分析下面的代码 :#!/usr/bin/env python
# coding: utf-8
# # AIMET Quantization workflow for LLaMA V2 7B with LORA adapters using PEFT pipeline
#
# This notebook shows a working code example of how to use AIMET to quantize LLaMaV2 model.
#
# ---
# ### Required packages
# The notebook assumes AIMET and LLamaV2 related packages are already installed.
# In[ ]:
# #### Overall flow
# This notebook covers the following
# 1. Top Level Config
# 1. Model Adaptation.
# 1. Model Sample Input
# 1. Base BERT MHA FP Model Instantiation
# 1. Loading LORA Adapter on base Bert MHA Model
# 1. Adapted BERT MHA Model Preparation
# 1. Adapted BERT MHA Model Quantization with PEFT pipeline
# 1. Base KV MHA FP Model Instantiation
# 1. Loading LORA Adapter on base KV MHA Model
# 1. Adapted KV MHA FP Model Preparation
# 1. Create Adapted KVcache MHA Quantsim and Apply Encodings from Adapted BERT MHA Model
# 1. Export onnx and encodings
#
#
# #### What this notebook is not
# * This notebook is not intended to show the full scope of optimization. For example, the flow will not use QAT, KD-QAT as deliberate choice to have the notebook execute more quickly.
# In[2]:
get_ipython().run_line_magic('load_ext', 'autoreload')
get_ipython().run_line_magic('autoreload', '2')
# In[1]:
# Install packages only if running in jupyter notebook mode
if hasattr(__builtins__,'__IPYTHON__'):
get_ipython().system('sudo -H pip install --quiet --upgrade --root-user-action=ignore --no-cache-dir transformers==4.41.2,')
get_ipython().system('sudo -H pip install --quiet --upgrade --root-user-action=ignore --no-cache-dir tokenizers==0.19.0,')
# !sudo -H pip install --quiet --upgrade --root-user-action=ignore --no-cache-dir transformers==4.27.4,
# !sudo -H pip install --quiet --upgrade --root-user-action=ignore --no-cache-dir tokenizers==0.13.0,
get_ipython().system('sudo -H pip install --quiet --upgrade --root-user-action=ignore --no-cache-dir peft')
get_ipython().system('sudo -H apt-get update')
get_ipython().system('sudo -H apt-get install -y libc++-dev')
get_ipython().system('sudo -H apt-get install -y clang')
# In[1]:
import transformers
print (transformers.__version__)
# In[2]:
get_ipython().system('sudo -H pip install --quiet --upgrade --root-user-action=ignore --no-cache-dir transformers==4.41.2,')
get_ipython().system('sudo -H pip install --quiet --upgrade --root-user-action=ignore --no-cache-dir tokenizers==0.19.0,')
# #### Setup QNN SDK
# In[14]:
import sys
import os
QNN_SDK_ROOT = '/tmp/qnn/2.28.0.241029' # QNN 2.28.0
sys.path.insert(0, QNN_SDK_ROOT + '/lib/python')
os.environ['LD_LIBRARY_PATH'] = os.path.join(QNN_SDK_ROOT + '/lib/x86_64-linux-clang', os.getenv('LD_LIBRARY_PATH', ''))
# In[15]:
import qti
#checking if correct QNN version is loaded
print(qti.__path__)
# ### Setting NSP Target
# In[3]:
sys.path.append(os.path.abspath('../'))
sys.path.append(os.path.abspath('../../common'))
from utilities.nsptargets import NspTargets
# Android GEN4 is supported for this notebook
nsp_target = NspTargets.Android.GEN4
# Select quantsim config based on target
# Point this to different path if AIMET install in path other than /usr/local/lib/python3.10/dist-packages/
htp_config_file = f'/usr/local/lib/python3.10/dist-packages/aimet_common/quantsim_config/htp_quantsim_config_{nsp_target.dsp_arch}.json'
# ---
# ## 1. Top Level Config
#
# In[11]:
import os, sys
from tqdm import tqdm
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
import torch
from transformers import AutoConfig, AutoTokenizer, default_data_collator
cache_dir='./cache_dir'
output_dir = './32layer_test'
os.makedirs(cache_dir, exist_ok=True)
os.makedirs(output_dir, exist_ok=True)
device = "cuda"
