







WebMagic框架简介
WebMagic框架包含四个组件,PageProcessor、Scheduler、Downloader和Pipeline。
这四大组件对应爬虫生命周期中的处理、管理、下载和持久化等功能。
这四个组件都是Spider中的属性,爬虫框架通过Spider启动和管理。
WebMagic总体架构图如下:
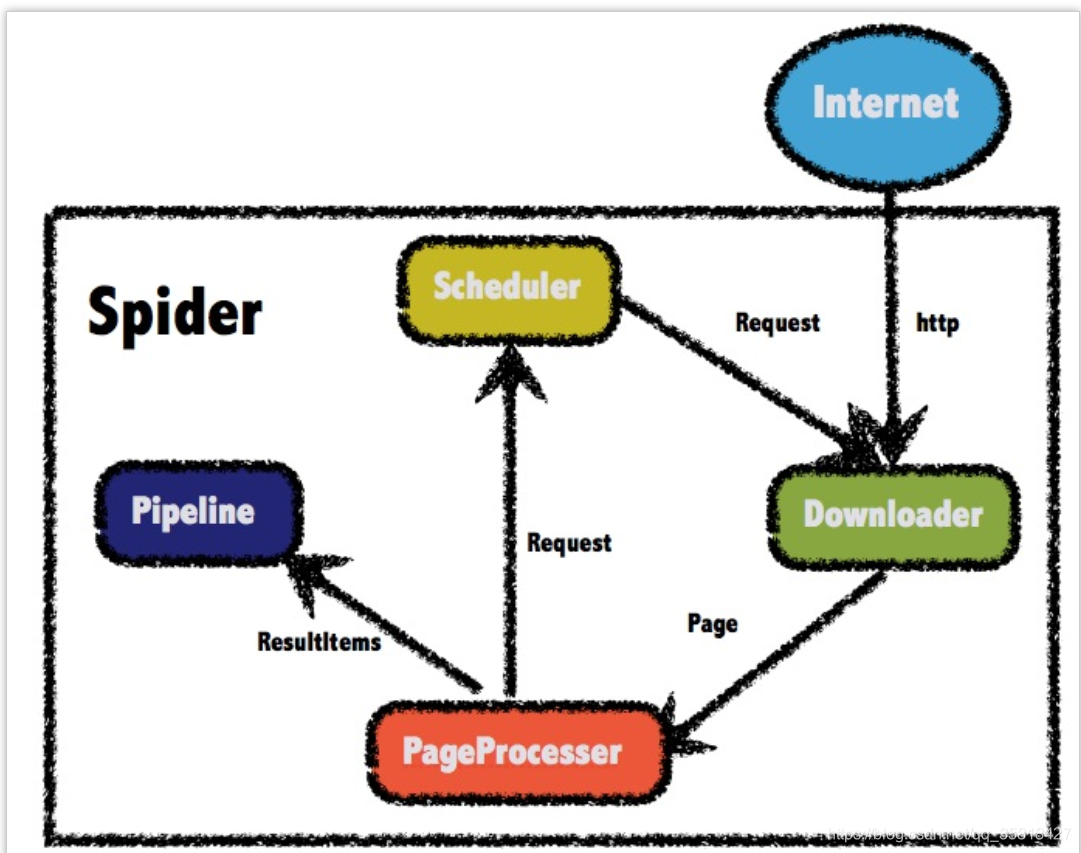
四大组件
PageProcessor 负责解析页面,抽取有用信息,以及发现新的链接。需要自己定义。
Scheduler 负责管理待抓取的URL,以及一些去重的工作。一般无需自己定制Scheduler。
Pipeline 负责抽取结果的处理,包括计算、持久化到文件、数据库等。
Downloader 负责从互联网上下载页面,以便后续处理。一般无需自己实现。
用于数据流转的对象
Request 是对URL地址的一层封装,一个Request对应一个URL地址。
Page 代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
ResultItems 相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。
WebMagic使用小细节
WebMagic框架支持多种抽取方式,包括xPath、css选择器、正则表达式,还可以通过links()方法选择所有链接。
记住抽取之前要获得通过getHtml()来获取html对象,通过html对象来使用抽取方法,基本上都是通过xPath来定位页面中文章的url。把他们通过addTargetRequests方法加入到队列中即可。
使用xPath时要留意,框架作者自定义了几个函数:
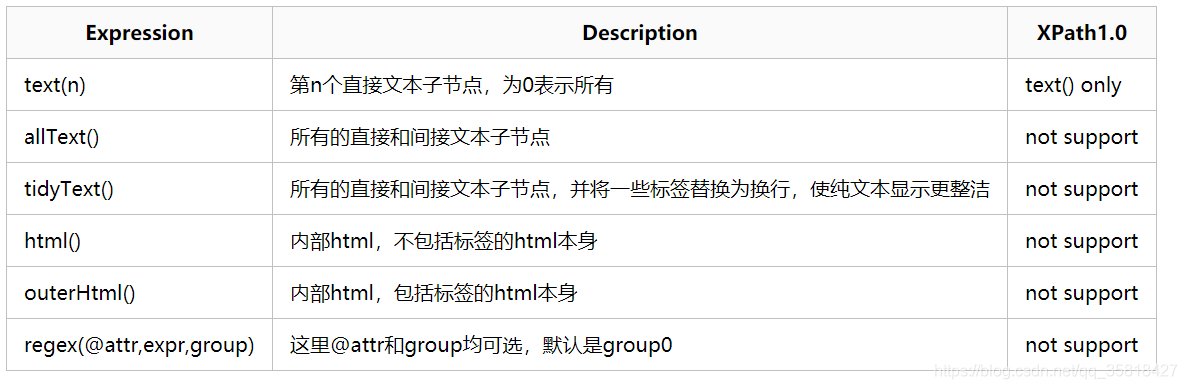
使用起来很方便。
打开官网 http://webmagic.io/
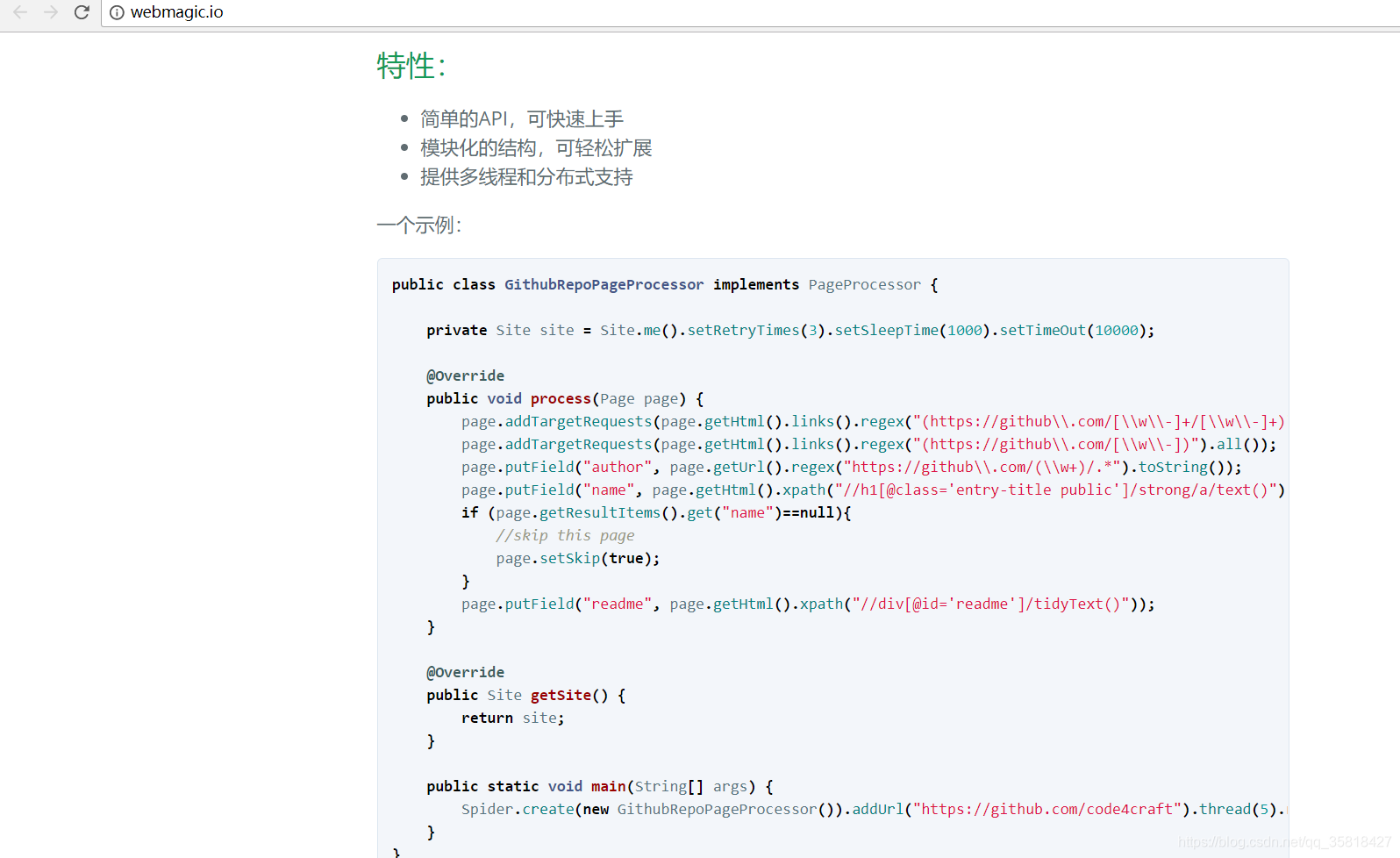

根据官网demo改造一波
入门demo
新建2个类来随便爬下蔬菜网站试试
MeiLvPageProcessor.java
package com.wangtao.wm;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.IntStream;
public class MeiLvPageProcessor implements PageProcessor{
//重试3次,每次请求休眠100毫秒,设置超时时间为10000毫秒
private Site site = Site.me().setRetryTimes(3).setSleepTime(100).setTimeOut(10000);
private AtomicInteger one = new AtomicInteger(0);
private AtomicInteger two = new AtomicInteger(0);
