







官方API接口使用方法参考:
查询历史数据API接口使用方法
查询当前数据API接口使用方法
该python脚本主要功能用于统计zabbix每个业务组下所有主机的磁盘每周使用增量情况
脚本内基本每一块实现什么功能都注释了,因为是也没怎么花时间去学习python,很多地方命令方法较为简陋,本博主照葫芦画瓢写的可优化地方很多,后续再花时间更新优化,目前初学的水平差不多就这样,刚刚接触python应该也看得懂把。
复制运行前,请全脚本看一下,有几个地方要手动修改一下。
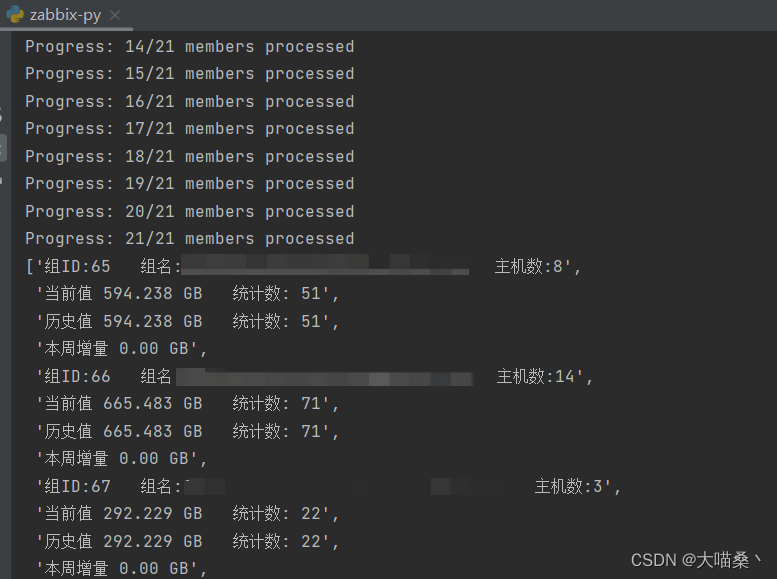
运行效果
from pprint import pprint
from pyzabbix.api import ZabbixAPI
import time
from datetime import datetime
from tqdm import tqdm
# 脚本运行时间
starttime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
start_time = time.time()
print("开始时间" + " " + starttime)
# zabbixAPI登录
zapi = ZabbixAPI(url='http://192.168.1.1/', user='Admin', password='SSSSS2')
# 创建组ID list-如果不清楚组id可以在下方的获取Group组信息pprint(group_list)
groupid_list = [65, 66, 67, 69, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87]
# 循环遍历组list内的业务信息
membersProcessed = 0
print_inf = []
disk_t = []
for groupid in groupid_list:
group_id = '组ID:' + str(groupid)
# 获取Group组信息
group = zapi.do_request('hostgroup.get', dict())
group_list = []
for r in group['result']:
group_list.append('组ID:' + r['groupid'] + ' ' + '组名:' + r['name'])
group_temp = [group_temp for group_temp in group_list if group_id in group_temp]
# 获取指定组ID下的所有主机ID
resp = zapi.do_request('host.get', dict(groupids=groupid))
list_hostid = [h['hostid'] for h in (resp['result'])]
hostnu = (len(list_hostid))
print_inf.append(group_list[group_list.index(group_temp[0])] + " " + "主机数:" + str(hostnu))
# 目录路径定义
keylist = [
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/boot,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/tmp,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/var/tmp,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},C:\,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/data,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/home,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/fsdatabase,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/fslog,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/newdata,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/opt,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/shared/log,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/shared/oslog,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/shared/shared,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/tmp,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/u01,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/var/log,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},/var/tmp,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},D:\,used]'",
"'vmware.vm.vfs.fs.size[{$VMWARE.URL},{$VMWARE.VM.UUID},E:\,used]'"
]
# 获取当前监控数据
item_temp = [(hosttemp, keytemp) for hosttemp in list_hostid for keytemp in keylist ]
list_item_host_id = []
list_itemvlue = []
for key_temp in item_temp:
items_temp10 = []
key_ins_h = ("zapi.do_request('item.get',dict(search={""\"key_\": " + (key_temp[1]) + "},hostids=" + (key_temp[0]) + "))")
items_temp1 = eval(key_ins_h)
list_itemvlue.append([q['lastvalue'] for q in (items_temp1['result'])])
items_temp10.append([h['hostid'] for h in (items_temp1['result'])])
items_temp10.append([h['itemid'] for h in (items_temp1['result'])])
list_item_host_id.append(sum(items_temp10, []))
# 当前数据嵌套List数据处理
while [] in list_item_host_id:
list_item_host_id.remove([])
while [] in list_itemvlue:
list_itemvlue.remove([])
item_t = str(len(list_itemvlue))
list_itemvlue_h = sum(list_itemvlue, [])
list_itemvlue_s = [int(x) for x in list_itemvlue_h]
list_itemvlue_q = sum(list_itemvlue_s) / 1024 / 1024 / 1024
# 历史数据获取
items_history = []
items_history_nu =[]
for v1 in list_item_host_id:
# list_item_host_id_ = lambda x, y: print(dict(zip(x, y)))
# list_item_host_id_(**dict(x=v1, y=v2))
items_v0 = []
items_v1 = []
items_temphis = zapi.do_request('trend.get', dict(hostids=v1[0], itemids=v1[1], time_from="1675212315",time_till="1675782000"))
items_v0.append([h['value_min'] for h in (items_temphis['result'])])
items_v1.append(items_v0[0])
items_history.append(items_v1[0][0])
items_history_nu.append(items_temphis)
# 历史数据嵌套List数据处理
while [] in items_history:
items_history.remove([])
his_t = str(len(items_history))
items_history_numbers = []
items_history_t = [int(x) for x in list_itemvlue_h]
for n in items_history_t:
items_history_numbers.append(int(n))
items_history = items_history_numbers
items_historyvlue_h = sum(items_history_numbers)
items_historyvlue_q = items_historyvlue_h / 1024 / 1024 / 1024
# 增量计算
disk_z = list_itemvlue_q - items_historyvlue_q
disk_t.append(disk_z)
# 循环输出业务信息
# print_inf.append(group_list[group_list.index(group_temp[0])] + " " + "主机数:" + str(hostnu))
print_inf.append("当前值" + " " + ('{:.3f} GB'.format(list_itemvlue_q)) + " 统计数: " + item_t)
print_inf.append("历史值" + " " + ('{:.3f} GB'.format(items_historyvlue_q)) + " 统计数: " + his_t)
print_inf.append("本周增量" + " " + ('{:.2f} GB'.format(disk_z)))
membersProcessed += 1
print('Progress: {}/{} members processed'.format(membersProcessed, len(groupid_list)))
# 脚本执行时间
endtime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
end_time = time.time()
run_time = ("%.2f" % ((end_time - start_time)/60))
pprint(print_inf)
print("完成时间" + " " + endtime + " " + "耗时 " + str(run_time) + "分钟")
disk_t_h = (sum(disk_t))
print("总增量" + " " + ('{:.3f} GB'.format(disk_t_h)))


















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









