







C++实现基于二叉查找树的有序符号表(上)
此为上篇,下篇整理删除和范围查找等方法
一. 关于二叉查找树
1.针对实现有序符号表的问题,二叉查找树的优势
若使用无序链表实现符号表,虽然插入数据相比有序数组更有灵活性,但是每次查找都需要对该链表进行遍历来完成查找任务。
若使用有序数组,尽管有序数组可以通过索引快速查找到指定数据,但要解决插入数据的问题,通常需要移动插入位置后面的所有数据,代价较大。
而此次使用二叉查找树来实现有序符号表,它链表的灵活性,又能保持数据有序性,以便我们通过指定键的相对顺序对数据进行查找工作,而二叉查找树的代码和二分法几乎一样简单,虽然在二叉查找树中查找随机键的成本比二分法高39%,但插入一个随机键的成本却可以达到对数级别。
2.实现基于二叉查找树的有序符号表的规则
一棵二叉查找树通常由许多节点组成,节点就是我们要选取的数据结构,本篇将节点数据类型以模板类的方式实现,该节点类包含以下成员变量及成员方法:
template<typename KEY, typename VALUE> BSTNode
{
public:
KEY key;
VALUE value;
BSTNode *LeftNode;
BSTNode *RightNode;
int N;
};
如上所示,该节点类包含key、value、指向左子节点对象的指针、指向右子节点对象的指针以及节点计数器。
(1)key 和 value不用多说, 我们主要通过key来对某一棵二叉查找树进行查找、插入、删除等操作。
(2)每个节点都有两个子节点(左子节点、右子节点),左子节点是左子树的根节点,而左子树代表比当前节点键小的所有节点组成的二叉树,右子节点是右子树的根节点,右子树代表比当前节点键大的所有节点组成的二叉树。
如下图所示
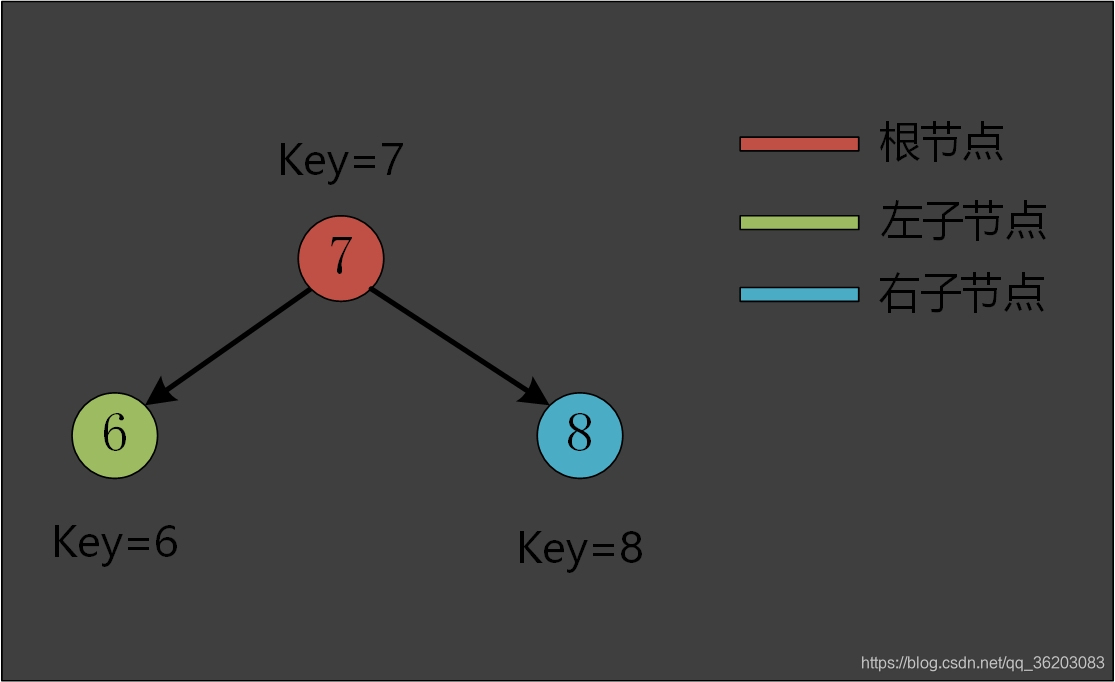
由二叉查找树实现的有序符号表,可以被看作是由许多较小的二叉树组成,每一个小二叉树都遵循左子树的键都小于它的根节点的键,右子树中的键都大于它的根节点的键,每个。 这样看来,一个二叉查找树应是有序的。
二.二叉查找树实现
我们需要使用上面声明的节点类模板来实现二叉查找树,还需要一个查找树的模板类,类的声明中有以下方法和变量,如下所示:
template<typename KEY, typename VALUE>
class BST
{
private:
BSTNode<KEY, VALUE> *m_root;
VALUE get(BSTNode<KEY, VALUE> *bstnode, KEY key);
BSTNode<KEY, VALUE>* put(BSTNode<KEY, VALUE> *bstnode, KEY key, VALUE value);
BSTNode<KEY, VALUE>* min(BSTNode<KEY, VALUE> *bstnode);
BSTNode<KEY, VALUE>* max(BSTNode<KEY, VALUE> *bstnode);