# Auto-regression length: number of tokens to consume and number of logits to produce.
ARN=73
# model_id="<path_to_model_weight> or <HF_model_id(meta-llama/Llama-2-7b-hf)>"
model_id="/002data/kraus/projects/LLM/qualcomm_llama/model/Step-1/7b_chat/"
num_hidden_layers = 32 #configurable to less number for debugging purposes
context_length = 4096
# adatper dictionary name to peft_id
lora_adapter_dict={'french':'kaitchup/Llama-2-7b-mt-French-to-English',
'oasst': 'kaitchup/Llama-2-7B-oasstguanaco-adapter'}
lora_adapter_dict={'french':'french',
'oasst': 'oasst'}
# ---
#
# ## 2. Model Adaptations
# The following model adaptation are enabled for inference using provided modeling_llama.py:
# * Use 2D attention_mask
# * Replace position ids with embedding
# * Output new KV only
#
# The following adaptation is enabled using in place replacement utility function
# * Convert linear to conv
# In[5]:
from transformers.models.llama import modeling_llama
from transformers import cache_utils
from aimet_utils.linear_to_conv import replace_linears_with_convs
from aimet_torch.pro.utils.profiler import event_marker
from qcllama_adaptation import (
QcLlamaAttention,
bypass_update_causal_mask,
DynamicCache_update,
DynamicCache_get_seq_length,
update_attr
)
with event_marker("FP model adaptation configuration"):
modeling_llama.LLAMA_ATTENTION_CLASSES['eager'] = QcLlamaAttention
# Bypass attention_mask preparation
assert update_attr(modeling_llama.LlamaModel, '_update_causal_mask', bypass_update_causal_mask) or \
update_attr(modeling_llama.LlamaModel, '_prepare_decoder_attention_mask', bypass_update_causal_mask), \
f"neither _prepare_decoder_attention_mask(..) nor _update_causal_mask(..) found, Unknown LlamaModel definition in {modeling_llama.__file__}"
# Adapting KV$ management
assert update_attr(cache_utils.DynamicCache, 'update', DynamicCache_update), f"Unknown DynamicCache definition: {cache_utils.DynamicCache}"
assert update_attr(cache_utils.DynamicCache, 'get_seq_length', DynamicCache_get_seq_length), f"Unknown DynamicCache definition: {cache_utils.DynamicCache}"
# In[6]:
import qcllama_adaptation
print(qcllama_adaptation.__file__)
# In[7]:
from transformers.models.deprecated.open_llama import modeling_open_llama
from transformers import cache_utils
from aimet_utils.linear_to_conv import replace_linears_with_convs
from aimet_torch.pro.utils.profiler import event_marker
from qcllama_adaptation import (
QcLlamaAttention,
bypass_update_causal_mask,
DynamicCache_update,
DynamicCache_get_seq_length,
update_attr
)
with event_marker("FP model adaptation configuration"):
modeling_llama.LLAMA_ATTENTION_CLASSES['eager'] = QcLlamaAttention
# Bypass attention_mask preparation
assert update_attr(modeling_llama.LlamaModel, '_update_causal_mask', bypass_update_causal_mask) or \
update_attr(modeling_llama.LlamaModel, '_prepare_decoder_attention_mask', bypass_update_causal_mask), \
f"neither _prepare_decoder_attention_mask(..) nor _update_causal_mask(..) found, Unknown LlamaModel definition in {modeling_llama.__file__}"
# Adapting KV$ management
assert update_attr(cache_utils.DynamicCache, 'update', DynamicCache_update), f"Unknown DynamicCache definition: {cache_utils.DynamicCache}"
assert update_attr(cache_utils.DynamicCache, 'get_seq_length', DynamicCache_get_seq_length), f"Unknown DynamicCache definition: {cache_utils.DynamicCache}"
# ---
# ## 3. Model Sample Input
# #### Dummy input
#
# In[8]:
from forward_pass_wrapper import get_position_embeddings_from_position_ids, prepare_combined_attention_mask, get_padded_kv_values, flatten_tensors
def get_dummy_data(model_mode, num_layers, hidden_size, num_attention_heads, rope_theta, tokenizer, device, separate_tuple_input_output, num_tokens=None, concat_head_in_batch_dimension=False):
max_tokens = tokenizer.model_max_length
attention_mask = torch.ones((1, max_tokens), dtype=torch.long, device=device)
if model_mode == 'bertcache':
num_tokens = max_tokens
position_ids = torch.cumsum(attention_mask, dim=1) - 1
position_ids = position_ids.clip(0, max_tokens - 1)
position_ids = position_ids[..., :num_tokens]
position_ids = position_ids.to(device=device)
past_kv_length = max_tokens - num_tokens if model_mode == 'kvcache' else 0
attention_mask = prepare_combined_attention_mask(attention_mask, input_shape=(1, num_tokens),
past_key_values_length=past_kv_length, device=device,
mask_neg=-100)
position_ids = get_position_embeddings_from_position_ids(position_ids,
head_dim=hidden_size//num_attention_heads,
max_length=max_tokens,
rope_theta=rope_theta,
device=device)
inputs = {
'attention_mask': attention_mask,
'position_ids': position_ids,
'input_ids': torch.randint(0, len(tokenizer), (1, num_tokens), device=device)
}
if model_mode == 'kvcache':
inputs['past_key_values'] = get_padded_kv_values(past_size=max_tokens - num_tokens,
num_layers=num_layers,
hidden_size=hidden_size,
concat_head_in_batch_dimension=concat_head_in_batch_dimension,
num_attention_heads=num_attention_heads,
device=device)
if separate_tuple_input_output:
flattened_kvcache = tuple(flatten_tensors(inputs['past_key_values']))
