




 本文详细介绍正则表达式的八大核心方法,包括re.match、group、.*?、re.search、re.findall、re.sub、re.compile及结果保存技巧,适合Python爬虫初学者快速上手。
本文详细介绍正则表达式的八大核心方法,包括re.match、group、.*?、re.search、re.findall、re.sub、re.compile及结果保存技巧,适合Python爬虫初学者快速上手。
接触了python后,爬虫是必不可少的。正则表达式是我们处理爬虫数据,解析HTML数据的重要工具。由于正则表达式十分复杂,这让初学者常常感到头痛。我在查找了大量资料后,发现 毕来生 总结的正则表达式的学习十分适合像我这样的初学者。因此,在本文我重现了regex(正则表达式)的常用方法。如下:
包括的内容:
1 re.match()
2 group()
3 .*? 通用匹配符,贪婪与非贪婪匹配
4 re.search()
5 re.findall()
6 re.sub()
7 re.compile()
8 匹配结果保存到txt,csv。(利用pandas库在代码 167 行)
此外我还有个问题:pandas在控制台输出的信息列是不对齐的,请问怎么使用format()方法对齐。
如图所示:

欢迎在https://blog.youkuaiyun.com/qq_36090423 交流。
以上所有源码在createRegex.py,已上传至 https://download.youkuaiyun.com/download/qq_36090423/10544386
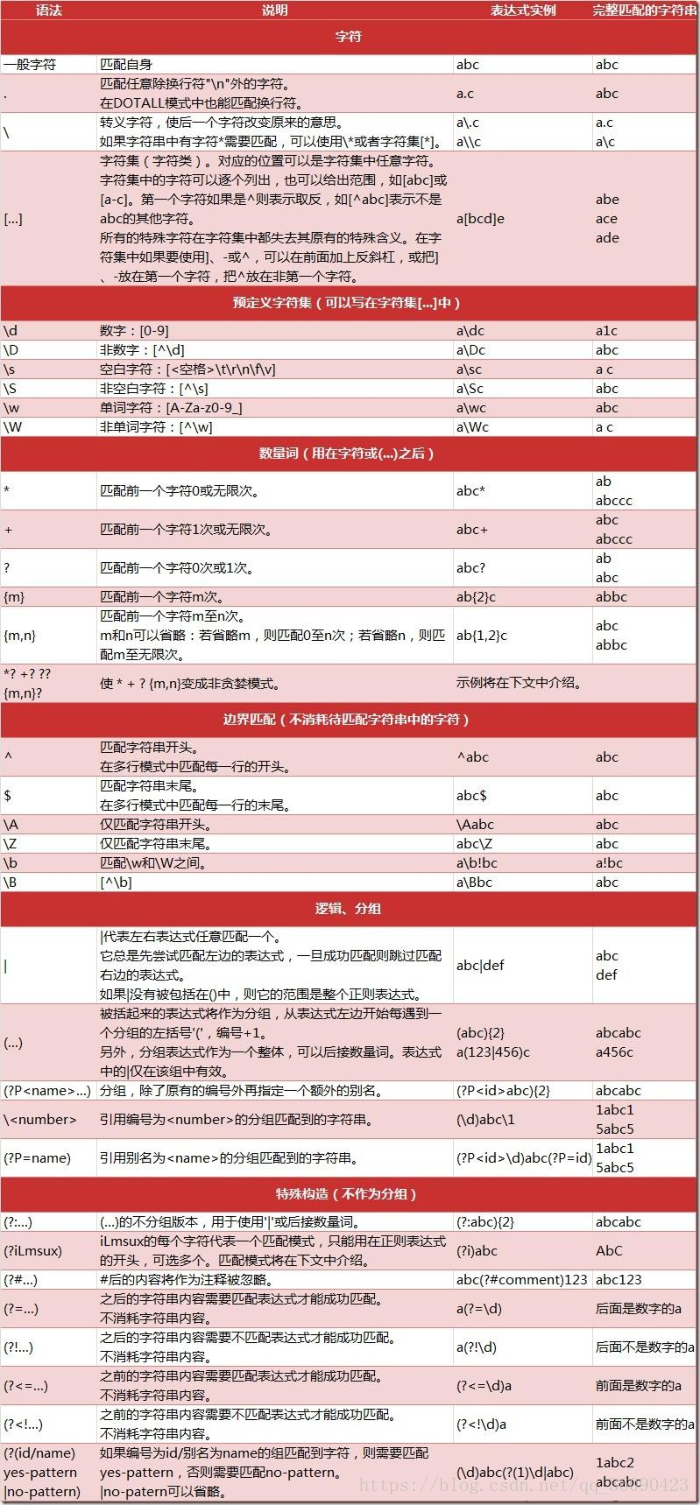
另外附录正则表达的语法规范。

















 3031
3031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









