









 本文介绍了如何使用Python的priority_queue和unordered_map数据结构解决LeetCode上的问题,即找出数据集中出现次数最多的前k个元素。通过先统计元素频率,然后构造大顶堆或小顶堆进行操作,适合面试和技术面试准备。
本文介绍了如何使用Python的priority_queue和unordered_map数据结构解决LeetCode上的问题,即找出数据集中出现次数最多的前k个元素。通过先统计元素频率,然后构造大顶堆或小顶堆进行操作,适合面试和技术面试准备。
顶堆priority_queue使用(数据中出现次数最多的前k个元素)
1、priority_queue用法
转自:https://www.cnblogs.com/yalphait/articles/8889221.html


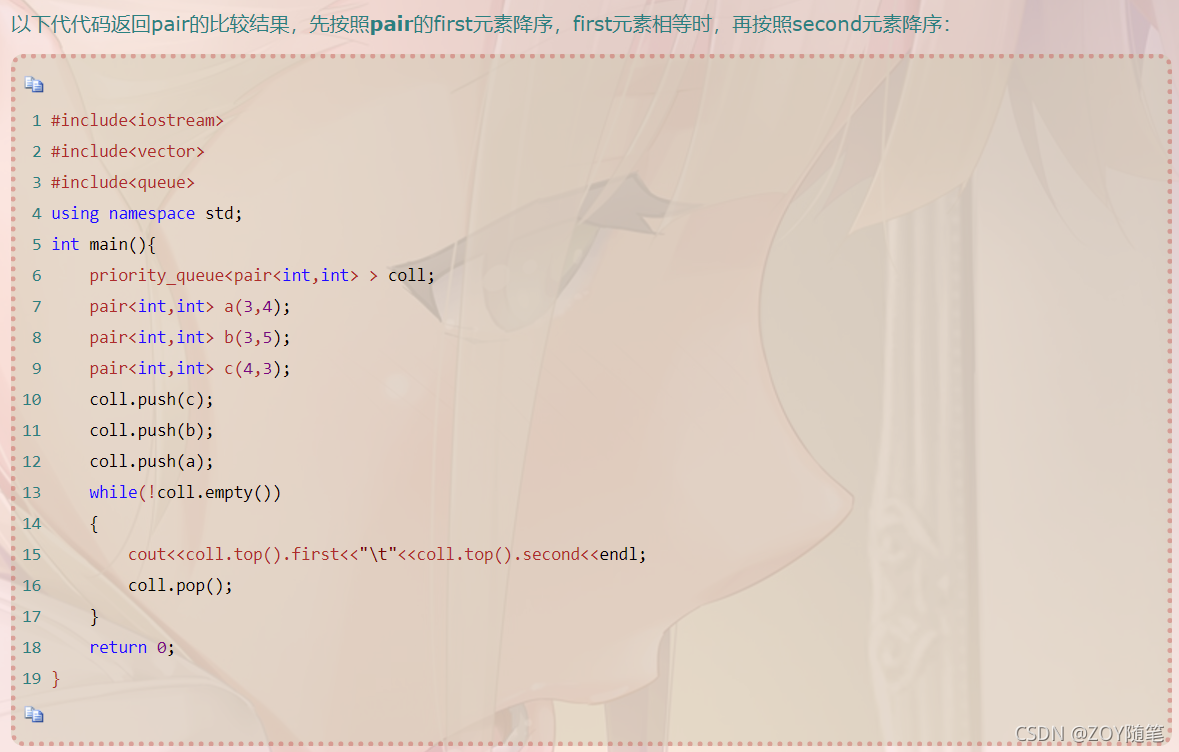
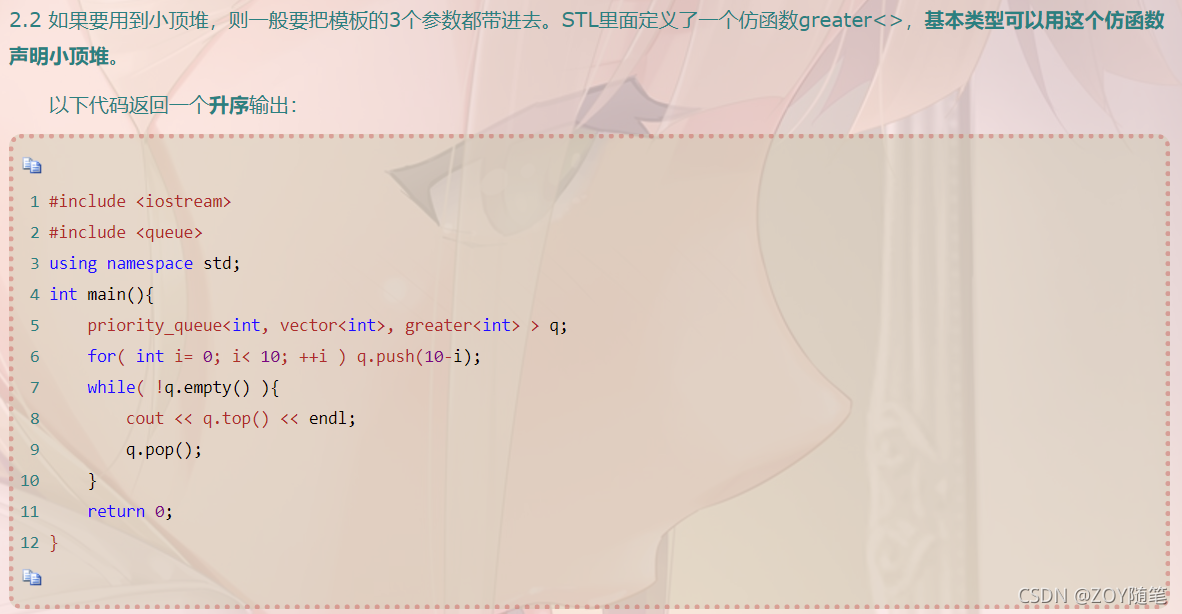
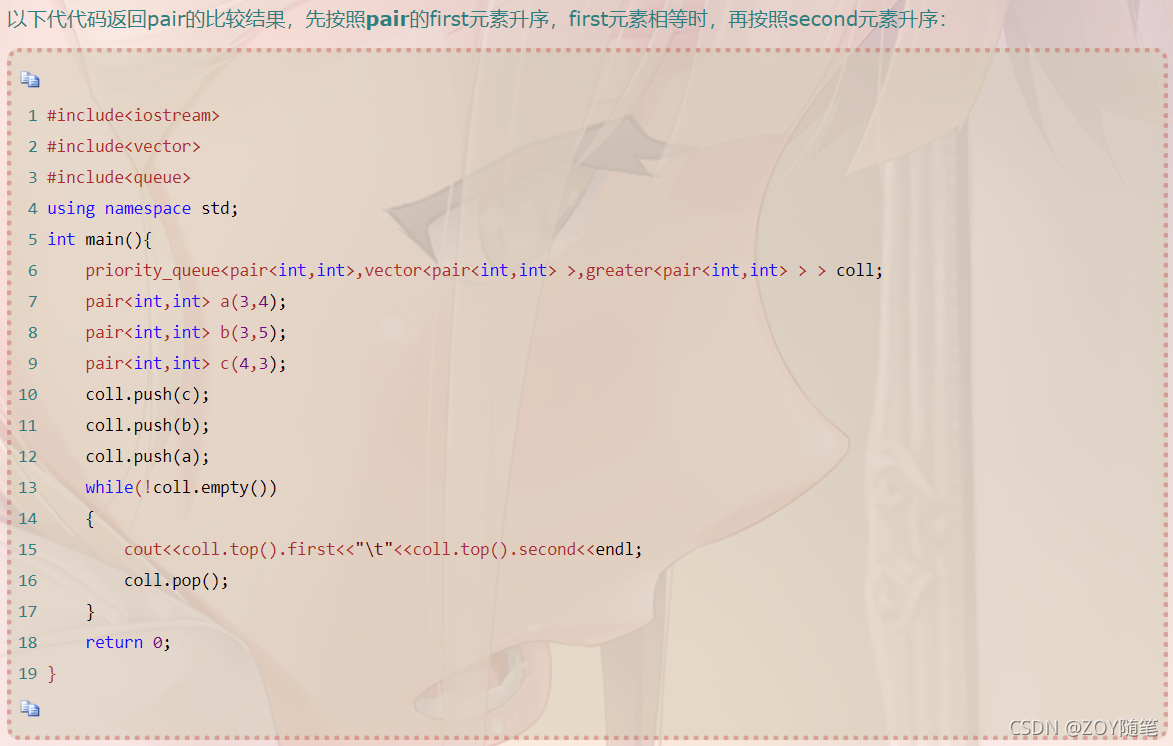
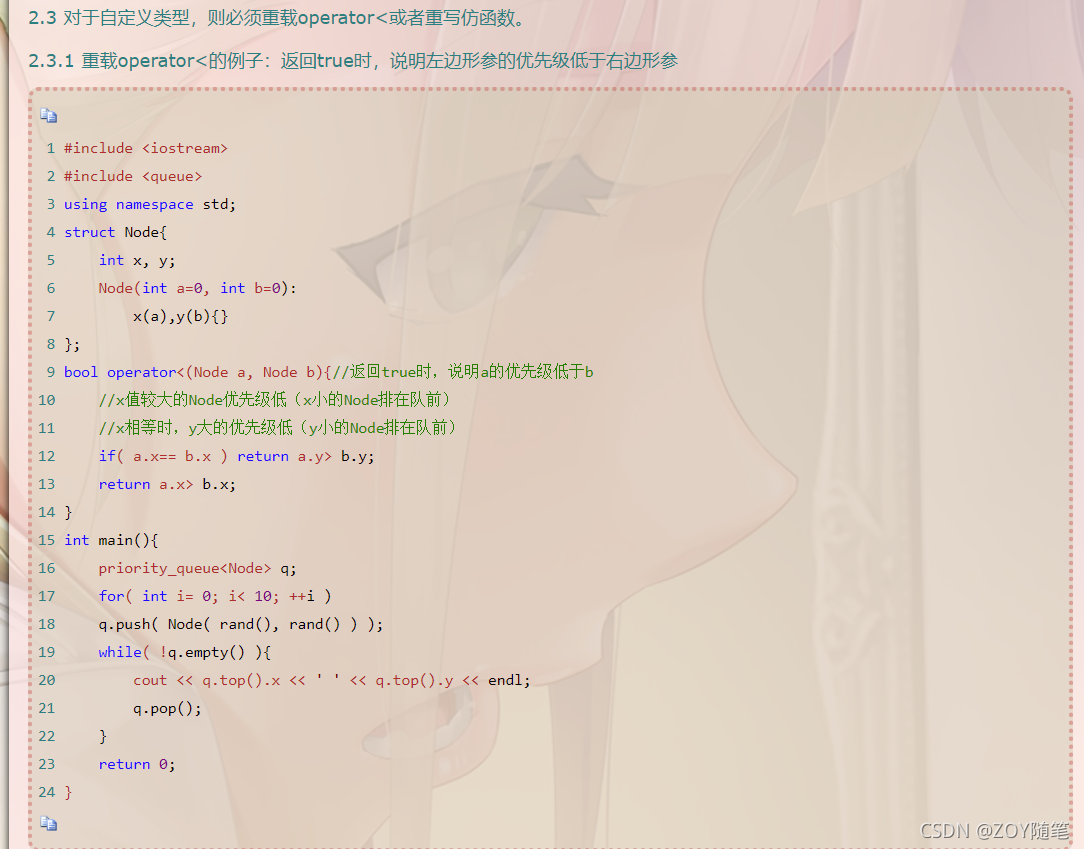
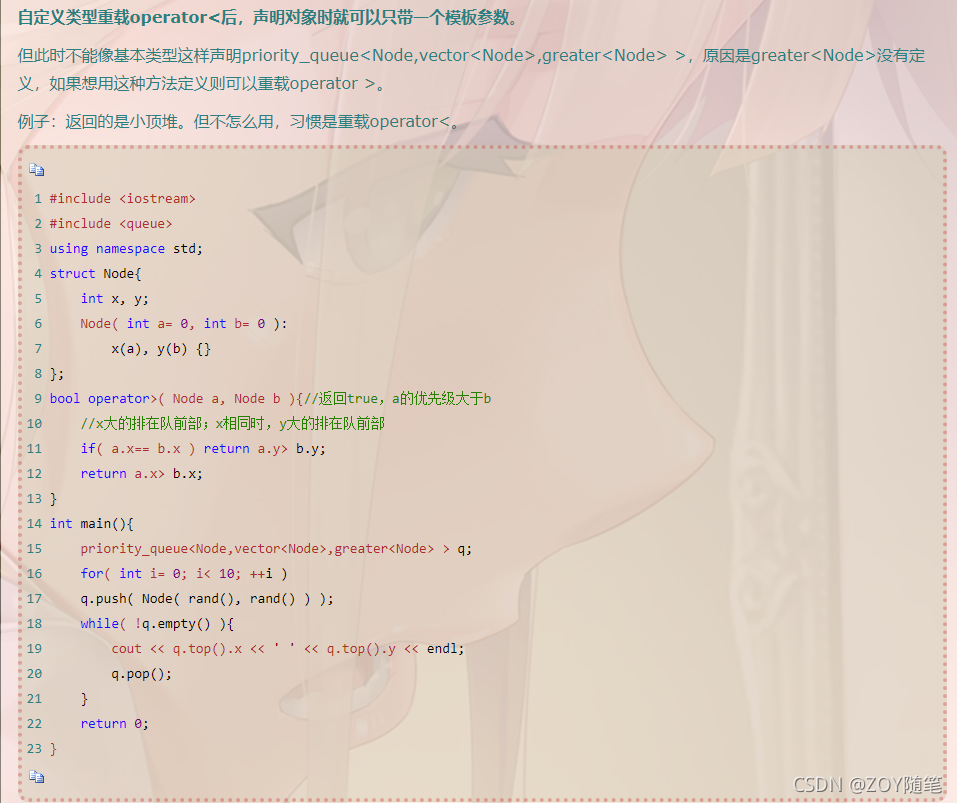
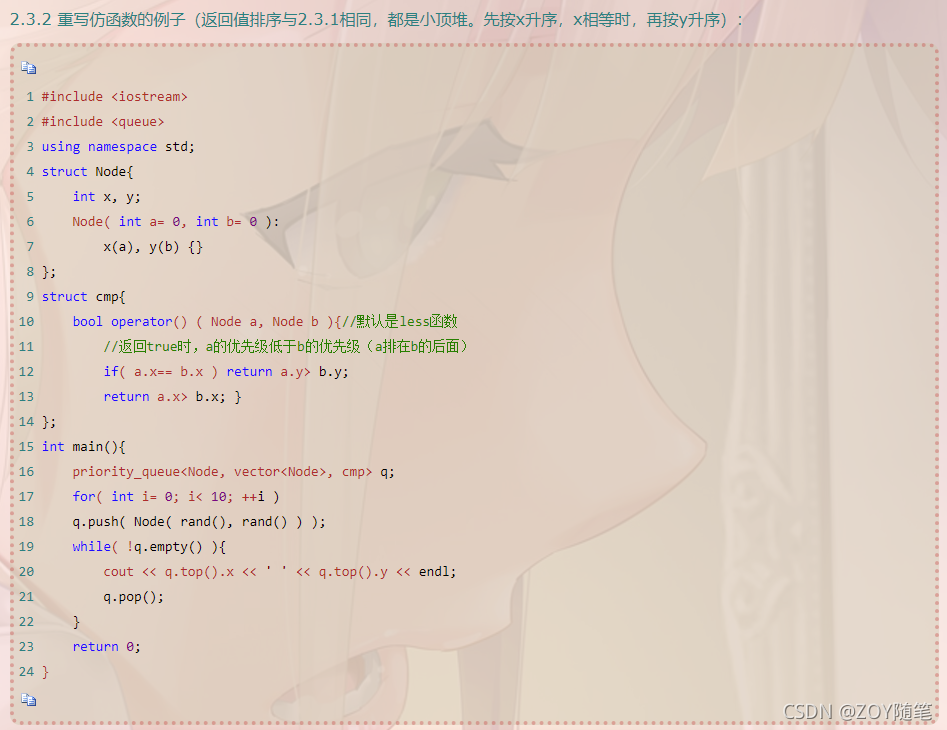
2、举例(数据中出现次数最多的前k个元素)
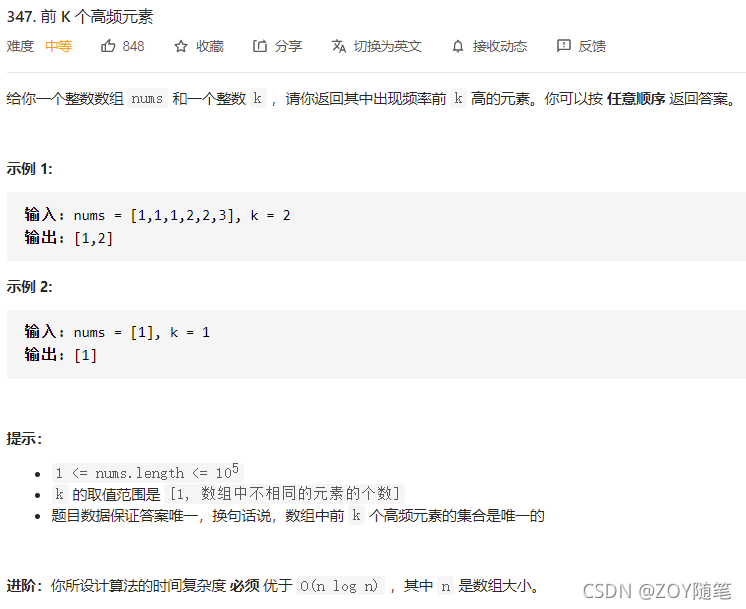
https://leetcode-cn.com/problems/top-k-frequent-elements/
/*