BSTNode<KEY, VALUE>* floor(BSTNode<KEY, VALUE>* bstnode, KEY key);
BSTNode<KEY, VALUE>* ceiling(BSTNode<KEY, VALUE>* bstnode, KEY key);
BSTNode<KEY, VALUE>* select(BSTNode<KEY, VALUE> *bstnode, int k);
int rank(BSTNode<KEY, VALUE> *bstnode, KEY key);
BSTNode<KEY, VALUE>* deleteMin(BSTNode<KEY, VALUE> *bstnode);
BSTNode<KEY, VALUE>* deleteMax(BSTNode<KEY, VALUE> *bstnode);
BSTNode<KEY, VALUE>* deleteNode(BSTNode<KEY, VALUE> *bstnode, KEY key);
void keys(BSTNode<KEY, VALUE> x, queue<KEY> queue, KEY lok, KEY hik);
int size(BSTNode<KEY, VALUE> *bstnode);
public:
int size();
VALUE get(KEY key);
void put(KEY key, VALUE value);
KEY min();
KEY max();
KEY floor(KEY key);
KEY ceiling(KEY key);
KEY select(int K);
int rank(KEY key);
void deleteMin();
void deleteMax();
void deleteNode(KEY key);
BSTNode<KEY, VALUE>* deleteMin_tool(BSTNode<KEY, VALUE> *bstnode);
queue<KEY> keys();
queue<KEY> keys(KEY lok, KEY hik);
};
下面会依次实现,并尽量理解其意义
(1) put
put 方法用于在保持二叉查找树有序的情况下,插入新的数据或者更新数据。
本篇使用递归的方式实现插入数据,首先判断所要插入的二叉查找树是否为空(意味着一个节点也没有),那么此时插入的数据就是整个二叉树的根节点,因此只需要使得新插入的节点作为二叉查找树的根节点,在本篇中的具体做法是 如果put接收到的节点指针变量为NULL(比如,某个节点已经没有左节点/右节点,说明已经没有比这个节点的key更小/更大的节点了,), 那么新申请分配一份内存空间,使用BSTNode构造函数初始化一个节点,让N(节点计数器)的值为1,代表没有左子树也没有右子树。初始化了一个新节点指针后,将其赋值给m_root或者某节点的左节点指针或右节点指针。
如果要插入的二叉查找树不为空,则判断指定键和根节点的大小
如果指定键小于根节点,则再次调用put,使根节点的左子树作为put的参数,使其返回值等于根节点的左子树(递归)。效果是继续向左子树深入,直到使指定键找到其合适的位置,保持有序性
