







引入
逻辑回归是一种二分类算法,逻辑回归实质是去试图找出一个边界把样本空间一分为二,然后在不同的区域中就是不同的类别。
就如下面这张图,蓝色区域与黄色区域被一条直线分开。
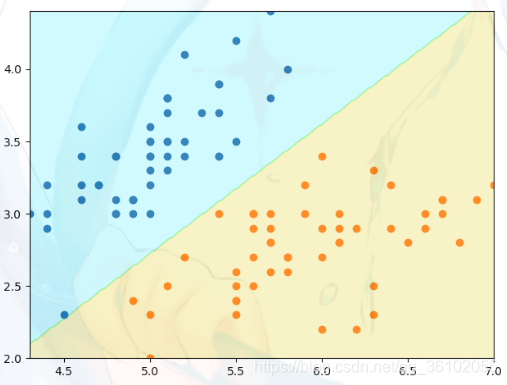
我们可以假设这条直线是,假设有样本
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
.
.
.
(
x
m
,
y
m
)
(\textbf{x}_1,y_1), (\textbf{x}_2,y_2)...(\textbf{x}_m,y_m)
(x1,y1),(x2,y2)...(xm,ym)
则我们想要找这个边界可以写成
y
=
x
T
θ
+
b
y=\textbf{x}^T\mathbf{ \theta}+b
y=xTθ+b
当把样本带入这个式子,如果y大于0就可以认为是一种类别,反之就是另一种类别。
但是上述式子算出来的值是连续的,而标记却是离散的,这样无法对应起来,所以此时就可以用后验概率来描述。
用
P
(
y
=
1
∣
x
)
P(y=1|\textbf{x})
P(y=1∣x)表示在
x
\textbf{x}
x的情况下为第一种类的概率
它的对立事件很明显就是
P
(
y
=
0
∣
x
)
P(y=0|\textbf{x})
P(y=0∣x)
当
P
(
y
=
1
∣
x
)
≥
0.5
P(y=1|\textbf{x}) \geq 0.5
P(y=1∣x)≥0.5时就可以认为是带入边界大于0的情况,反之就是小于0的情况。
此时就需要一个函数来把
x
T
θ
+
b
\textbf{x}^T\mathbf{ \theta}+b
xTθ+b的值和概率之间来对应起来了。
在逻辑回归中,采用的函数就是Sigmoid函数
S
i
g
m
o
i
d
(
t
)
=
1
1
+
e
−
t
Sigmoid(t)=\frac{1}{1+e^{-t}}
Sigmoid(t)=1+e−t1
当
t
≥
0
t \geq 0
t≥0时
y
≥
0.5
y \geq 0.5
y≥0.5很完美的就把
x
T
θ
+
b
\textbf{x}^T\mathbf{ \theta}+b
xTθ+b的值域映射到了概率的值域,把
x
T
θ
+
b
\textbf{x}^T\mathbf{ \theta}+b
xTθ+b带入得到
P
(
y
=
1
∣
x
)
=
1
1
+
e
−
(
x
T
θ
+
b
)
P(y=1|\textbf{x})=\frac{1}{1+e^{-(\textbf{x}^T\mathbf{ \theta}+b)}}
P(y=1∣x)=1+e−(xTθ+b)1
同样道理可以写出
P
(
y
=
0
∣
x
)
P(y=0|\textbf{x})
P(y=0∣x),只需要用1减去
P
(
y
=
1
∣
x
)
P(y=1|\textbf{x})
P(y=1∣x)
P
(
y
=
0
∣
x
)
=
e
−
(
x
T
θ
+
b
)
1
+
e
−
(
x
T
θ
+
b
)
P(y=0|\textbf{x})=\frac{e^{-(\textbf{x}^T\mathbf{ \theta}+b)}}{1+e^{-(\textbf{x}^T\mathbf{ \theta}+b)}}
P(y=0∣x)=1+e−(xTθ+b)e−(xTθ+b)
很明显,可以到这么一个函数函数。
Q
(
x
,
y
)
=
P
(
y
=
1
∣
x
)
y
∗
P
(
y
=
0
∣
x
)
1
−
y
Q(\textbf{x}, y)=P(y=1|\textbf{x})^y*P(y=0|\textbf{x})^{1-y}
Q(x,y)=P(y=1∣x)y∗P(y=0∣x)1−y
它的其实就是把上面两个概率结合了起来,可以发现在已经y确定时给出
x
,
\textbf{x},
x,Q函数就可以给出一个预测,显然,这个值预测越大也就越符合原来已经确定的y。
那么现在问题就是需要确定一个参数
θ
\theta
θ使
Q
Q
Q对所有样本的预测尽可能的准,也就是让Q尽可能的大。
这里就可以想到,这种想法与极大似然估计是不谋而合的,所以就可以使用极大似然估计法来确定这个
θ
\theta
θ。
设极大似然函数
L
(
θ
)
=
∏
i
=
1
m
Q
(
x
i
,
y
i
)
L(\theta)=\prod\limits_{i =1}^mQ(\textbf{x}_i, y_i)
