







 本文详细介绍了Java中的三种内部类:静态内部类、成员内部类和局部内部类。静态内部类适用于构建嵌套对象,常用于Builder模式或隐藏复杂实现。成员内部类可以访问外部类的所有成员,并常用于实现设计模式,如集合框架中的迭代器。局部内部类,包括匿名内部类,通常用于一次性实现简单接口,要求访问的局部变量必须为final。理解这些内部类的特性和应用场景对于提升Java编程能力至关重要。
本文详细介绍了Java中的三种内部类:静态内部类、成员内部类和局部内部类。静态内部类适用于构建嵌套对象,常用于Builder模式或隐藏复杂实现。成员内部类可以访问外部类的所有成员,并常用于实现设计模式,如集合框架中的迭代器。局部内部类,包括匿名内部类,通常用于一次性实现简单接口,要求访问的局部变量必须为final。理解这些内部类的特性和应用场景对于提升Java编程能力至关重要。
1.内部类的种类:
静态内部类
成员内部类
局部内部类
2.1静态内部类
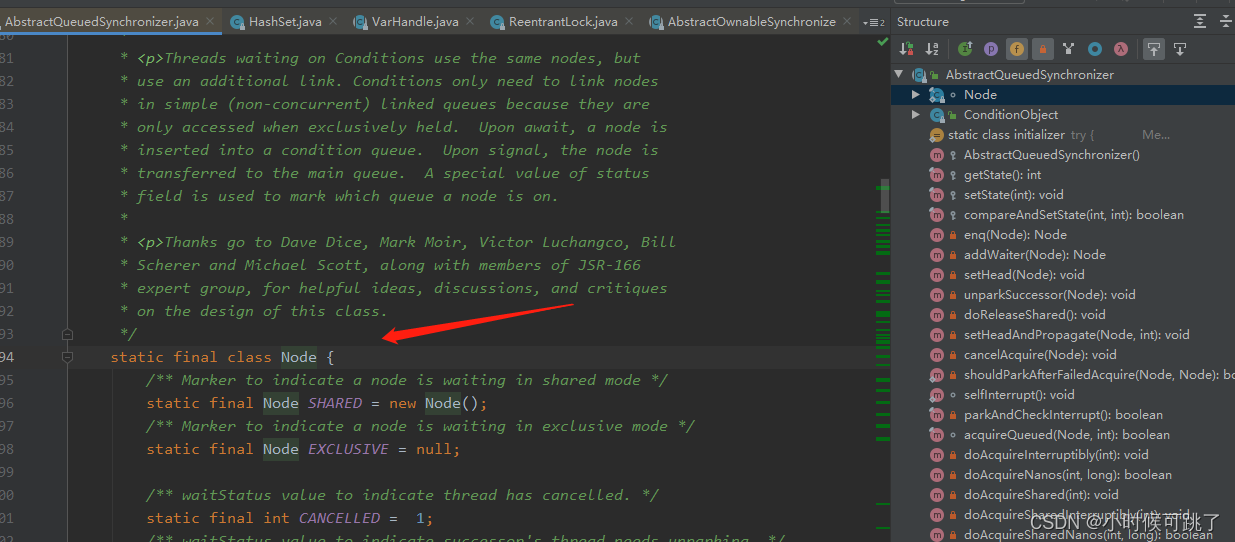
静态内部类其实差不多在一个类文件里创建另一个类,内部类对象不能访问外部类的成员变量,要创建该内部类还需要 new 外部类.内部类()的形式。
静态内部类作用:一般我们是builder模式或者一些数据接收的嵌套对象时会采用这种写法,或者我们代码中需要拆出来一个类有特别的功能但是又想对外影藏这些细节进行一个封装
2.2成员内部类
