




 本文围绕MySQL性能优化展开,介绍了调优思路,包括数据库设计规划、数据应用、服务及系统优化等。阐述了服务优化配置原则,应用优化方式如合理设计表结构、建立索引、编写高效SQL等。还分享了MySQL技巧,如分析执行情况、记录慢查询等,以及SQL语句调优等内容。
本文围绕MySQL性能优化展开,介绍了调优思路,包括数据库设计规划、数据应用、服务及系统优化等。阐述了服务优化配置原则,应用优化方式如合理设计表结构、建立索引、编写高效SQL等。还分享了MySQL技巧,如分析执行情况、记录慢查询等,以及SQL语句调优等内容。
MySQL性能优化
目标
- 调优思路
- 系统优化
- mysql服务优化
- 应用优化方式
- SQL语句调优
- 启用mysql慢查询
调优思路
- 数据库设计与规划–以后再修该很麻烦,估计数据量,使用什么存储引擎
- 数据的应用–怎样取数据,sql语句的优化
- mysql服务优化–内存的使用,磁盘的使用
- 操作系统的优化–内核、tcp连接数量
- 升级硬件设备
系统优化
- 使用好的硬件,更快的硬盘、大内存、多核CPU,专业的存储服务器(NAS、SAN)
- 设计合理架构,如果 MySQL 访问频繁,考虑 Master/Slave 读写分离;数据库分表、数据库切片(分布式),也考虑使用相应缓存服务帮助 MySQL 缓解访问压力
服务优化
MySQL配置原则
配置合理的MySQL服务器,尽量在应用本身达到一个MySQL最合理的使用
针对 MyISAM 或 InnoDB 不同引擎进行不同定制性配置
针对不同的应用情况进行合理配置
针对 my.ini 进行配置,后面设置是针对内存为2G的服务器进行的合理设置
公共选项
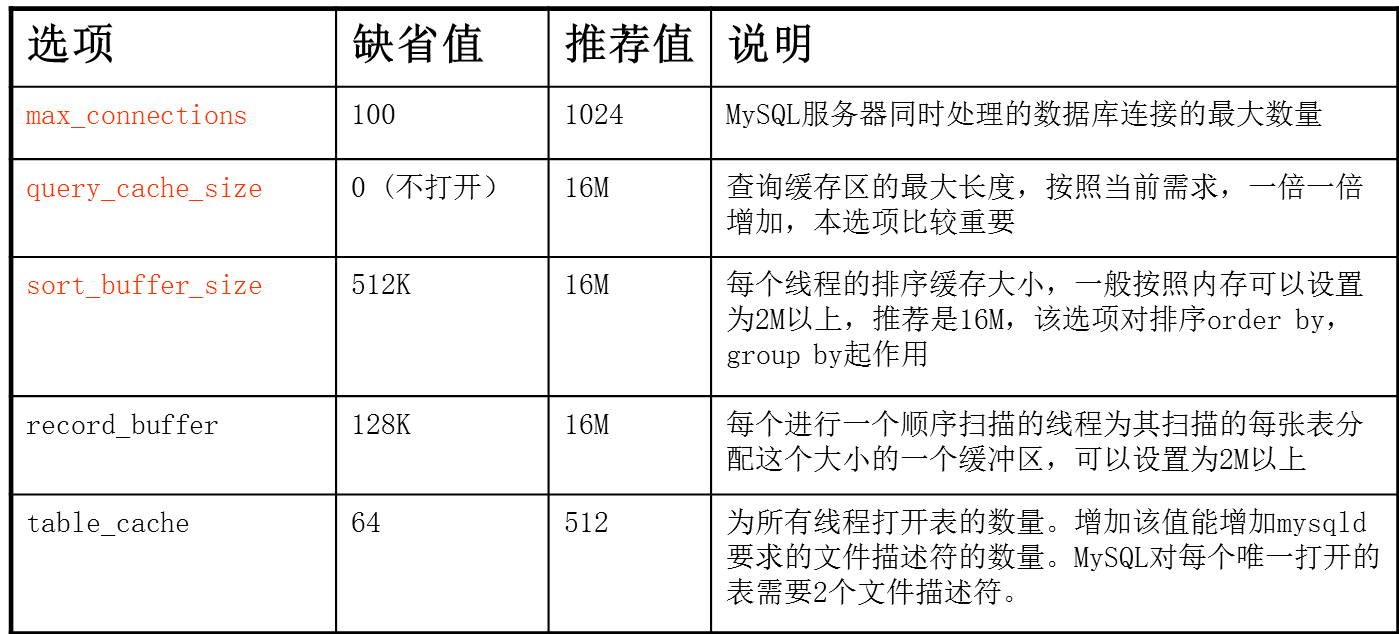
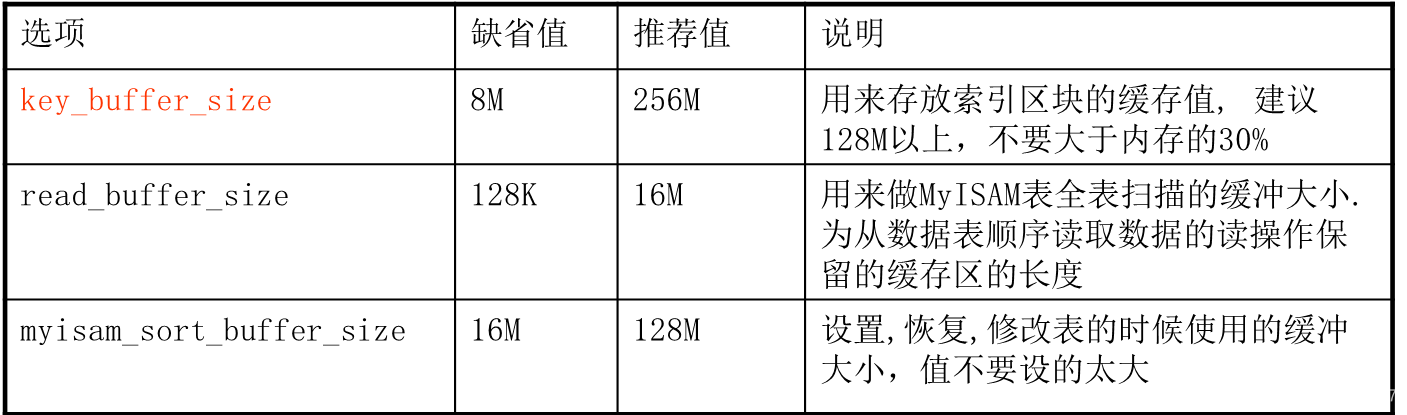
MyISAM 选项
InnoDB 选项

应用优化方式
设计合理的数据表结构:适当的数据冗余
对数据表建立合适有效的数据库索引
数据查询:编写简洁高效的SQL语句
表结构设计原则
选择合适的数据类型:如果能够定长尽量定长
使用 ENUM 而不是 VARCHAR,ENUM类型是非常快和紧凑的,在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美 。
不要使用无法加索引的类型作为关键字段,比如 text类型
为了避免联表查询,有时候可以适当的数据冗余,比如
邮箱、姓名这些不容易更改的数据
选择合适的表引擎,有时候 MyISAM 适合,有时候
InnoDB适合
为保证查询性能,最好每个表都建立有 auto_increment
字段, 建立合适的数据库索引
最好给每个字段都设定 default 值
索引建立原则(一)
一般针对数据分散的关键字进行建立索引,比如ID、QQ,
像性别、状态值等等建立索引没有意义
字段唯一,最少,不可为null。
尽量使用短索引,一般对int、char/varchar、date/time 等
类型的字段建立索引
需要的时候建立联合索引,但是要注意查询SQL语句的编写
谨慎建立 unique 类型的索引(唯一索引)
大文本字段不建立为索引,如果要对大文本字段进行检索,
可以考虑全文索引
频繁更新的列不适合建立索引
索引建立原则(二)
order by 字句中的字段,where 子句中字段,最常用的sql
语句中字段,应建立索引。
唯一性约束,系统将默认为改字段建立索引。
对于只是做查询用的数据库索引越多越好,但对于在线实时
系统建议控制在5个以内。
索引不仅能提高查询SQL性能,同时也可以提高带where字句
的update,Delete SQL性能。
Decimal 类型字段不要单独建立为索引,但覆盖索引可以包
含这些字段。
