




 本文综述了几种结合知识库和非结构化文本信息的知识驱动对话系统模型。包括利用结构化知识库进行对话生成、结合非结构化文本选择最佳回复、基于聊天记录和外部事实生成丰富回应的模型。此外,还探讨了完全数据驱动的方法,以及如何在对话系统中整合知识库和文本知识。
本文综述了几种结合知识库和非结构化文本信息的知识驱动对话系统模型。包括利用结构化知识库进行对话生成、结合非结构化文本选择最佳回复、基于聊天记录和外部事实生成丰富回应的模型。此外,还探讨了完全数据驱动的方法,以及如何在对话系统中整合知识库和文本知识。
Chatbot&QA with knowledge
目前,chatbot&QA都很火,Neural network 模型已经可以进行很自然的对话交互了,在传统的seq2seq模型的基础上,近年来提出很多结合Knowledge的方式。本文就是总结了部分此方向的论文。
所谓的Knowledge分为两种,knowledge base 和unstructured textual information。
knowledge base(KB):一般为三元组的方式(s,r,o)。这种结构化的数据更容易用于回答组合问题,但是目前所拥有的knowledge base很大的问题在于信息不完整,也就是信息量少。
unstructured textual information:非结构化的文本形式。与KB相反,这种形式的知识量很大,比如百度百科,知乎等等,但它是非结构化的形式。
Seq2seq模型:
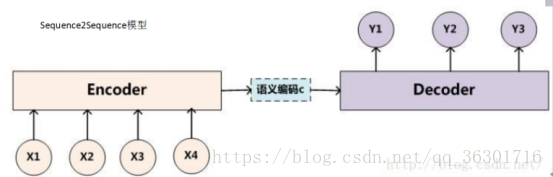
unstructured textual information
非结构化文本处理的主要思路:将文本中的facts整理得到fact set,根据输入的信息input筛选出与之相关的facts:F={f1,f2,……,fn} ,再利用input和facts的信息进行建模,选出候选集中相关度最高的答案或者生成最可能的答案。下面介绍三种模型:
1:A Neural Network Approach for Knowledge-Driven Response Generation
该论文实现任务的是conversation的生成,输入有WikiPedia数据库和聊天的历史信息,输出为下一句聊天内容。
该论⽂所引⼊的知识包含两部分: ⽣成某句回答时,整合过去所出现的所有对话,作为⼀种 knowledge。 每个对话者拥有 WikiPedia ⾥的属于各⾃的 global knowledge。 该论⽂中提出的模型包含 sentence modeling 和 sequence modeling。 sentence modeling ⽤于提取 local features,即提取 knowledge ⾥的内容。该 model 使⽤了 CNN 来对句⼦进⾏分类,每个 sentence 作为输⼊,最终输出 sentence 的 classification。再将 classification 信息插⼊ RNN 的训练过程。
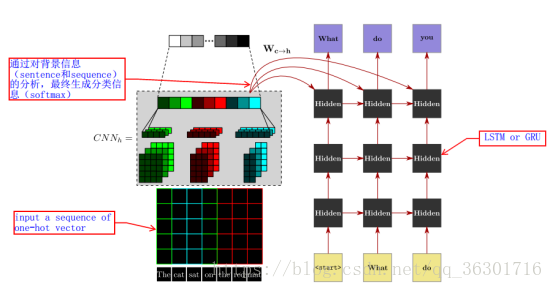
sentence modeling(图中左边部分):此部分输入句子后表示成one-hot vector,再通过一个CNN网络根据topic-keyword对其进行分类。
预训练:先在Wikipedia数据集上预训练Sentence Model,从而得到含有维基百科全局信息的初始模型。(此过程sentence modeling独立完成)
预训练完成后模型提取到了相关数据库的 local features,这也就是该模型结合knowledge的方式。
完成预训练后,该模型在整体中的作用是对输入的历史聊天记录进行分类,并将分类信息送给sequence modeling。
sequence modeling(图中右边部分):该部分就是一个RNN模型,在每一步输出前的最后一个状态中都加入sentence modeling中得到的分类信息。其中RNN的实现结构分为两种Long Short-Term Memory(LSTM)和Gated Recurrent Unit(GRU)。
2:Incorporating Unstructured Textual Knowledge Sources into Neural Dialogue Systems
