






【2023.3.8】数据结构复习笔记
序言
看b站王道数据结构视频,对自己遗漏的知识点进行回顾,并记录笔记。
一、绪论
-
数据结构中
- 最小单位:数据项
- 基本单位:数据元素
-
算法5个重要特性:
- 有穷性
- 确定性
- 可行性
- 输入(0个及以上)
- 输出(1个及以上)。
-
数据结构从逻辑上划分为三种基本类型
- 线性结构
- 树形结构
- 图形结构
-
数据结构包括:
- 数据的逻辑结构
- 数据的存储结构
- 数据的操作运算。
二、线性表
线性结构中元素之间存在一对一关系;
树型结构中元素之间存在一对多关系;
图型结构中元素之间存在多对多关系。
三、栈、队列和数组
考点:已知入栈顺序的n个元素,其出栈顺序有多少种: 1 n + 1 ∗ C ( n 2 n ) \frac{1}{n+1}*C{n \choose 2n} n+11∗C(2nn)
例题:字符A、B、C、D一次进入堆栈,其出栈顺序的序列有多少种:14
1、栈在表达式求值中的运用
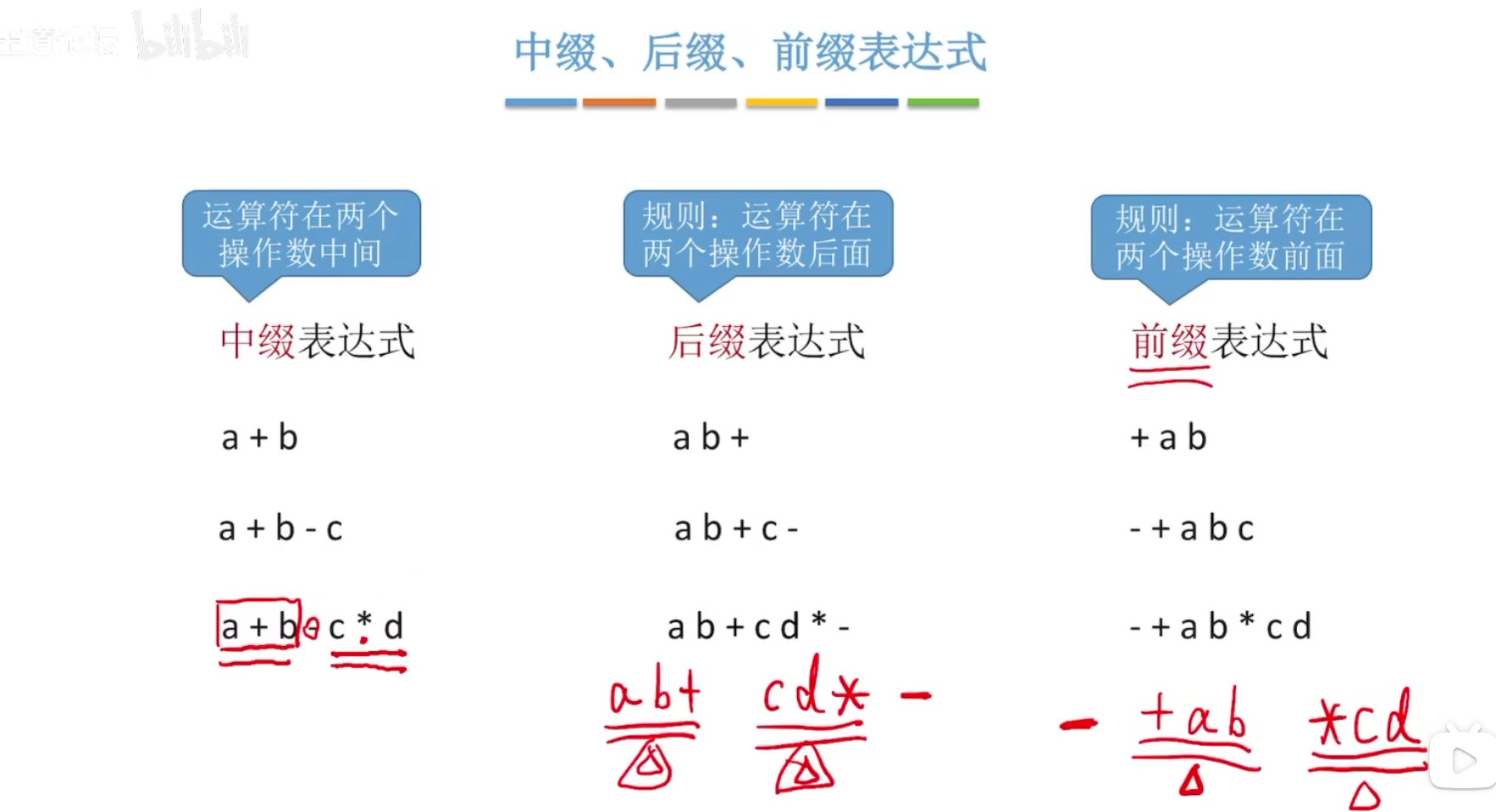
中缀表达式:即正常写法
