 并发编程与Java线程安全
并发编程与Java线程安全





创建线程的方法
- 集成Thread类,重写run()方法,调用start方法
public class T extends Thread{
private static volatile int count;
@Override
public synchronized void run() {
for (int i = 0; i < 50 ; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(count+++" 线程"+Thread.currentThread().getName());
}
}
public static void main(String[] args) {
T t = new T();
T t1 = new T();
t1.start();
t.start();
}
}
- 实现runnable接口,重写run方法,调用start方法
public class TT implements Runnable {
private int count;
public synchronized void run() {
for (int i = 0; i < 50; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(count+++" 线程"+Thread.currentThread().getName());
}
}
public static void main(String[] args) {
TT tt = new TT();
Thread thread1 = new Thread(tt);
Thread thread2 = new Thread(tt);
thread1.start();
thread2.start();
}
}
并发编程中的三个概念:
在并发编程中,我们经常会遇到三个问题:原子性,可见性,有序性.
1. 原子性
原子性即要么全部执行,要么全不执行,原子性的操作不会被线程调度机制打断.
有个很典型的例子:银行转账的问题.A向B转账1000元,那么必将有A先减1000元,然后B加1000元.这两个操作必须具有原子性,即要么全部执行成功,要么相当于不执行.假如A减1000元之后,出现了异常,那么B就不会加上1000元,从而导致很严重的问题.
java语言的x++自增操作自减操作都不是原子性的.自增操作的执行流程是先从工作内存中获取值,然后再将值+1后赋值到工作内存中,这两个操作合在一起就不是原子性的操作了.因为在获取到值之后,可能会因为线程调度机制而去执行其他的线程,这样就可能导致+1这一操作不会执行,这样就不具备原子性了.
2. 可见性
可见性是指当多个线程访问一个共享变量时,当某个线程对共享变量进行了修改,那么其他线程读取到的必须要是修改后的值.这就是可见性.
class Game extends Thread {
public int index = 0;
public void setIndex(int index) {
this.index = index;
}
public int getIndex() {
return index;
}
@Override
public void run() {
System.out.println("Game Start");
while (true) {
if (getIndex() == -1) {
break;
}
}
System.out.println("Game End");
}
public static void main(String[] args) {
Game game = new Game();
game.start();
try {
Thread.sleep(1000);
} catch (Exception e) {
}
game.setIndex(-1);
System.out.println("change.....");
}
}
例如此处就是一个可见性的问题,主线程修改后的值没有被子线程读取到,所以结果会是一个死循环
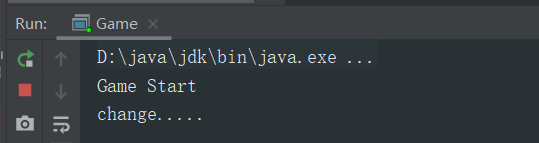
解决的方法有:
1. 用volatile修饰共享变量
public volatile int index = 0;
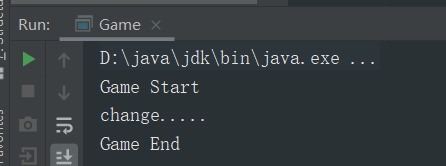
2. 用synchronized 给getIndex()方法加上锁,使其能读取到最新数据
public synchronized int getIndex() {
return index;
}
3. 使用原子类
class Game extends Thread {
public AtomicInteger index = new AtomicInteger(0);
/* public void setIndex(int index) {
this.index = index;
}
public synchronized int getIndex() {
return index;
}*/
@Override
public void run() {
System.out.println("Game Start");
while (true) {
if (index.get() == -1) {
break;
}
}
System.out.println("Game End");
}
public static void main(String[] args) {
Game game = new Game();
game.start();
try {
Thread.sleep(1000);
} catch (Exception e) {
}
synchronized (game) {
game.index.set(-1);
}
System.out.println("change.....");
}
}
2.2 脏读也是可见性的问题
写方法加锁而读方法不加锁,容易导致脏读
以上面的get和set方法为例, 当线程1调用set方法修改index的值时,线程2可以调用get方法获取值,此时获取的值是修改之前的.而当get方法也加上synchronized 修饰之后,get和set方法的锁是同一个对象,都是this.所以get方法必须在set方法执行完成释放锁之后才会执行,这样读取到的就是修改后的值.
public synchronized void setIndex(int index) {
this.index = index;
}
public int getIndex() {
return index;
}
3 有序性
有序性:即程序执行的顺序按照代码的先后顺序执行。
一般来说,处理器为了提高运行效率,可能会对输入代码进行优化.它不保证各个语句执行的顺序是否一致,但是会保证代码的执行结果是一致的.这就是指令的重排序.那么,处理器是依靠什么来判断执行的结果是否一致呢?