即bstnode->LeftNode = put(bstnode->LeftNode);
如果指定键大于根节点,则让它深入右子树,直到指定键找到其合适的位置,使二叉查找树保持有序性,即bstnode->RightNode = put(bstnode->RightNode);
最后应该更新当前节点的节点计数器,本篇的迭代方法使得插入数据后沿着原来的遍历路径,可以更新路径中每一个节点的节点计数器。
具体代码如下:
template<typename KEY, typename VALUE> void BST<KEY, VALUE>::put(KEY key, VALUE value)
{
m_root = put(m_root, key, value);
}
template<typename KEY, typename VALUE> BSTNode<KEY, VALUE>* BST<KEY, VALUE>::put(BSTNode<KEY, VALUE>* bstnode , KEY key, VALUE value)
{
if(bstnode == NULL) return new BSTNode(key, value, 1);
else if(key < bstnode->key) bstnode->LeftNode = put(bstnode->LeftNode, key, value);
else if(key > bstnode->key) bstnode->RightNode = put(bstnode->RightNode, key, value);
bstnode->N = size(bstnode->LeftNode) + size(bstnode->RightNode);
return bstnode;
}
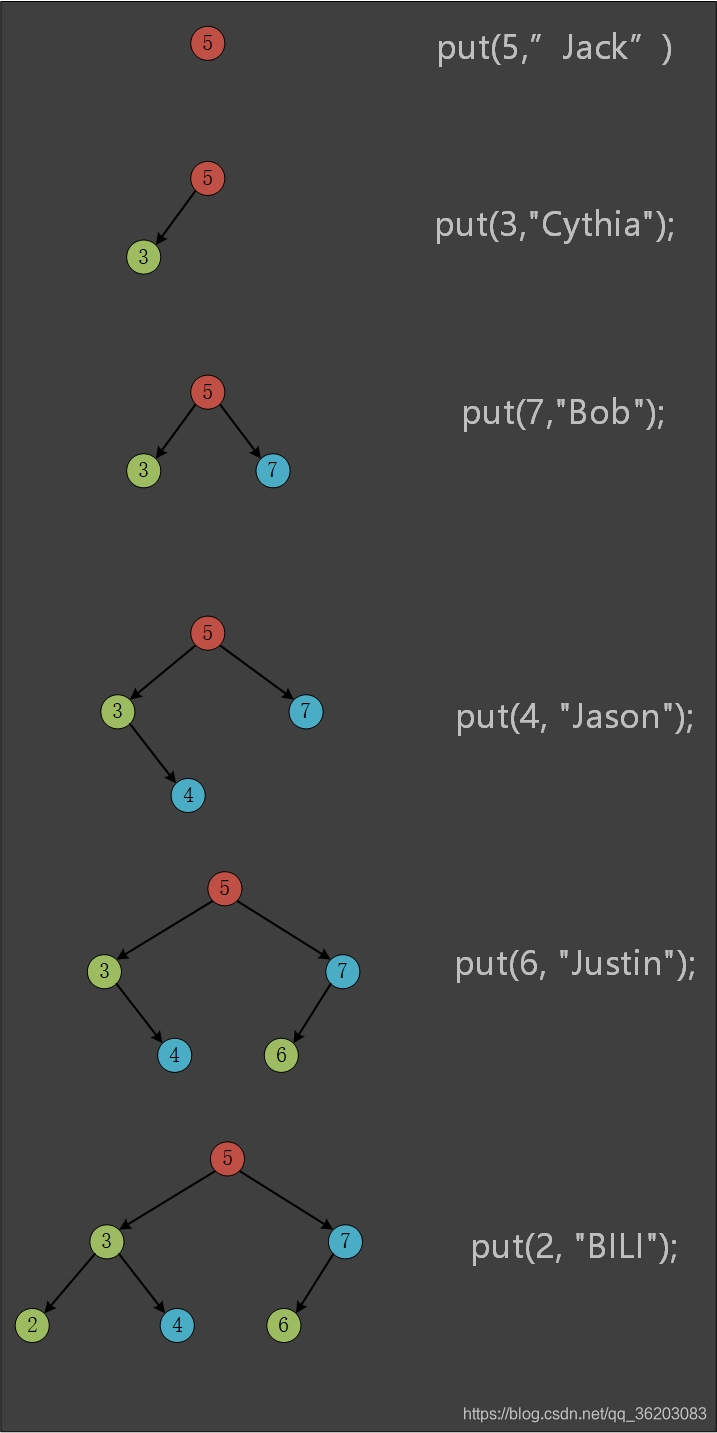
假设我们在main函数中这样调用put函数
BST<int, string> bb;
bb.put(5, "Jack");
bb.put(3,"Cythia");
bb.put(7,"Bob");
bb.put(4, "Jason");
bb.put(6, "Justin");
bb.put(2, "BILI");
那么插入数据过程可以如下图所示:
(2) get
get方法用于查找某指定键对应的值
大概思路为,若二叉查找树的根节点或者深入左子树或右子树后最后发现子节点指针为空,说明要查找的节点不存在,返回NULL。
如果指定键小于当前节点的值,递归地调用get函数,携带指定key向左子树深入寻找指定键;如果指定键大于当前节点的值,递归地调用get函数,携带指定key向右子树深入寻找指定键。
template<typename KEY, typename VALUE> VALUE BST<KEY, VALUE>::get(KEY key)
{
return get(m_root, KEY key);
}
