







数据库锁是一种机制,用于协调多个进程或线程并发访问某一资源,以保证数据的一致性和完整性。
从性能上,分为乐观锁和悲观锁
1. 乐观锁
乐观锁基于一种假设:在多数情况下,数据在访问和修改的过程中不会发生冲突。因此,它只在数据实际更新时才检查是否存在冲突。
- 实现方式:
- CAS(Compare And Swap):这是乐观锁的一种典型实现方式,广泛应用于Java的并发编程中。通过比较数据版本的前后状态来决定是否可以安全地执行更新。
- 版本号控制:在数据表中添加一个版本号(version)字段,通过比较操作前后的版本号来判断数据是否被其他事务修改过。
2. 悲观锁
悲观锁假设在任何时候只要数据被多个事务访问,就极有可能引起冲突。因此,它在数据访问之前就加锁,以防止其他事务的访问。
- 类型:
- 读锁(共享锁,S锁):允许多个事务并发读取同一资源,但在释放读锁之前,阻止对该资源的写操作。
- 写锁(排它锁,X锁):当一个事务对数据进行写操作时,它会阻止其他事务对该数据的读和写操作,直到写操作完成。
3. 补充说明
- 适用场景:
- 乐观锁:更适合读操作频繁的场景。在这种场景下,使用乐观锁可以减少锁的持有时间,从而减少锁冲突的可能性,提高系统的并发能力。
- 悲观锁:更适合写操作频繁的场景。当数据频繁被更新时,悲观锁通过提前加锁可以有效避免数据更新的冲突和不一致性。
- 性能影响:
乐观锁通常在冲突较少时性能较好,因为它避免了锁的直接管理开销。但在冲突频繁发生时,可能因为重试操作而导致性能下降。悲观锁虽然能有效避免数据冲突,但可能因为锁等待而降低并发性能。
从数据操作的粒度上,分为表锁和行锁
1. 表锁
表锁是一种较为简单的锁机制,它在操作前锁定整个表,适用于对表进行批量操作的场景。
- 特点:
- 开销小,加锁快:因为锁定的是整个表,所以管理起来相对简单。
- 无死锁:整个表作为锁定对象,不会出现死锁情况。
- 并发度低:由于锁定整张表,任何其他的写操作都需要等待解锁,读操作的限制依赖于锁的类型(读锁还是写锁)。
- 操作命令示例:
- 加锁:LOCK TABLES 表名 READ/WRITE;
- 查看锁:SHOW OPEN TABLES;
- 解锁:UNLOCK TABLES;
- 使用场景:
- 读锁:允许多个事务并发读取,但阻止写操作。
- 写锁:当前会话可以进行读写操作,其他会话的任何操作都会被阻塞,直到锁释放。
2. 行锁
行锁是更为细粒度的锁机制,只锁定操作的具体数据行。主要由支持事务的存储引擎(如InnoDB)实现。
- 特点:
- 开销较大,加锁慢:需要定位到具体的行,且管理这些锁的代价较高。
- 可能出现死锁:不同的事务可能锁定不同的行,存在死锁的可能性。
- 并发度高:只锁定必要的行,影响范围小,支持更高的并发访问。
- 前提条件:
为了有效地使用行锁,UPDATE、DELETE等操作的WHERE子句应该使用索引字段。否则,可能触发行锁升级为表锁。
- 行锁升级为表锁:
- 在可重复读(RR)隔离级别下,如果UPDATE或DELETE操作没有使用到索引,则为了维护一致性,MySQL可能将行锁升级为表锁。
- 读已提交(RC)隔离级别下不会自动升级为表锁,因为RC级别对一致性的要求不如RR级别高。
要理解为什么在RR(可重复读)隔离级别下MySQL可能会从行锁升级为表锁,而在RC(读已提交)隔离级别下不会,我们需要先了解两个隔离级别处理数据一致性问题的机制差异,以及索引的作用在这其中的影响。
RR(可重复读)隔离级别
在RR隔离级别下,MySQL的目标是确保事务可以多次读取同一数据并获得相同的结果,即使在这个事务执行期间其他事务也在进行数据修改。此外,RR级别也试图通过使用间隙锁来避免幻读问题,幻读是指当事务在读取某范围内的记录时,另一个事务在这个范围内插入了新的记录,导致第一个事务在再次读取这个范围的记录时会发现新的“幻影”记录。
为了实现这种一致性,如果一个事务在没有使用索引字段的条件下进行扫描(比如全表扫描或是使用了非索引字段的查询),MySQL为了防止在扫描期间数据发生变化(不可重复读和幻读),会选择将操作升级为表锁。这种方式确实能防止数据在扫描期间的变化,但代价是牺牲了并发性。
RC(读已提交)隔离级别
相比之下,RC隔离级别只保证读取的数据是已经被提交的,这意味着在同一个事务内的两次读操作可能会看到不同的数据(解决了脏读问题,但不能解决不可重复读和幻读问题)。因为RC隔离级别对数据一致性的要求不如RR级别高,所以当查询不使用索引字段时,MySQL在RC级别下不需要将操作升级为表锁,因为它允许事务看到其他事务提交的数据变化。
索引的影响
