




 本文详细介绍从日志收集、处理到数据分析的全过程。利用Flume实时收集日志,通过Kafka进行消息传递,最后借助Spark Streaming实现日志数据的实时清洗与分析。涵盖Flume配置、Kafka消费与Spark Streaming应用实例。
本文详细介绍从日志收集、处理到数据分析的全过程。利用Flume实时收集日志,通过Kafka进行消息传递,最后借助Spark Streaming实现日志数据的实时清洗与分析。涵盖Flume配置、Kafka消费与Spark Streaming应用实例。
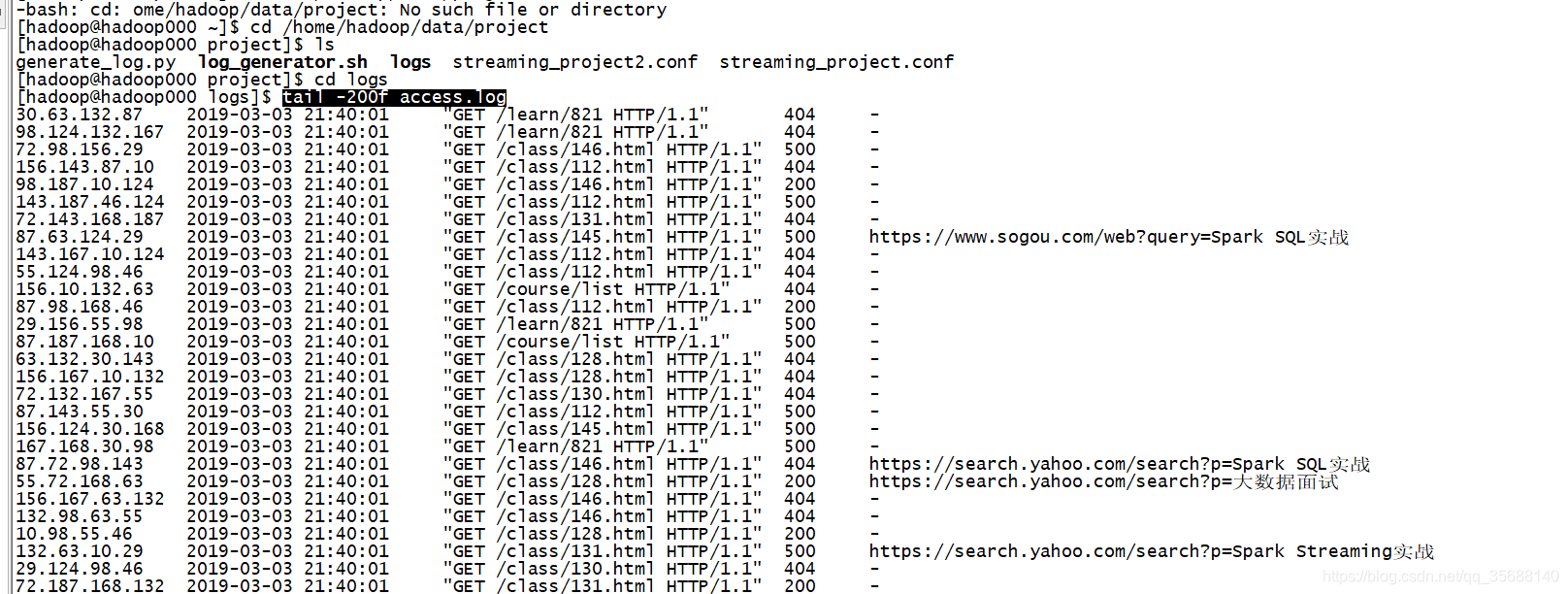
1.监控最新的日志
使用命令检测日志:
tail -200f access.log
2.编写flume的conf
vi streaming_project.conf
添加conf内容
exec-memory-logger.sources = exec-source
exec-memory-logger.sinks = logger-sink
exec-memory-logger.channels = memory-channel
exec-memory-logger.sources.exec-source.type = exec
exec-memory-logger.sources.exec-source.command = tail -F /home/hadoop/data/project/logs/access.log
exec-memory-logger.sources.exec-source.shell = /bin/sh -c
exec-memory-logger.channels.memory-channel.type = memory
exec-memory-logger.sinks.logger-sink.type = logger
