




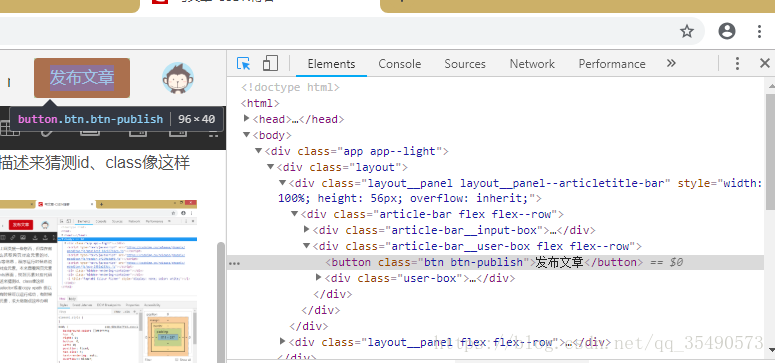
最近刚学爬虫,准备上网页搜一些东西,但是在做的过程中不知道怎么抓取网页对应元素的id、name、xpath、class等信息,程序运行时候总说信息是错的,找不到对应元素。本来查看网页元素的方式是打开elements界面,找到元素对应代码所在位置看代码的描述来猜测id、class像这样
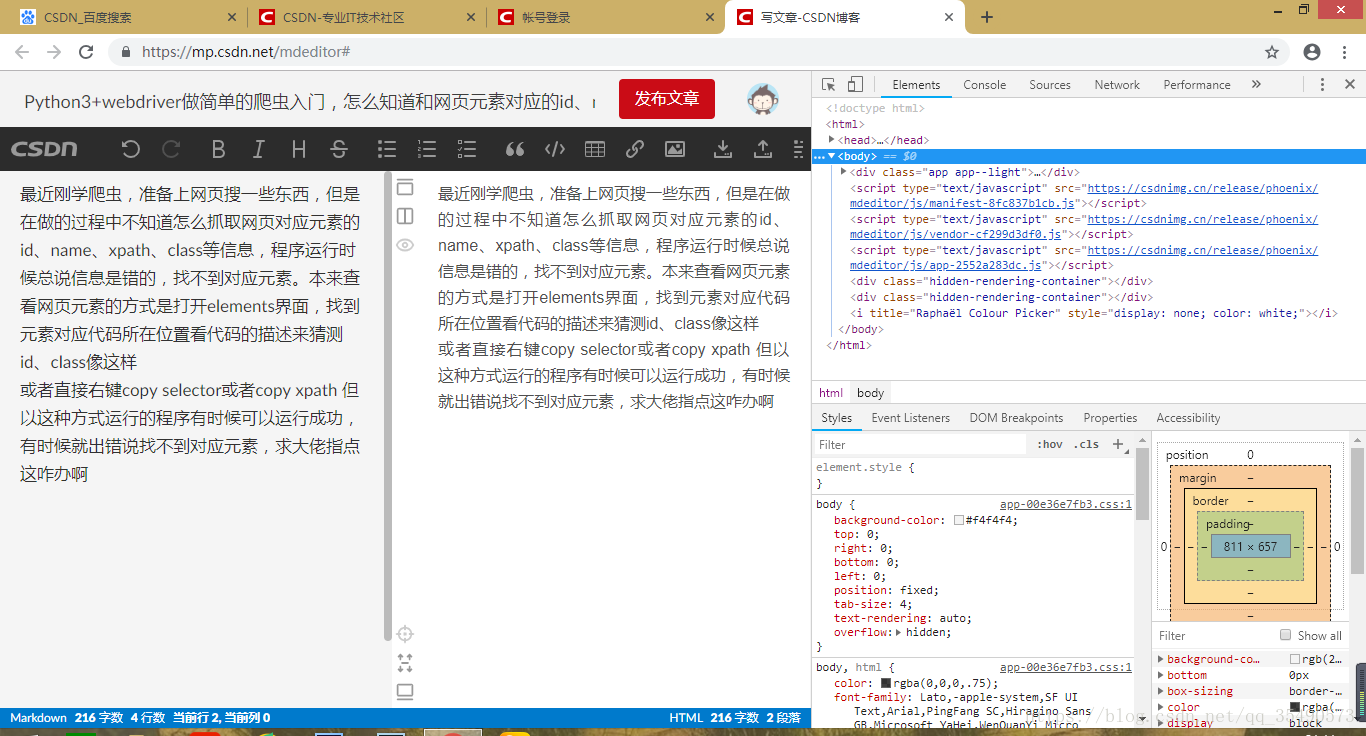
然后像这样就在程序里写了
fide_element_by_class_name(“btn btn-publish”)
不知道这样对么
或者直接右键copy selector或者copy xpath这样
但以这种方式运行的程序有时候可以运行成功,有时候就出错说找不到对应元素,求大佬指点这咋办啊
Python3+webdriver做简单的爬虫入门,怎么知道和网页元素对应的id、name、xpath等信息
最新推荐文章于 2024-10-29 10:17:47 发布
 本文探讨了使用爬虫抓取网页元素时常见的问题,包括如何准确获取元素的id、name、xpath、class等信息,以及在程序运行中遇到的元素定位错误。作者分享了通过浏览器检查元素功能和直接复制选择器或XPath的方法,并寻求更稳定可靠的解决方案。
本文探讨了使用爬虫抓取网页元素时常见的问题,包括如何准确获取元素的id、name、xpath、class等信息,以及在程序运行中遇到的元素定位错误。作者分享了通过浏览器检查元素功能和直接复制选择器或XPath的方法,并寻求更稳定可靠的解决方案。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









