







1 梯度下降
梯度下降是一种一阶迭代迭代最小化算法,总体思想是:向损失函数下降最快的地方移动
- 从某点
开始
- 迭代计算:
(
是损失函数
)
- 当最小值达到时结束
我们可以表示为
α在机器学习中被称为学习率,但是梯度下降每一步的长度并非仅仅与α有关,而是与有关。当太小时会导致收敛速度非常慢,太大时会有overshooting的风险,最佳的值可以通过line search找到 。
2 衰减与动量(momentum)
学习率的变化可以是适应性的,也可以是遵循一定计划的。
我们可以通过定义一个衰减参数ρ,使得学习率α减小,比如:等等。我们可以引入物理中动量的概念,积累过去的梯度并且沿着他们的方向移动:
momentum
步长正比于梯度序列的对齐程度
加入动量后的梯度下降法优点:对于大λ会有更快的收敛速度,并且能逃离局部最小值。
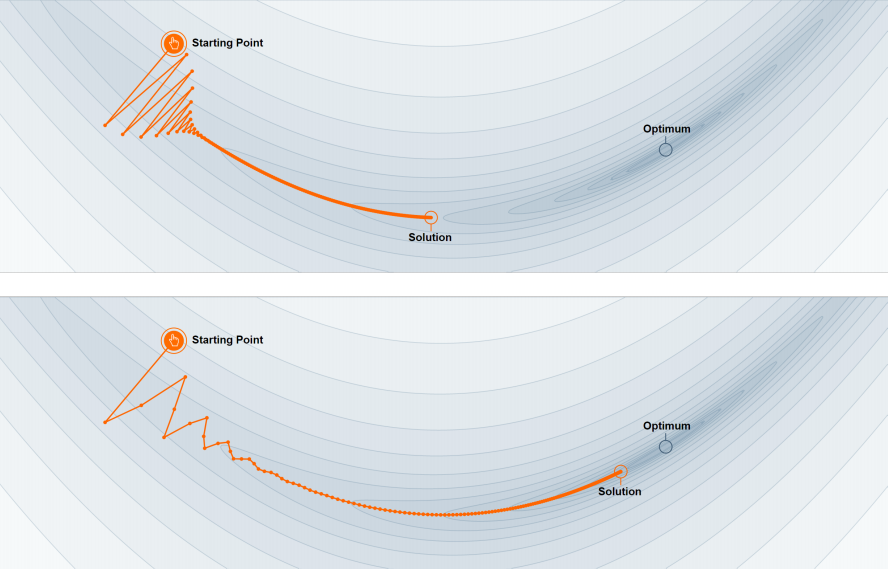
3 实现
梯度下降实现动量部分的代码
def update_theta_M(theta, target, preds, features, lr,v):
'''
Function to compute the gradient of the log likelihood
and then return the updated weights
Input:
theta: the model parameter matrix.
target: the label array
preds: the predictions of the input features
features: it's the input data matrix. The shape is (N, H)
lr: the learning rate
Output:
theta: the updated model parameter matrix.
'''
m = len(target)
preds = predictions(features, theta)
gama=0.9
G = np.dot(np.transpose(features), target - preds)
v=gama*v+lr * G / m
theta = theta + v
return theta,v
def gradient_ascent_M(theta, features, target, lr, num_steps):
'''
Function to execute the gradient ascent algorithm
Input:
theta: the model parameter matrix.
target: the label array
num_steps: the number of iterations
features: the input data matrix. The shape is (N, H)
lr: the learning rate
Output:
theta: the final model parameter matrix.
log_likelihood_history: the values of the log likelihood during the process
'''
log_likelihood_history = np.zeros(num_steps)
preds = predictions(features, theta)
v=0
for i in range(num_steps):
theta,v = update_theta_M(theta, target, preds, features, lr,v)
log_likelihood_history[i] = log_likelihood(theta, features, target)
return theta, log_likelihood_history 具体完整代码见我Kaggle notebook。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