该论文实现任务是给定一个context和一个response candidate list作为备选答案,通过context来从candidate list中选择正确的response。
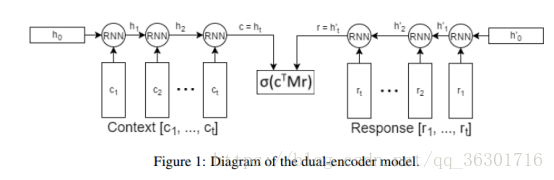
上图模型是ubuntu corpus中的baseline模型,称为dual encoder,一个rnn来encode context,一个rnn来encode response,然后综合起来做预测。
本文的模型是基于该任务上结合了外部相关数据,并且数据是非结构化的文本。如下图:
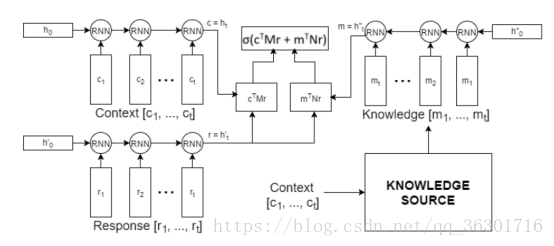
也就是增加了一个RNN网络来 encoder knowledge,再分别利用RNN网络隐藏层的最后一层c,r来计算候选集的概率,并综合结果得出相似度最高的一个答案。
该问题的定义太过简单,与实际应用相差较大,但是其思路可以借鉴。
3:A Knowledge-Grounded Neural Conversation Model
该模型思路与上一个模型类似,也是基于聊天记录结合非结构化文本知识,但是其答案是生成的。
该论文意在没有槽位填充下产生内容更加丰富的回应。论文实验中以对话记录和外部的facts”为条件,通过常见的seq2seq方法使模型在开放领域的设置中变的通用和可行。
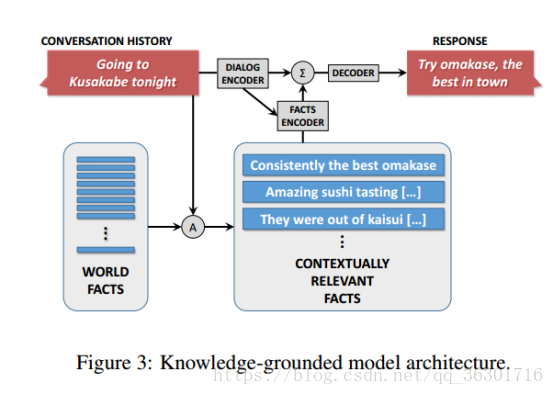
该模型思路如图:。首先我们有一个可用的world facts,这是一个每行为一条词目的集合(例如百科,评论),并以命名实体作为关键词进行索引。然后在给定的source sequence S中,识别S的“focus”(即特征词)。这些foucs可以被用于关键词匹配或更先进的方法中,例如实体链(entity linking)或命名实体识别。这样query就可以检索到所有上下文相关的facts: F = {f1, f2, f3, ….., fk}。根据检索出的facts,encoder聊天记录,并利用其结果encoder相关知识,两部分encoder的结果结合,最终decoder出response。此处的encoder和decoder都是基于seq2seq模型。
Facts Encoder:
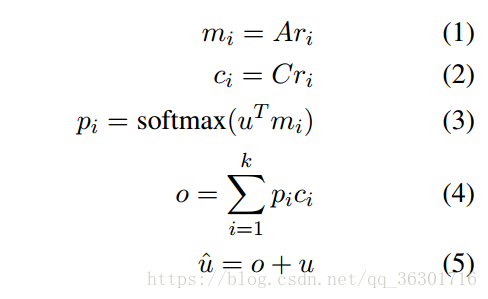
ri是代表fi的词袋表示(v维);u是聊天信息encoder出的结果(d维向量);A,C ϵ Rd×v 是参数。最终结果整合了输入sequence和相关知识,最后通过该隐藏态来预测响应sequence的逐词生成。
knowledge base
Knowledge base是三元组的形式(s,r,o),s和o分别代表subject和object,r代表s和o的关系relation。
4:Flexible End-to-End Dialogue System for Knowledge Grounded Conversation
该论文提出了一个完全数据驱动的生成对话系统GenDS,它能够基于输入消息和相关知识库(KB)生成响应。为了生成任意数量的答案实体,即使这些实体从未出现在培训集中,我们设计了一个 dynamic knowledge enquirer,根据不同的本地上下文,在单个响应中选择不同的答案实体。
该论文分为Candidate Facts Retriever、Message Encoder、Reply Decoder三部分,其中Reply Decoder又分为Common Word Generator和Dynamic Knowledge Enquirer两种。
首先介绍一下问题:输入为1)输入的信息;2)knowledge base K;3)实体类型列表Ʈ。
此外,将所有的单词分为两种knowledge words和common words:knowledge words是knowledge base中包含的所有实体;common words是其他剩余单词。这两类词在词义上不重合,比如love在knowledge word中可能表示一首歌的名字,在common word中表示喜欢。
Candidate Facts Retriever:
从 input 中提取 entity(E),然后在 KB 中进⾏ query,将通过 relation 寻找到的 objects 和 subjects 作为 Candidate Facts 存储为⼀个集合。(此处是说将entity作为objects来寻找subjects和将entity作为subjects来寻找objects)