* 模板申明带3个参数:priority_queue<Type, Container, Functional>,其中Type 为数据类型,Container为保存数据的容器,Functional 为元素比较方式。
* Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector。
* 比较方式默认用operator<,所以如果把后面2个参数缺省的话,优先队列就是大顶堆(降序),队头元素最大。特别注意pair的比较函数。
*/
//一堆元素中,出现次数最多(最少的前k个元素) :: hash+小顶堆(大顶堆)
// 先一次遍历将各元素出现次数存入hash表中,pair的key值为元素,value值为出现次数
//再遍历一次hash表,将hash表中队组放大大顶堆中,大顶堆自定义排序(按照队组第二个元素排序)
//hash表实现:unordered_map或者unordered_set
//堆实现:priority_queue ,默认大顶堆,即降序,写一个参数即可eg:priority_queue<int>
//小顶堆实现:eg:priority_queue<int, vector<int>, greater<int> > q; 升序
//priority_queue使用类似queue,头文件也是#include <queue>
class Mycompare{ //自定义优先队列priority_queue的仿函数
public:
bool operator()(const pair<int,int>&p1,const pair<int,int>&p2)const
{
return p1.second<p2.second;
}
};
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
if(k<=0||nums.empty())
return {};
if(k>nums.size()-1)
return nums;
vector<int>ans; //结果
unordered_map<int,int>hash; //hash表用来记录各元素出现次数
priority_queue <pair<int,int>,vector<pair<int,int>>,Mycompare> q;
//先遍历一遍,元素及次数存入hash表
for(int x:nums)
{
auto pos=hash.find(x);
if(pos!=hash.end()) //存在value值++
{
++pos->second;
}
else //不存在插入
{
hash.insert(pair<int,int>(x,1));
