







 Bi-RealNet是一种新型1-bit CNN模型,通过shortcut传递实数值以增强表达能力和改进训练算法,使分类精度在ImageNet上显著提升,达到62.4%的top-1精度。
Bi-RealNet是一种新型1-bit CNN模型,通过shortcut传递实数值以增强表达能力和改进训练算法,使分类精度在ImageNet上显著提升,达到62.4%的top-1精度。
Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm
2018 ECCV
香港科技 腾讯 华科
Paper:https://arxiv.org/abs/1808.00278v5
Code:https://github.com/liuzechun/Bi-Real-net
摘要
高效的1-bit CNN相比全精度的CNN在大规模的数据集上的分类精度损失太多,为了最小化1-bit CNN模型与全精度CNN模型之间的性能差距,我们提出了一种新的名为Bi-Real Net的模型,用 shortcut传递网络中已有的实数值,从而提高二值化网络的表达能力,并且改进了现有的 1-bit CNN 训练方法。首先,我们推导出符号函数对于激活的导数的一个严格的近似值。其次,我们提出了一个与权值相关的幅度感知梯度来更新权值参数。第三,我们通过clip函数对实值CNN模型进行预训练,而不是ReLU函数,更好的初始化Bi-Real Net。试验结果表明,18层Bi-Real Net在ImageNet数据集上达到56.4%的top-1分类精度,比baseline XNOR Net相对高了10%。并且更深的34层 Bi-Real Net达到了62.4%的top-1分类精度。
1 引言
深度卷积神经网络(CNN)由于精度高在视觉任务中已经有非常广泛的应用,但是 CNN的模型过大限制了它在很多移动端的部署。模型压缩也因此变得尤为重要。在模型压缩方法中,将网络中的权重和激活都只用+1 或者-1 来表示将可以达到理论上的32倍的存储空间的节省和58倍的加速效果。由于它的权重和激活都只需要用1-bit 表示,因此极其有利于硬件上的部署和实现。然而现有的二值化压缩方法在 ImageNet 这样的大数据集上会有较大的精度下降。我们认为,这种精度的下降主要是有两方面造成的:(1)1-bit CNN的表达能力本身很有限,不如实数值的网络;(2) 1-bit CNN 在训练过程中有导数不匹配的问题导致难以收敛到很好的精度。
一个重要的观察是,在推理过程中,由于位计数操作,1位卷积层产生整数输出。如果有一个BatchNorm层,则整数输出将变成实值。但是这些实值激活通过连续符号函数变成了二值化的-1或+ 1,如下图的(a),显然,与二进制激活相比,这些整数或实数激活包含更多的信息,而传统的1-bit CNN丢失了。受此启发,我们建议通过添加一个简单而有效的shortcut保持这些实值的激活,如图(b)所示,该shortcut将实值激活连接到加法运算符,当前1bit convolution或BN输出的实数结果与下一个1bit convolution或BN输出的实数结果直接相加。通过这样做,所提出的模型的表示能力比原来的1-bit CNNs高得多,只增加了微不足道的计算成本,而没有任何额外的内存成本。
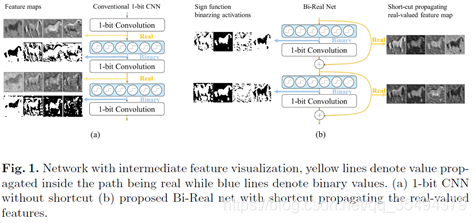
此外,文章还提出了一种新的1位CNNs训练算法,包括三个技术创新点: (1)推导出符号函数对于激活的导数的一个严格的近似值。(2)我们提出了一个与权值相关的幅度感知梯度来更新权值参数。(3)我们通过clip函数对实值CNN模型进行预训练,而不是ReLU函数,更好的初始化Bi-Real Net。
2 方法
2.1 Standard 1-bit CNNs and Its Representational Capability
1-bit CNN 网络主要指在CNN网络中间的卷积层中权重参数和响应值都是二值的,二值化是通过 sign 函数完成的
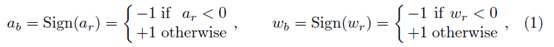
因为卷积和 batch normalization(如果使用的话),1-bit CNN中的训练和推理阶段的响应为实数值。图2显示给定一个二值响应图和一个二值的卷积核,则输出的响应是位于正负9的一个奇数。如果batch normalization 使用了,那么整数响应将被映射为实数。在训练阶段实数权重被用于更新二值权重。和32位的权重参数表示的实数CNN模型相比较,1-bit CNN网络模型大小减少了32倍多。更重要的是,因为响应也是二值的,所以卷积操作可以通过位运算XNOR操作和一个 bit-count 操作(在BNN中有介绍),而实数CNN模型中的卷积操作是通过实数乘法完成的,所以 1-bit CNN模型计算量减少了近 64倍,但是二值网络的精度下降的比较多,尤其在大型数据库上如 ImageNet。我们认为这主要是因为二值网络的表达能力较差。实数可以表示更多的可能的布局,而二值网络相比于实数网络能够表示的布局要少很多。