exec-memory-logger.sources.exec-source.channels = memory-channel
exec-memory-logger.sinks.logger-sink.channel = memory-channel
启动flume
flume-ng agent --name exec-memory-logger --conf $FLUME_HOME/conf --conf-file /home/hadoop/data/project/streaming_project.conf -Dflume.root.logger=INFO,console
过一分钟产生日志:
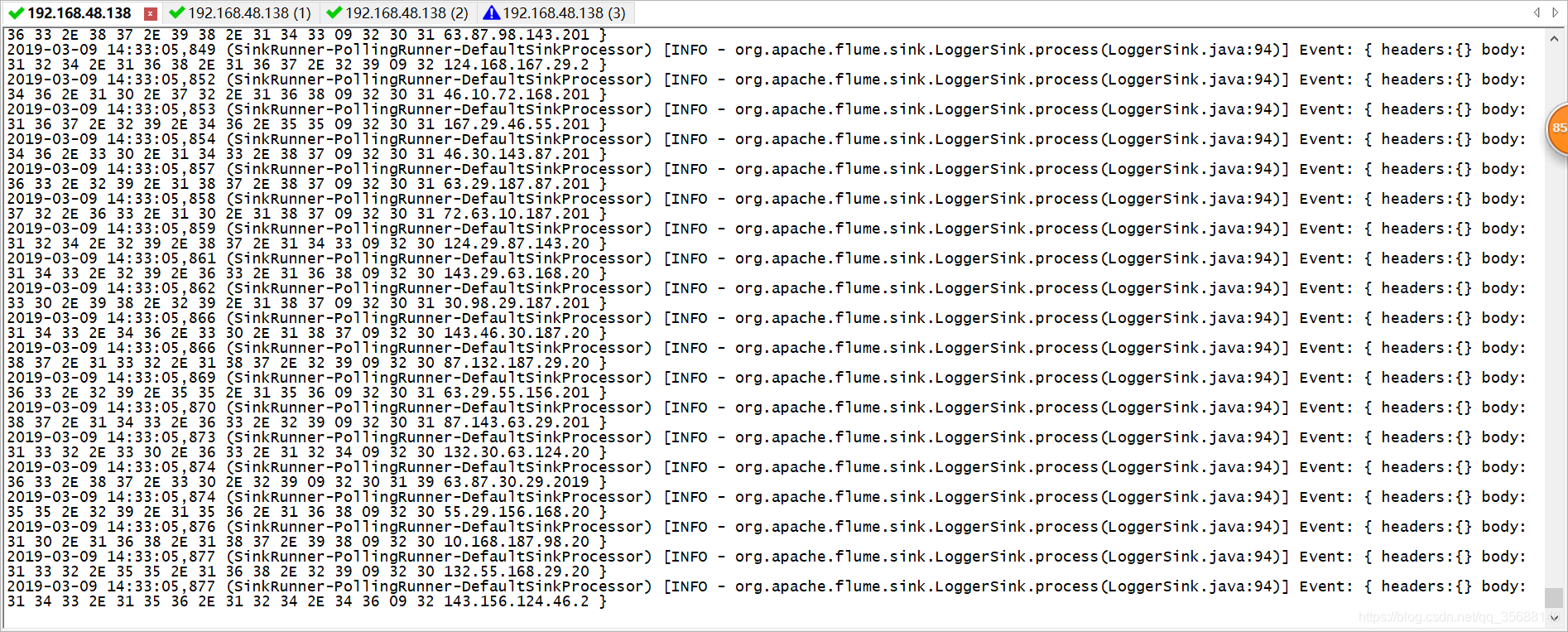
3.对接kafka
vi streaming_project2.conf
flume对接kafka
exec-memory-kafka.sources = exec-source
exec-memory-kafka.sinks = kafka-sink
exec-memory-kafka.channels = memory-channel
exec-memory-kafka.sources.exec-source.type = exec
exec-memory-kafka.sources.exec-source.command = tail -F /home/hadoop/data/project/logs/access.log
exec-memory-kafka.sources.exec-source.shell = /bin/sh -c
exec-memory-kafka.channels.memory-channel.type = memory
exec-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
exec-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