inputs = inputs['input_ids'], inputs['attention_mask'], inputs['position_ids'][0], inputs['position_ids'][1]
inputs = inputs + flattened_kvcache
else:
if separate_tuple_input_output:
inputs = inputs['input_ids'], inputs['attention_mask'], inputs['position_ids'][0], inputs['position_ids'][1]
return inputs
# #### Input and Output names
# In[9]:
def get_input_output_names(num_layers, past_key_values_in, separate_tuple_input_output):
def _get_past_key_values_names(sfx, n_layers):
all = []
for i in range(n_layers):
all.append(f'past_key_{i}_{sfx}')
all.append(f'past_value_{i}_{sfx}')
return all
output_names = ['logits']
input_names = ['input_ids', 'attention_mask']
if separate_tuple_input_output:
output_names += _get_past_key_values_names('out', num_layers)
input_names += ['position_ids_cos', 'position_ids_sin']
if past_key_values_in:
input_names += _get_past_key_values_names('in', num_layers)
else:
output_names += ['past_key_values']
input_names += ['position_ids']
if past_key_values_in:
input_names += ['past_key_values']
return input_names, output_names
# ### 4. Base BERT MHA FP Model Instantiation
#
# In[ ]:
# In[12]:
llm_config = AutoConfig.from_pretrained(model_id, cache_dir=cache_dir, trust_remote_code=True)
# model params
llm_config.num_hidden_layers = num_hidden_layers
llm_config.cache_dir = cache_dir
llm_config.device = torch.device('cpu')
# QC LLM model config
setattr(llm_config, 'mask_neg', -100)
setattr(llm_config, 'num_logits_to_return', 0)
setattr(llm_config, 'return_top_k', 0)
setattr(llm_config, "use_conv", False)
setattr(llm_config, 'return_new_key_value_only', True)
setattr(llm_config, 'transposed_key_cache', True)
setattr(llm_config, 'use_combined_mask_input', True)
setattr(llm_config, 'use_position_embedding_input', True)
setattr(llm_config, 'separate_tuple_input_output', False)
setattr(llm_config, '_attn_implementation', 'eager')
setattr(llm_config, '_attn_implementation_internal', 'eager')
print(f'num_layer: {llm_config.num_hidden_layers}, context_length: {context_length}')
with event_marker('BERT MHA FP model'):
fp_base_model = modeling_llama.LlamaForCausalLM.from_pretrained(model_id, config=llm_config)
os.environ['TOKENIZERS_PARALLELISM'] = '0'
tokenizer = AutoTokenizer.from_pretrained(model_id, cache_dir=cache_dir, use_fast=True, trust_remote_code=True)
## Adjust the tokenizer to limit to context length
tokenizer.model_max_length = context_length
# ### 5. Loading LORA Adapters on Base Bert MHA Model
# In[13]:
# loading adapter to Bert MHA model and save adapter weights
from peft import PeftModel,PeftConfig,LoraConfig
from aimet_torch.peft import replace_lora_layers_with_quantizable_layers,track_lora_meta_data
from lora_utils import save_lora_weights_after_adaptation
from aimet_utils.linear_to_conv import replace_linears_with_convs
from aimet_utils.linear_to_conv import ConvInplaceLinear
import copy
# Adding dummy adapter for q_proj, k_proj, v_proj and combined adapters into one adapter
k_v_lora_config = LoraConfig(
r=16,
lora_alpha=16,
bias='none',
target_modules=["q_proj","k_proj", "v_proj"],
init_lora_weights=False # leads to random init not zeros
)
for adapter_name,peft_model_id in lora_adapter_dict.items():
model_before_adapter = copy.deepcopy(fp_base_model)
print (f"=====loading adapter {adapter_name}====")
lora_model = PeftModel.from_pretrained(model_before_adapter, peft_model_id, adapter_name=adapter_name)
dummy_adapter_name = "k_v_adapter"
lora_model.add_adapter(dummy_adapter_name, k_v_lora_config)
for name, param in lora_model.named_parameters():
if dummy_adapter_name in name and "lora" in name:
param.data.fill_(0.0)
combined_adapter_name = "combined_adapter"
lora_model.add_weighted_adapter(
adapters=[adapter_name, dummy_adapter_name],
weights=[1.0, 1.0],
adapter_name=combined_adapter_name,
combination_type="linear"
)
lora_model.set_adapter(combined_adapter_name)
lora_model.delete_adapter(adapter_name)
lora_model.delete_adapter(dummy_adapter_name)
# Replace lora layers with quantizable layers
replace_lora_layers_with_quantizable_layers(lora_model)
# Linear to Conv model adaptation
lora_model=replace_linears_with_convs(lora_model)
# Save adapter weights after adaptation
save_lora_weights_after_adaptation(lora_model, output_dir, adapter_name)
del model_before_adapter
del fp_base_model
track_lora_meta_data(lora_model, output_dir, 'meta_data', ConvInplaceLinear)
# In[14]:
# fill lora layers with 0 to evaluate base model
for name, param in lora_model.named_parameters():
if 'lora' in name:
param.data.fill_(0.0)
# #### 5.1 Adapted BERT MHA Model Evaluation
#
# In[15]:
# defining ppl evaluation function
from torch.nn import CrossEntropyLoss
bert_mha_fp_model=lora_model.base_model.model
def bert_ppl_eval(data_loader, forward_pass_manager, num_batches=0):
if num_batches == 0:
num_batches = len(data_loader)
loss = 0
for batch_id, batch in enumerate(tqdm(data_loader, total=num_batches, desc="Evaluating")):
if batch_id >= num_batches:
break
outputs = forward_pass_manager(**batch)
lm_logits = outputs["lm_logits"].cpu()