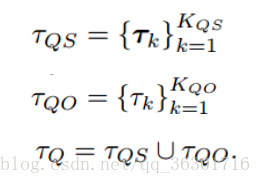
Message Encoder:
该部分的目的是抓住用户的意图,所以我们用实体的类型来代替输入信息中的实体X,然后将更改后的信息用RNN编码得到representations H。比如我们输入为“我想听周杰伦的歌,你给我推荐一下”,将周杰伦用类型person代替,不会影响推荐歌曲的意图,而且前面模型中筛选出实体本身就和周杰伦相关,所以也不会影响最终生成结果。
之所以用实体类型替代实体,是为了再句子生成过程中更多地考虑语言的流畅等而不是纠结在具体的实体上。
Reply Decoder
该部分是根据user intention H 和candidate facts τQ 生成response。此处设计了一个门a knowledge gate={0,1}来控制该生成的是knowledge word还是common word。
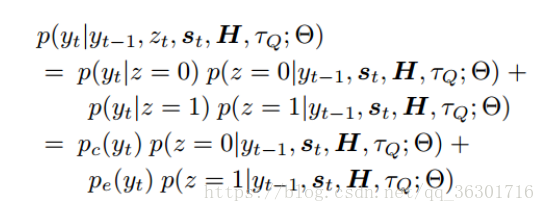
Z=0时启用Common Word Generator,Z=1是启用Dynamic Knowledge Enquirer。
Common Word Generator
该部分主要是利用Message Encoder的结果意图向量H,使用RNN网络生成下一个词语的概率,再选择概率最高的。具体公式不列举了,感兴趣的可以去独一下论文。
Dynamic Knowledge Enquirer
根据动态实体总分对Candidate Facts Retriever中的所有相关实体进行排序,选择最合适的一个。
定义了三个分数:文章匹配度分数 rek, 实体更新分数 ft 和 实体类型更新分数 ukt, 最终三个实体的总分作为动态实体分数。
5:Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks
最后一个模型当然是两种类型的knowledge都结合了。
该论文任务:给出问题 q (w1;w2;...;wn) 这些词中至少包含一个空和一个实体,模型完成的是根据 knowledge base K 和text T 用一个实体来填空。
Universal schema
如下图左边部分,universal schema matrix中行标为一对实体,列标为kb或者文本中存在的关系。
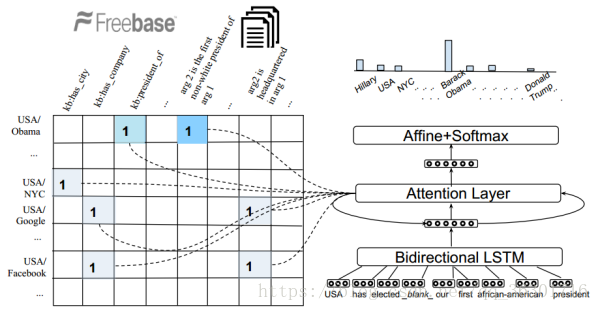
universal schema matrix中的内容Memory:每个Memory cell都是key-value pair的形式。
(s,r,o)代表KB 三元组:
key : k ϵ R2d formed by concatenating the embeddings s ϵ Rd and r ϵ Rd of subject entity s and relation r respectively.
value v: The embedding o ϵ Rd of object entity o .
(s; [w1;...;arg1;...;arg2;wn]; o) ϵ T 代表 textual fact,其中arg1 和 arg2 是实体‘s’和‘o’的所在的位置。
key: k = [w1; :::;s; :::; blank ; wn] , arg1处换成s。然后用双向LSTM网络生成分布式表示:
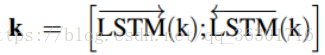
value: the embedding of the object entity o.
模型:(如上图)
Question Encoder
用双向LSTM生成分布式表示q ϵ R2d
Attention over cells
k、v分别代表key值和value值,k用于生成注意力机制的权重,v用来计算上下文表示以预测答案。其中c0初始化为q。
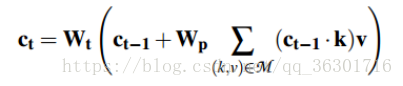
Answer Entity Selection
根据最终的上下文向量 ct 选择答案。
转载请声明,谢谢!

















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









