






 本文探讨了在大规模数据处理中程序运行时间的重要性,包括估计、比较和优化技巧。复习了数学基础知识如指数、对数、级数和模运算,重点介绍了递归的概念、证明方法以及C++中的递归应用。讲解了递归的四个基本法则,强调了基准情形和不断推进在编程中的关键作用。
本文探讨了在大规模数据处理中程序运行时间的重要性,包括估计、比较和优化技巧。复习了数学基础知识如指数、对数、级数和模运算,重点介绍了递归的概念、证明方法以及C++中的递归应用。讲解了递归的四个基本法则,强调了基准情形和不断推进在编程中的关键作用。
第一章 引论
本章阐述本书的目的和目标,并且简要复习离散数学和程序设计的一些概念。
1.1本书讨论的内容
在许多问题中,写出一个可以工作的程序是不够的。如果这个程序是在大规模的数据集上运行,那么运行时间就成了问题。在本书中我们将看到,对于大规模的输入,如何估计程序的运行时间,更重要的是,弄清如何在尚未具体编码的情况下比较两个程序的运行时间。我们还将看到提高程序的运行速度以及确定程序瓶颈的技巧。这些技巧将使我们能够找到需要着重优化的那些代码段。
1.2数学知识复习
1.2.1指数
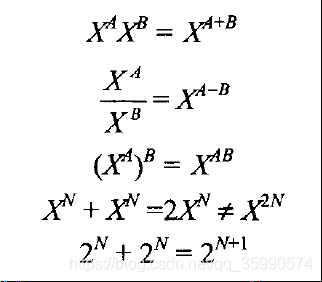
1.2.2对数
在计算机科学中,所有的对数都是以2为底的,除非另有声明。
定义1.1
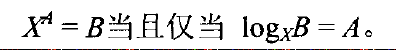
定理1.1
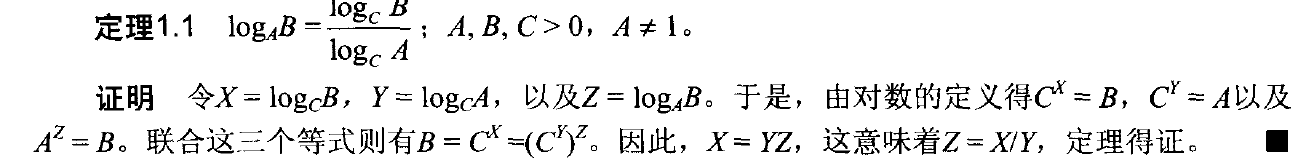
定理1.2

其他公式

1.2.3级数

经常用来分析的另一种级数是算术级数。任何这样的级数都可以用基本公式求其值。
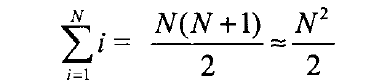

当k=-1时,后一个公式不成立。此时需要下面的公式,这个公式在计算机科学中远比在其他数学科目中用得多。数Hn叫作调和数,其和叫作调和和。下面近似式中的误差趋向于y=0.57721566,称为欧拉常数(Euler’s constant)。
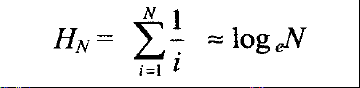
1.2.4模运算
如果N整除A-B,那么就说A与B模N同余(congruent),记为A=B(modN)。直观地看,这意味着无论A或B被M除,所得余数都是相同的。因此,81=61=l(mod10)。
1.2.5证明方法
证明数据结构分析中的结论的两种最常见的方法是归纳法证明和反证法证明
1.归纳法
由归纳法进行的证明有两个标准的部分。第一步是证明基准情形(base case),就是确定定理对于某个(某些)小的(通常是退化的)值的正确性;这一步总是很简单的。接着,进行归纳假设(inductive hypothesis)。一般说来,这意味着假设定理对直到某个有限数k的所有情况都是成立的。然后使用这个假设证明定理对下一个值(通常是k+1)也是成立的。至此定理得证(在k是有限的情形下)。
2.反证法
反证法证明是通过假设定理不成立,然后证明该假设导致某个已知的性质不成立,从而证明原假设是错误的。
1.3递归的简单介绍
当一个函数用自身来定义时就称为是递归(recursive)的。C++允许函数是递归的。但必须要记住,C++所做的仅仅是试图遵循递归思想。不是所有的数学递归函数都能被有效地(或正确地)用C++的递归模拟来实现。要点在于,递归函数f应该像非递归函数一样只用几行就能表示出来。
C++的递归方法若无基准情况也是毫无意义的。
关于递归,有几个重要而可能混淆的概念。一个常见问题是:它就是循环逻辑吗?答案是:
虽然用一个函数本身来定义这个函数,但是并没有用一个函数实例本身来定义该特定实例。换句话说,通过使用f(5)来得到f(5)的值才是循环的。通过使用f(4)得到f(5)的值就不是循环的。
。跟踪挂起的函数调用(这些调用已经开始但是正等待着一次递归调用的完成)以及跟踪这些调用的变量、所需的记录工作都由计算机自动完成。然而,要点在于,递归调用将一直进行到基准情形出现为止。
通常,我们会说某函数对一个特殊情形无效,而对其他情形是正确的。对于递归程序,不存在“特殊情形”。
上面的讨论引出递归的前两个基本法则:
(1)基准情形(base cases)。必须总有某些基准的情形,它们不用递归就能求解。
(2)不断推进(making progress)。对于那些要被递归求解的情形,递归调用必须总能够朝着一个基准情形推进。
递归的主要问题是隐含的簿记开销。虽然这些开销几乎总是合理的(因为递归程序不仅简化了算法设计而且有助于给出更加简洁的代码),但是递归绝不应该作为简单for循环的代替物。
当编写递归例程的时候,关键是要牢记递归的四条基本法则:
(1)基准情形。必须总有某些基准情形不用递归就能求解。
(2)不断推进。对于那些需要递归求解的情形,递归调用必须总能够朝着基准情形的方向推进。
(3)设计法则。假设所有的递归调用都能运行。
(4)合成效益法则(compound interest rule)。在求解一个问题的同一实例时,切勿在不同的递归调用中做重复性的工作。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









