







TACO 2025 Paper 分布式元数据论文阅读笔记整理
问题
数据安全(包括机密性、完整性和可用性)和崩溃一致性保证对于构建可信持久内存(PM)系统至关重要,通常通过安全元数据和一致性元数据以实现保证。
安全元数据包括以下几种:
-
机密性:通常使用计数器模式加密(CME)[47,58]。维护每个块的加密计数器,在加密/解密块时,使用计数器生成一个一次性填充(OTP),并将OTP与明文/密文进行异或。
-
完整性:生成每个块的消息认证码(MAC)和完整性树。
-
可用性:现有研究[5,43,59]提高了数据本身的可靠性,并探索了如何从错误中恢复。
但安全元数据中的错误(如计数器、MAC和树节点中的错误)会产生放大效应,严重影响数据可用性。存在纠错机制(如纠错码(ECC))的情况下,安全元数据可能会遇到不可纠正的错误(例如,由于硬件故障或恶意攻击)[42]。一些无法纠正的安全元数据错误可能会使大量数据无法验证。出于安全考虑,不可验证的数据会被丢弃,导致严重的数据丢失并降低数据可用性。
为了维护崩溃一致性,现有方法添加了额外的一致性元数据,如日志[51,56,60]和检查点[40,50],以原子方式更新一组数据。例如,用日志跟踪数据更新的信息,崩溃后回滚到原始版本或向前滚动到完全更新的版本。然而,一致性元数据错误对数据可用性有巨大影响。
以日志为例,存储在PM日志区域中的日志条目包含更新数据的地址,用于崩溃后定位数据区域中部分更新的数据,以恢复不一致。如果日志中出现错误,系统无法确定哪些数据被部分更新,数据区域中的所有数据的一致性都不可验证。类似于由于安全元数据错误而无法验证的数据,应丢弃可能不一致的数据,从而导致大量数据丢失。
现有方法未能同时实现有效性和效率。
-
类似于减轻安全元数据错误的放大效应[63],增加冗余(通过使用更强的ECC或维护副本)允许系统容忍更多错误,减少一致性元数据错误。但使用更强的ECC会增加内存访问延迟(高达21%[5]),而维护副本会将一致性元数据写入的数量增加数倍(日志的效率对日志写入的数量很敏感[23])。
-
将一致性元数据放置在安全区域内的非易失性缓冲区中(类似于[60,61])可以避免恶意攻击造成的无法纠正的错误。但一致性元数据大小受到缓冲区大小的限制,缓冲区也可能有错误(例如硬件故障)。
本文方法
本文发现了崩溃一致性错误放大(CCEA)问题,一致性元数据中的错误可能会使PM中的大部分数据不一致。通过缓解安全元数据错误的放大效应的方法是不够的,因为安全元数据通常是为单一目的而设计的(例如完整性验证),而一致性元数据是为多种目的而设计,包括不一致性定位和恢复。
本文提出了COVER,一种崩溃一致性验证方法,有效缓解CCEA问题。关键思路是,根据元数据的相对位置将元数据与数据相关联,可以在任意元数据错误的情况下实现不一致定位。从而保证一致性元数据错误后依旧可以定位数据。
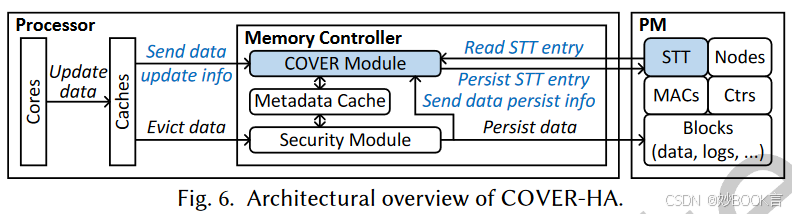
COVER通过解耦不一致定位和恢复来提高效率。添加了状态跟踪表(STT),负责在一致性元数据错误的情况下定位不一致。为了定位不一致,数据区域被划分为多个保管库(例如,块大小)。第1个STT条目跟踪第1个数据保管库的一致性状态,仅在状态发生变化时更新。跟踪更多的状态信息可以提供更高的不一致定位精度,但会产生更多的开销。提出了三种设计方案,在有效性和效率之间进行了不同的权衡。
-
方案1:效率较高,但有效性较低。数据更新通常包含在事务中,以确保一组数据可以从一个一致的状态更新到另一个状态。为了以低开销定位不一致,在每个STT条目中只放置1位更新标识,表示数据保管库是否已按事务进行更新。然而,在每次事务提交时重置更新标识会导致巨大的开销。为了获得更好的效率,会定期批量重置所有更新标识。并设计了一种动态切换方法,以避免在事务执行的关键路径中等待重置更新标识。
-
方案2:具有中等效率和中等有效性。在方案1中,一些一致的数据库可能被STT视为不一致,因为在提交过程中更新标识没有重置,导致假阳性不一致。在方案2中,STT跟踪事务信息,以指示哪些数据是由内联事务更新的,因为只有当数据被内联事务部分更新时,才会处于不一致的状态。事务提交后,其信息应从STT中删除。但遍历STT以查找和删除信息会带来巨大的性能开销,因此开发了延迟删除方法,首先在提交期间执行逻辑删除,然后在再次访问STT条目时执行物理删除。
-
方案3:效率较低,但有效性较高。在某些情况下,即使一致性元数据有几个不可纠正的错误,也可以恢复不一致的数据库。为了实现恢复,OPT3不仅跟踪事务信息,还跟踪STT中数据库的更新和持久状态。
实验结果表明,与最先进的安全PM设计相比,COVER有效地缓解了这一问题,采用OPT1、OPT2和OPT3的COVER平均产生1.0%、2.5%和4.4%的边际性能开销[18,60],一致性元数据错误导致的数据丢失量分别降低到SOTA设计的9.7×10−4%、2.1×10−4%和1.6×10−5%。
总结
针对PM系统的崩溃一致性问题,当用于维护崩溃一致性的元数据(日志、检查点)出现错误时,无法判断数据的一致性状态,因此需要丢弃大量不可验证的数据。本文提出COVER,关键思路是,关联元数据与数据的相对位置,在元数据错误的情况下实现数据定位,从而减少丢弃数据的数量。添加了状态跟踪表(STT),跟踪数据的一致性状态,仅在状态发生变化时更新(事务)。进一步提出3种跟踪策略:(1)仅跟踪数据块是否被事务更新,效率高但效果较弱。(2)跟踪事务信息,避免假阳性不一致,但引入更高的开销。(3)跟踪数据的更新与持久化状态,在错误情况下支持部分数据恢复,效果最佳但性能开销较大。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