答案是处理器在重排序的时候会考虑指令之间的数据依赖性.当语句2要用到语句1的结果的时候,重排序时不会将语句2运行在语句1之前.
int a = 1; //语句1
int y = a+1 //语句2
重排序在单线程的情况下不会有问题,但是在多线程的情况下,会存在问题.
如下所示的语句1和语句2之间是没有依赖关系的,此时,处理器就有可能会将语句2重排序到语句1的前面.而此时,假如线程1先执行了语句2但是还没有执行语句1,线程2就能调用doSomeThing()方法处理业务逻辑了,此时程序会报错
//线程1
context = init();//语句1
inited = true;//语句2
//线程2
if(inited){
doSomeThing()
}
由以上可知, 要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
java内存模型
java内存模型中标明,类中的共享变量(成员变量)在运行时是保存在主内存之中.而每个线程都有自己的工作内存.线程在操作共享变量时,不会直接操作主内存中的数据.每个线程执行程序的时候,都会讲主内存中的共享变量拷贝一份到自己的工作内存.线程在操作数据的时候,也是先从自己的工作内存中获取数据,修改时也是将修改后的结果保存在自己的工作内存中,最后才会将修改后的值保存到主内存中.
synchronized和lock为什么能保证线程安全?
- 保证原子性:被synchronized修饰的部分,必须在该线程执行完之后才会执行其他线程,不会因为线程调度机制而导致执行到一半又去执行其他线程了
- 保证可见性: 由java内存模型可知, 可见性的原因就是因为线程没能及时的读取到其他线程修改的主内存中的值, 而synchronized在执行完毕释放锁之后,会刷新主内存中的值为最新的数据. 这样也就保证了可见性
- 保证有序性: synchronized修饰的部分相当于是单线程执行的, 而单线程的指令重排并不会影响到程序的结果.同时,也能发现, synchronized修饰的部分也是会被指令重排的.但是因为synchronized修饰的部分是串行执行的, 因此能保证有序性.
volatile 怎么保证有序性和可见性?
可见性: volatile的两条实现原则:
1.Lock前缀指令会引起处理器缓存会写到内存
当对volatile变量进行写操作的时候,JVM会向处理器发送一条lock前缀的指令,将这个缓存中的变量回写到系统主存中
2.一个处理器的缓存回写到内存会导致其他处理器的缓存失效
处理器使用嗅探技术保证内部缓存 系统内存和其他处理器的缓存的数据在总线上保持一致。
综合上面两条实现原则,我们了解到:如果一个变量被volatile所修饰的话,在每次数据变化之后,其值都会被强制刷入主存。而其他处理器的缓存由于遵守了缓存一致性协议,也会把这个变量的值从主存加载到自己的缓存中。这就保证了一个volatile在并发编程中,其值在多个缓存中是可见的
有序性: volatile 禁止了JVM的重排序,禁止了重排序,就不存在有序性的问题了.