# we can either pass input_ids or input_embeds in our fpm, hence with input_embeds we pass the labels.
if 'input_ids' not in batch:
batch['input_ids'] = batch['labels']
lm_logits = lm_logits.reshape(batch['input_ids'].shape[0], -1, lm_logits.shape[-1])
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = batch['input_ids'][..., 1:].contiguous().to(shift_logits.device)
loss_fct = CrossEntropyLoss()
loss += loss_fct(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1),
)
loss = loss / num_batches
ppl = loss.exp()
return ppl
# In[ ]:
from forward_pass_wrapper import LLMForwardPassManager
orig_fpm = LLMForwardPassManager(cfg=llm_config,
model=bert_mha_fp_model,
tokenizer=tokenizer,
model_mode='bertcache',
num_logits_to_return=0,
separate_tuple_input_output=False)
input_names, output_names = get_input_output_names(num_layers=llm_config.num_hidden_layers, past_key_values_in=False,
separate_tuple_input_output=False)
from wikitext_dataloader import get_wiki_dataset
train_dataloader, test_dataloader, _ = get_wiki_dataset(context_length,
tokenizer, cache_dir,
train_batch_size = 1,
test_batch_size = 1)
with event_marker("BERT MHA FP eval"):
with torch.no_grad():
with orig_fpm.place_on_device(device):
orig_ppl = bert_ppl_eval(test_dataloader, orig_fpm)
print(f"ppl score of original BERT MHA fp model: {orig_ppl}")
# ### 6. Adapted BERT MHA Model Preparation
# #### Estimated running time: ~ 1h 20m
# In[13]:
import aimet_torch.pro.ir_graph_op_handler as ir_graph_op_handler
from aimet_torch.pro import model_preparer
# Setting this flag to False means that the prepared model will be flattened
# This flag must be set to false because we rely on the model structure being flat to enable weight sharing
ir_graph_op_handler.KEEP_ORIGINAL_MODEL_STRUCTURE = False
# configuring the model for BERT mode
bert_mha_fp_model.num_logits_to_return = 0
dummy_input = get_dummy_data('bertcache', llm_config.num_hidden_layers,
llm_config.hidden_size, llm_config.num_attention_heads,
llm_config.rope_theta, tokenizer, 'cpu',
separate_tuple_input_output=False)
input_names, output_names = get_input_output_names(num_layers=llm_config.num_hidden_layers,
past_key_values_in=False,
separate_tuple_input_output=True)
converter_args_param = ['--input_layout']
converter_args_value = 'NONTRIVIAL'
converter_args = []
for input_param in converter_args_param:
for input_name in input_names:
converter_args += [input_param, input_name, converter_args_value]
with event_marker("BERT MHA Model prepare", flush_ram=True):
bert_mha_prepared_model = model_preparer.prepare_model(bert_mha_fp_model,
dummy_input,
filename="bert_mha_prepared_model",
path=output_dir,
input_names=input_names,
output_names=output_names,
converter_args=converter_args,
skipped_optimizers=['eliminate_common_subexpression','eliminate_nop_with_unit', 'eliminate_duplicate_initializer'],
)
# In[ ]:
del orig_fpm
del bert_mha_fp_model
# #### 6.1 Adapted BERT MHA Prepared Model Verification
# Verify if prepared BERT model generates the same PPL as FP model
# ##### Estimated running time: ~ 3m
# In[17]:
from aimet_torch.utils import load_pytorch_model
# Load prepared model if prepartion is run before and prepared model can be retrived from filer path
# # bert_mha_prepared_model = load_pytorch_model(path=output_dir, filename="bert_mha_prepared_model",
# # model_name='ConvertedModel', load_state_dict=True)
# Calculate ppl score for prepared fp model
bert_mha_fpm = LLMForwardPassManager(cfg=llm_config,
model=bert_mha_prepared_model,
tokenizer=tokenizer,
model_mode='bertcache',
num_logits_to_return=0,
separate_tuple_input_output=True)
with event_marker("BERT MHA Prepared FP eval"):
with torch.no_grad():
with bert_mha_fpm.place_on_device(device):
prepared_bertcache_ppl = bert_ppl_eval(test_dataloader, bert_mha_fpm)
print(f"ppl score of BERT prepared fp model: {prepared_bertcache_ppl}\n"
f"orig ppl - prepared ppl = {orig_ppl - prepared_bertcache_ppl}")
# ### 7. Adapted BERT MHA Model Quantization with PEFT pipeline
#
# We will be executing PTQ using calibration data that was captured earlier
# #### Create Quantsim
# In[16]:
from aimet_common.defs import QuantScheme
from aimet_torch.v2.quantsim import QuantizationSimModel