在InnoDB存储引擎中,行锁实际上是索引锁。这意味着当查询条件基于索引时,MySQL可以更精确地锁定需要的数据行。如果查询没有使用索引,MySQL就无法只锁定必要的行,因为它无法确定哪些行会受到查询的影响。在RR级别下,为了维持一致性,MySQL选择锁定更多的数据(甚至是整张表),而在RC级别下,则允许事务看到查询期间其他事务对数据所做的修改。
总结
RR隔离级别下MySQL可能会从行锁升级为表锁,是因为RR级别下需要保证数据在事务内的一致性和防止幻读,当查询不使用索引时,MySQL采取更保守的策略来维护这种一致性。而在RC级别下,因为一致性要求不高,所以不需要将操作升级为表锁。理解这一点有助于在设计数据库操作时,更好地利用索引来优化查询性能和并发控制。
3. 行锁示例操作
- 开启事务:BEGIN;或START TRANSACTION;
- 更新数据:UPDATE 表名 SET 字段名=值 WHERE 条件;
- 提交事务:COMMIT;
总结
InnoDB存储引擎通过实现行级锁定,相较于MyISAM的表级锁定,提供了更高的并发处理能力。正确地使用行锁和表锁,根据实际的业务需求和数据访问模式选择合适的锁类型和隔离级别,是优化数据库操作性能的关键。不过,需要注意的是,不当的锁使用策略可能导致性能下降,特别是在高并发的环境下。
行锁与事务隔离级别案例分析
1. 场景1读未提交:事务A读取其它事务尚未提交的数据
2. 场景2读已提交:**事务A读取其他事务已提交的数据,**MVCC机制(查询是快照读,更新是当前读)
3. 场景3可重复读(默认隔离级别):MVCC机制
4. 场景4串行化(解决幻读)**:**串行化隔离级别是通过将所有操作加锁互斥来实现
间隙锁与临键锁
在MySQL InnoDB存储引擎中,为了实现事务的隔离级别,特别是在可重复读(Repeatable Read, RR)隔离级别下防止幻读(Phantom Reads),InnoDB使用了两种特殊类型的锁:间隙锁(Gap Locks)和临键锁(Next-Key Locks)。理解这两种锁的概念和区别对于优化数据库操作和避免死锁至关重要。
1. 间隙锁(Gap Locks)
间隙锁是一种锁定一个范围但不包括记录本身的锁,它锁定的是索引记录之间的“间隙”,或者是第一个索引记录之前或最后一个索引记录之后的“间隙”。间隙锁的主要目的是为了防止其他事务在这些间隙中插入新的记录,从而保证了可重复读的隔离级别下事务的一致性。
临键锁(Next-Key Locks)
临键锁是间隙锁和行锁的结合体,它不仅锁定索引记录之间的间隙,还锁定了索引记录本身。这意味着,临键锁既防止了在锁定范围内的数据插入,也防止了记录本身的修改或删除。InnoDB默认使用临键锁来避免幻读问题。
2. 间隙锁与临键锁的区别
- 锁定范围:间隙锁只锁定记录之间的间隙,而不包括记录本身;临键锁同时锁定间隙和记录本身。
- 防止幻读:临键锁通过锁定间隙及记录本身,有效地防止了幻读问题。而间隙锁虽然可以防止在间隙中的插入操作,但不对记录本身提供保护。
- 使用场景:在可重复读隔离级别下,InnoDB通过使用临键锁来避免幻读。但是,在某些操作中,如非唯一索引扫描或范围查询时,可能只使用间隙锁。
- 死锁风险:由于临键锁和间隙锁都涉及到范围锁定,它们增加了事务之间死锁的潜在风险。然而,由于临键锁的锁定范围更广,可能会相对增加死锁的可能性。
3. 临键锁的使用场景
- 默认行为:在可重复读(Repeatable Read, RR)隔离级别下,InnoDB对于大多数情况默认使用临键锁。临键锁既锁定索引记录本身,也锁定前往下一个索引记录之间的间隙,从而防止幻读。
- 唯一索引上的等值查询:在执行等值查询(如SELECT … WHERE unique_key = value)时,如果使用的是唯一索引,InnoDB会优化锁的使用,仅对找到的索引记录使用行锁,而非临键锁。
- 范围查询:对于范围查询(如SELECT … WHERE key_column BETWEEN value1 AND value2),InnoDB会使用临键锁来锁定查询范围内的所有记录和间隙。
4. 间隙锁的使用场景
- 防止幻读:在可重复读隔离级别下,为了防止幻读,InnoDB会在执行范围查询或索引扫描时使用间隙锁,锁定查询间隙,防止其他事务在这些间隙中插入新的记录。
- 非唯一索引上的操作:当在非唯一索引上执行查询或更新操作时,如果操作涉及到范围,InnoDB可能使用间隙锁来锁定操作的范围。
5. 间隙锁演示
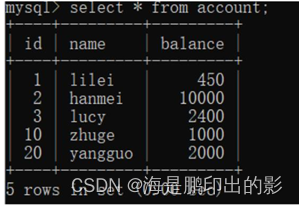
分析加锁范围
