







 本文详细介绍了Java的GVM内存结构,包括堆、虚拟机栈、本地方法栈、方法区和直接内存等,并讲解了程序计数器的作用。重点讨论了垃圾收集系统,包括对象存活判断的引用计数法和根搜索算法,以及各种垃圾回收策略如标记清除、复制、标记压缩和分代算法。此外,还涵盖了不同JVM参数的含义和垃圾收集器的选择,如Serial、ParNew、Parallel和CMS收集器,强调了停顿时间和吞吐量的权衡。
本文详细介绍了Java的GVM内存结构,包括堆、虚拟机栈、本地方法栈、方法区和直接内存等,并讲解了程序计数器的作用。重点讨论了垃圾收集系统,包括对象存活判断的引用计数法和根搜索算法,以及各种垃圾回收策略如标记清除、复制、标记压缩和分代算法。此外,还涵盖了不同JVM参数的含义和垃圾收集器的选择,如Serial、ParNew、Parallel和CMS收集器,强调了停顿时间和吞吐量的权衡。
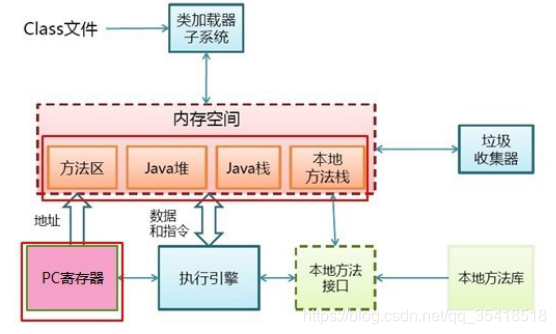
Java堆(所有线程共享的一块内存区域)
1、在虚拟机启动时创建。存放对象实例。
2、GC堆,垃圾收集器管理的主要区域。
3、通过 -Xmx 和 -Xms 控制,无法再扩展时,将会抛出OutOfMemoryError异常。