dummy_input = get_dummy_data('bertcache', llm_config.num_hidden_layers, llm_config.hidden_size, llm_config.num_attention_heads,
llm_config.rope_theta, tokenizer, device, separate_tuple_input_output=True)
with event_marker("create Quantsim", flush_ram=True):
with bert_mha_fpm.place_on_device(device):
quant_sim = QuantizationSimModel(model=bert_mha_fpm.model,
quant_scheme=QuantScheme.post_training_tf,
dummy_input=dummy_input,
default_output_bw=16,
default_param_bw=4,
in_place=False,
config_file=htp_config_file)
quant_sim.model.to('cpu')
# In[43]:
### Setting 16*8 matmuls
from aimet_torch.v2.experimental.quantsim_utils import set_matmul_second_input_producer_to_8bit_symmetric
set_matmul_second_input_producer_to_8bit_symmetric(quant_sim)
# #### Manual Mixed Precision
# In[44]:
from mixed_precision_overrides import ManualQuantsimMixedPrecisionConfig
with event_marker("Apply Mixed Precision", flush_ram=True):
quantsim_adjuster = ManualQuantsimMixedPrecisionConfig(mixed_precision_config_file= "./config/mixed_precision_profiles/w4_a16_exceptions_llama_v2_prepared_disableRMSNorm_clampgateprojconv_bundledkv.json")
quantsim_adjuster.apply_exceptions(quant_sim)
# #### Instantiation of PEFT utils
# In[30]:
import pickle,json
from aimet_torch.peft import PeftQuantUtils
from aimet_torch.v2.quantization.affine import QuantizeDequantize
with open(os.path.join(output_dir,'meta_data.pkl'), "rb") as f:
meta_data_file = pickle.load(f)
with open(os.path.join(output_dir,'bert_mha_prepared_model.json')) as f:
name_to_module_dict = json.load(f)
peft_utils = PeftQuantUtils(adapater_name_to_meta_data=meta_data_file, name_to_module_dict=name_to_module_dict)
# #### Sequential MSE
# ##### Estimated running time: ~ 1h 20m
# In[46]:
from aimet_torch.v2.seq_mse import apply_seq_mse
from aimet_torch.seq_mse import SeqMseParams
from aimet_torch.utils import load_pytorch_model
# Load prepared model if prepartion is run before and prepared model can be retrived from filer path
# # bert_mha_prepared_model = load_pytorch_model(path=output_dir, filename="bert_mha_prepared_model",
# # model_name='ConvertedModel', load_state_dict=True)
lora_layers =[layer for name,layer in peft_utils.get_fp_lora_layer(bert_mha_prepared_model)]
def _forward_fn(model, inputs):
prepared_inputs, _ = bert_mha_fpm.prepare_inputs(**inputs) if model == bert_mha_fpm.model else bert_mha_fpm.prepare_inputs(**inputs)
model(**prepared_inputs)
params = SeqMseParams(num_batches=20,
inp_symmetry="symqt",
num_candidates=20,
loss_fn="mse",
forward_fn=_forward_fn)
bert_mha_sim_fpm = LLMForwardPassManager(cfg=llm_config,
model=quant_sim.model,
tokenizer=tokenizer,
model_mode='bertcache',
num_logits_to_return=0,
separate_tuple_input_output=True)
with event_marker("SeqMSE"):
with bert_mha_fpm.place_on_device("cuda"),bert_mha_sim_fpm.place_on_device("cuda"):
apply_seq_mse(bert_mha_fpm.model, quant_sim, train_dataloader, params, modules_to_exclude=lora_layers)
quant_sim.save_encodings_to_json(output_dir, 'base_seqmse')
# #### Concat Encoding Unification
# In[47]:
from aimet_torch.v2.experimental import propagate_output_encodings
import aimet_torch.elementwise_ops as aimet_ops
propagate_output_encodings(quant_sim, aimet_ops.Concat)
# #### Setup Lora Layer to 16 bit per tensor
# In[48]:
## do this if changing for lora layers
for _,module in peft_utils.get_quantized_lora_layer(quant_sim):
# setting 16 bit per tensor
module.param_quantizers['weight'] = QuantizeDequantize(shape=(1, 1, 1, 1), bitwidth=16, symmetric=True).to(module.weight.device)
peft_utils.quantize_lora_scale_with_fixed_range(quant_sim, 16, 0.0, 1.0)
peft_utils.disable_lora_adapters(quant_sim)
# #### Calibration
# ##### Estimated running time: ~ 5m
# In[49]:
def calibration_wrapper(model, kwargs):
data_loader = kwargs['data_loader']
fpm = kwargs['fpm']
max_iterations = kwargs['num_batches']
for batch_id, batch in enumerate(tqdm(data_loader)):
if batch_id < max_iterations:
prepared_inputs, _ = fpm.prepare_inputs(**batch)
model(**prepared_inputs)
else:
break
kwargs = {
'data_loader': train_dataloader,
'fpm': bert_mha_sim_fpm,
'num_batches': 100
}
with event_marker("compute encoding for base", flush_ram=True):