后缀表达式:即运算符在后面,从最里面的运算开始写:
【左操作数 右操作数 运算符】
前缀表达式:即运算符在前面
(1)中缀转后缀:左优先原则
后缀表达式中运算符生效的次序,与中缀表达式相同,例如:
手算

中转后时,先找到中缀表达式中运算符运算次序。遵守左优先原则
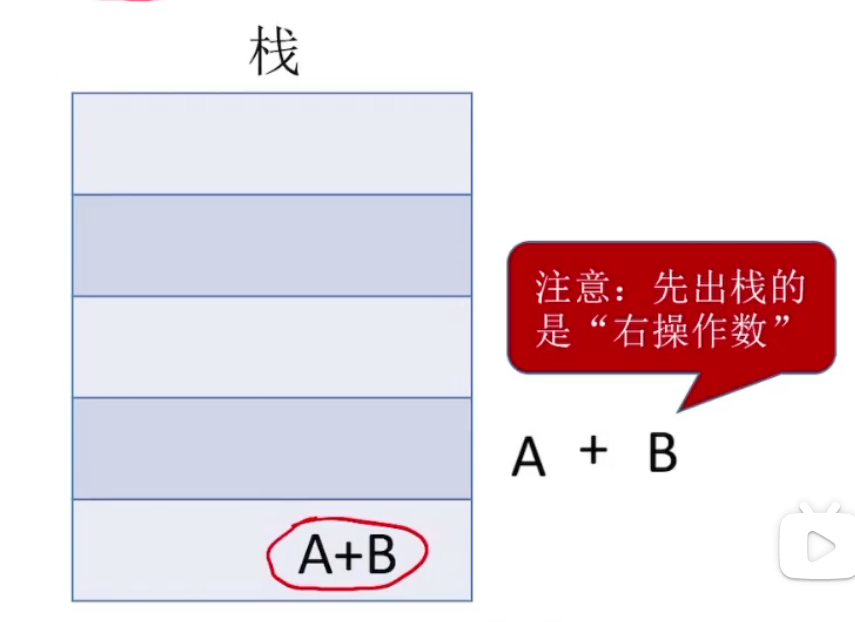
机算