exec-memory-kafka.sinks.kafka-sink.topic = streamingtopic
exec-memory-kafka.sinks.kafka-sink.batchSize = 5
exec-memory-kafka.sinks.kafka-sink.requiredAcks = 1
exec-memory-kafka.sources.exec-source.channels = memory-channel
exec-memory-kafka.sinks.kafka-sink.channel = memory-channel
启动flume
flume-ng agent --name exec-memory-kafka --conf $FLUME_HOME/conf --conf-file /home/hadoop/data/project/streaming_project2.conf -Dflume.root.logger=INFO,console
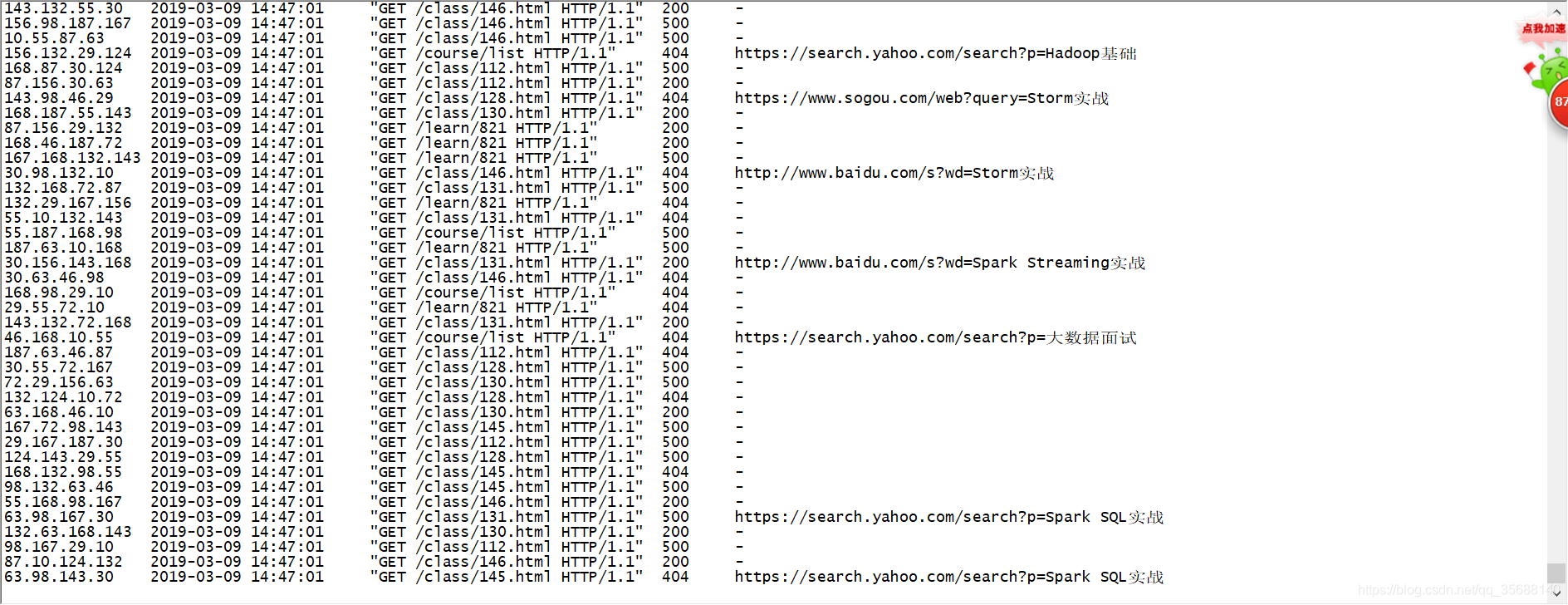
kafka消费
kafka-console-consumer.sh --zookeeper localhost:2181 --topic streamingtopic --from-beginning
4.sparkstreaming对接kafka
package com.qianliu
import org.apache.spark.SparkConf
import org.apache.spark.api.java.JavaSparkContext
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Spark Streaming对接Kafka
*/
object KafkaStreamingApp {