@Override
public void process(Page page) {
Html html = page.getHtml();
List<String> list=null;
if(one.get()==0) {
list = html.css(".nav .menu #tag_ul a").links().all();
page.addTargetRequests(list);
one.getAndIncrement();
}else{
list = html.css(".boxs .img .p_title a").links().all();
page.addTargetRequests(list);
}
//标题
String title = html.xpath("//div[@class='weizhi']/h1/text()").toString();
page.putField("title",title);
//图片
String img = html.xpath("//div[@class='content']/center/html()").toString();
page.putField("img",img);
//模特名称
List<String> name = html.css(".c_l p a","text").all();
String info = null;
if (name != null && name.size() > 0) {
if (name.size() < 2) {
info = name.get(0);
}else{
info = name.get(1);
}
}
page.putField("info",info);
if (page.getResultItems().get("title") == null) {
page.setSkip(true);
if(two.get()>0) {
//分頁
List<String> all = html.xpath("//div[@id='pages']/a").all();
//第一页
String data = all.get(all.size() - 2);
String startPage = data;
data = data.replaceAll("<a href[^>]*>", "").replaceAll("</a>", "");
int size = Integer.parseInt(data);
//后面的分页图片数据
IntStream.rangeClosed(2,size).forEach(i->{
page.addTargetRequest(startPage.replaceAll(".html", "/"+i+".html"));
});
}
two.getAndIncrement();
}else{
//第一页数据不一样
String startPage = html.xpath("//div[@id='pages']/a").links().get();