将后缀表达式,操作数从左往右以此压入堆栈,
遇到运算符,则弹出两个栈顶元素,将运算结果压入堆栈

注意:先出栈的是右操作数,如图中的B。
(2)中缀转前缀:右优先原则
右优先原则,即从右往左书写,依次转换为前缀。
手算

机算
将前缀表达式,从右往左一次压入堆栈,先出栈是左操作数,这两点与后缀都相反。

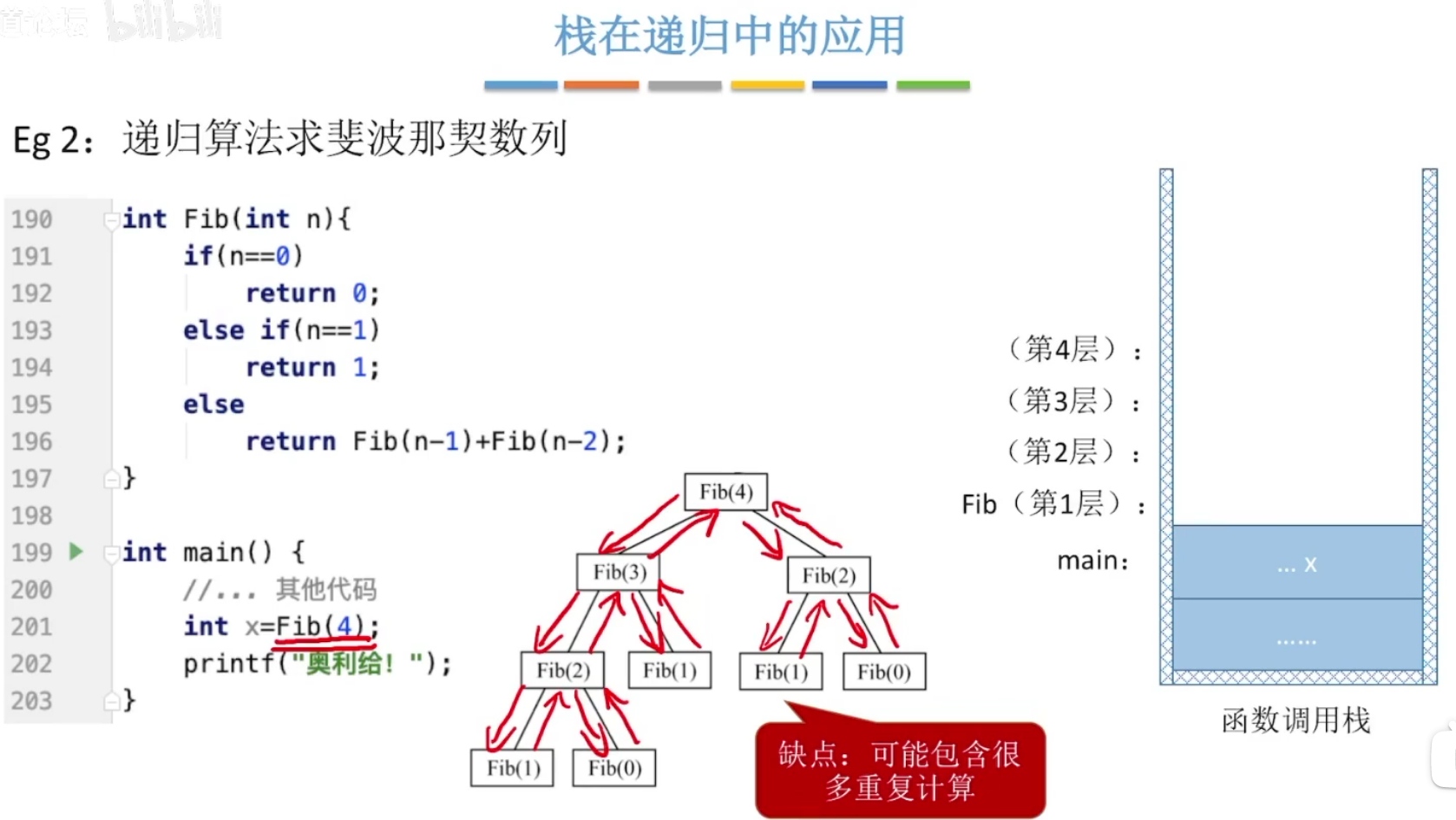
2、栈在递归中的应用
递归求斐波那契数,注意看二叉树表示递归过程。
3、数组和特殊矩阵
行优先、列优先
(1)对称矩阵
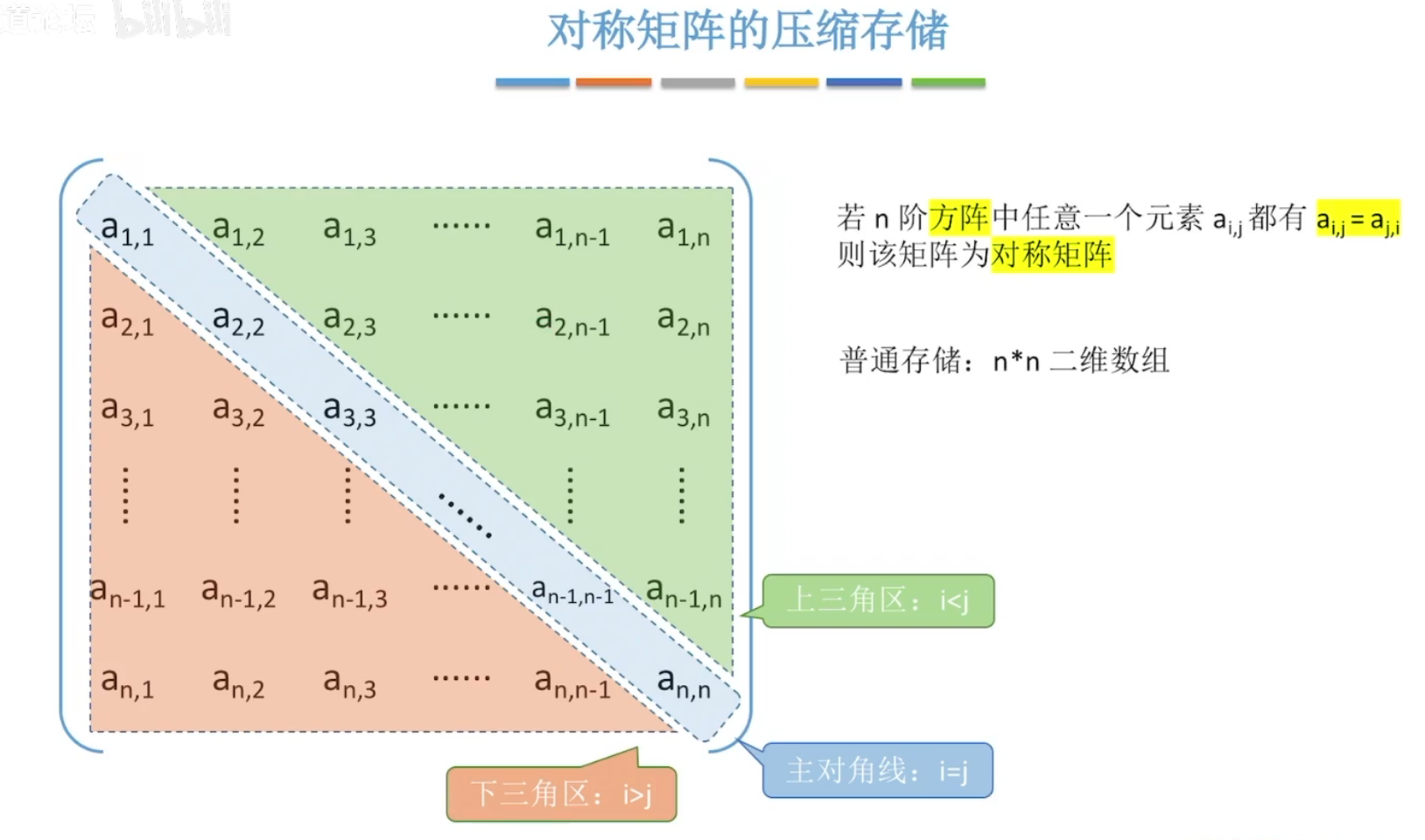
上三角or下三角区域
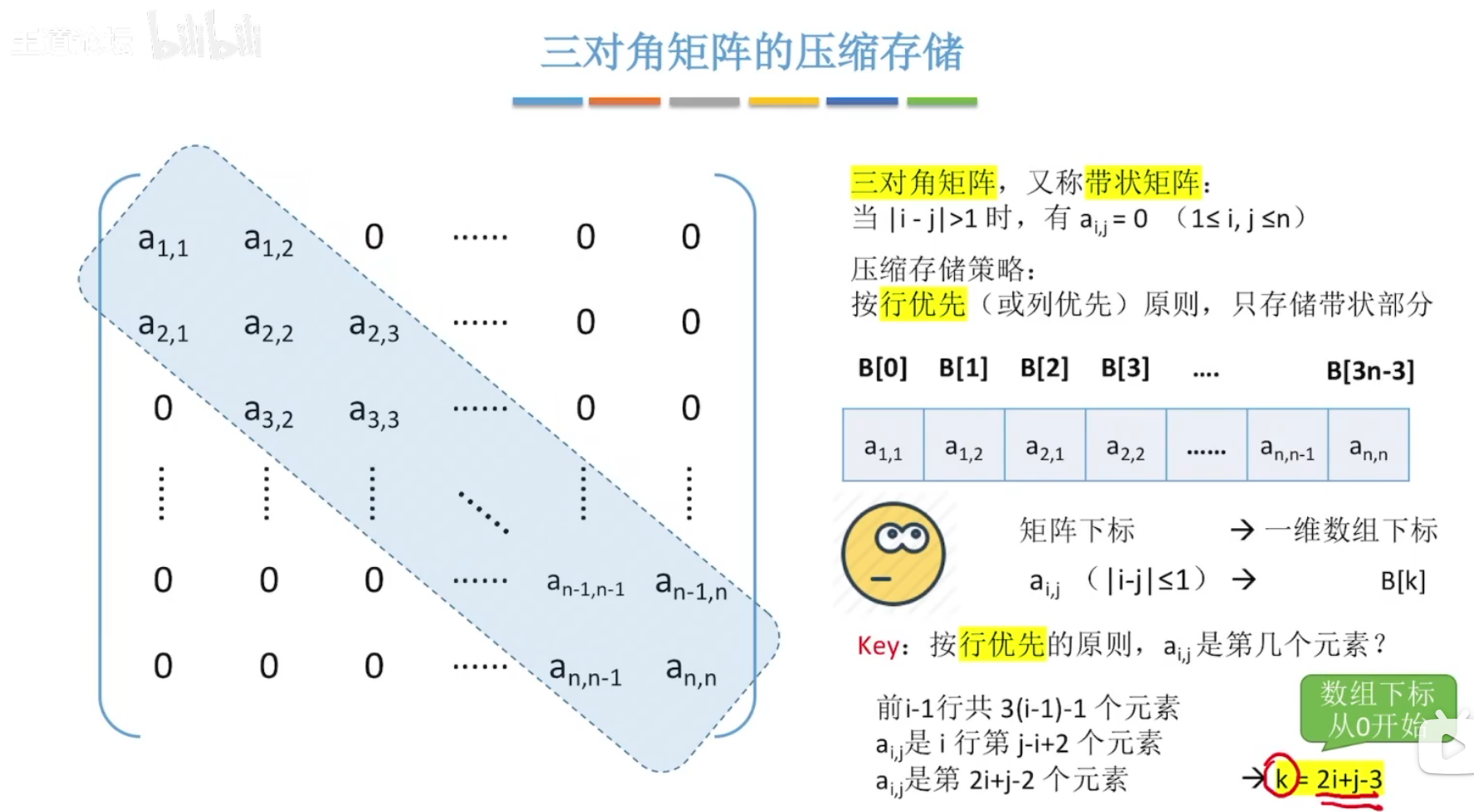
