




 本文分享了爬虫开发中的实用技巧,包括处理编码问题、解析动态网页、使用AJAX技术、POST与GET请求的区别及图片爬取的注意事项。同时,提供了Python错误处理策略,如解决TypeError和HTTP403Forbidden错误,以及使用Session和SSL证书的方法。
本文分享了爬虫开发中的实用技巧,包括处理编码问题、解析动态网页、使用AJAX技术、POST与GET请求的区别及图片爬取的注意事项。同时,提供了Python错误处理策略,如解决TypeError和HTTP403Forbidden错误,以及使用Session和SSL证书的方法。

打开文件要加上encoding否则可能GBK编码错误

携程的某些数据无法爬取,获得的HTML里不是真实数据
获取li列表个数有变化的时候最好用selector,获得整个列表,然后再分离
strip()可以修改自己想剃掉的参数
携程的评论,点击第二页后网站并没有变化,如果直接通过div列表只能获得第一页的评论
python错误提示:TypeError: expected string or bytes-like object(预定的数据类型或者字节对象相关)
一般为数据类型不匹配造成的。


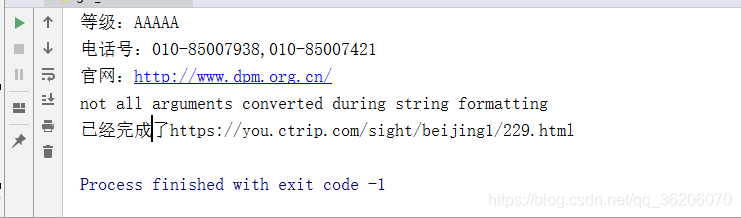
说明前后%和后面的参数数量不对应,有n个字段,就要有n个%s
先建立表
create table xiecheng(cname varchar(20),ename varchar(20),want int,went int,address varchar(50),rank varchar(7),tele varchar(20),office varchar(20));


将长度调整为50个char,试一试可以不
是可行的。
create table ctrip (name varchar(20),rank int, want int,went int,score varchar(6), level varchar(6),cnum int,lovers int,family int,friends int,business int,alone int);
开始爬取图片
先创建文件夹用来放图片
os.mkdir(‘E:\’+name)

然后
#打开文件夹并写入图片
with open(filename,‘wb’) as f:
f.write(response.content)
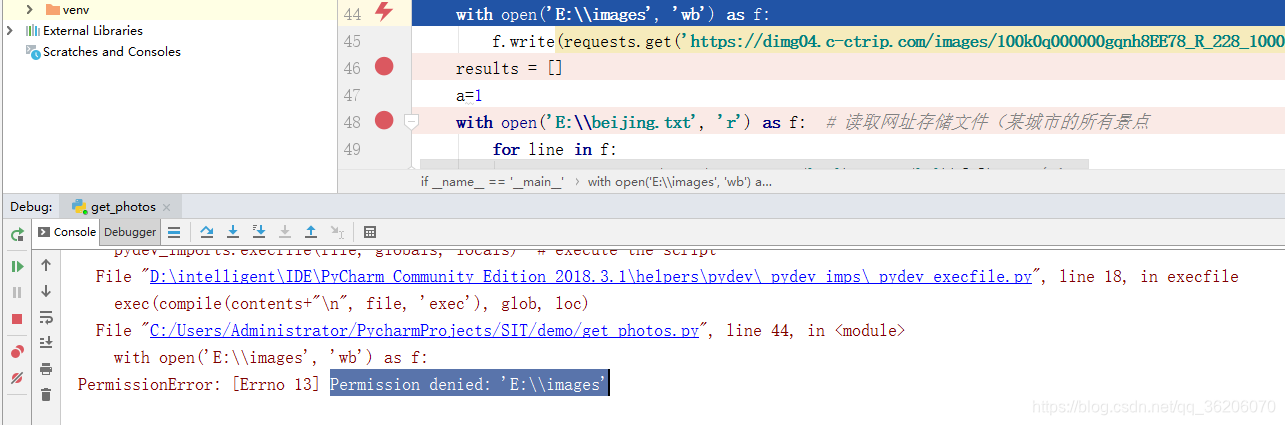
出现报错
查到了AJAX技术,查到了参数的变化规律,最重要的就是用对get 和post!!!(坑惨了)
s.get(url=url, params=data1, headers=headers)
s.post(url=url, data=data1, headers=headers)
这是正确的写法
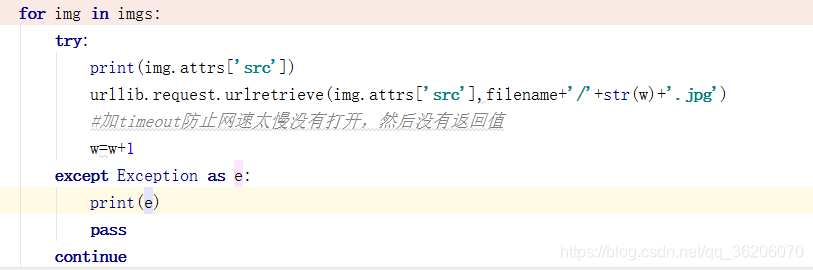
在爬取图片的时候遇到了一定的问题,莫名其妙抛出异常(待解决)
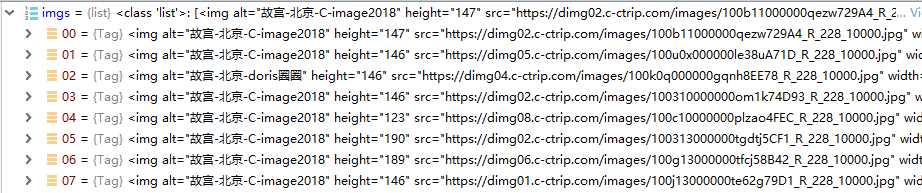
图片img标签已经放入list中,然后去读src的属性值。

抛出这个异常

解决方案:
可以尝试在img.查看所有的函数,然后发现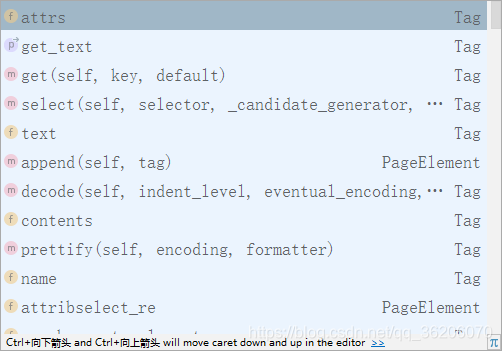
attrs后便转化为字典结构,然后问题就迎刃而解。

继续下一步

 报错了又
报错了又
解决方案如下:

又遇到了404not

再找这个的解决方案
import pandas as pd
dates=range(20161010,20161114)
pieces=[]
for date in dates:
try:
data=pd.read_csv('A_stock/overview-push-%d/stock overview.csv' %date, encoding='gbk')
pieces.append(data)
except Exception as e:
pass
continue
data=pd.concat(pieces)
爬虫 url error : HTTP 403 Forbidden
一般情况加一个响应头即可,最好是谷歌
以下是常用的几个响应头
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
https://www.cnblogs.com/coder-lzh/p/9843197.html
介绍了Session和SSL证书的问题。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









