







Regular Expression
Defination : a regular expression is a specific pattern that provides concise and flexible means to “match” strings of text, such as particular characters,words or patterns of chararters.
注意一些符号的组合
- ^出现在[ ]里面时表示Not inside
- 注意substring、whole string 、group
- preceding(在…之前)

Add more constraint(必须以abc开头或结尾)
Only when ABC at the beginning(middle or end) of the string , it can be counted as a match
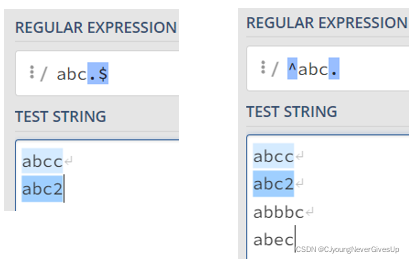
regex_match -> Match the whole string
regex_search -> Search the string to see if there’s a substring that can be matched(关心子串时)
int main()
{
string str;
while (true)
{
cin >> str;
// . -> Any character except newline
// ? -> zero or one preceding character
// * -> zero or more preceding character
// + -> one of more preceding character 至少出现一次
// [...] ->Any charater inside the square brackets(方括号) : ab[cd]* preceding character can be either c or d
// [^...] -> Any charater not inside the square brackets
//parenthesis圆括号 defines a group , what's being matched by this group is called a sub match
regex e1("(abc)de+\\1");// \1 the backslash one means the sub match will appear at this position again
regex e2("(ab)c(de+)\\2\\1");// \2 表示第二个组de+ 在此位置出现一次 \1表示第一个组ab在此位置出现一次
regex e3("abc?", regex_constants::icase);
//Search the E-mail address that end with .com
regex e4("[[:w:]]+@[[:w:]]+\.com"); //old
regex e4_new("\\w+@\\w+\.com"); //new
bool match = regex_match(str, e4_new);
cout << (match ? "Matched" : "Not Matched") << endl << endl;
}
}
Submatch
Agenda
1、Various Regular Expression Grammars
2、Regex Submatch
Regular Express Grammar(Different flavor of regular expression)
- ECMAScript (Default)
- basic
- extended
- awk
- grep
- egrep
Suppose I want to extract somthing,how should i do?
1、Defined a group by using parenthesis
2、smatch object is a temporary class match results of string
smatch m;
m[0].str() The entire match(same with m.str(), m.str(0))
m[1].str() The substring that matches the first group (same with m.str(1))
m[2].str() The substring that matches the second group
m.prefix() Everything before the first matched character
m.suffix() Everything after the last matched chararcter
//extract infos from E-mail address
smatch m;
regex e5("([[:w:]]+)@([[:w:]]+)\.com");
regex e5_new("(\\w+)@(\\w+)\.com");
bool found = regex_search(str, m, e5_new);
//fetch match result
for (int i = 0; i < m.size(); ++i)
{
cout << "m[" << i << "]:str()=" << m[i].str() << endl;
//m[i].str() can be m.str(i) | *(m.begin()+n)
}
cout << "m.prefix().str():" << m.prefix().str() << endl;
cout << "m.suffix().str():" << m.suffix().str() << endl;
Iterators
Agenda
1、Regex Iterator
2、Regex Token Iterator、regex_replace
regex_Iterator
is a iterator pointing to match results
To repeatedly apply the regular expression upon the target string
regex_token_iterator
is a iterator pointing to sub match
each iterator contains only one match result
Extract Infos 提取多个匹配的信息,咋办?
1、用submatch solution ->结果如下

