



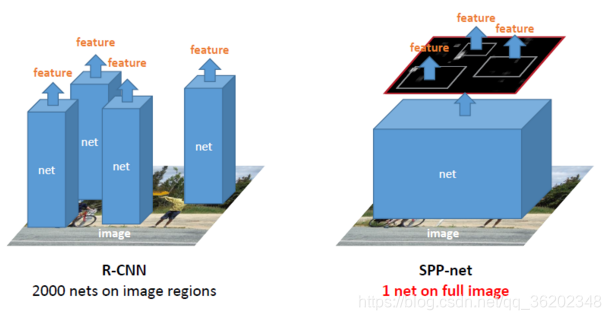
R-CNN对于输入的图片,需要先用SS算法提取出约2k个候选框,必须一个一个转换成固定大小,再输入到卷积网络中,原因是需要使卷积后的feature maps 对应全连接层的配置,耗时费力。
1.SPP-Net的提出,首先是改进了卷积网络普遍需要统一大小的图像输入问题,SPP-Net提出了金字塔池化层(Spatital Pyramid Pooling),替换了网络最后一个池化层(即pool5),金字塔池化层通过多个最大池化层的处理,具体的池化规则为:stride = a/n, 池化窗口window size = [a/n,a/n] ,n为每一层最终输出的feature map边长, a为经过最后一层卷积层后的feature map的边长,即输入金字塔的图像块边长,这样最终输出就是[(a - a/n) / (a/n) + 1] = n,即输出设定大小,然后拼凑成和神经元个数相同的特征数。比如论文中为21类,设置金字塔为3层,分别是1, 2 * 2, 4 * 4,这样输出全部固定为 21个特征。
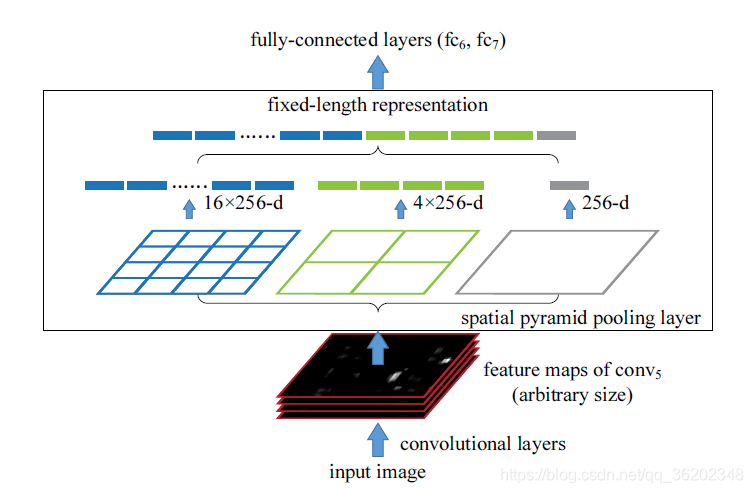
2.还有一点改进的地方,就是对于R-CNN而言,CNN需要对每张图的2k个候选框进行计算,并且是一个一个计算,十分费时。SPP-Net提出将整张图片通过CNN计算出featumap, 再将SS提取的2k个候选框映射到feature map上,这样就得到了对应候选框的feature map。
具体如何映射还未深究,另外一点疑惑是SPP之后为何要对应输出21 * 256,原因是如果是原来的 RCNN 结构,输入224 * 224 * 3,输出的feature map 是[6,6,256],则对应 fc6的权重参数便是[6 * 6 * 256, 4096], conv5 输出通道数是 256,加了SPP之后,通道数不变,输入[6,6,256], 设定 3 层金字塔最大池化层得到 21个特征,因此最后输出21 * 256, 对应 fc6 权重参数则为[21 * 256, 4096],这个层数 21 是可以随意设定的,以及这个图片划分也是可以随意的,只要效果好同时最后能组合成我们需要的特征个数即可。
引用:
虽然SPPNET可以使得网络可以接受不同尺寸的图片的输入,但是在深度学习中我们一般采用批处理(batch)数据来训练网络,然而一个batch中的数据必须保证图片的尺寸在各个维度上面必须是一致的(因为训练的过程需要将批量的数组转化为张量的形式)。因此SPPNET接受不同图片尺寸作为网络的输入的情况也只适用于batch_size=1的时候。
对于模型的训练将batch_size设置为1明显是不合理的,这样会导致模型最终难以收敛。所以SPPNET在深度学习中主要的应用应该在于从特征提取的最后一个feature map中进行多尺度的感知(不同尺寸的pooling_size)以增强特征的表现能力。这也是SPPNET的主要作用。而对于不同的size的图片我们为了保证原有图片的flexibility的时候主要还是采用图片尺寸的等比例缩放以及相关的填充,以保证图片具有相同大小的尺寸以及特征不丢失。
参考:
https://arxiv.org/pdf/1406.4729.pdf 论文链接
http://www.dengfanxin.cn/?p=403 论文翻译
https://blog.youkuaiyun.com/qq_37053885/article/details/81808744 部分代码、映射变换
https://www.cnblogs.com/kk17/p/9748378.html
https://www.cnblogs.com/gongxijun/p/7172134.html

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