内部分:新生代(1/3 的堆空间大小)、老年代(2/3 的堆空间大小)
新生代又分:Eden 和 两个 Survivor 区(2个Survivor分别叫from和to区 )
Edem : from : to = 8 : 1 : 1(大小比例)
回收流程:eden --> 回收后存活的 进入from ——> from满以后 ——> 拷贝仍在使用的放入to(新过来的数据也放入to),清空from区(一次年龄增加) ——> 数据年龄到一定上限时,存入老年代
(from 和 to 区是相互的,如果to在存数据时,两个身份交换)
Minor GC:(Eden代满触发)回收年轻代。
Full GC:(老代满或永久代满触发)同时回收年轻代、年老代。
(注:Java8中已经移除了永久代,新加了一个叫做元数据区的native内存区)
Java虚拟机栈(Java方法执行的内存模型)
1、存储局部变量表、操作数栈、动态链接、方法出口等信息。
2、如果线程请求的栈深度大于虚拟机所允许的深度,则抛出StackOverflowError异常。
3、无法申请到足够的内存,就会抛出OutOfMemoryError异常。
本地方法栈(操作类似虚拟机栈)
为虚拟机使用到的native方法服务。
运行时常量池:(方法区的一部分,存放编译期生成的各种字面量和符号引用)
方法区(各个线程共享的内存区域)
已被虚拟机加载的类信息、常量、静态变量
直接内存
程序计数器(当前线程所执行的字节码的行号指示器。)
记录当前线程执行的位置,然后重新获取到cpu时间后,能接着上次任务执行。
执行引擎
负责执行虚拟机的字节码
垃圾收集系统
1、执行是自动的,调用System.gc 方法来"建议"执行垃圾收集器,但不一定会马上执行。回收类时会先调用类的finalize()
public class Test {
public static void main(String[] args) {
Test test = new Test();
test = null;
System.gc(); // 手动回收垃圾
}
@Override
protected void finalize() throws Throwable {
// gc回收垃圾之前调用
System.out.println("垃圾回收机制...");
}
}
判断对象是否存活
引用计数法(一般都没使用这种方法)
1、每当有一个地方引用它时,计数器值加1。
2、任何时刻计数器值为0的对象就是不可能再被使用的。
3、很难解决对象之间相互循环引用的问题。
根搜索算法
1、通过一系列称为“GC Roots”的对象作为起始点,从这些节点向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链(即GC Roots到对象不可达)时,则证明此对象是不可用的。
GC Roots 对象
- 虚拟机栈(栈帧中的局部变量区,也叫做局部变量表)中引用的对象。
- 方法区中的类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI(Native方法)引用的对象。
(就是一个对象,他的引用原始类是GC Roots,则不清除,设置为null则清除了当前引用)
垃圾回收机制策略
标记清除算法
1、找到所有可访问的对象,把未被标记的对象回收。
2、应用在老年代,因为老年代的对象生命周期比较长。
3、优点:可以解决循环引用的问题、必要时才回收(内存不足时)。
4、缺点:回收时,应用需要挂起、标记和清除的效率不高、会造成内存碎片(删除中间数据,留下来的空间小。不能存放大一点的数据)
复制算法
1、把存活的对象复制到另一个区域,然后清除原来区域。
2、使用在新生代中。这些生命周期短。
3、流程:(发生young gc,下面两个都会执行一次)
- 当前from区将存储权限交给to区(from和to身份交换),拷贝老from存活的对象到老to里面(清空老from)。
- Eden区满的时候 ——> 拷贝存货对象到 From 区(清空Eden区)
4、注意: 万一存活对象数量比较多,那么To域的内存可能不够存放,这个时候会借助老年代的空间。
5、优点:存活对象不多的情况下,性能高。能解决内存碎片和循环引用的问题。
6、缺点:如果存活对象的数量比较大,性能差。会造成一部分的内存浪费。
标记压缩算法
1、方式:
任意顺序 : 即不考虑原先对象的排列顺序,也不考虑对象之间的引用关系,随意移动对象;
线性顺序 : 考虑对象的引用关系,例如a对象引用了b对象,则尽可能将a和b移动到一块;
滑动顺序 : 按照对象原来在堆中的顺序滑动到堆的一端。
2、优点:在标记清除算法之上解决内存碎片化问题。
3、缺点:由于移动了可用对象,需要去更新引用。
分代算法
1、新生代使用:复制算法。
2、老年代使用:标记-清除-压缩算法。
JVM参数
- -XX:+PrintGC 每次触发GC的时候打印相关日志
- -XX:+UseSerialGC 串行回收
- -XX:+PrintGCDetails 更详细的GC日志
- -Xms 堆初始值
- -Xmx 堆最大可用值
- -Xmn 新生代堆最大可用值
- -XX:SurvivorRatio 用来设置新生代中eden空间和from/to空间的比例.
- -XX:NewRatio 配置新生代与老年代占比 1:2
- -XX:MaxTenuringThreshold(进入老年代需要的年龄,默认15)
- -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/export/home/tomcat/logs/(当出现OutOfMemoryError 时,把该内存日志打印到指定Path路径内)
总结:在实际工作中,我们可以直接将初始的堆大小与最大堆大小相等,
这样的好处是可以减少程序运行时垃圾回收次数,从而提高效率。
使用示例:-Xms20m -Xmx20m -Xmn1m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC
说明:堆内存初始化值20m,堆内存最大值20m,新生代最大值可用1m,eden空间和from/to空间的比例为2/1
使用示例: -Xms20m -Xmx20m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC
-XX:NewRatio=2
说明:堆内存初始化值20m,堆内存最大值20m,新生代最大值可用1m,eden空间和from/to空间的比例为2/1
新生代和老年代的占比为1/2
垃圾收集器
serial收集器(-XX:+UseSerialGC,小型应用)
1、串行收集器,使用一个线程去回收。
2、新生代、老年代使用串行回收;新生代复制算法、老年代标记-压缩。
3、垃圾收集的过程中会Stop The World(服务暂停)
4、CPU利用率最高,停顿时间即用户等待时间比较长。
ParNew收集器(-XX:+UseParNewGC,-XX:ParallelGCThreads=8)
1、Serial收集器的多线程版本
2、新生代并行,老年代串行;新生代复制算法、老年代标记-压缩
parallel 收集器( XX:+USeParNewGC)
1、类似ParNew收集器,更关注系统的吞吐量。
2、自适应调节策略,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调节参数。
3、控制GC的时间不大于多少毫秒或者比例。
4、采用多线程来通过扫描并压缩堆。
5、特点:停顿时间短,回收效率高,对吞吐量要求高。
6、适用场景:大型应用,科学计算,大规模数据采集等。
cms收集器(-XX:+UseConcMarkSweepGC)
1、以获取最短回收停顿时间为目标的收集器。(希望系统停顿时间最短,以给用户带来较好的体验)
2、流程:
(1)初始标记:(短暂,暂停所有应用程序线程)
(2)并发标记
(3)并发预处理
(4)重新标记:(短暂,暂停所有应用程序线程),标记并发标记阶段遗漏的对象(在并发标记阶段结束后对象状态的更新导致)
(5)并发清除
(6)并发重置
3、优点:响应时间优先,减少垃圾收集停顿时间
4、缺点:产生大量空间碎片、并发阶段会降低吞吐量
g1收集器( -XX:+UseG1GC)
1、堆被划分成 许多个连续的区域(region)。
2、吸收了CMS收集器特点。
3、特点:
- 支持多CPU和垃圾回收线程
- 在主线程暂停的情况下,使用并行收集(并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。 )
- 在主线程运行的情况下,使用并发收集(并发是指一个处理器同时处理多个任务。)
4、优点:支持很大的堆,高吞吐量

















 2151
2151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









