







1、前言
闲来无聊,最近迷恋上玩基金,真的是又菜瘾有大,刚好有朋友是做数据分析相关的,他想用excel分析基金历史数据,于是乎,让我去爬取天天基金上的排行数据。
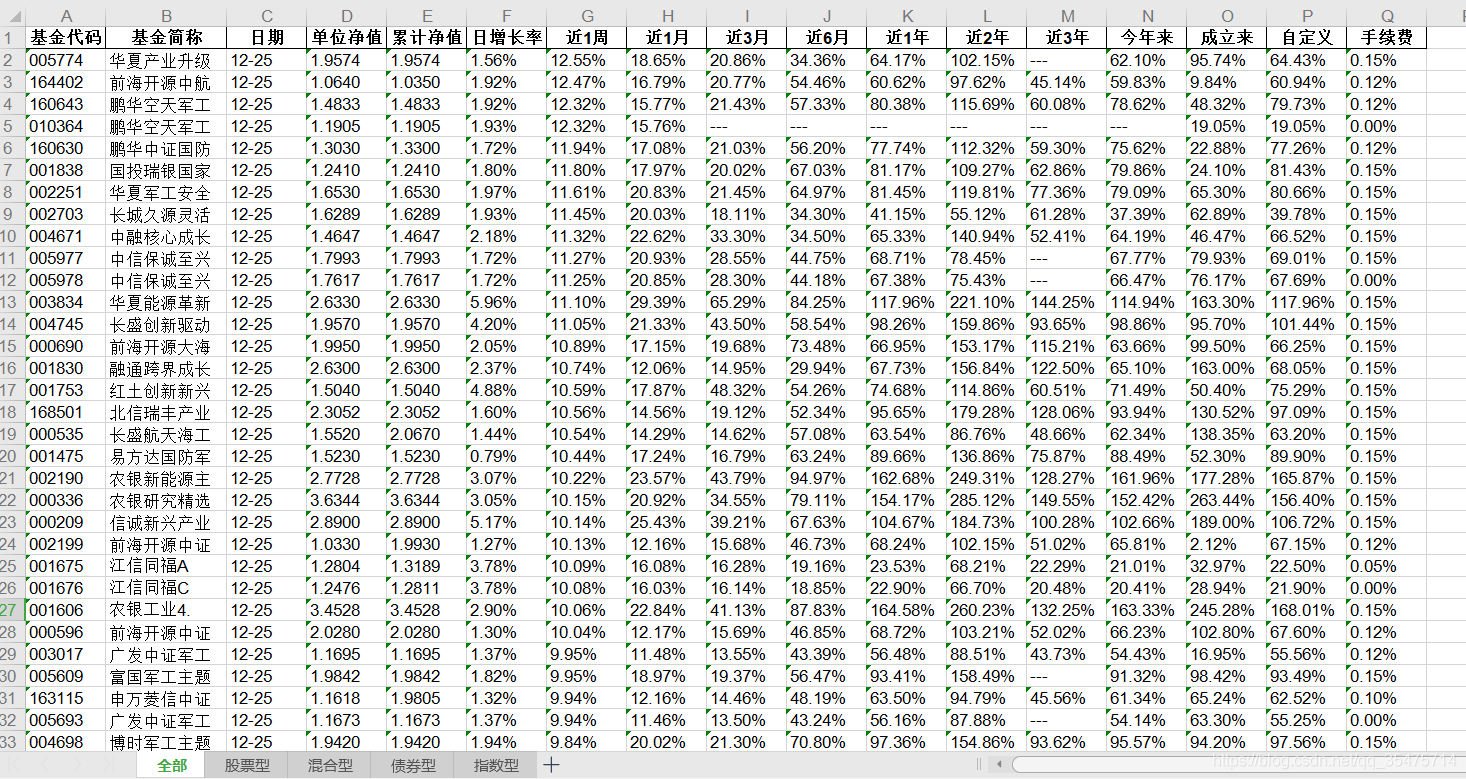
2、xls文件结果展示
爬取了全部、股票型、混合型、债券型、指数型,5种类型排行,excel保存结果如下:
3、源码
话不多说,源码如下:
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import pandas as pd
from bs4 import BeautifulSoup
import time
import datetime
url_dict = {
"全部": "http://fund.eastmoney.com/data/fundranking.html#tall;c0;r;szzf;pn10000;ddesc;qsd20191227;qed20201227;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb",
"股票型": "http://fund.eastmoney.com/data/fundranking.html#tgp;c0;r;szzf;pn10000;ddesc;qsd20191227;qed20201227;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb",
"混合型": "http://fund.eastmoney.com/data/fundranking.html#thh;c0;r;szzf;pn10000;ddesc;qsd20191227;qed20201227;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb",
"债券型": "http://fund.eastmoney.com/data/fundranking.html#tzq;c0;r;szzf;pn10000;ddesc;qsd20191227;qed20201227;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb",
"指数型": "http://fund.eastmoney.com/data/fundranking.html#tzs;c0;r;szzf;pn10000;ddesc;qsd20191227;qed20201227;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb"}
thead = ["基金代码", "基金简称", "日期", "单位净值", "累计净值", "日增长率", "近1周", "近1月",
"近3月", "近6月", "近1年", "近2年", "近3年", "今年来", "成立来", "自定义", "手续费"]
def getData(key, url, xlsWriter):
chrome_options = Options()
chrome_options.add_argument('--headless')
#chrome_options.add_argument('--disable-browser-side-navigation')
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
time.sleep(10)
soup = BeautifulSoup(driver.page_source)
dbtable = soup.findAll(name="table", attrs={"id": "dbtable"})
all_dict = {}
for i in range(len(thead)):
all_dict[thead[i]] = []
trs_item = dbtable[0].tbody.findAll(name="tr")
for tr_item in trs_item:
ids = tr_item.findAll(name="td")
for i in range(len(thead)):
all_dict[thead[i]].append(ids[i + 2].text)
pd.DataFrame(all_dict).to_excel(excel_writer=xlsWriter, sheet_name=key,index=None)
print("%s,nums=%d,%s" % (key, len(all_dict[thead[i]]), url))
driver.close()
if __name__ == "__main__":
today = datetime.datetime.now().strftime('%Y%m%d')
xlsWriter = pd.ExcelWriter("wealth%s.xls"%today) # xls
for key, url in url_dict.items():
getData(key, url, xlsWriter)
xlsWriter.close()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