with bert_mha_sim_fpm.place_on_device(device):
quant_sim.compute_encodings(calibration_wrapper, kwargs)
from global_encoding_clipper import clamp_activation_encodings
clamp_activation_encodings(quant_sim,500)
# #### Adapted BERT MHA Quantsim Eval for Quantization Accuracy
# ##### Estimated running time: ~7m
# In[50]:
with event_marker("Sim eval for base"):
with torch.no_grad():
with bert_mha_sim_fpm.place_on_device(device):
sim_ppl = bert_ppl_eval(test_dataloader, bert_mha_sim_fpm)
print(f"ppl score of quantsim model: {sim_ppl}\n"
f"orig ppl - quantsim ppl = {orig_ppl - sim_ppl}")
quant_sim.save_encodings_to_json(output_dir, 'base_encoding')
# #### Load Adapter Weights, Compute Encodings and Save Encodings
# ##### Estimated running time: ~ 25m
# In[51]:
peft_utils.freeze_base_model_param_quantizers(quant_sim)
for adapter_name,peft_model_id in lora_adapter_dict.items():
peft_utils.enable_adapter_and_load_weights(quant_sim,os.path.join(output_dir,f'{adapter_name}.safetensor'))
with event_marker(f"compute encoding for {adapter_name} adapter", flush_ram=True):
with bert_mha_sim_fpm.place_on_device(device):
quant_sim.compute_encodings(calibration_wrapper, kwargs)
from global_encoding_clipper import clamp_activation_encodings
clamp_activation_encodings(quant_sim, 500)
with event_marker(f"Sim eval for {adapter_name} adapter"):
with torch.no_grad():
with bert_mha_sim_fpm.place_on_device(device):
sim_ppl = bert_ppl_eval(test_dataloader, bert_mha_sim_fpm)
print(f"ppl score of quantsim model: {sim_ppl}\n"
f"orig ppl - quantsim ppl = {orig_ppl - sim_ppl}")
## save encodings for kvcache mode to consume
quant_sim.save_encodings_to_json(output_dir, f'{adapter_name}_adapter_encoding')
# In[52]:
del bert_mha_sim_fpm
del bert_mha_fpm
del bert_mha_prepared_model
del quant_sim
# ### 8. Base KV MHA FP Model Instantiation
# In[20]:
llm_config = AutoConfig.from_pretrained(model_id, cache_dir=cache_dir, trust_remote_code=True)
# model params
llm_config.num_hidden_layers = num_hidden_layers
llm_config.cache_dir = cache_dir
llm_config.device = torch.device('cpu')
# QC LLM model config
setattr(llm_config, 'mask_neg', -100)
setattr(llm_config, 'num_logits_to_return', ARN)
setattr(llm_config, 'return_top_k', 0)
setattr(llm_config, "use_conv", False)
setattr(llm_config, 'return_new_key_value_only', True)
setattr(llm_config, 'transposed_key_cache', True)
setattr(llm_config, 'use_combined_mask_input', True)
setattr(llm_config, 'concat_head_in_batch_dimension', False)
setattr(llm_config, 'use_sha', False)
setattr(llm_config, 'num_tokens', ARN)
setattr(llm_config, 'use_position_embedding_input', True)
setattr(llm_config, 'separate_tuple_input_output', False)
setattr(llm_config, '_attn_implementation', 'eager')
setattr(llm_config, '_attn_implementation_internal', 'eager')
print(f'num_layer: {llm_config.num_hidden_layers}, context_length: {context_length}, arn: {ARN}')
with event_marker('KV FP model'):
kv_fp_base_model = modeling_llama.LlamaForCausalLM.from_pretrained(model_id, config=llm_config)
os.environ['TOKENIZERS_PARALLELISM'] = '0'
tokenizer = AutoTokenizer.from_pretrained(model_id, cache_dir=cache_dir, use_fast=True, trust_remote_code=True)
## Adjust the tokenizer to limit to context length
tokenizer.model_max_length = context_length
# ### 9. Loading LORA Adapter on base KV MHA Model
# In[21]:
# loading only 1 adapter to have adapted graph ,
adapter_name= "french"
# peft_model_id="kaitchup/Llama-2-7b-mt-French-to-English"
peft_model_id="french"
lora_model = PeftModel.from_pretrained(kv_fp_base_model, peft_model_id, adapter_name=adapter_name)
dummy_adapter_name = "k_v_adapter"
lora_model.add_adapter(dummy_adapter_name, k_v_lora_config)
# Write the lora's for k and v with zeros
# not doing this due to graph issue reported for g2g
for name, param in lora_model.named_parameters():
if dummy_adapter_name in name and "lora" in name:
param.data.fill_(0.0)
combined_adapter_name = "combined_adapter"
lora_model.add_weighted_adapter(
adapters=[adapter_name, dummy_adapter_name],
weights=[1.0, 1.0],
adapter_name=combined_adapter_name,
combination_type="linear"
)
lora_model.set_adapter(combined_adapter_name)