L(θ)=i=1∏mQ(xi,yi)
为了方便将其求对数
l
n
(
L
(
θ
)
)
=
∑
i
=
1
m
l
n
[
Q
(
x
i
,
y
i
)
]
ln(L(\theta))=\sum\limits_{i =1}^mln[Q(\textbf{x}_i, y_i)]
ln(L(θ))=i=1∑mln[Q(xi,yi)]
把Q带入
l
n
(
L
(
θ
)
)
=
∑
i
=
1
m
y
∗
l
n
(
P
(
y
=
1
∣
x
i
)
)
∗
(
1
−
y
)
∗
l
n
(
P
(
y
=
0
∣
x
i
)
)
ln(L(\theta))=\sum\limits_{i =1}^my*ln(P(y=1|\textbf{x}_i)) * (1 - y)*ln(P(y=0|\textbf{x}_i))
ln(L(θ))=i=1∑my∗ln(P(y=1∣xi))∗(1−y)∗ln(P(y=0∣xi))
把
P
(
y
=
1
∣
x
)
,
P
(
y
=
0
∣
x
)
P(y=1|\textbf{x}),P(y=0|\textbf{x})
P(y=1∣x),P(y=0∣x)带入
l
n
(
L
(
θ
)
)
=
∑
i
=
1
m
y
∗
l
n
(
1
1
+
e
x
i
T
θ
+
b
)
∗
(
1
−
y
)
∗
l
n
(
e
x
i
T
θ
+
b
1
+
e
x
i
T
θ
+
b
)
ln(L(\theta))=\sum\limits_{i =1}^my*ln(\frac{1}{1 + e^{\textbf{x}_i^T\theta + b}}) * (1 - y)*ln(\frac{ e^{\textbf{x}_i^T\theta + b}}{1 + e^{\textbf{x}_i^T\theta + b}})
ln(L(θ))=i=1∑my∗ln(1+exiTθ+b1)∗(1−y)∗ln(1+exiTθ+bexiTθ+b)
整理合并得
l
n
(
L
(
θ
)
)
=
∑
i
=
1
m
y
∗
(
x
i
T
θ
+
b
)
+
l
n
(
1
−
S
i
g
m
o
i
d
(
x
i
T
θ
+
b
)
)
ln(L(\theta))=\sum\limits_{i =1}^my*(\textbf{x}_i^T\theta + b) +ln(1-Sigmoid(\textbf{x}_i^T\theta + b))
ln(L(θ))=i=1∑my∗(xiTθ+b)+ln(1−Sigmoid(xiTθ+b))
由于最大化
l
n
(
L
(
θ
)
)
ln(L(\theta))
ln(L(θ))相当于最小化
−
l
n
(
L
(
θ
)
)
-ln(L(\theta))
−ln(L(θ)),设
J
(
θ
)
=
−
1
m
l
n
(
L
(
θ
)
)
J(\theta)=-\frac{1}{m}ln(L(\theta))
J(θ)=−m1ln(L(θ))
得
J
(
θ
)
=
−
1
m
∑
i
=
1
m
y
∗
(
x
i
T
θ
+
b
)
+
l
n
(
1
−
S
i
g
m
o
i
d
(
x
i
T
θ
+
b
)
)
J(\theta)=-\frac{1}{m}\sum\limits_{i =1}^my*(\textbf{x}_i^T\theta + b) +ln(1-Sigmoid(\textbf{x}_i^T\theta + b))
J(θ)=−m1i=1∑my∗(xiTθ+b)+ln(1−Sigmoid(xiTθ+b))
想要使这个函数最大化只需要求偏导,然后使用梯度下降法,或者随机梯度下降法之类的方法就可以了(这个函数是一个单峰函数)
梯度下降法求解
使用梯度下降法就需要求出梯度,首先与线性回归一样,把样本增加一列属性用于和截距
b
b
b匹配,同时
J
(
θ
)
=
−
1
m
∑
i
=
1
m
y
∗
(
x
i
T
θ
)
+
l
n
(
1
−
S
i
g
m
o
i
d
(
x
i
T
θ
)
)
J(\theta)=-\frac{1}{m}\sum\limits_{i =1}^my*(\textbf{x}_i^T\theta) +ln(1-Sigmoid(\textbf{x}_i^T\theta))
J(θ)=−m1i=1∑my∗(xiTθ)+ln(1−Sigmoid(xiTθ))
然后对其求偏导。
∇
J
(
θ
)
=
(
∂
J
(
θ
)
∂
θ
0
∂
J
(
θ
)
∂
θ
1
.