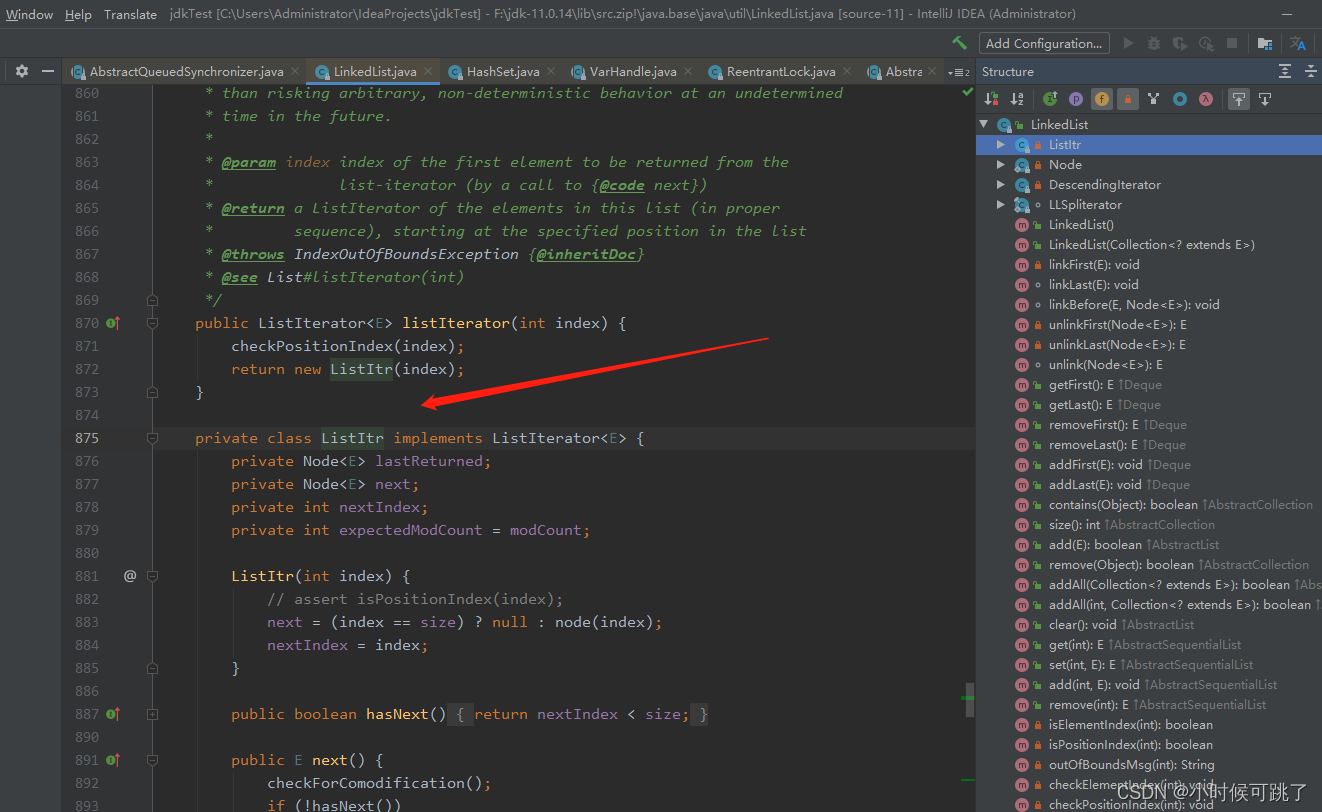
成员内部类其实是作为一个外部类的成员变量的形式,内部不能声明static的变量及方法,目前的看法都是说这只是javac编译器的限制,有待使用asm字节码技术生成二进制class文件做测试。另外语法层面上来说,内部类可以访问外部类所有变量,也可以通过外部类.this的形式访问外部对象
作用:从设计角度来看,成员内部类是继接口这种形式外丰富了java单继承在某些设计场景下的缺陷,我们可以采用内部类的形式来继承其他类的功能并组合到外部类中。JDK的集合源码中的迭代模式就是采用这种形式进行实现的
2.3局部内部类
匿名内部类
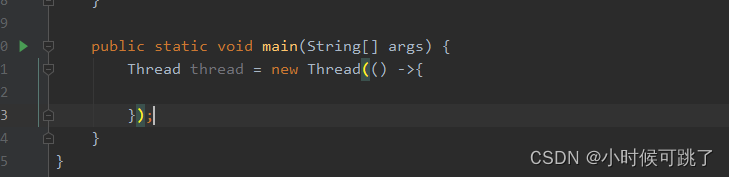
有时候我们的代码中,对于某些接口的实现类我们可能仅仅只使用一次,可以采用匿名内部类的形式来简化代码
有名内部类
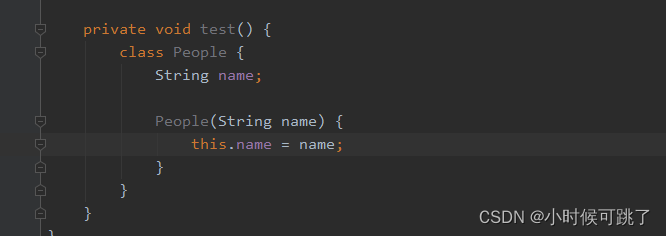
有名内部类的作用大多数就是用来重载构造器的,匿名内部类默认是使用无参构造器的方式。另外需要注意,局部内部类访问方法变量时必须时final修饰的,因为内部类对象是有可能逃逸到方法外,而局部变量只能在方法中,所以语法规定了只能访问final的变量,JVM会进行特殊处理

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