lora_model.delete_adapter(adapter_name)
lora_model.delete_adapter(dummy_adapter_name)
# Replace lora layer with quantizable layers
replace_lora_layers_with_quantizable_layers(lora_model)
# linear to conv adaptation
lora_model=replace_linears_with_convs(lora_model)
kv_mha_fp_model = lora_model.base_model.model
# ### 10. Adapted KV Cache MHA Model Preparation
# #### Estimated running time: ~ 1h 20m
# In[22]:
import aimet_torch.pro.ir_graph_op_handler as ir_graph_op_handler
from aimet_torch.pro import model_preparer
# Setting this flag to False means that the prepared model will be flattened
# This flag must be set to false because we rely on the model structure being flat to enable weight sharing
ir_graph_op_handler.KEEP_ORIGINAL_MODEL_STRUCTURE = False
dummy_input = get_dummy_data('kvcache', llm_config.num_hidden_layers, llm_config.hidden_size, llm_config.num_attention_heads, llm_config.rope_theta,
tokenizer, 'cpu', separate_tuple_input_output=False, num_tokens=ARN, concat_head_in_batch_dimension=llm_config.concat_head_in_batch_dimension)
input_names, output_names = get_input_output_names(
num_layers=llm_config.num_hidden_layers, past_key_values_in=True, separate_tuple_input_output=True)
# Build the converter args
converter_args_param = ['--input_layout']
converter_args_value = 'NONTRIVIAL'
converter_args = []
for input_param in converter_args_param:
for input_name in input_names:
converter_args += [input_param, input_name, converter_args_value]
with event_marker("KV MHA Model prepare", flush_ram=True):
kv_mha_prepared_model = model_preparer.prepare_model(kv_mha_fp_model,
dummy_input,
filename="kv_mha_prepared_model",
path=output_dir,
input_names=input_names,
output_names=output_names,
converter_args=converter_args,
skipped_optimizers=['eliminate_common_subexpression','eliminate_nop_with_unit', 'eliminate_duplicate_initializer'],
)
del kv_mha_fp_model
#
# ### 11. Create Adapted KVcache MHA Quantsim and Apply Encodings from Adapted BERT MHA Model
# In[23]:
kvcache_fpm = LLMForwardPassManager(cfg=llm_config,
model=kv_mha_prepared_model,
tokenizer=tokenizer,
model_mode='kvcache',
num_logits_to_return=ARN,
separate_tuple_input_output=True,
num_tokens=ARN)
llm_config.concat_head_in_batch_dimension = False
dummy_input = get_dummy_data('kvcache', llm_config.num_hidden_layers, llm_config.hidden_size, llm_config.num_attention_heads,
llm_config.rope_theta, tokenizer, device, separate_tuple_input_output=True, num_tokens=ARN, concat_head_in_batch_dimension=llm_config.concat_head_in_batch_dimension)
with event_marker("create KV Quantsim"):
with kvcache_fpm.place_on_device(device):
kv_quant_sim = QuantizationSimModel(model=kvcache_fpm.model,
quant_scheme=QuantScheme.post_training_tf,
dummy_input=dummy_input,
default_output_bw=16,
default_param_bw=4,
in_place=True,
config_file=htp_config_file,
)
# In[24]:
### Setting 16*8 malmuls
from aimet_torch.v2.experimental.quantsim_utils import set_matmul_second_input_producer_to_8bit_symmetric
set_matmul_second_input_producer_to_8bit_symmetric(kv_quant_sim)
# #### Concat encoding unification
# In[25]:
from aimet_torch.v2.experimental import propagate_output_encodings
import aimet_torch.elementwise_ops as aimet_ops
propagate_output_encodings(kv_quant_sim, aimet_ops.Concat)
# #### Mixed precision config
# In[26]:
from mixed_precision_overrides import ManualQuantsimMixedPrecisionConfig
with event_marker("Apply Mixed Precision", flush_ram=True):
quantsim_adjuster = ManualQuantsimMixedPrecisionConfig(mixed_precision_config_file= "./config/mixed_precision_profiles/w4_a16_exceptions_llama_v2_prepared_disableRMSNorm_clampgateprojconv_bundledkv.json")
quantsim_adjuster.apply_exceptions(kv_quant_sim)
# #### Setup lora layer to be 16bit per tensor
# In[31]:
import json
import pickle
with open(os.path.join(output_dir,'meta_data.pkl'), "rb") as f:
meta_data_file = pickle.load(f)
with open(os.path.join(output_dir,'kv_mha_prepared_model.json')) as f:
name_to_module_dict = json.load(f)
peft_utils = PeftQuantUtils(adapater_name_to_meta_data=meta_data_file, name_to_module_dict=name_to_module_dict)
## do this if changing for lora layers
for _,module in peft_utils.get_quantized_lora_layer(kv_quant_sim):