- 因为123是连续的,那么间隙 id 为 (3,10),(10,20),(20,正无穷) 这三个区间
- 事务A 执行 update account set name = ‘zhuge’ where id > 8 and id <18
- 因为 8,18 落在区间 (3,10),(10,20) 其他事务无法在 id (3,20] 区间修改数据
- 这个效果等同于 select * from table where id>8 and id<18 for update
行锁分析与管理
在MySQL中,特别是使用InnoDB存储引擎时,了解和分析行锁的情况对于优化数据库性能、解决锁冲突和避免死锁至关重要。以下是一些有用的查询和命令,帮助你分析和管理行锁。
分析行锁争夺情况
- 查看行锁统计信息
SHOW STATUS LIKE 'innodb_row_lock%';
关键指标说明:
- Innodb_row_lock_current_waits:当前正在等待的行锁数量。
- Innodb_row_lock_time_avg:每次行锁等待的平均时间(毫秒)。
- Innodb_row_lock_waits:自系统启动以来,行锁等待发生的总次数。
- Innodb_row_lock_time_max:自系统启动以来,最长一次行锁等待所花的时间(毫秒)。
- 查看当前事务信息
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
这个查询可以让你看到当前正在进行的所有InnoDB事务的信息。
- 查看当前锁信息
对于MySQL 8.0及之前的版本:
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
对于MySQL 8.0及之后的版本,使用data_locks表:
SELECT * FROM performance_schema.data_locks;
- 查看锁等待信息
对于MySQL 8.0及之前的版本:
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
对于MySQL 8.0及之后的版本,使用data_lock_waits表:
SELECT * FROM performance_schema.data_lock_waits;
管理和解决锁冲突
- 解锁操作
如果需要终止一个长时间持有锁的事务,可以使用KILL命令,但需谨慎操作,以避免数据不一致。
KILL trx_mysql_thread_id; -- 用实际的线程ID替换trx_mysql_thread_id
trx_mysql_thread_id可以从INNODB_TRX表中获取。
- 查看InnoDB锁等待的详细信息
SHOW ENGINE INNODB STATUS\G;
这个命令提供了InnoDB存储引擎的详细状态,包括锁等待、死锁信息、事务信息等。它是分析InnoDB性能问题的强大工具。
总结
通过上述方法,你可以有效地分析和管理InnoDB的行锁,从而优化数据库的并发性能,减少锁冲突和死锁的发生。在面对锁相关的性能问题时,合理利用这些工具和命令可以帮助你快速定位和解决问题。在实际操作中,需要根据具体的业务逻辑和数据访问模式,做出合理的锁策略和事务管理决策。
死锁演示
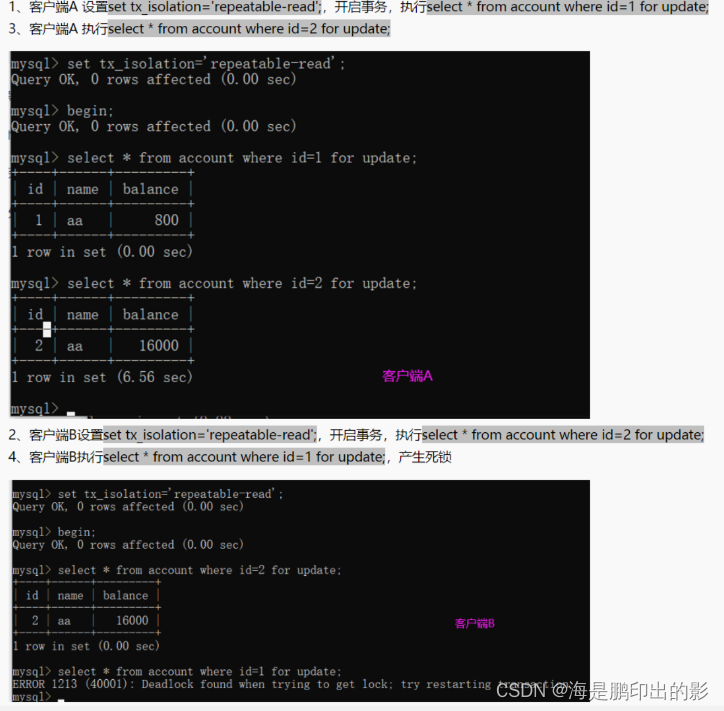
大多数情况 Mysql 可以自动检测死锁并回滚产生死锁的那个事务,但是有些情况无法自动检测死锁,查看近期死锁日志信息:**show engine innodb status,**可以根据锁等待的事务ID搜索对应的SQL语句
锁优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少检索条件范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql尽量放在事务最后执行
回滚产生死锁的那个事务,但是有些情况无法自动检测死锁,查看近期死锁日志信息:**show engine innodb status,**可以根据锁等待的事务ID搜索对应的SQL语句
锁优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少检索条件范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql尽量放在事务最后执行
- 尽可能低级别事务隔离

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