只有建立索引以后,表内的行才按照特地的顺序存储,按照
需要可以是asc或desc方式。
如果索引由多个字段组成将最用来查询过滤的字段放在前面
可能会有更好的性能。
编写高效的 SQL (一)
能够快速缩小结果集的 WHERE 条件写在前面,如果有恒量条件,
也尽量放在前面
尽量避免使用 GROUP BY、DISTINCT 、OR、IN 等语句的使用,
避免使用联表查询和子查询,因为将使执行效率大大下降
能够使用索引的字段尽量进行有效的合理排列,如果使用了
联合索引,请注意提取字段的前后顺序
针对索引字段使用 >, >=, =, <, <=, IF NULL和BETWEEN 将会使用
索引, 如果对某个索引字段进行 LIKE 查询,使用 LIKE ‘%abc%’
不能使用索引,使用 LIKE ‘abc%’ 将能够使用索引
如果在SQL里使用了MySQL部分自带函数,索引将失效,同时将无法
使用 MySQL 的 Query Cache,比如 LEFT(), SUBSTR(), TO_DAYS()
DATE_FORMAT(), 等,如果使用了 OR 或 IN,索引也将失效
使用 Explain 语句来帮助改进我们的SQL语句
编写高效的 SQL (二)
不要在where 子句中的“=”左边进行算术或表达式运算,否则系统将
可能无法正确使用索引
尽量不要在where条件中使用函数,否则将不能使用索引
避免使用 select *, 只取需要的字段
对于大数据量的查询,尽量避免在SQL语句中使用order by 字句,避免
额为的开销,替代为使用ADO.NET 来实现。
如果插入的数据量很大,用select into 替代 insert into 能带来更好的性能
采用连接操作,避免过多的子查询,产生的CPU和IO开销
只关心需要的表和满足条件的数据
适当使用临时表或表变量
对于连续的数值,使用between代替in
where 字句中尽量不要使用CASE条件
尽量不用触发器,特别是在大数据表上
编写高效的 SQL (三)
更新触发器如果不是所有情况下都需要触发,应根据业务需要加
上必要判断条件
使用union all 操作代替OR操作,注意此时需要注意一点查询条
件可以使用聚集索引,如果是非聚集索引将起到相反的结果
当只要一行数据时使用 LIMIT 1
尽可能的使用 NOT NULL填充数据库
拆分大的 DELETE 或 INSERT 语句
批量提交SQL语句
MySQL技巧分享
常用技巧
使用 Explain/ DESC 来分析SQL的执行情况
使用 SHOW PROCESSLIST 来查看当前MySQL服务器线程
执行情况,是否锁表,查看相应的SQL语句
设置 my.cnf 中的 long-query-time 和 log-slow-queries 能够
记录服务器那些SQL执行速度比较慢
另外有用的几个查询:SHOW VARIABLES、SHOW
STATUS、SHOW ENGINES
使用 DESC TABLE xxx 来查看表结构,使用 SHOW INDEX
FROM xxx 来查看表索引
使用 LOAD DATA 导入数据比 INSERT INTO 快多了
SELECT COUNT(*) FROM Tbl 在 InnoDB 中将会扫描全表
MyISAM 中则效率很高
SQL语句调优
Explain 使用
语法:EXPLAIN SELECT select_options
Type: 类型,是否使用了索引还是全表扫描, const,eg_reg,ref,range,index,ALL
Key: 实际使用上的索引是哪个字段
Ken_len: 真正使用了哪些索引,不为 NULL 的就是真实使用的索引
Ref: 显示了哪些字段或者常量被用来和 key 配合从表中查询记录出来
Rows: 显示了MySQL认为在查询中应该检索的记录数