synchronized和lock的区别
- lock是一个类,不是JVM自带的,而synchronized是一个关键字,是JVM自带的
- synchronized修饰的方法代码块在执行完成之后会自动释放锁,而lock不会自动释放锁,需要用户手动释放
- Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;
- 通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
- Lock可以提高多个线程进行读操作的效率。
阻塞队列
常见的几种阻塞队列:
- ArrayBlockingQueue:基于数组实现的一个阻塞队列,在创建ArrayBlockingQueue对象时必须制定容量大小。并且可以指定公平性与非公平性,默认情况下为非公平的,即不保证等待时间最长的队列最优先能够访问队列。
- LinkedBlockingQueue:基于链表实现的一个阻塞队列,在创建LinkedBlockingQueue对象时如果不指定容量大小,则默认大小为Integer.MAX_VALUE。
- PriorityBlockingQueue:以上2种队列都是先进先出队列,而PriorityBlockingQueue却不是,它会按照元素的优先级对元素进行排序,按照优先级顺序出队,每次出队的元素都是优先级最高的元素。注意,此阻塞队列为无界阻塞队列,即容量没有上限(通过源码就可以知道,它没有容器满的信号标志),前面2种都是有界队列。
- DelayQueue:基于PriorityQueue,一种延时阻塞队列,DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue也是一个无界队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
阻塞队列中的方法 VS 非阻塞队列中的方法
1.非阻塞队列中的几个主要方法:
add(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则会抛出异常;
remove():移除队首元素,若移除成功,则返回true;如果移除失败(队列为空),则会抛出异常;
offer(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则返回false;
poll():移除并获取队首元素,若成功,则返回队首元素;否则返回null;
peek():获取队首元素,若成功,则返回队首元素;否则返回null
对于非阻塞队列,一般情况下建议使用offer、poll和peek三个方法,不建议使用add和remove方法。因为使用offer、poll和peek三个方法可以通过返回值判断操作成功与否,而使用add和remove方法却不能达到这样的效果。注意,非阻塞队列中的方法都没有进行同步措施。
2.阻塞队列中的几个主要方法:
阻塞队列包括了非阻塞队列中的大部分方法,上面列举的5个方法在阻塞队列中都存在,但是要注意这5个方法在阻塞队列中都进行了同步措施。除此之外,阻塞队列提供了另外4个非常有用的方法:
put(E e)
take()
offer(E e,long timeout, TimeUnit unit)
poll(long timeout, TimeUnit unit)
put方法用来向队尾存入元素,如果队列满,则等待;
take方法用来从队首取元素,如果队列为空,则等待;
offer方法用来向队尾存入元素,如果队列满,则等待一定的时间,当时间期限达到时,如果还没有插入成功,则返回false;否则返回true;
poll方法用来从队首取元素,如果队列空,则等待一定的时间,当时间期限达到时,如果取到,则返回null;否则返回取得的元素;
并发容器:
ConcurrentHashMap(JDK1.8)
get()方法
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());//计算哈希值
if ((tab = table) != null && (n = tab.length) > 0 &&
//根据哈希值从table数组中获取到对应哈希桶中的头节点,未找到头结点返回null
(e = tabAt(tab, (n - 1) & h)) != null) {
//与头节点的哈希值进行比对,如果相等则返回头结点的val
if ((eh = e.hash) == h) {
//与头结点的key再进行比对
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//hash值为负值表示正在扩容,这个时候查的是ForwardingNode的find方法来定位到nextTable来
//eh=-1,说明该节点是一个ForwardingNode,正在迁移,此时调用ForwardingNode的find方法去nextTable里找。
//eh=-2,说明该节点是一个TreeBin,此时调用TreeBin的find方法遍历红黑树,由于红黑树有可能正在旋转变色,所以find里会有读写锁。
else if (eh < 0) {
return (p = e.find(h, key)) != null ? p.val : null;
}
//eh>=0,说明该节点下挂的是一个链表,直接遍历该链表即可。
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;//未找到对应的值
}
可以看到,在1.8中ConcurrentHashMap的get操作全程不需要加锁,这也是它比其他并发集合比如hashtable、用Collections.synchronizedMap()包装的hashmap;安全效率高的原因之一。
ConcurrentHashMap的get操作为什么不需要加锁呢?
大家都知道,线程安全常常是因为获取的共享变量不一致而导致的,而get方法中访问到的共享变量只有Node类型的数组table,
transient volatile Node<K,V>[] table;
而volatile关键字可以保证共享变量的可见性, 即实时访问到其他线程修改后的数据. 那么,get方法不加锁的原因是因为table变量使用了volatile修饰么, 其实不然, volatile关键字对于基本类型的修改可以在随后对多个线程的读保持一致, 但是对于引用类型如数组,实体bean,仅仅保证引用的可见性,但并不保证引用内容的可见性。
真正的原因是因为在Node类中val变量和next变量是用volatile修饰了, 也是因为此处保证了ConcurrentHashMap的get方法的线程安全
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
由以上可以看出
get操作全程不需要加锁是因为Node的成员val是用volatile修饰的和数组用volatile修饰没有关系。
数组用volatile修饰主要是保证在数组扩容的时候保证可见性。
那么, Node数组table为什么要用volatile修饰呢?