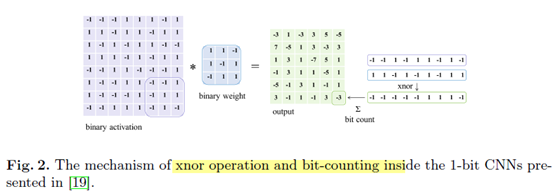
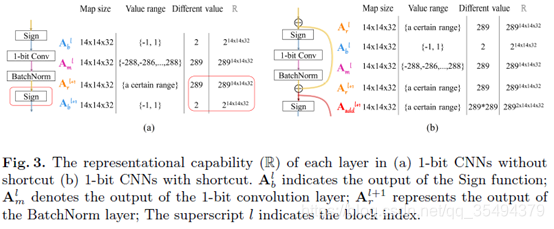
2.2 Bi-Real Net Model and Its Representational Capability
在使用二值化符号函数之前使用一个简单的shortcut来保留实数响应(借鉴了残差网络),这样可以增加 1-bit CNN的表征能力。该shortcut将实值激活连接到加法运算符,当前1bit convolution或BN输出的实数结果与下一个1bit convolution或BN输出的实数结果直接相加。通过这样做,模型的表示能力比原来的1-bit CNNs高得多,只增加了微不足道的计算成本,而没有任何额外的内存成本。
2.3 网络训练
因为激活和权重参数都是二值的,连续函数优化方法如随机梯度下降 (SGD)不能被直接用于训练 1-bit CNN。主要存在两个问题:
- 在激活上如何计算符号函数的梯度,因为符号函数不连续;
- 二值权重的损失函数梯度因为太小导致难以改变权重的符号。
对于问题1,文献(Advances in Neural Information Processing Systems)提出使用分段线性函数的梯度来近似符号函数的梯度。对于问题2,使用实值权重来进行权重更新计算。这里我们提出一个新的训练算法和一个新的初始化方法。
网络的训练过程如图4所示:权重更新的是实值权重,前向推理的采用二值的权重。
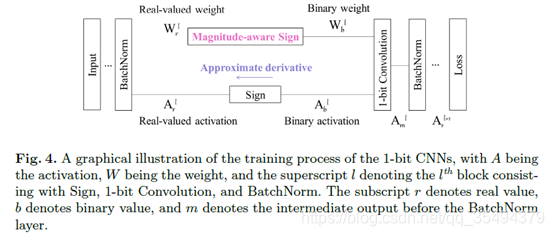
2.3.1关于响应的符号函数导数的近似
使用分段多项函数代替clip函数近似估计符号函数,梯度的计算如图5所示:

2.3.2权重的幅度感知梯度
标准的梯度下降算法不能被直接应用,因为梯度值太小,不能改变二值权重。为了解决这个问题,文献(Advances in Neural Information Processing Systems)在训练阶段引入一个实数权重矩阵和一个符号函数,那么对这个实数权重矩阵进行二值化就可以得到二值权重参数矩阵。在反向传播时,实数参数矩阵就可以通过梯度下降方法进行更新。梯度只和实数参数矩阵的符号相关,和实数参数矩阵的幅值无关。
基于这个观察,我们提出幅度感知函数代替上面的符号函数。这样梯度和实数参数矩阵的符号和幅值都相关。
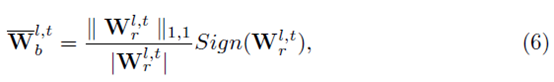
最终用于更新实数权重的递归公式如下:
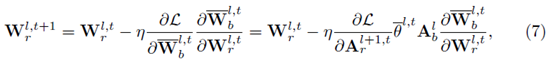
其中更新步长中的乘积项为Loss关于实数激活的梯度、BN层Gamma系数、二值激活、以及Magnitude-aware Sign操作的梯度。Magnitude-aware Sign操作的梯度,即二值权重关于实数权重的梯度表示为(Sign函数的求导仍然采用Clip函数近似):
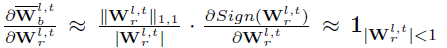
由于模型在推理部署阶段,实数权重的二值化仍然采用常规的Sign操作,因此采用Magnitude-aware Sign操作训练模型并收敛之后,需要采用Sign操作额外训练若干epoch更新BN层moving参数(此时learning rate置零),以适应实际部署的需求。
2.3.3初始化方法
由于二值网络的二值化输出为{-1,1},不包含零元素,故在更新预训练模型的参数时,选择clip函数替代ReLU作为非线性激活函数能够获得更好的初始化效果。同时在二值网络的训练阶段,权重衰减置零,即不需要对实数权重作L1或L2正则化约束。并且两个one layer per block的shortcut结构要优于一个two layer per block的shortcut结构。
3 实验
3.1 准确度
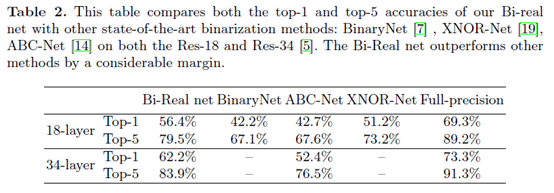
3.2 计算效率和内存占用分析
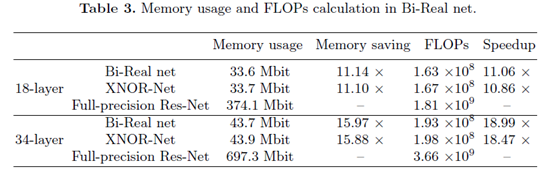
4 结论
这篇文章针对XNOR-net的缺陷,在网络结构及优化训练方面做了一系列增强与改进,具体包括引入one layer per block形式的shortcut连接、采用二次函数拟合实数激活的sign操作、在更新实数权重时引入实数权重的幅度、以及预训练模型采用clip函数替代ReLU予以训练,从而在实现网络权重与激活输出二值化的同时,确保了大型数据集(ILSVRC ImageNet)上有较高的精度,相比最早的二值化网络有较大的提升,相比全精度网络,还是有很大的差距,有10%的精度损失。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