template<typename KEY, typename VALUE> VALUE BST<KEY, VALUE>::get(BSTNode<KEY, VALUE> *bstnode, KEY key)
{
if(bstnode == NULL)
return NULL;
if(key < bstnode->key) return get(bstnode->LeftNode, key);
else if(key > bstnode->key) return get(bstnode->RightNode, key);
else return bstnode->value;
}
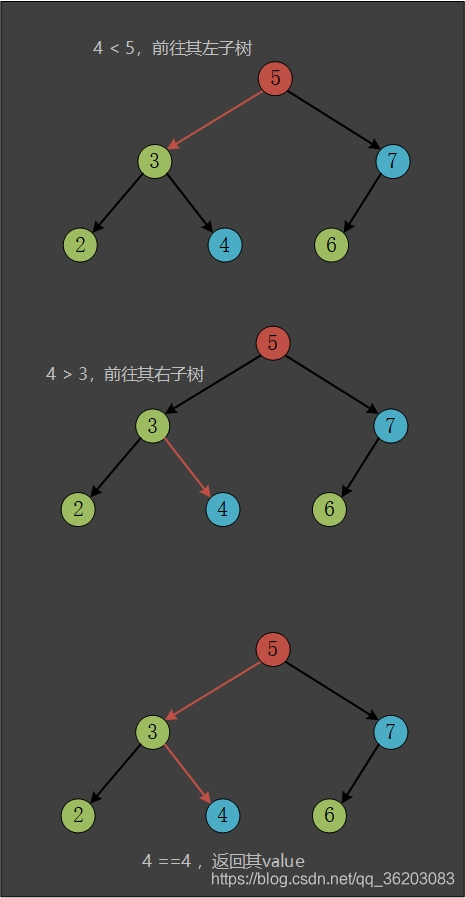
插入数据后,假设我们需要查找键为4的节点
查找过程如下图所示
(3) min/max
min和max分别表示获取二叉查找树中,最小的键和最大的键,实现方法非常简单,例如,想要实现min(),个人的理解是只需不断地往二叉查找树的左子树深入,直到找到某个节点的左子节点为空为止,那么这个节点就是键最小的节点。
代码如下所示:
template<typename KEY, typename VALUE> KEY BST<KEY, VALUE>::min(KEY key)
{
return min(m_root)->key;
}
template<typename KEY, typename VALUE> BSTNode<KEY, VALUE>* BST<KEY, VALUE>::min(BSTNode<KEY, VALUE> *bstnode)
{
if(bstnode->LeftNode == NULL) return bstnode;
return min(bstnode->LeftNode);
}
max函数同理,只需不断向右子树深入,直到找到某个节点的右子节点为空,这个节点的键就是最大的。
template<typename KEY, typename VALUE> KEY BST<KEY, VALUE>::max(KEY key)
{
return max(m_root)->key;
}
template<typename KEY, typename VALUE> BSTNode<KEY, VALUE>* BST<KEY, VALUE>::max(BSTNode<KEY, VALUE> *bstnode)
{
if(bstnode->RightNode == NULL) return bstnode;
return max(bstnode->RightNode);
}
(4) floor/ceiling
floor方法实现了查询比指定键小于等于的最大键,在递归的过程当中,如果指定键比当前节点的键小,那么小于等于指定键的最大键肯定在左子树当中,因此向左子树深入,继续调用floor函数;
如果指定键比当前节点大,如果右子树中存在小于等于指定键的节点,那么所要查找的拥有那个最大键的节点才会存在于右子树当中,否则比指定键小的最大键就是当前节点。
代码如下所示:
template<typename KEY, typename VALUE> KEY BST<KEY, VALUE>::floor(KEY key)
{
BSTNode *bstnode = floor(m_root, key);
if(bstnode == NULL) return NULL;
else return bstnode->key;
}
template<typename KEY, typename VALUE> BSTNode<KEY, VALUE>* BST<KEY, VALUE>::floor(BSTNode<KEY, VALUE> *bstnode, KEY key)
{
if(bstnode == NULL) return NULL;
if(key == bstnode->key) return bstnode;
if(key < bstnode->key)
return floor(bstnode->LeftNode, key);
BSTNode<KEY, VALUE>* bstnode_r = floor(bstnode->RightNode, key);
if(bstnode_r != NULL) return bstnode_r;
else return bstnode;
}
ceiling方法用于找到大于指定键的最小键,实现原理与floor非常类似,如下所示
template<typename KEY, typename VALUE> KEY BST<KEY, VALUE>::ceiling(KEY key)
{
BSTNode<KEY, VALUE> *bstnode = ceiling(m_root, key);
if(BSTNode == NULL)
return NULL;
else return bstnode->key;
}
template<typename KEY, typename VALUE> BSTNode<KEY, VALUE>* BST<KEY, VALUE>::ceiling(BSTNode<KEY, VALUE> *bstnode, KEY key)
{
if(bstnode == NULL) return NULL;
//此处一方面是检查二叉查找树根节点是否为空,直接返回NULL
//另一方面,如果二叉树不为空,但某节点的左子树为空时,表明该节点就是大于等于指定键的最小值
if(key == bstnode->key) return bstnode;
if(key > bstnode->key) //指定键比 当前节点的键大,说明比指定键更大或等于它的键肯定在右子树出现
return ceiling(bstnode->RightNode, key);
BSTNode<KEY, VALUE>*bstnode_l = ceiling(bstnode->LeftNode, key);
if(bstnode_l != NULL) return bstnode_l;
else return bstnode
}
这部分递归算法对我来说比较难,所以又画了张图(真费时间😒)
考虑一下基线条件是什么,也就是说最简单的情况是什么?