.
.
∂
J
(
θ
)
∂
θ
n
)
\nabla J(\theta) = \begin{gathered} \begin{pmatrix} \frac{\partial J(\theta)}{\partial \theta_0}\\ \frac{\partial J(\theta)}{\partial \theta_1}\\ ...\\ \frac{\partial J(\theta)}{\partial \theta_n} \end{pmatrix} \quad \end{gathered}
∇J(θ)=⎝⎜⎜⎜⎛∂θ0∂J(θ)∂θ1∂J(θ)...∂θn∂J(θ)⎠⎟⎟⎟⎞
得
∇
J
(
θ
)
=
1
m
(
∑
i
=
1
m
X
0
(
i
)
(
S
i
g
m
o
i
d
(
X
(
i
)
θ
)
−
y
(
i
)
)
∑
i
=
1
m
X
1
(
i
)
(
S
i
g
m
o
i
d
(
X
(
i
)
θ
)
−
y
(
i
)
)
.
.
.
∑
i
=
1
m
X
n
(
i
)
(
S
i
g
m
o
i
d
(
X
(
i
)
θ
)
−
y
(
i
)
)
)
\nabla J(\theta) = \frac{1}{m}\begin{gathered} \begin{pmatrix} \sum\limits_{i = 1}^mX_0^{(i)}(Sigmoid(X^{(i)}\theta)-y^{(i)})\\ \sum\limits_{i = 1}^mX_1^{(i)}(Sigmoid(X^{(i)}\theta)-y^{(i)})\\ ...\\ \sum\limits_{i = 1}^mX_n^{(i)}(Sigmoid(X^{(i)}\theta)-y^{(i)}) \end{pmatrix} \quad \end{gathered}
∇J(θ)=m1⎝⎜⎜⎜⎜⎜⎜⎜⎛i=1∑mX0(i)(Sigmoid(X(i)θ)−y(i))i=1∑mX1(i)(Sigmoid(X(i)θ)−y(i))...i=1∑mXn(i)(Sigmoid(X(i)θ)−y(i))⎠⎟⎟⎟⎟⎟⎟⎟⎞
仿照线性回归的方式,上式也可以用矩阵乘法的方式写成
∇
J
(
θ
)
=
1
m
X
T
(
S
i
g
m
o
i
d
(
X
θ
)
−
y
)
\nabla J(\theta)=\frac{1}{m}X^T(Sigmoid(X\theta) -y)
∇J(θ)=m1XT(Sigmoid(Xθ)−y)
然后就可以numpy的矩阵乘法轻松地实现了。
决策边界
分类边界就是一开始所描绘的那种边界,逻辑回归在特征维数为2的时候分类边界就是一条直线。
使用matplotlib可以用一种很简单的方式绘制出这条边界。
def ShowBound(model, data, target, categories):
from matplotlib.colors import ListedColormap
axis = [np.min(data[:, 0]), np.max(data[:, 0]), np.min(data[:, 1]), np.max(data[:, 1])]
# 确定x轴与y轴的范围
lst = ListedColormap(['#98F5FF', '#54FF9F', '#EEE685'])
x, y = np.meshgrid(np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) / 0.01)),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) / 0.01)))
