







import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets.california_housing import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR)
housing.data.shape
housing.data[:5][:]
from sklearn import tree
dtr = tree.DecisionTreeRegressor(max_depth = 2)
dtr.fit(housing.data[:, [6, 7]], housing.target)
#要可视化显示 首先需要安装 graphviz http://www.graphviz.org/Download..php
import os
os.environ["PATH"] += os.pathsep + 'C:/soft/graphviz/graphviz-2.38/release/bin' #注意修改你的路径dot_data = \
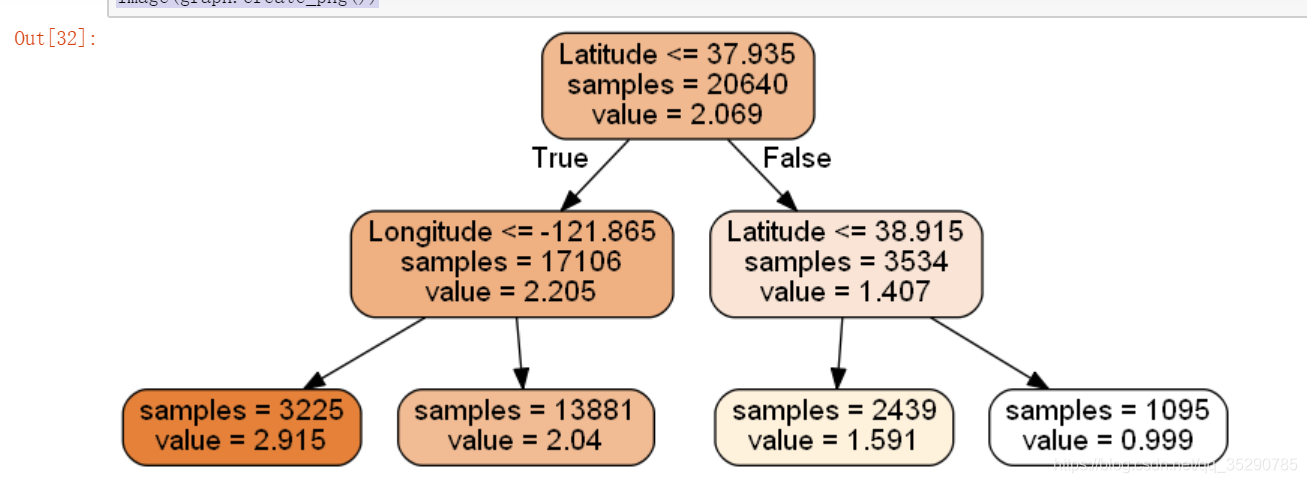
tree.export_graphviz(
dtr,
out_file = None,
feature_names = housing.feature_names[6:8],
filled = True,
impurity = False,
rounded = True
)
#pip install pydotplus
import pydotplus
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor("#FFF2DD")
from IPython.display import Image
Image(graph.create_png())
graph.write_png("dtr_white_background.png")
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = \
train_test_split(housing.data, housing.target, test_size = 0.1, random_state = 42)
dtr = tree.DecisionTreeRegressor(random_state = 42)
dtr.fit(data_train, target_train)dtr.score(data_test, target_test)
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor( random_state = 42)
rfr.fit(data_train, target_train)
rfr.score(data_test, target_test)
#from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import GridSearchCV
tree_param_grid = { 'min_samples_split': list((3,6,9)),'n_estimators':list((10,50,100))}
grid = GridSearchCV(RandomForestRegressor(),param_grid=tree_param_grid, cv=5)
grid.fit(data_train, target_train)
grid.grid_scores_, grid.best_params_, grid.best_score_
rfr = RandomForestRegressor( min_samples_split=3,n_estimators = 100,random_state = 42)
rfr.fit(data_train, target_train)
rfr.score(data_test, target_test)


















 8561
8561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