这里我们用 Regex Iterator

测试代码如下:
int main()
{
string str = "zzz cjyoung@gmail.com; cjyoung@hotmail.com animeOtaku@qq.com";
regex e("(\\w+)@(\\w+)\.com");
//1.
sregex_iterator pos(str.cbegin(), str.cend(), e);
sregex_iterator end;//Default constructor defines past-the-end iterator
for (; pos != end; ++pos)
{
cout << "Matched :" << pos->str(0) << endl;
cout << "user name:" << pos->str(1) << endl;
cout << "Domain:" << pos->str(2) << endl;
cout << endl;
}
//2.int _Sub = -1 suffixed
sregex_token_iterator pos2(str.cbegin(), str.cend(), e,-1);
sregex_token_iterator end2;
for (; pos2 != end2; pos2++)
{
cout << "Matched: " << pos2->str() << endl;
cout << endl;
}
getchar();
}
regex_replace
int main()
{
string str = "cjyoung@gmail.com; cjyoung@hotmail.com;; animeOtaku@qq.com";
regex e("(\\w+)@(\\w+)\.com");
//add flag to choose how the replacement happen
cout << regex_replace(str, e, "$1 is on $2");//$1 means first submatch
// all the things that are not matched by the regular expression will not be copied to the new string
cout << regex_replace(str, e, "$1 is on $2",regex_constants::format_no_copy);
cout << regex_replace(str, e, "$1 is on $2", regex_constants::format_no_copy| regex_constants::format_first_only);
getchar();
}
- 去除左侧无效字符(空格,回车,TAB)
std::string testString = " /r/n Hello World ! GoodBye World/r/n";
std::string TrimLeft = "([//s//r//n//t]*)(//w*.*)";
boost::regex expression(TrimLeft);
testString = boost::regex_replace( testString, expression, "$2" );
std::cout<< "TrimLeft:" << testString <<std::endl;
//打印输出:
TrimLeft:Hello World ! GoodBye World
//CString 正则相关
std::wstring wsRegExp(L"第?(\d){1,3}层?(至|到)第?(\d){1,3}层[\u4e00-\u9fa5]{1,5}图");
std::wstring wsText(sName);
std::tr1::regex_constants::syntax_option_type fl = std::tr1::regex_constants::icase;// 表达式选项 - 忽略大小写
std::tr1::wregex wReg(wsRegExp, fl);
std::tr1::wsmatch match;
bool found = std::tr1::regex_search(wsText, match, wReg);
for (int i = 0; i < match.size(); ++i)
{
CString strNo = match[i].str().c_str();
}
eg: extract all substrings using regex_search() -
[link]https://stackoverflow.com/questions/32553593/c-regex-extract-all-substrings-using-regex-search
std::regex_search returns after only the first match found.
std::smatch What std::smatch gives you is all the matched groups in the regular expression.
If you want to find all matches you need to use std::sregex_iterator.
int main()
{
std::string s1("{1,2,3}");
std::regex e(R"(\d+)");
std::cout << s1 << std::endl;
std::sregex_iterator iter(s1.begin(), s1.end(), e);
std::sregex_iterator end;
while(iter != end)
{
std::cout << "size: " << iter->size() << std::endl;
for(unsigned i = 0; i < iter->size(); ++i)
{
std::cout << "the " << i + 1 << "th match" << ": " << (*iter)[i] << std::endl;
}
++iter;
}
}
OutPut
{1,2,3}
size: 1
the 1th match: 1
size: 1
the 1th match: 2
size: 1
the 1th match: 3
The end iterator is default constructed by design so that it is equal to iter when iter has run out of matches. Notice at the bottom of the loop I do ++iter. That moves iter on to the next match. When there are no more matches, iter has the same value as the default constructed end.
Another example to show the submatching (capture groups):
int main()
{
std::string s1("{1,2,3}{4,5,6}{7,8,9}");
std::regex e(R"((\d+),(\d+),(\d+))");//Raw String
std::cout << s1 << std::endl;
std::sregex_iterator iter(s1.begin(), s1.end(), e);
std::sregex_iterator end;
while(iter != end)
{
std::cout << "size: " << iter->size() << std::endl;
std::cout << "expression match #" << 0 << ": " << (*iter)[0] << std::endl;
for(unsigned i = 1; i < iter->size(); ++i)
{
std::cout << "capture submatch #" << i << ": " << (*iter)[i] << std::endl;
}
++iter;
}
}
OutPut
{1,2,3}{4,5,6}{7,8,9}
size: 4
expression match #0: 1,2,3
capture submatch #1: 1
capture submatch #2: 2
capture submatch #3: 3
size: 4
expression match #0: 4,5,6
capture submatch #1: 4
capture submatch #2: 5
capture submatch #3: 6
size: 4
expression match #0: 7,8,9
capture submatch #1: 7
capture submatch #2: 8
capture submatch #3: 9
扩展
string res = "5.教育作用: 通过法的实施使法律对一般人的行为产生影响, 这种作用具体";
Regex regex = new Regex("[一二三四五六七八九].*");
bool b = regex.IsMatch(res);
C#代码中b的值为什么为true
在C#中,正则表达式的匹配规则是找到字符串中任意位置满足模式的部分,而非只从字符串开始处进行匹配。
你的正则表达式 “[一二三四五六七八九].*” 是用来匹配以汉字数字"一"到"九"开头并后续跟随任意字符的字符串。在你提供的 res 字符串中,确实存在满足这个模式的部分。例如:“教育作用: 通过法…” 这个子串就是以汉字 “教” 开头,并后续跟随其他字符。
因此,当你使用 regex.IsMatch(res) 进行检查时,它会返回 true ,表示在 res 中找到了与给定正则表达式相匹配的子串。
如果你想要检查整个字符串是否完全符合某个模式(即从头到尾都符合),那么可以在正则表达式前后添加插入符号 (^) 和美元符号 ( ) 来表示开始和结束。例如: " [ 一二三四五六七八九 ] . ∗ ) 来表示开始和结束。例如: "^[一二三四五六七八九].* )来表示开始和结束。例如:"[一二三四五六七八九].∗" 就表示一个完全由以汉字数字 “一” 到 “九” 开头并后续跟随任意字符组成的字符串。
std::regex re("[一二三四五六七八九].*");
std::cmatch m;
bool b = std::regex_match("5.教育作用: 通过法的实施使法律对一般人的行为产生影响, 这种作用具体", m, re);
为什么在C++代码中b的值为false?
在C++中,std::regex_match函数会检查整个字符串是否匹配给定的正则表达式,而不是像C#中的Regex.IsMatch()方法那样只要字符串中存在满足模式的子串就返回true。这就解释了为什么在C++代码中b的值为false。
你提供的正则表达式 “[一二三四五六七八九].*” 是用来匹配以汉字数字"一"到"九"开头并后续跟随任意字符的字符串。但你提供的字符串 “5.教育作用: 通过法…” 并不是以这些汉字开头,因此 std::regex_match() 返回false。
如果你想要检查字符串中是否存在满足模式的子串,应该使用 std::regex_search() 函数而非 std::regex_match()。以下是一个示例:
#include <iostream>
#include <string>
#include <regex>
int main() {
std::string s = "5.教育作用: 通过法...";
std::regex e ("[一二三四五六七八九].*");
bool match = std::regex_search(s.begin(), s.end(), e);
std::cout << (match ? "Matched" : "Not matched") << std::endl;
return 0;
}

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