其实就是为了使得Node数组在扩容的时候对其他线程具有可见性而加的volatile
put()方法:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());//获取哈希值
int binCount = 0;
//死循环
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//第一次添加元素时,初始化table数组
tab = initTable();
//添加到一个空的哈希桶时,通过CAS算法无锁插入数据
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//hash桶(tab[i])是fwd节点,表示正在扩容
else if ((fh = f.hash) == MOVED)
//扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//锁住哈希桶的头结点
synchronized (f) {
if (tabAt(tab, i) == f) {
//哈希值>=0说明是Node链表
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//新增元素的哈希值与头结点相同,则将值val替换为新值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//遍历链表,向尾结点插入数据
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//链表长度>=8时,转换成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//哈希桶存储的元素个数+1
addCount(1L, binCount);
return null;
}
从源码中看出,put方法在往空的哈希桶添加元素时,是采用CAS算法无锁插入的; 只有在发生哈希碰撞时,才会给哈希桶加上锁,锁是每个哈希桶的头结点.
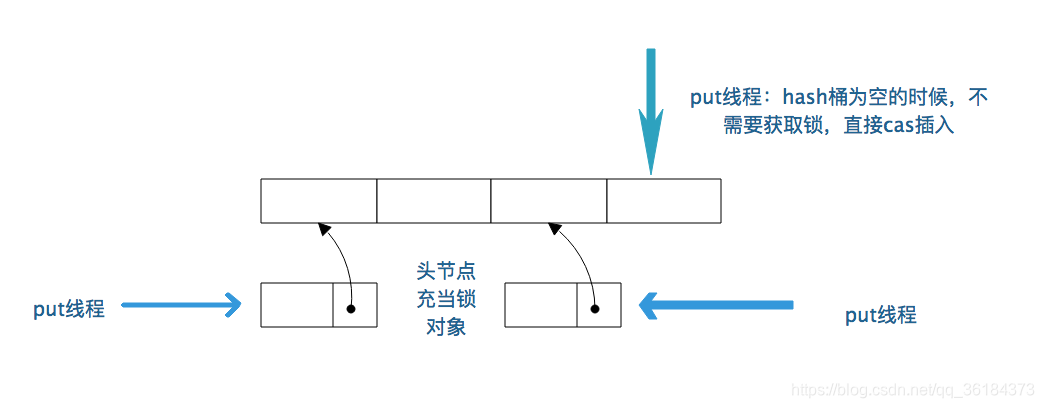
remove()方法
public V remove(Object key) {
return replaceNode(key, null, null);
}
/**
* Implementation for the four public remove/replace methods:
* Replaces node value with v, conditional upon match of cv if
* non-null. If resulting value is null, delete.
* <p>
* 四个公共删除/替换方法的实现:用v替换节点值,条件是如果非空则匹配cv。如果结果值为null,请删除。
*
*/
final V replaceNode(Object key, V value, Object cv) {
int hash = spread(key.hashCode());//哈希值
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//table为空或者还未添加元素
if (tab == null || (n = tab.length) == 0 ||
(f = tabAt(tab, i = (n - 1) & hash)) == null)
break;
//正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
boolean validated = false;
//锁住头结点
synchronized (f) {
if (tabAt(tab, i) == f) {
//链表结构
if (fh >= 0) {
validated = true;
for (Node<K,V> e = f, pred = null;;) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
V ev = e.val;
if (cv == null || cv == ev ||
(ev != null && cv.equals(ev))) {
oldVal = ev;
if (value != null)
e.val = value;
else if (pred != null)
pred.next = e.next;
else
setTabAt(tab, i, e.next);
}
break;
}
pred = e;
if ((e = e.next) == null)
break;
}
}
//红黑树
else if (f instanceof TreeBin) {
validated = true;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null &&
(p = r.findTreeNode(hash, key, null)) != null) {
V pv = p.val;
if (cv == null || cv == pv ||
(pv != null && cv.equals(pv))) {
oldVal = pv;
if (value != null)
p.val = value;
else if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
}
if (validated) {
if (oldVal != null) {
if (value == null)
addCount(-1L, -1);
return oldVal;
}
break;
}
}
}
return null;
}
remove方法也是锁住哈希桶的头结点.依赖于CAS算法


















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









