







目录
为什么Transformer可以做图像也可以做文本,为什么它适合做一个跨模态的任务?
前言
多模态融合Multimodal Fusion也称多源信息融合(Multi-source Information Fusion),多传感器融合(Multi-sensor Fusion)。多模态融合是指综合来自两个或多个模态的信息以进行预测的过程。在预测的过程中,单个模态通常不能包含产生精确预测结果所需的全部有效信息,多模态融合过程结合了来自两个或多个模态的信息,实现信息补充,拓宽输入数据所包含信息的覆盖范围,提升预测结果的精度,提高预测模型的鲁棒性。
目前已有的多模态图像融合模型很多采用自编码器结构,如下图 a。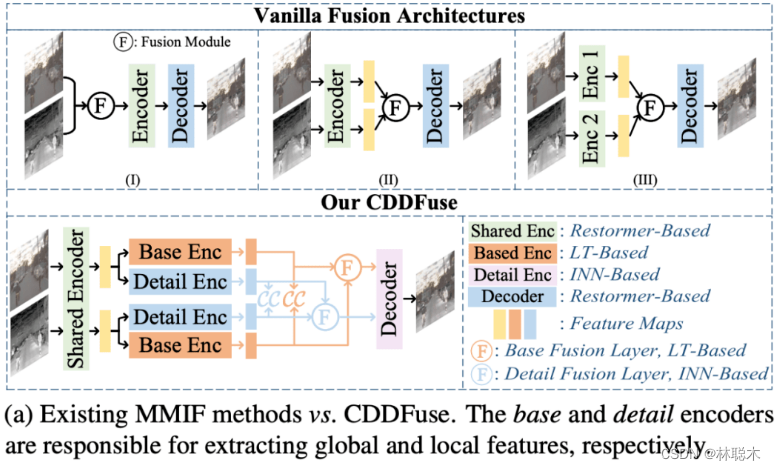
但是这种方式有三个缺陷:
1. CNN 的解释性较差,难以控制,对跨模态特征提取不够充分,如上图 a 前两种都是多模态输入共享编码器,因此难以提取到模态特有的特征,而第三种双分支结构则忽略了各个模态共有属性;
2. 上下文独立的 CNN 结构只能在相对小的感受野内

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











