 4, 5, 7, 8, 11, 12, 13, 0, 1, 2, 5, 6, 11, 14, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 13, 14, 3, 4, 5, 7, 8, 9, 11, 13, 3, 4, 5, 7, 8, 9, 11, 12, 0, 1, 2, 5, 6, 10, 11]]) >>> print(data.y) tensor([0]) >>> print(data.num_nodes) 15 ##划分训练集、验证集和测试集。 >>> dataset = dataset.shuffle() >>> train_dataset = dataset[0:800] >>> val_dataset = dataset[800:900] >>> test_dataset = dataset[900:] >>> print(train_dataset) IMDB-BINARY(800) -
What does each number of the following output mean?
解答:
torch_geometric.data.Batch继承自torch_geometric.data.Data, 包含一个称为batch的额外属性。参考:https://pytorch-geometric.readthedocs.io/en/2.0.4/_modules/torch_geometric/loader/dataloader.html#DataLoader
把图数据进行了拼接,最终32个图数据,拼接成一个拥有总1082个节点,21维度的特征,4066个边的图batch 数据(https://blog.youkuaiyun.com/u012211422/article/details/125212863)。
print(batch) >>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32]) ##enzyme数据集的基本信息为:Data(edge_index=[2, 168], x=[37, 21], y=[1]) >>> from torch_geometric.datasets import TUDataset >>> from torch_geometric.loader import DataLoader >>> >>> dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True) >>> loader = DataLoader(dataset, batch_size=32, shuffle=True) >>> print(dataset) ENZYMES(600) >>> dataset.num_classes 6 ##该数据集的图总共包括6个类别。 >>> dataset.num_node_features 21 ##每一个节点有21个特征 >>> data = dataset[0] >>> data Data(edge_index=[2, 168], x=[37, 21], y=[1]) ###第一张图有168条有向边,37个节点,每个节点3个特征,整张图有一个类别 >>> data.is_undirected() True ##batch的操作展示 >>> for batch in loader: ... print(batch,batch.num_graphs) ... ''' DataBatch(edge_index=[2, 4350], x=[1169, 21], y=[32], batch=[1169], ptr=[33]) 32 DataBatch(edge_index=[2, 3630], x=[937, 21], y=[32], batch=[937], ptr=[33]) 32 DataBatch(edge_index=[2, 3958], x=[1016, 21], y=[32], batch=[1016], ptr=[33]) 32 DataBatch(edge_index=[2, 3620], x=[947, 21], y=[32], batch=[947], ptr=[33]) 32 DataBatch(edge_index=[2, 3864], x=[1116, 21], y=[32], batch=[1116], ptr=[33]) 32 DataBatch(edge_index=[2, 4570], x=[1184, 21], y=[32], batch=[1184], ptr=[33]) 32 DataBatch(edge_index=[2, 4326], x=[1111, 21], y=[32], batch=[1111], ptr=[33]) 32 DataBatch(edge_index=[2, 3710], x=[934, 21], y=[32], batch=[934], ptr=[33]) 32 DataBatch(edge_index=[2, 3708], x=[957, 21], y=[32], batch=[957], ptr=[33]) 32 DataBatch(edge_index=[2, 3814], x=[1010, 21], y=[32], batch=[1010], ptr=[33]) 32 DataBatch(edge_index=[2, 4102], x=[1056, 21], y=[32], batch=[1056], ptr=[33]) 32 DataBatch(edge_index=[2, 4242], x=[1060, 21], y=[32], batch=[1060], ptr=[33]) 32 DataBatch(edge_index=[2, 3988], x=[1021, 21], y=[32], batch=[1021], ptr=[33]) 32 DataBatch(edge_index=[2, 4232], x=[1089, 21], y=[32], batch=[1089], ptr=[33]) 32 DataBatch(edge_index=[2, 3622], x=[941, 21], y=[32], batch=[941], ptr=[33]) 32 DataBatch(edge_index=[2, 3942], x=[1083, 21], y=[32], batch=[1083], ptr=[33]) 32 DataBatch(edge_index=[2, 3810], x=[1008, 21], y=[32], batch=[1008], ptr=[33]) 32 DataBatch(edge_index=[2, 4190], x=[1162, 21], y=[32], batch=[1162], ptr=[33]) 32 DataBatch(edge_index=[2, 2886], x=[779, 21], y=[24], batch=[779], ptr=[25]) 24 ''' ##说明:不同的batch中,都是用32个图作为输入。包含的总结点数目batch有所不同。

















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









