







hive报错记录之:

hive是依托于hadoop的,因此需要去先启动hadoop的相关命令:
先把hadoop下面的守护进程全部启动:
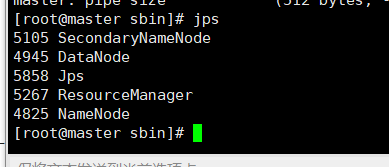
出现了新的错误:
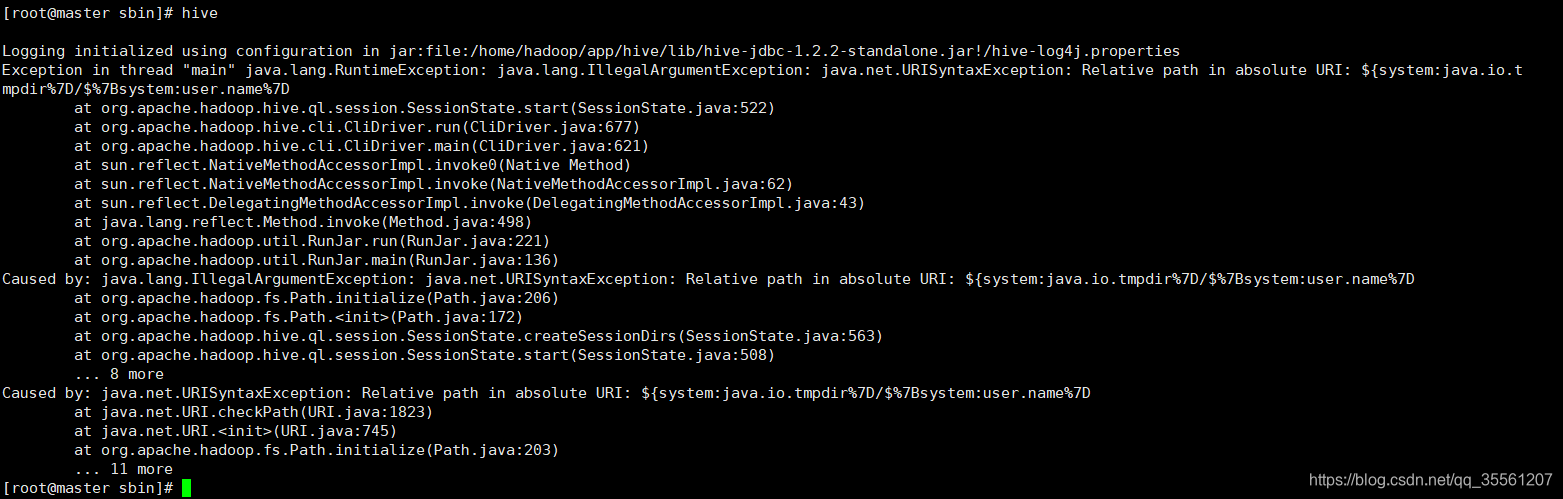
出现了新问题,hive的临时目录没有设置好;
解决方案如下所示:
https://blog.youkuaiyun.com/wodedipang_/article/details/72718138
出现了新问题:

相关的过程如下所示:
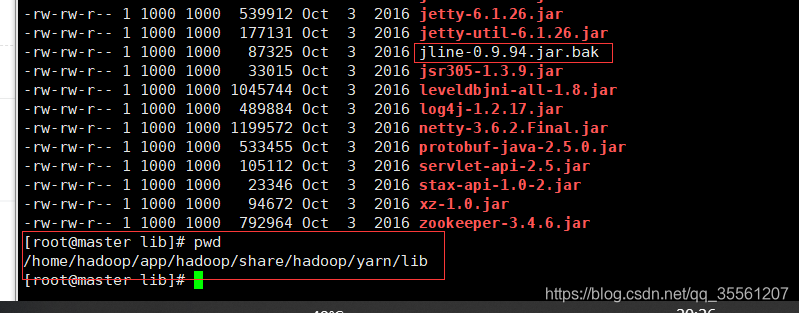
将该路径下的jar删除,或者改变为备份形式。
重启hadoop集群,以及hive即可
过程如下所示;
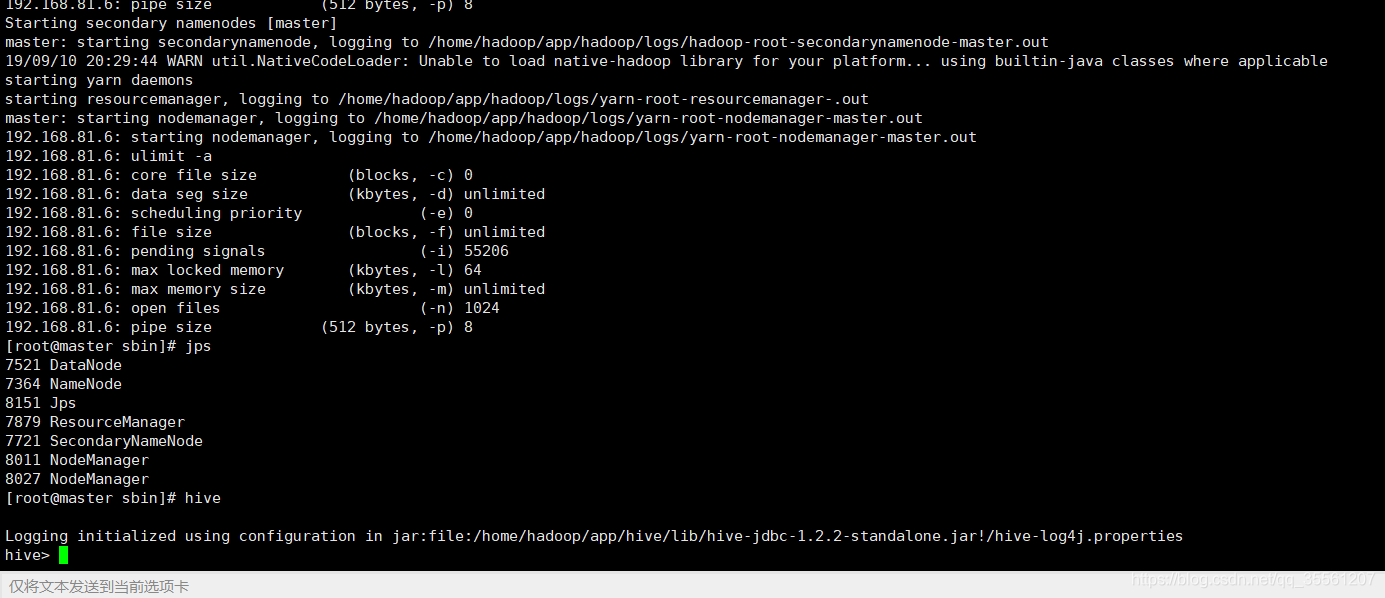
hive自此启动成功。

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