def main(args: Array[String]): Unit = {
//判断输入的数据长度是否符合要去
if(args.length != 4) {
System.err.println("Usage: KafkaStreamingApp <zkQuorum> <group> <topics> <numThreads>")
}
//初始化输入的数据为Array
val Array(zkQuorum, group, topics, numThreads) = args
//初始化sparkcontext
val sparkConf = new SparkConf().setAppName("KafkaReceiverWordCount")
.setMaster("local[2]")
sparkConf.set("spark.testing.memory", "512000000")
//sparkstreamingcontext
val ssc = new StreamingContext(sparkConf, Seconds(60))
//将多个topic输入
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
// TODO... Spark Streaming如何对接Kafka
val messages = KafkaUtils.createStream(ssc, zkQuorum, group,topicMap)
// TODO... 自己去测试为什么要取第二个
messages.map(_._2).count().print()
//启动spark
ssc.start()
ssc.awaitTermination()
}
}
每一分钟100条结果,符合我们的模拟的数据产生速率:
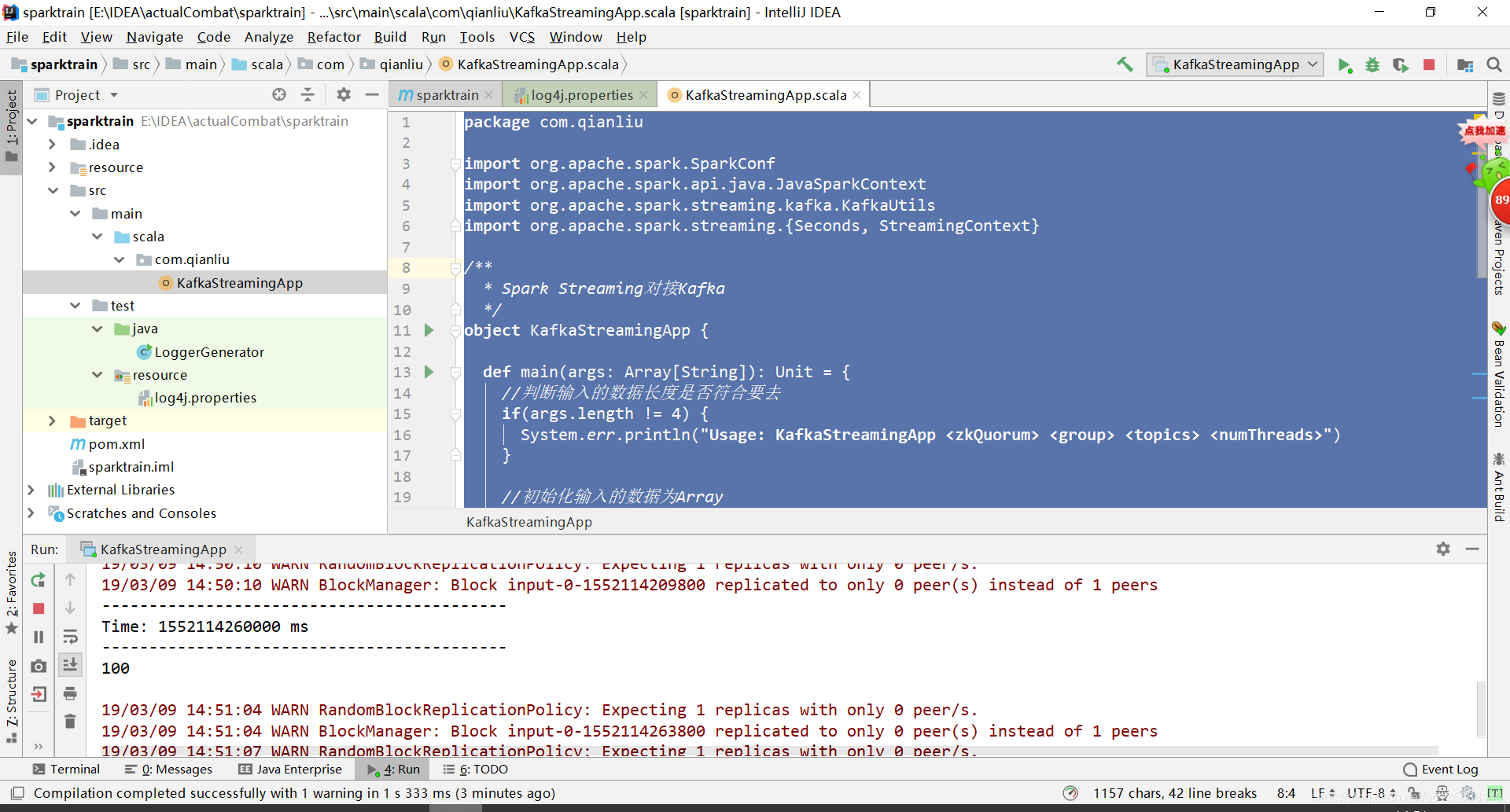
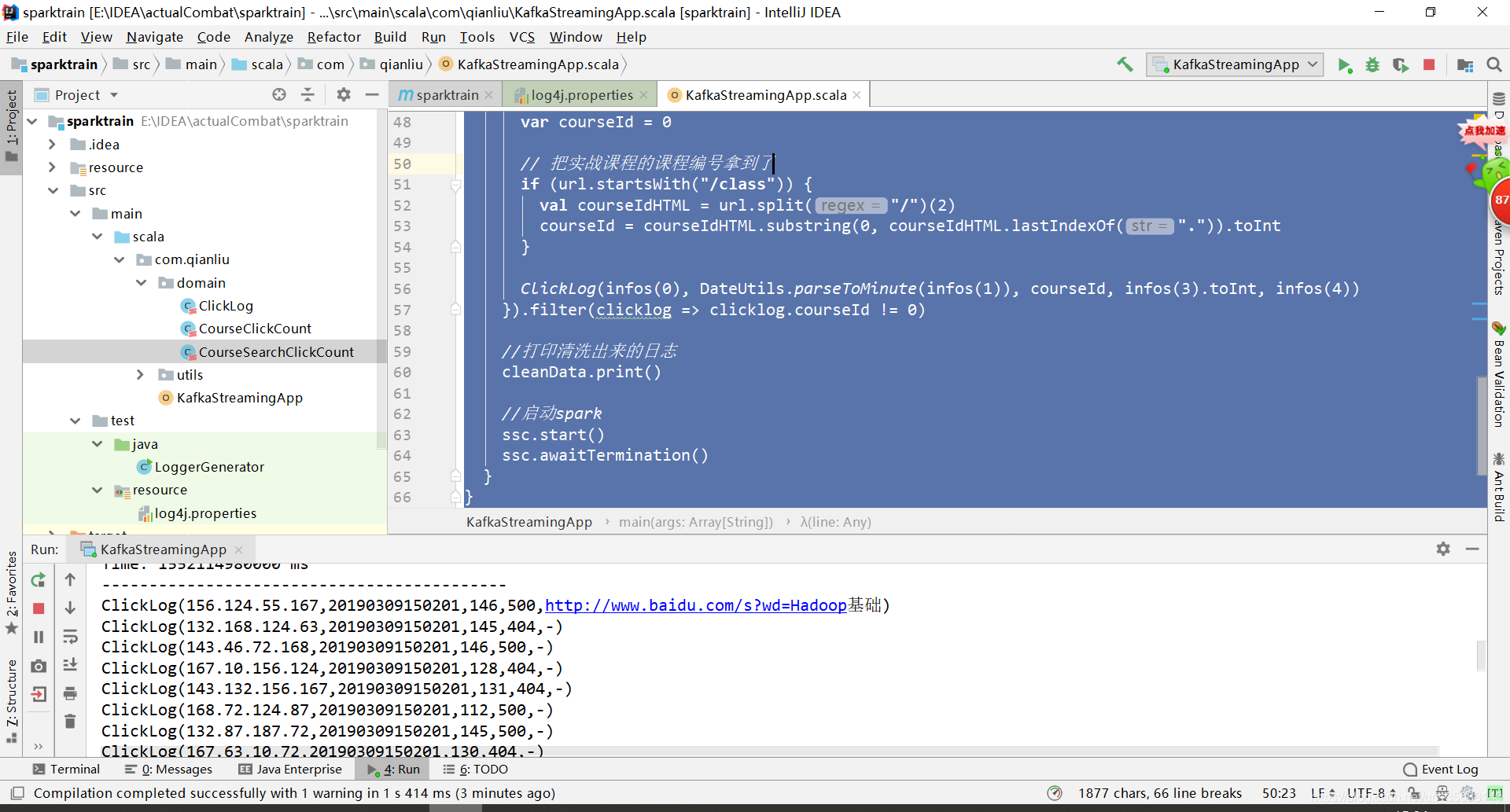