# 使用linspace方法划分坐标轴,并且用meshgrid方法生成对应的x与y矩阵
pre = np.c_[x.ravel(), y.ravel()]
# 把坐标组合起来
pre_target = model.predict(pre)
plt.contourf(x, y, pre_target.reshape(x.shape), alpha=0.5, cmap=lst)
# 绘制等高线
for i in range(categories):
plt.scatter(data[target == i][:, 0], data[target == i][:, 1])
plt.xlim(axis[0], axis[1])
plt.ylim(axis[2], axis[3])
首先导入sklearn的逻辑回归,与pipline,然后创建一个逻辑回归实例
from LogisticRegression import ShowBound
from sklearn.linear_model import LogisticRegression
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
log_reg = Pipeline([
('std', StandardScaler()),
('log', LogisticRegression())
])
然后导入鸢尾花数据集,只选择其两个特征以及两种类型。
iris = datasets.load_iris()
target = iris.target
data = iris.data[:, :2][target <= 1]
target = target[target <= 1]
然后使用写好的ShowBound就可以看边界了。
加入多项式特征
同样的道理,如果样本空间不是简简单单就可以使用线性划分的,就需要引入多项式特征了。
用随机数制造一个数据集,用双曲线的公加上一个噪音来创造一个有两个标记的数据集
np.random.seed(123)
data = np.random.random(size=(400, 2)) * 3
target = np.array(5 * (data[:, 0] - 1.5) ** 2 + np.random.random(size=data[:, 0].shape) * 2
<= 3 * (data[:, 1] - 1.5) ** 2, dtype='int')
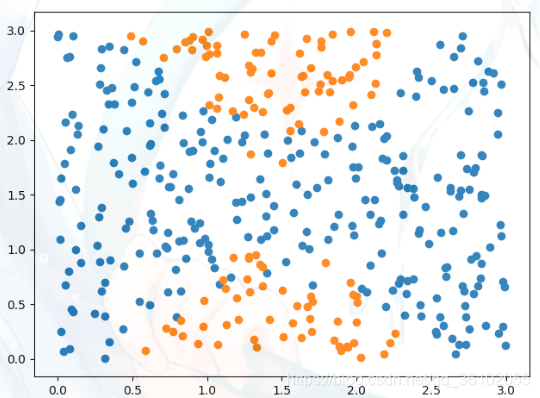
很显然这不具有线性关系,所以需要使用多项式武器~
log_reg = Pipeline([
('ploy', PolynomialFeatures(degree=2)),
('std', StandardScaler()),
('log', LogisticRegression())
])
使用多项式特征后再来看看边界。
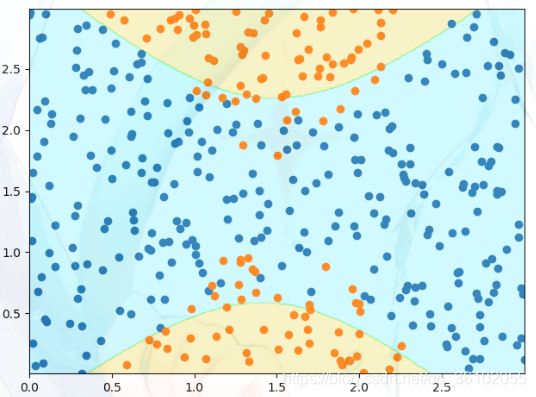
可以发现,它也比较好的划分出了界线。
模型正则化
逻辑回归也会出现过拟合的现象,而模型正则化就是结局这一问题的好方法。
正则化的方式包括L1正则化,L2正则化,弹性网等方法,sklearn的逻辑回归自带这些参数。
需要注意的是与LASSO和Ridge不同,sklearn的逻辑回归的惩罚系数是在损失函数上的
以L2正则化为例
J
(
