







一、 Flume 简介
1 Flume 提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume 只能在 Unix 环境下运行。
2 Flume 基于流式架构,容错性强,也很灵活简单。
3 Flume、 Kafka 用来实时进行数据收集, Spark、 Storm 用来实时处理数据, impala 用来实时查询。
二、 Flume 角色
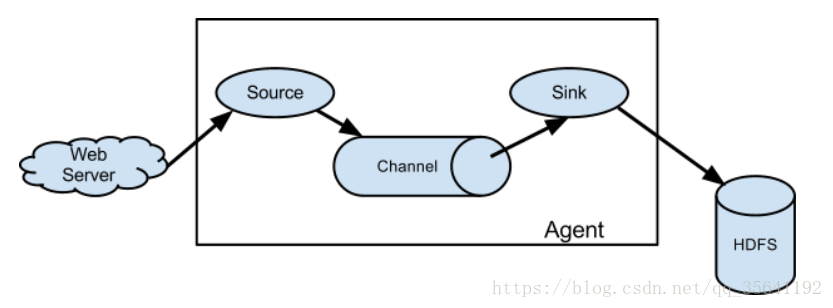
1、 Source
用于采集数据, Source 是产生数据流的地方,同时 Source 会将产生的数据流传输到 Channel,这个有点类似于 Java IO 部分的 Channel。
2、 Channel
用于桥接 Sources 和 Sinks,类似于一个队列。
3、 Sink
从 Channel收集数据,将数据写到目标源(可以是下一个 Source,也可以是 HDFS或者 HBase)。
4、 Event
传输单元, Flume 数据传输的基本单元,以事件的形式将数据从源头送至目的地。
三、 Flume 传输过程
source 监控某个文件或数据流,数据源产生新的数据,拿到该数据后,将数据封装在一个Event 中,并 put 到 channel 后 commit 提交, channel 队列先进先出, sink 去 channel 队列中拉取数据,然后写入到 HDFS 中。
四、 Flume 部署
1、解压文件
tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
2、文件配置
flume-env.sh 涉及修改项:
pwd
/opt/module/apache-flume-1.7.0-bin/conf
mv flume-env.sh.template flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_151
















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