5.清洗数据
package com.qianliu
import com.qianliu.domain.ClickLog
import com.qianliu.utils.DateUtils
import org.apache.spark.SparkConf
import org.apache.spark.api.java.JavaSparkContext
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Spark Streaming对接Kafka
*/
object KafkaStreamingApp {
def main(args: Array[String]): Unit = {
//判断输入的数据长度是否符合要去
if(args.length != 4) {
System.err.println("Usage: KafkaStreamingApp <zkQuorum> <group> <topics> <numThreads>")
}
//初始化输入的数据为Array
val Array(zkQuorum, group, topics, numThreads) = args
//初始化sparkcontext
val sparkConf = new SparkConf().setAppName("KafkaReceiverWordCount")
.setMaster("local[2]")
sparkConf.set("spark.testing.memory", "512000000")
//sparkstreamingcontext
val ssc = new StreamingContext(sparkConf, Seconds(60))
//将多个topic输入
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
// TODO... Spark Streaming如何对接Kafka
val messages = KafkaUtils.createStream(ssc, zkQuorum, group,topicMap)
// TODO... 自己去测试为什么要取第二个
//messages.map(_._2).count().print()
//数据清洗
val logs = messages.map(_._2)
val cleanData = logs.map(line => {
val infos = line.split("\t")
// infos(2) = "GET /class/130.html HTTP/1.1"
// url = /class/130.html
val url = infos(2).split(" ")(1)
var courseId = 0
// 把实战课程的课程编号拿到了
if (url.startsWith("/class")) {
val courseIdHTML = url.split("/")(2)
courseId = courseIdHTML.substring(0, courseIdHTML.lastIndexOf(".")).toInt
}
ClickLog(infos(0), DateUtils.parseToMinute(infos(1)), courseId, infos(3).toInt, infos(4))
}).filter(clicklog => clicklog.courseId != 0)
//打印清洗出来的日志
cleanData.print()
//启动spark
ssc.start()
ssc.awaitTermination()
}
}
查看结果:

















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