θ
)
=
−
C
m
∑
i
=
1
m
y
∗
(
x
i
T
θ
)
+
l
n
(
1
−
S
i
g
m
o
i
d
(
x
i
T
θ
)
)
+
1
n
∑
i
=
1
n
θ
i
2
J(\theta)=-\frac{C}{m}\sum\limits_{i =1}^my*(\textbf{x}_i^T\theta) +ln(1-Sigmoid(\textbf{x}_i^T\theta)) + \frac{1}{n}\sum\limits_{i = 1}^n\theta_i^2
J(θ)=−mCi=1∑my∗(xiTθ)+ln(1−Sigmoid(xiTθ))+n1i=1∑nθi2
其中C就是惩罚的系数,他不在L2上了,而是翻了过来,此时C越大惩罚反而越低,C越小惩罚反而越高,查看sklearn的文档,里面的逻辑回归默认使用L2正则化,C默认值是1
把degree调到25,并且降低惩罚
log_reg = Pipeline([
('ploy', PolynomialFeatures(degree=30)),
('std', StandardScaler()),
('log', LogisticRegression(C=1e15))
])
log_reg.fit(data, target)
ShowBound(log_reg, data, target, 2)
plt.show()
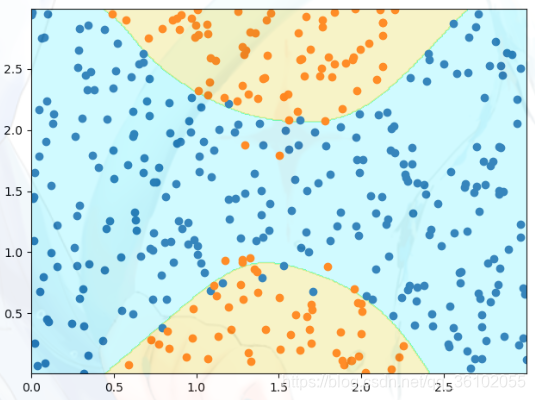
可以发现出现了过拟合现象,上下的决策边界变得不对称不规则。
尝试调小C的值
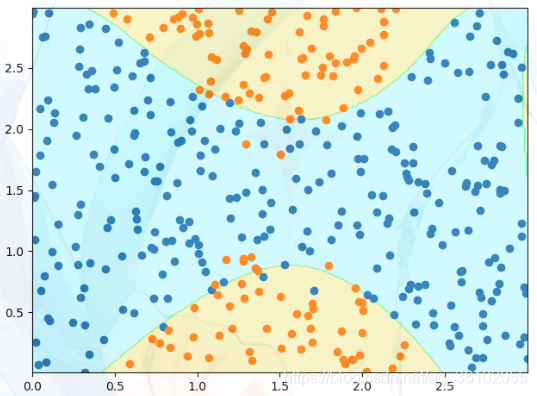
可以发现先,上下的数据又变得规则起来。
也可以调整LogisticRegression的参数来使用L1正则化和弹性网。
OVO与OVR
逻辑回归本身只支持二分类,但是可以通过一些改造使其支持多分类。
其中有OVO与OVR
OVR
OVR就是one vs rest
假设有4个类别,用四种不同颜色表示
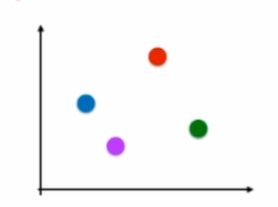
那么OVR的想法就是拿出其中一个类别,与剩下的三种类别组成一个二分类问题。
很明显的,这样可以构成4种二分类,对于一个新来的样本,可以依次在每种二分类去预测一下属于哪一种,最终选择概率最高的那一个。
OVO
OVO的全程就是one vs one。
OVO的思路就是每次选出两个种类对其进行训练,然后对于新来的数据判断其属于哪一个种类。
最后进行一个投票,把新来的种类归为投票数最高的一个种类。
假设一共有n个种类则有
C
n
2
C_n^2
Cn2中划分,其复杂度明显高于OVR
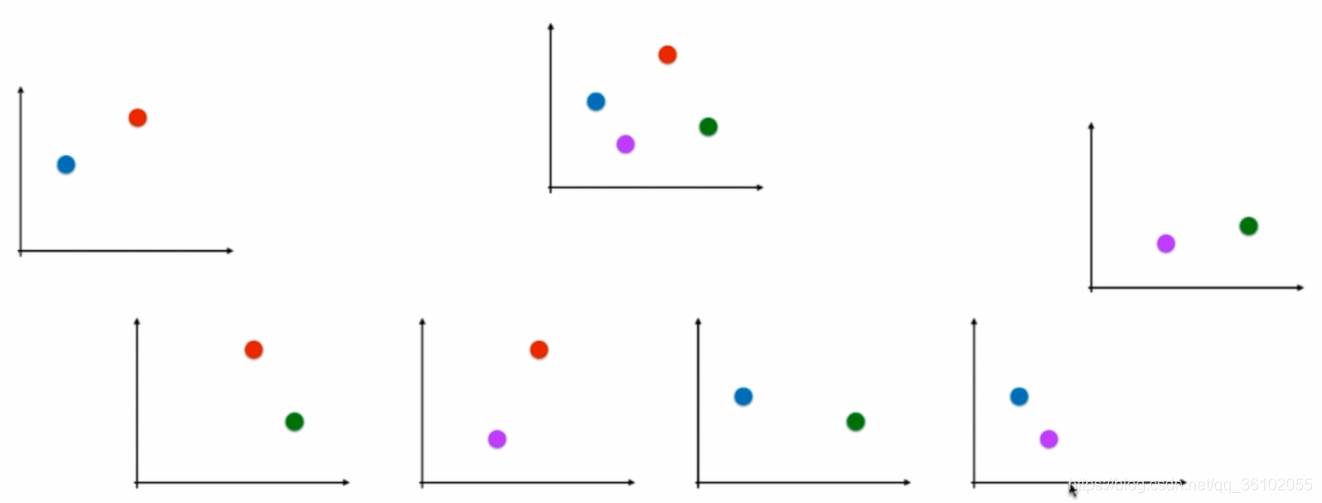
sklearn中的LogisticRegression中自带了这两种方法。
def __init__(self, penalty='l2', dual=False, tol=1e-4, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False, n_jobs=1):
其中可以看出默认方式是OVR,如果想要使用OVO则需要调整multi_class=‘multinomial’。
同时把solver改成‘lbfgs’或者‘sag’ 或者 ‘newton-cg’。
就可以使用OVO了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









