




 EmbeddingLayer在处理高维稀疏数据时极为有效,如NLP中的词向量化,能减少one-hot编码的维度并捕捉词间关系;在用户行为分析及推荐系统中,亦能高效地嵌入复杂信息,提升深度学习模型的表现。
EmbeddingLayer在处理高维稀疏数据时极为有效,如NLP中的词向量化,能减少one-hot编码的维度并捕捉词间关系;在用户行为分析及推荐系统中,亦能高效地嵌入复杂信息,提升深度学习模型的表现。
为什么我们要开始使用embedding layer
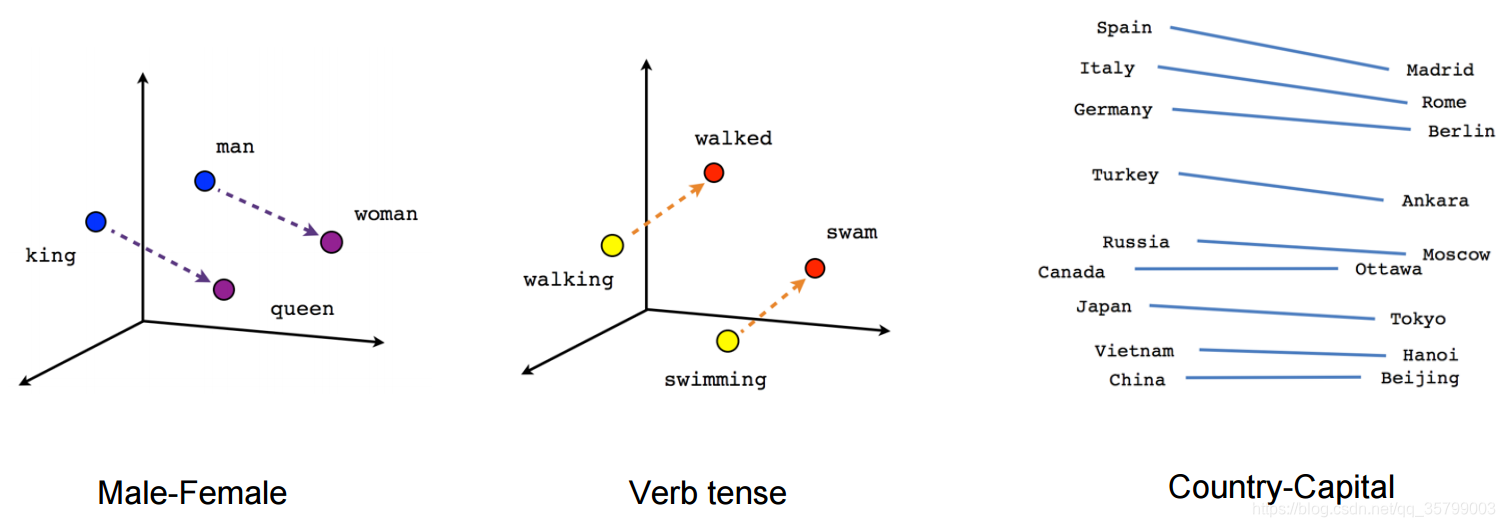
在介绍embedding的概念可能非常陌生。 例如,除了“将正整数(索引)转换为固定大小的稠密向量”之外,Keras文档没有提供任何解释。 快速谷歌搜索可能不会让你更进一步,因为这些类型的文档是第一个弹出的东西。 但是,在某种意义上,Keras的文档描述了所发生的一切。 那么为什么要使用embedding layer呢? 以下是两个主要原因:
- one-hot编码向量是高维和稀疏(sparse)的。 假设我们正在进行自然语言处理(NLP)并且有一个2000字的字典。 这意味着,当使用one-hot编码时,每个单词将由包含2000个整数的向量表示, 其中1999个是零。 在大数据集中,这种方法的计算效率不高。
- 每个embedding的向量在训练神经网络时得到更新。 如果你已经看过这篇文章顶部的图片,你可以看到在多维空间中如何找到单词之间的相似度。 这使我们可以看到单词之间的关系,也可以看到任何可以通过embedding转换为向量的事物之间的关系。
这个概念可能仍然有点模糊。 让我们看一下embedding layer对词示例的作用。 然而,embedding的起源来自于word embedding。 如果您有兴趣阅读更多内容,可以看看word2vec的论文。 我们以这句话为例(不要认真对待):
“deep learning is very deep”
使用embedding layer的第一步是通过索引对该句子进行编码。 在这种情况下,我们为每个唯一单词分配一个索引。 这句话看起来像这样:
1 2 3 4 1
接下来创建embedding矩阵。 我们决定为每个下标分配多少“潜在因素(latent factors)”。 基本上这意味着我们想要向量多长。 一般用例的长度为32和50。让我们在这篇文章中为每个索引分配6个潜在因子,以保持其可读性。 embedding矩阵看起来像这样:

因此,我们可以使用embedding矩阵来保持每个向量的大小更小,而不是以巨大的one-hot编码向量。 简而言之,发生的事情就是“deep”这个词由向量 [.32, .02, .48, .21, .56, .15]表示。 但是,并非每个单词都被向量替换。 相反,它被用于在embedding矩阵中查找向量的索引替换。 当再次使用非常大的数据集时,这在计算上是有效的。 由于embedding向量在深度神经网络的训练过程中也得到更新,我们可以在多维空间中探索哪些词是彼此相似的。 通过使用像t-SNE这样的降维技术,可以看到这些相似之处。

不仅仅word embedding
前面的例子表明,word embedding在自然语言处理领域非常重要,它们使我们能够捕获非常难以捕获的语言关系。 但是,embedding layer可以用于嵌入更多的东西,而不仅仅是单词。 在我目前的研究项目中,我使用embedding layer来嵌入在线用户行为。 在这种情况下,我正在为用户行为分配索引,例如“在门户Y上的页面类型X上的页面视图”或“滚动的X像素”。 然后,这些索引用于构造用户行为序列。
在将“传统”机器学习模型(SVM,随机森林,梯度提升树)与深度学习模型(DNN,RNN)进行比较时,我发现这种embedding方法对深度神经网络非常有效。
“传统的”机器学习模型依赖于设计的特征的表格输入。 这意味着我们作为研究人员决定将什么变成一个特征。 在这些情况下,特征可能是:访问的主页数量、完成的搜索量、滚动的像素总数。 但是,在进行特征工程时很难捕获空间(时间)维度。 通过使用深度学习和embedding layer,我们可以通过提供一系列用户行为(作为索引)作为模型的输入来有效地捕获此空间维度。
在我通过门控递归单位/长短期记忆(Gated Recurrent Unit/Long-Short Term Memory)来研究RNN中表现最佳, 结果非常接近。 从“传统”特征工程对Gradient Boosted Trees建模表现最佳。 我将在未来更详细地写一篇关于这项研究的博客文章。 我想我的下一篇博文将更详细地探讨RNN。
其他研究探索了使用embedding layer来编码学生行为MOOCs (Piech et al., 2016) 。以及用户通过在线时尚商店的路径(Tamhane et al., 2017)。
推荐系统
embedding layer甚至可以用于处理推荐系统中的稀疏矩阵问题。 由于深度学习课程(fast.ai)使用推荐系统来引入embedding layer,我也想在这里探讨它们。
推荐系统正在各处使用,您可能每天都受到它们的影响。 最常见的例子是亚马逊的产品推荐和Netflix的节目推荐系统。 Netflix实际上持有1,000,000美元的挑战,为他们的推荐系统找到最好的协同过滤算法。
有两种主要类型的推荐系统,区分这两者很重要。
- 基于内容的过滤。 此类过滤基于有关item/product的数据。 例如,我们让用户填写他们喜欢的电影。 如果他们说他们喜欢科幻电影,我们推荐科幻电影。 在这种情况下,必须为所有item提供大量元信息。
- 协同过滤:让我们找到像你一样的其他人,看看他们喜欢什么,并假设你喜欢同样的东西。 像你这样的人=以类似方式观看的电影的人。 在大型数据集中,事实证明这比元数据方法更好。 与人们的实际行为相比,基本上向询问他们的行为是不太好的。 对我们中间的心理学家来说可以进一步讨论这个问题。
为了解决这个问题,我们可以针对所有电影创建一个巨大的所有用户评级矩阵。 但是,在许多情况下,这将创建一个非常稀疏的矩阵。想想你的Netflix帐户,你看过他们的系列和电影总供应量的百分之几?这可能是一个相当小的百分比。然后,通过梯度下降,我们可以训练神经网络来预测每个用户对每部电影评分的高度。如果您想了解更多关于在推荐系统中使用深度学习的信息,请告诉我,我们可以进一步探讨。 总之,embedding layer是惊人的,不应该被忽视。

















 1663
1663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









