







为什么叫雪花算法
雪花是自然界中独一无二的,每一片雪花都有其独特的形状和结构。雪花算法生成的 ID 也具有唯一性。在分布式系统中,它能够为不同的对象或者事件生成唯一的标识符,就像每片雪花在众多雪花中独一无二一样。
雪花算法解析
结构图解
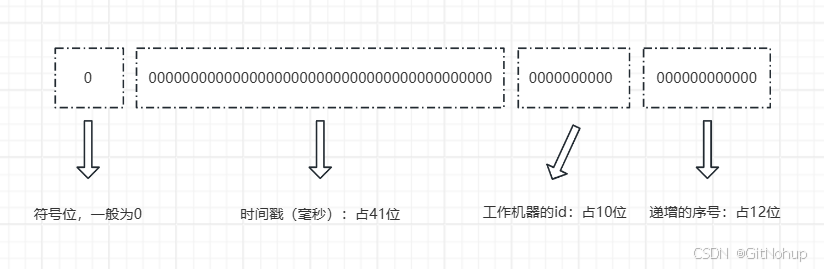
64位结构解析
- 1位符号位:用来表示正负,一般来说都是正数,所以值为0。
- 41位时间戳:以毫秒为单位,记录ID生成的时间。41位时间戳可以使用69年。2^41/(365×24×60×60×1000) ≈ 69.7年
- 10位机器id:可以部署在1024个节点,包括5位datacenterId和5位workerId。
- 12位递增序号:支持同一毫秒内同一个节点可以生成 2^12 = 4096 个ID。
时间戳:
雪花算法使用时间戳来保证ID的递增性。每次生成ID时,都会获取当前的时间戳,如果当前时间戳小于上一次生成ID的时间戳,算法会等待直到时间戳增加。
机器标识
机器标识由两部分组成:数据中心ID(datacenterId)和机器ID(workerId)。在不同机房和不同机器之间也能生成唯一的ID。
序列号
序列号用于在同一毫秒内生成多个ID。序列号从0开始,每次生成ID时递增,当达到最大值(4095)时,序列号归零,等待下一个毫秒的到来。
ID生成过程
- 当需要生成一个新的ID时,算法会获取当前的时间戳。
- 如果当前时间戳与上一次生成ID的时间戳相同,算法会使用序列号生成ID,并将序列号加1。
- 如果序列号超过了最大值(4095),算法会等待直到下一个毫秒的到来。
- 如果当前时间戳与上一次生成ID的时间戳不同,算法会重置序列号为0,并使用当前时间戳生成ID。
ID的唯一性和有序性
- 由于时间戳的递增性,即使在高并发情况下,生成的ID也是递增的。
- 机器标识和序列号的组合确保了在不同的机器和数据中心之间生成的ID的唯一性。
Java中如何使用雪花算法
这里演示使用hutool包封装的api使用方法。
先导入依赖:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>
public static void main(String[] args) {
/**
* 多机房的分布式项目使用
* 参数1:workerId 终端ID
* 参数2:dataCenterId 数据中心id
*/
long id1 = IdUtil.getSnowflake(12, 2).nextId();
/**
* 单机房的分布式项目使用
* 参数1:workerId 终端ID
*/
long id2 = IdUtil.getSnowflake(24).nextId();
/**
* 普通项目使用
*/
long id3 = IdUtil.getSnowflake().nextId();
System.out.println("Snowflake ID1: " + id1);
System.out.println("Snowflake ID2: " + id2);
System.out.println("Snowflake ID3: " + id3);
}
应用场景
雪花算法可以快速而稳定地生成唯一ID,并且还能保证ID的有序性和单调递增性,同时生成的id占用的空间较小,适合存储和传输。
雪花算法常应用于分布式高并发的系统中。数据库主键、分布式数据库主键、消息队列、分布式消息队列、分布式日志、分布式缓存等都可以使用。
时钟回拨问题
方法一:记录一个最大的时间戳,如果服务器发生了时钟回拨,则获取这个时间戳,生成id。
方法二:采用备用机切换,如果发现了时钟回拨,则把流量切到备用机器上。
最后,一旦发现时钟回拨问题,要记得生成告警,让人工介入处理。

















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