}
}
for(unordered_map<int,int>::iterator it=hash.begin();it!=hash.end();it++)
{
q.push(*it);
}
for(int i=0;i<k;i++)
{
ans.push_back(q.top().first);
q.pop();
}
return ans;
};
};
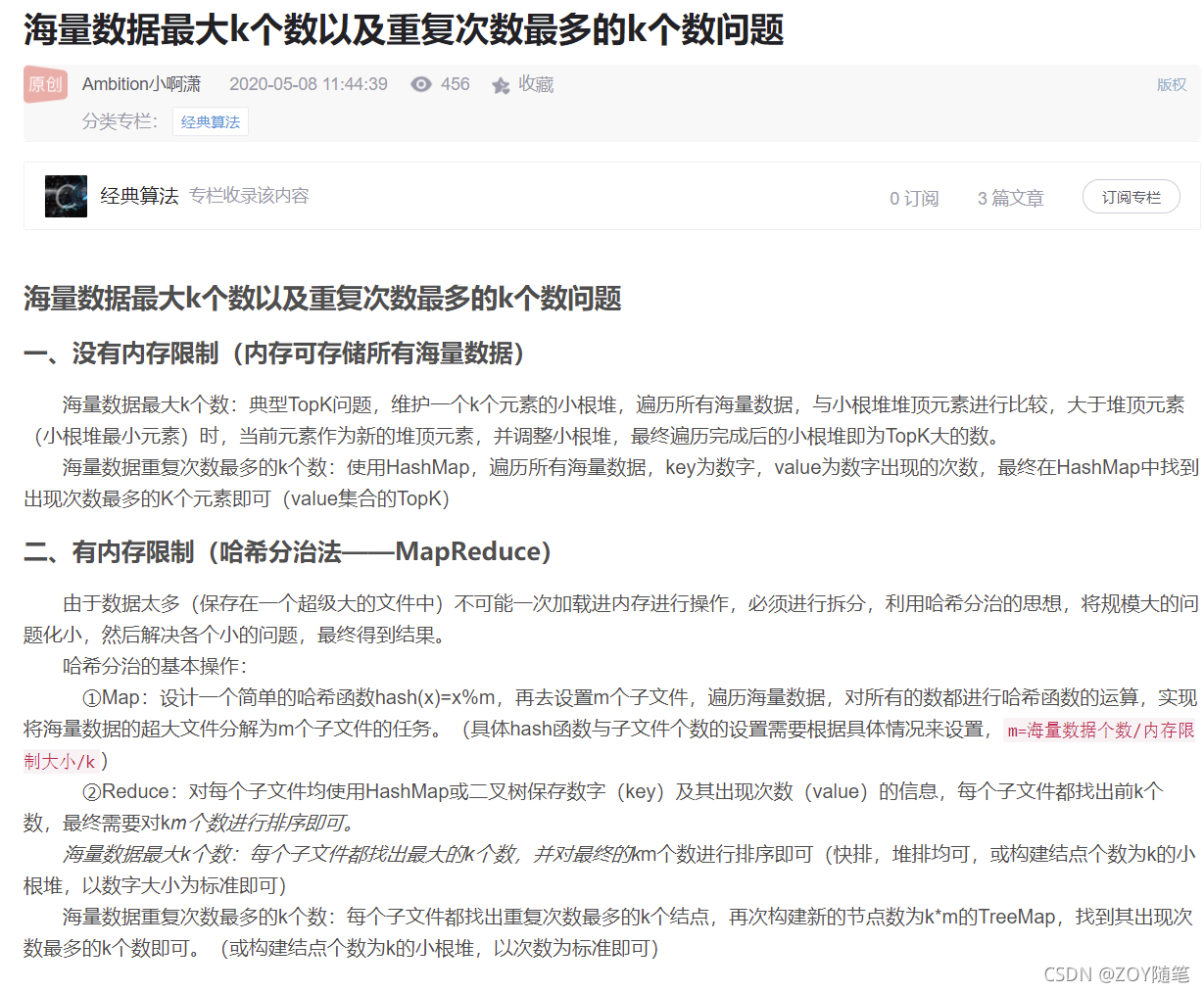
3、面试补充
转自:https://blog.youkuaiyun.com/weixin_43490440/article/details/105991036


















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











