







背景
随着行业内AI战略的铺开。 知识的存储跟表达也有了新的标准。对于向量数据产生了存储检索的需求。向量这个数学表达,在目前是人与AI交互的中间媒介。 所以我们有必要深入探讨向量数据库,并对当前主流的数据库做一些对比分析。
什么是向量数据库?
简单下个定义,因为喂给Transformer的知识首先需要做embedding,所以用于存储embedding之后数据的数据库即可称为向量数据库。
向量数据库需要解决什么问题?因为向量数据库是基于embedding之后的向量的存储与检索。所以首先需要提供存储能力,其次更重要的是检索。
即如何根据一个query快速找到相关的embedding内容。
关于检索,主要是计算两个向量之间的相似度。
推荐的计算两个向量之间距离推荐的算法为: 余弦相似度函数, 其表达式如下:
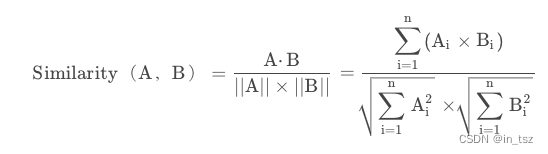
常见的向量数据库
向量检索是一个革命性的技术,使得开发者和工程师可以将知识或数据向量化之后实现更有效的存储、检索以及推荐。
通过对比这些向量两两之间的相似性,可以实现快速、直观、无缝的信息检索。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









