







1.建表语句
CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE=InnoDB;
2.假设里面插入很多数据,现在需要查询
select city,name,age from t where city='杭州' order by name limit 100;
3.分析2的查询
explain select city,name,age from t where city='杭州' order by name limit 100;

using index condition,表示虽然触发了city的索引,但是因为没有索引覆盖,所以还必须通过主键id回表查询其他字段,
using filesort 表示使用排序,mysql会通过设置的sort_buff大小给每个线程在内存里进行排序
这里解释这段sql是如何执行的:
1.在sort_buff里生成列city,name,age
2.通过city索引找到主键id,在通过id回表查询获取name,age,填入记录
3.在进行下一个city的索引的主键Id,在回表查询填入记录
4.重复3步骤,直到查询条件不满足时,退出
5.在sort_buff中按照name进行快速排序
6.返回结果集

这种排序方式成为全字段排序,这里还存在一个问题,就是在sort_buff里排序的时候,如果当我们的数据量时大于sort_buffer_size设置的参数时,那么我们就没办法一次性在内存里进行排序完成,只能借助磁盘来辅助排序了。Mysql通过生成临时文件,然后在合并临时文件的方式来进行辅助排序。
mysql还在另一种排序方式:rowid排序。
这种排序是指当我们设置了 SET max_length_for_sort_data = 16参数时,即排序的数据里每一行的大小不能超过16B,如果超过了,比如上面我们的按照name排序,sort_buff里存的每一行记录时name,city,age。三个字段的大小已经超过16B了。所以这里必须更换排序算法:
1.在sort_buff内存了生成name,id两列
2.从索引city查找到主键id,然后回表获取name,id的值填入记录
3.下一条记录重复2操作,直到不满足条件为止
4.在sort_buff里按照name快速排序
5.在通过id,进行主键回表操作,获取name,age字段
6.返回结果集
如图:

通过rowid排序,可以明显的发现又多了一次回表的操作,所以Mysql在万不得已的情况下不会优先考虑这种排序算法的,
这里可以看出mysql的优化理论:在sort_buff足够的条件下,通过内存直接排序,减少磁盘的io!
那么这里假设我们不在程序里进行排序,那么如何让mysql帮我直接排序,而不使用上面那种排序算法呢?
还记得以前提到过的索引覆盖的理论嘛?当索引覆盖时,我们查询的时候就不需要回表了,而且索引都是拍好序的数据是可以直接返回的
那么这里我们直接将city,name,age设置位聚合索引,此时查询触发索引覆盖即可快速返回结果了
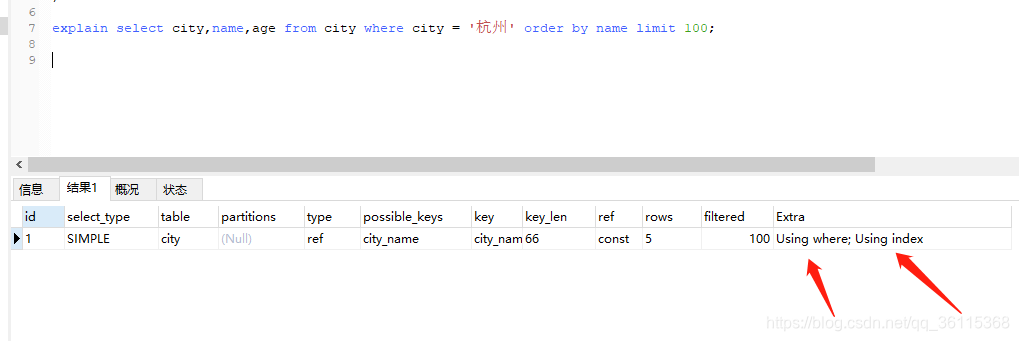
这里的Using index 就是表示索引覆盖了,所以我们没有看到前面的Using filesort!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