Extra: 显示了查询中MySQL的附加信息,关心Using filesort 和 Using temporary,性能杀手
type
这列很重要,显示了连接使用了哪种类别,有无使用索引
从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL
const:表中的一个记录的最大值能够匹配这个查询(索引可以是主键或惟一索引)。因为只有一行,这个值实际就是常数,因为MYSQL先读这个值然后把它当做常数来对待
• eq_ref:在连接中,MYSQL在查询时,从前面的表中,对每一个记录的联合都从表中读取一个记录,它在查询使用了索引为主键或惟一键的全部时使用
• ref:这个连接类型只有在查询使用了不是惟一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少—越少越好
• range:这个连接类型使用索引返回一个范围中的行,比如使用>或
• index: 这个连接类型对前面的表中的每一个记录联合进行完全扫描(比ALL更好,因为索引一般小于表数据)
• ALL:这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,应该尽量避免
MySQL Slow Log 分析工具
mysqldumpslow - mysql官方提供的慢查询日志分析工具
mysqlsla - hackmysql.com推出的一款日志分析工具,功能
非常强大
mysql-explain-slow-log – 德国工程师使用Perl开发的把 Slow Log 输出到屏幕,功能简单
mysql-log-filter - Google code 上一个开源产品,报表 简洁
操作系统的优化
tcp连接数量限制
优化系统打开文件的最大限制
关闭操作系统不必要的服务
mysql服务优化
show status 看系统的资源
show variables 看变量,在my.cnf配置文件里定义的
show warnings 查看最近一个sql语句产生的错误警告,看其他的需要看.err日志
show processlist显示系统中正在运行的所有进程。
show errors
启用mysql慢查询
—分析sql语句,找到影响效率的 SQL
log-slow-queries=/var/lib/mysql/slow.log 这个路径对mysql用户具有可写权限
long_query_time=2 查询超过2秒钟的语句记录下来
上面的 2 是查询的时间,即当一条 SQL 执行时间超过5秒的时候才记录,/var/lib/mysql/slow.log 是日志记录的位置。
然后重新启动MySQL服务
通用的MySQL服务器变量
back_log:该值定义服务器等待处理队列长度的最大值。如果站点访问量大,需加大该值。
delayed_queue_size:该值定义该队列容纳的数据行的最大个数。当队列满时,会阻塞后续的语句。加大该值能提高insert delayed语句的执行速度
flush_time:自动存盘间隔
key_buffer_size:用来容纳索引块的缓冲区的长度。加大该值可加块索引创建和修改操作的速度,该索引缓冲区越大,在内存中找到键值可能性就越大,读盘次数就越少
max_allowed_packet:服务器与客户程序之间通信使用的缓冲区的最大值
max_connections:允许同时打开的连接数,如果站点繁忙,需加大该值
table_cache:数据表缓存区的尺寸,加大该值可使服务器能够同时打开更多的数据表,从而减少文件打开/关闭操作的次数



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