# setting 16 bit per tensor
module.param_quantizers['weight'] = QuantizeDequantize(shape=(1, 1, 1, 1), bitwidth=16, symmetric=True).to(module.weight.device)
peft_utils.quantize_lora_scale_with_fixed_range(kv_quant_sim, 16, 0.0, 1.0)
peft_utils.disable_lora_adapters(kv_quant_sim)
# #### Mapping Base Encodings and Loading Mapped Encodings into Quantizer
# In[32]:
from encodings_mapper import EncodingsMapper
encoding_file = os.path.join(output_dir, 'base_encoding.json')
_ , mapped_encoding_file = EncodingsMapper(llm_config, output_dir, encoding_file).map_encodings()
kv_quant_sim.load_encodings(mapped_encoding_file, partial=False)
# ### 12. Export KVCache Model Onnx and encodings
# #### Estimated running time: ~ 1h
# In[34]:
from aimet_torch.utils import change_tensor_device_placement
from aimet_torch.onnx_utils import OnnxExportApiArgs
from aimet_torch import onnx_utils
from aimet_utils.clip_weights import clip_weights_to_7f7f
onnx_dir = os.path.join(output_dir, 'onnx')
os.makedirs(onnx_dir, exist_ok=True)
input_names, output_names = get_input_output_names(
num_layers=llm_config.num_hidden_layers, past_key_values_in=True, separate_tuple_input_output=True)
onnx_utils.RESTORE_ONNX_MODEL_INITIALIZERS = True
clip_weights_to_7f7f(kv_quant_sim)
onnx_api_args = OnnxExportApiArgs(input_names=input_names,output_names=output_names)
sample_inputs = change_tensor_device_placement(dummy_input, torch.device('cpu'))
filename_prefix = f"llamav2_AR{ARN}"
filename_prefix_encodings = f"{filename_prefix}_base"
with event_marker("KVCache export onnx and test vectors", flush_ram=True):
kv_quant_sim.export(onnx_dir, filename_prefix, sample_inputs, onnx_export_args=onnx_api_args,export_model=True, filename_prefix_encodings=filename_prefix_encodings)
# exporting tokenizer
tokenizer_dir = os.path.join(output_dir, 'tokenizer')
os.makedirs(tokenizer_dir, exist_ok=True)
tokenizer.save_pretrained(tokenizer_dir)
# #### Create sample test vectors for QNN SDK
# ##### Estimated running time: ~ 9m
# In[35]:
from test_vectors import generate_test_vectors
test_vector_layers = [
"model_layers_\\d+_input_layernorm_Pow",
"model_layers_\\d+_input_layernorm_Cast",
"lm_head_conv_Conv",
"lm_head_MatMul",
"model.layers\\d+.input_layernorm.cast",
"lm_head_conv",
"lm_head"
]
with event_marker("generate test vector"):
generate_test_vectors(kv_quant_sim, kvcache_fpm, train_dataloader, output_dir, num_batches=1, test_vector_layers=test_vector_layers, input_names=input_names)
# #### Mapping Encoding from Bert to Kvcache and Export encodings for Adapters
# ##### Estimated running time : ~ 10m
# In[36]:
from encodings_mapper import EncodingsMapper
peft_utils.freeze_base_model_param_quantizers(kv_quant_sim)
for adapter_name,peft_model_id in lora_adapter_dict.items():
peft_utils.enable_adapter_and_load_weights(kv_quant_sim,os.path.join(output_dir,f'{adapter_name}.safetensor'))
encoding_file = os.path.join(output_dir, f'{adapter_name}_adapter_encoding.json')
_ , mapped_encoding_file = EncodingsMapper(llm_config, output_dir, encoding_file).map_encodings()
kv_quant_sim.load_encodings(mapped_encoding_file, partial=False)
clip_weights_to_7f7f(kv_quant_sim)
peft_utils.export_adapter_weights(kv_quant_sim, output_dir, f'{adapter_name}_onnx')
filename_prefix_encodings = f"{filename_prefix}_{adapter_name}"
with event_marker(f"KVCache export {adapter_name} adapter encodings", flush_ram=True):
kv_quant_sim.export(onnx_dir, filename_prefix, sample_inputs, onnx_export_args=onnx_api_args,export_model=False, filename_prefix_encodings=filename_prefix_encodings)
# ---
# ## Summary
# In[37]:
from aimet_torch.pro.utils.profiler import EventProfiler
EventProfiler().report()
EventProfiler().json_dump(os.path.join(output_dir, 'profiling_stats'))
最新发布








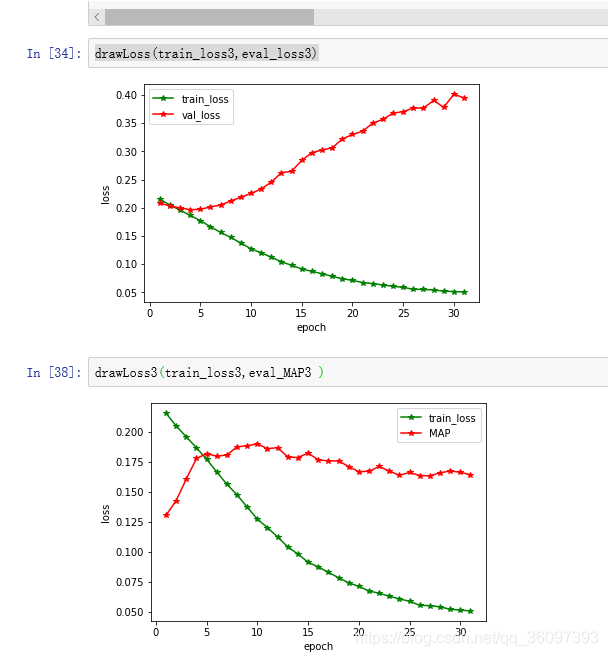
 本文探讨了通过调整模型参数、优化算法及数据处理策略来提高机器学习模型的时间效率与预测精度。具体包括减小批量大小、采用Adam优化器、合理初始化权重、避免过度正则化等方法,并对比了不同条件下的loss变化。同时,引入了MAP和NDCG作为评估模型预测能力的指标,详细解析了其计算方式和应用场景。
本文探讨了通过调整模型参数、优化算法及数据处理策略来提高机器学习模型的时间效率与预测精度。具体包括减小批量大小、采用Adam优化器、合理初始化权重、避免过度正则化等方法,并对比了不同条件下的loss变化。同时,引入了MAP和NDCG作为评估模型预测能力的指标,详细解析了其计算方式和应用场景。


















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