经过不太严谨的思考,得出以下结论
1.不存在二叉树的情况下,节点指针为NULL ,返回 NULL就可以
2.只有一个节点,并且这个节点的key和指定key相同,返回这个key即可,符合问题
这两种情况很好处理,可以马上想到要返回什么,而面对复杂的问题,我们需要缩小问题规模,直到满足基线条件
如果情况稍微复杂一点,二叉查找树如下所示
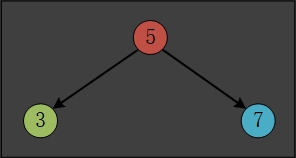
这种情况下,想要找到一个比指定键小的最大键也不是很难
假设指定键为4,先和根节点的key进行比较,显然 key < 根节点的key5,因此,根节点的右子树的节点都比5小,想要找到比键4小或等于4 的键,只能从根节点的右子树找,由此看来,我们有了一个缩小问题规模的办法,那就是继续调用floor函数,其参数变成右子树的根节点(代表我们的关注点将放在根节点的右子树——一个更小的树),直到达到基线条件,当然深入左子树的过程通常涉及右子树,马上讨论,这个过程对应如下代码:
if(key < bstnode->key)
return floor(bstnode->Leftnode, key);
但如果我们想要找到键小于等于6的最大键呢,通过与5进行比较发现,显然指定键6 大于这个二叉查找树的根节点的键5。
现在假设我们只有一个根节点,键为5,我们指定键为6,根节点的右节点为空,因此看来,比6小的最大值就只有5了,因此可以判断最简单的情况就是
1.不存在二叉树。
1.根节点没有右子树,返回当前的键即可。这个条件可以扩展为 在右子树中没有小于等于指定键的最大值。
现在使问题再复杂一点
现在根节点有右子节点了,我们继续调用floor函数,将参数设置为根节点的右子节点(如果右节点中不存在比指定键小或等于指定键的节点,根节点就是我们要的节点),接着问题规模进一步缩小,聚焦到了键为7的节点上,此时我们已经可以看出,距离满足基线条件不远了, 6 < 7, 因此,继续在floor内部调用floor函数,参数设置为键为7节点的左节点,缩小问题规模。

最终,键为7的节点左节点为NULL, 满足了基线条件if(键7节点的左子节点 == NULL),因此可以返回NULL,一层层返回,floor(键为7的节点,key=6) 的返回返回值就是NULL,floor(键为5的节点,key = 6)的返回值就是5本身,因为满足基线条件if(floor(键5节点的右子节点, key) == 0), 因此返回键为5的节点指针。
将floor用到更复杂的二叉查找树的原理相同,以上仅是个人理解,可能问题很大- -。
(5) select/rank
select方法的作用是找到排名为k的键,原理比较简单,若 某节点的N与k相等,那么直接返回该节点的key即可,如果N小于k,将问题规模缩小至右子树,继续调用select方法,参数设置为该节点的右子节点,并修改k值为 k-n-1,如果N 大于 k,说明排名k的节点就在左子树当中,缩小问题规模至左子树,深入左子树,继续调用select方法,参数设置额为该节点的左子节点,k值不变。
template<typename KEY, typename VALUE> KEY BST<KEY, VALUE>::select(int k)
{
return select(m_root, k)->key;
}
template<typename KEY, typename VALUE> BSTNode<KEY, VALUE> BST<KEY, VALUE>::select(BSTNode *bstnode, int k)
{
t = bstnode->left->N;
if(bstnode == NULL) return NULL;
if(t == k) return bstnode;
else if(t > k) return select(bstnode->LeftNode, k);
else
{
return select(bstnode->RightNode, k-N-1);
}
}
template<typename KEY, typename VALUE> int BST<KEY, VALUE>::rank(KEY key)
{
return rank(m_root, key);
}
template<typename KEY, typename VALUE> int BST<KEY, VALUE>::rank(BSTNode<KEY, VALUE>*bstnode, KEY, key)
{
if(bstnode == NULL) return 0;
if(key > bstnode->key)
return size(betsnode->LeftNode) + 1 + rank(bstnode->RightNode, key);
else if(key < bstnode->key)
return rank(bstnode->LeftNode, key);
else return size(bstnode->LeftNode);
}
rank方法原理较容易理解,不多赘述


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









