






 本文详细介绍了科大讯飞MSC Android版SDK的集成步骤,包括导入SDK、添加用户权限、初始化等关键环节,并附有真机运行照片。解决程序崩溃、初始化失败等问题。
本文详细介绍了科大讯飞MSC Android版SDK的集成步骤,包括导入SDK、添加用户权限、初始化等关键环节,并附有真机运行照片。解决程序崩溃、初始化失败等问题。
科大讯飞移动语音终端SDK(Mobile Speech Client, MSC)的整合流程对于Android开发者来说,是一个将科大讯飞提供的语音识别与合成技术集成到Android应用中的过程。以下是根据科大讯飞官方文档及参考文章整理的完整流程和示例代码。
完整流程
1. 注册与申请
- 前往科大讯飞官网(http://www.xfyun.cn/)进行注册并登录。
- 在控制台中创建应用,获取AppID。此AppID是后续SDK初始化及API调用时必需的。
2. 下载SDK
- 在科大讯飞官网下载适用于Android的语音SDK。
- 解压SDK,并准备将相关文件集成到Android项目中。
3. 集成SDK到Android项目
- 复制文件:将SDK中的
libs目录下的所有子文件复制到Android项目的libs目录下(如果项目中没有libs文件夹,则新建)。 - 配置JNI库:在项目
module/src/main/下新建jniLibs文件夹,将SDK中存放.so文件的文件夹(注意文件名开头大写)复制过去。 - 复制资源文件:将SDK中的
assets文件夹下的文件复制到项目的对应assets文件夹下。
4. 添加权限
在Android项目的AndroidManifest.xml文件中添加必要的权限,如网络访问、录音、相机等。以下是一些常用的权限:
xml复制代码
<uses-permission android:name="android.permission.INTERNET"/> | |
<uses-permission android:name="android.permission.RECORD_AUDIO"/> | |
<uses-permission android:name="android.permission.CAMERA"/> | |
<uses-permission android:name="android.permission.READ_PHONE_STATE"/> | |
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/> | |
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/> | |
<uses-permission android:name="android.permission.CHANGE_NETWORK_STATE"/> | |
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/> | |
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/> | |
<uses-permission android:name="android.permission.WRITE_SETTINGS"/> | |
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION"/> |
5. 初始化SDK
在应用的入口(如Application或Activity的onCreate方法)中初始化SDK。替换SpeechConstant.APPID+"=你的AppID"中的你的AppID为实际申请的AppID。
java复制代码
SpeechUtility.createUtility(context, SpeechConstant.APPID + "=你的AppID"); |
6. 使用SDK进行语音识别或语音合成
根据SDK提供的API,编写代码实现语音识别或语音合成的功能。以下是一个简单的语音识别示例代码片段:
java复制代码
import com.iflytek.cloud.SpeechConstant; | |
import com.iflytek.cloud.SpeechError; | |
import com.iflytek.cloud.SpeechRecognizer; | |
import com.iflytek.cloud.RecognizerListener; | |
import com.iflytek.cloud.RecognizerResult; | |
// 创建语音识别对象 | |
SpeechRecognizer mSpeechRecognizer = SpeechRecognizer.createRecognizer(this, null); | |
// 设置参数 | |
mSpeechRecognizer.setParameter(SpeechConstant.DOMAIN, "iat"); | |
mSpeechRecognizer.setParameter(SpeechConstant.LANGUAGE, "zh_cn"); | |
mSpeechRecognizer.setParameter(SpeechConstant.ACCENT, "mandarin"); | |
// 设置监听器 | |
mSpeechRecognizer.setRecognizerListener(new RecognizerListener() { | |
@Override | |
public void onResult(RecognizerResult results, boolean isLast) { | |
// 处理识别结果 | |
} | |
@Override | |
public void onError(SpeechError error) { | |
// 处理错误 | |
} | |
// 其他回调方法根据需要实现 | |
}); | |
// 开始识别 | |
mSpeechRecognizer.startListening(null); |
注意事项
- 确保在开发过程中参考科大讯飞官方文档,因为SDK的具体实现细节可能会随版本更新而有所变化。
- 在部署应用前,请确保处理好所有必要的用户隐私和权限问题。
- 对于语音识别和语音合成的结果,根据应用场景进行适当的处理和优化。
以上流程和示例代码提供了一个基本的框架,具体实现时可能需要根据项目需求进行调整。
参考官方文档:预备工作-科大讯飞MSC开发指南-Android
下面附上demo运行在真机上的照片:

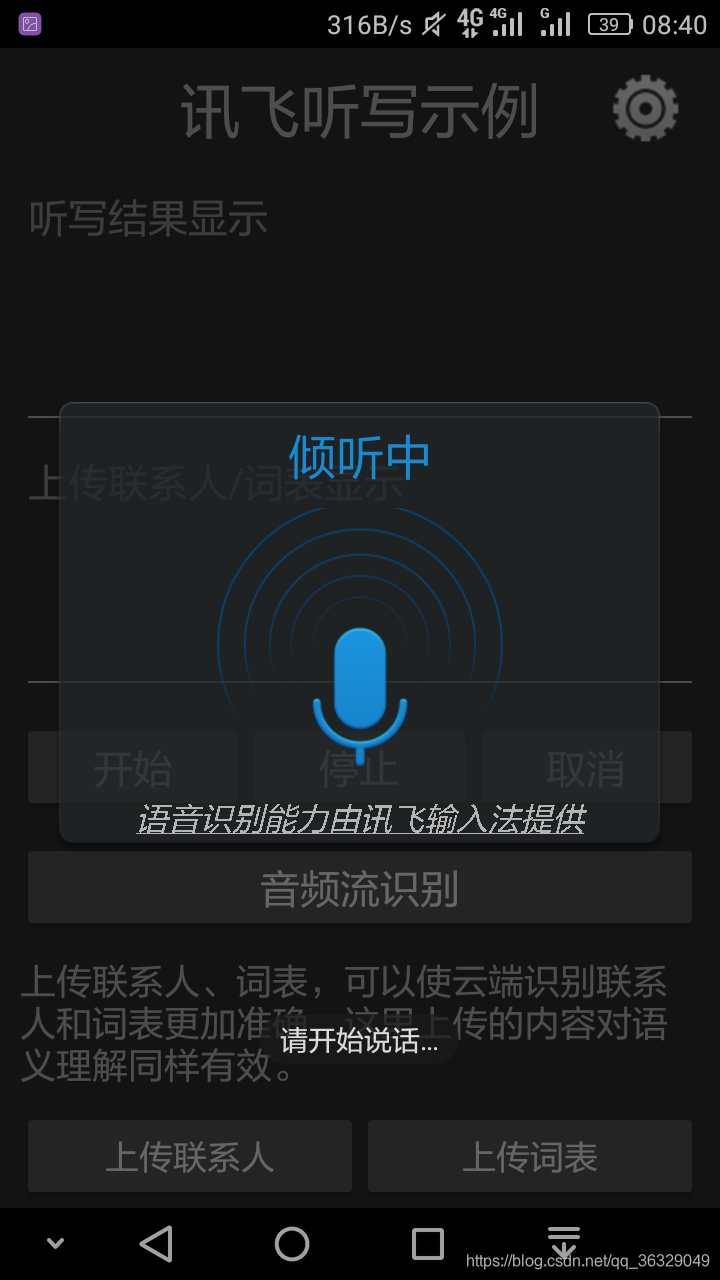



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