page.addTargetRequest(startPage);
System.out.println("正在从["+startPage+"]获取数据");
List<String> all = html.xpath("//div[@id='pages']/a").all();
//第一页
String data = all.get(all.size() - 2);
data = data.replaceAll("<a href[^>]*>", "").replaceAll("</a>", "");
int size = Integer.parseInt(data);
//后面的分页图片数据
IntStream.rangeClosed(2,size).forEach(i->{
page.addTargetRequest(startPage.replaceAll(".html", "_"+i+".html"));
});
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
long startTime= System.currentTimeMillis();
Spider.create(new MeiLvPageProcessor()).addUrl("https://www.meitulu.com/")
.addPipeline(new MeiLvPipeline())
.thread(16).run();
long endtTime= System.currentTimeMillis();
System.out.println("图片下载完成,总花时:"+(endtTime-startTime));
}
}
爬个蔬菜网站试试,设置16个线程来爬取
MeiLvPipeline .java
package com.wangtao.wm;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClientBuilder;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class MeiLvPipeline implements Pipeline{
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void process(ResultItems resultItems, Task task) {
System.out.println(resultItems);
String name = resultItems.get("info").toString();
String img = resultItems.get("img").toString();
String[] split = img.split("<img");
Map<String, Object> data = new HashMap<>();
for (int i = 1; i <split.length ; i++) {
String imageUrl = StringUtils.split(split[i], '"')[3];
data.put("title", resultItems.get("title"));//标题
data.put("name",name);//名称
data.put("image", imageUrl);
String url = StringUtils.split(split[i], '"')[1];
try {
this.downloadFile(imageUrl,url, new File( "E:\\images\\" + name+"\\"+ RandomStringUtils.randomNumeric(6) + ".jpg"));
} catch (Exception e) {
e.printStackTrace();
}
String json = null;
try {
json = MAPPER.writeValueAsString(data);
FileUtils.write(new File("E:\\code\\data1.json"), json + "\n", "UTF-8",
true);
} catch (JsonProcessingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 下载文件
*
* @param url 文件url
* @param dest 目标目录
* @throws Exception
*/
public void downloadFile(String imageUrl,String url, File dest) throws Exception {
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response =
HttpClientBuilder.create().build().execute(httpGet);
try {
FileUtils.writeByteArrayToFile(dest,
IOUtils.toByteArray(response.getEntity().getContent()));
System.out.println("下载完成:"+imageUrl);
} finally {
response.close();
}
}
}
pom.xml
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
运行结果
…经过1天一夜的爬取,还没跑完,实在没耐心等下去了,把程序结束了,成果展示如下
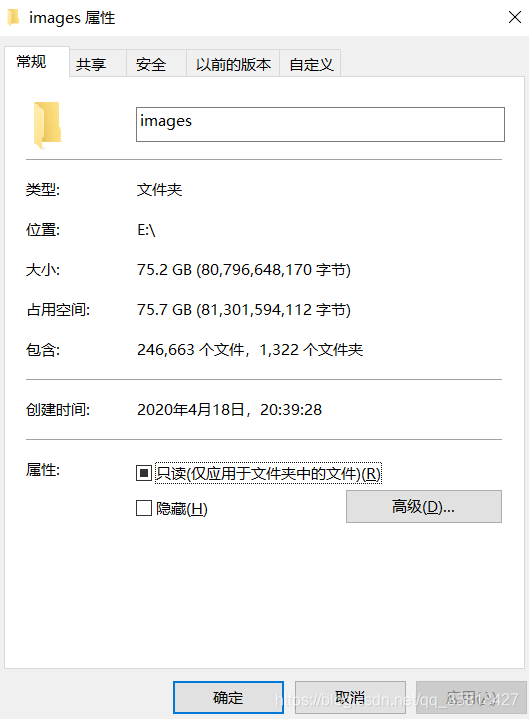
至此,webmagic入门到此结束,溜了…

















 1594
1594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