(2)三角矩阵
带状区域
当|i-j|>1时,有ai,j=0;
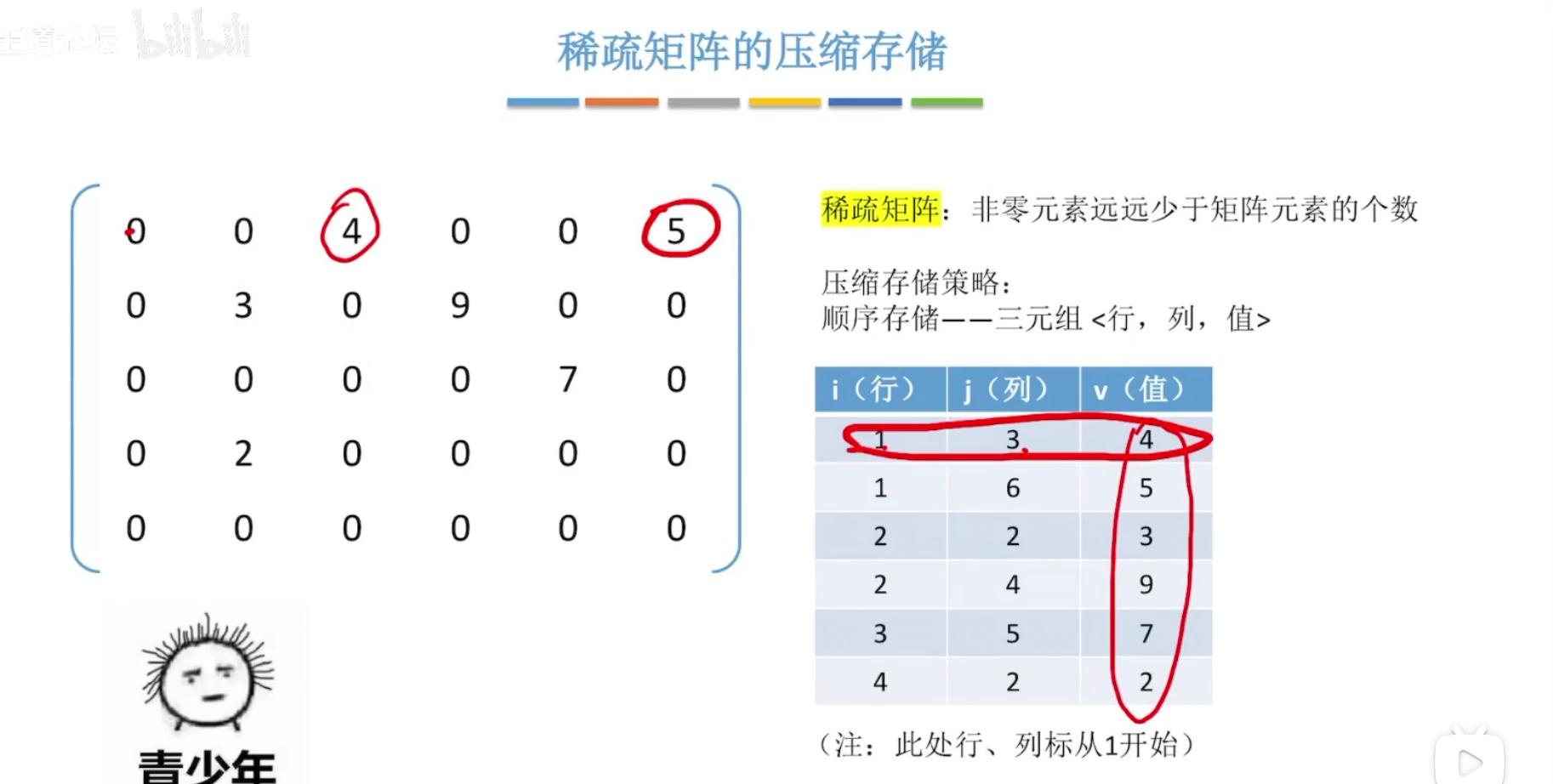
(3)稀疏矩阵
三元组表示法
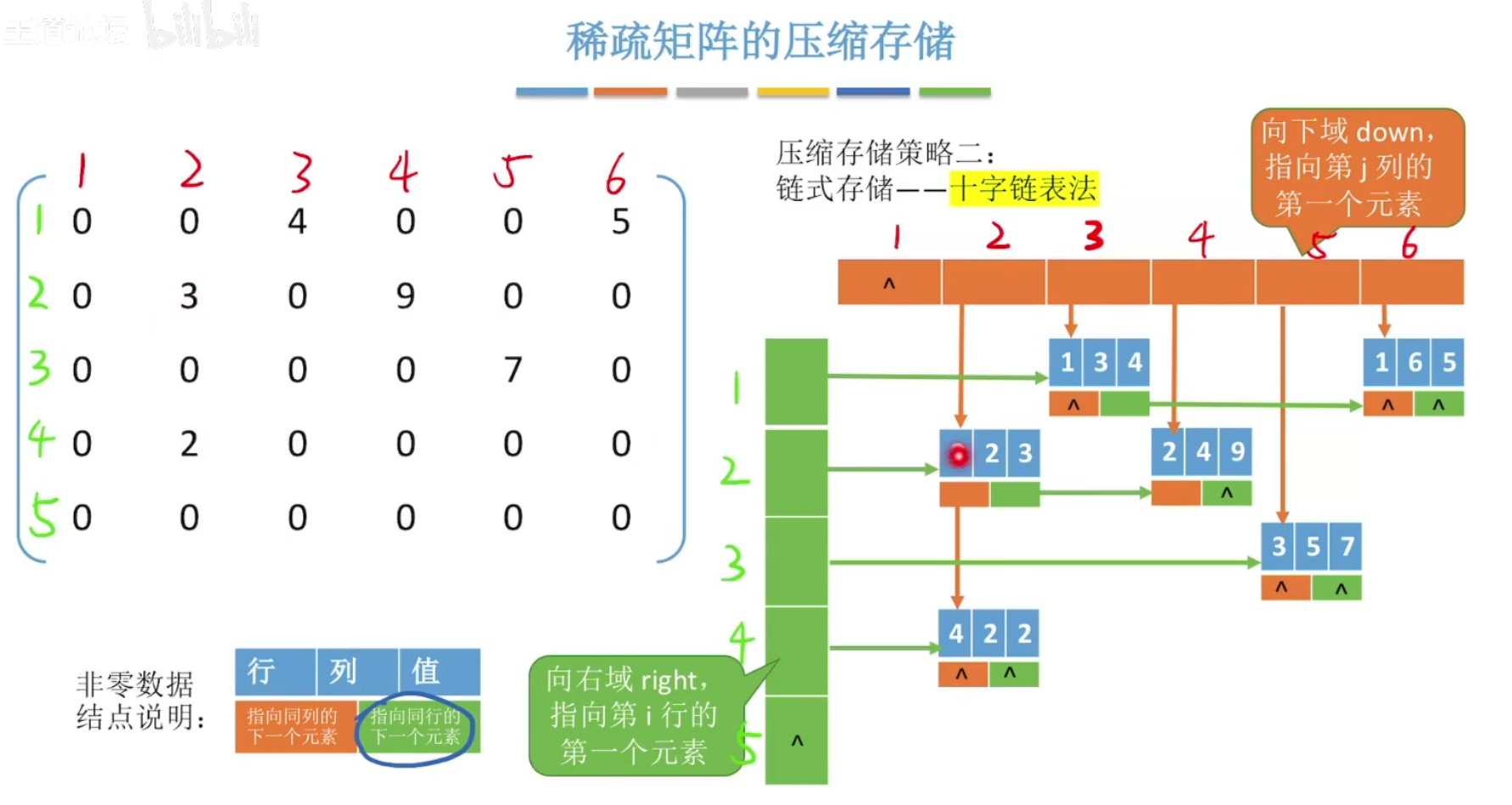
十字链表法
四、串
1、KMP算法
常考点,求模式串的next数组
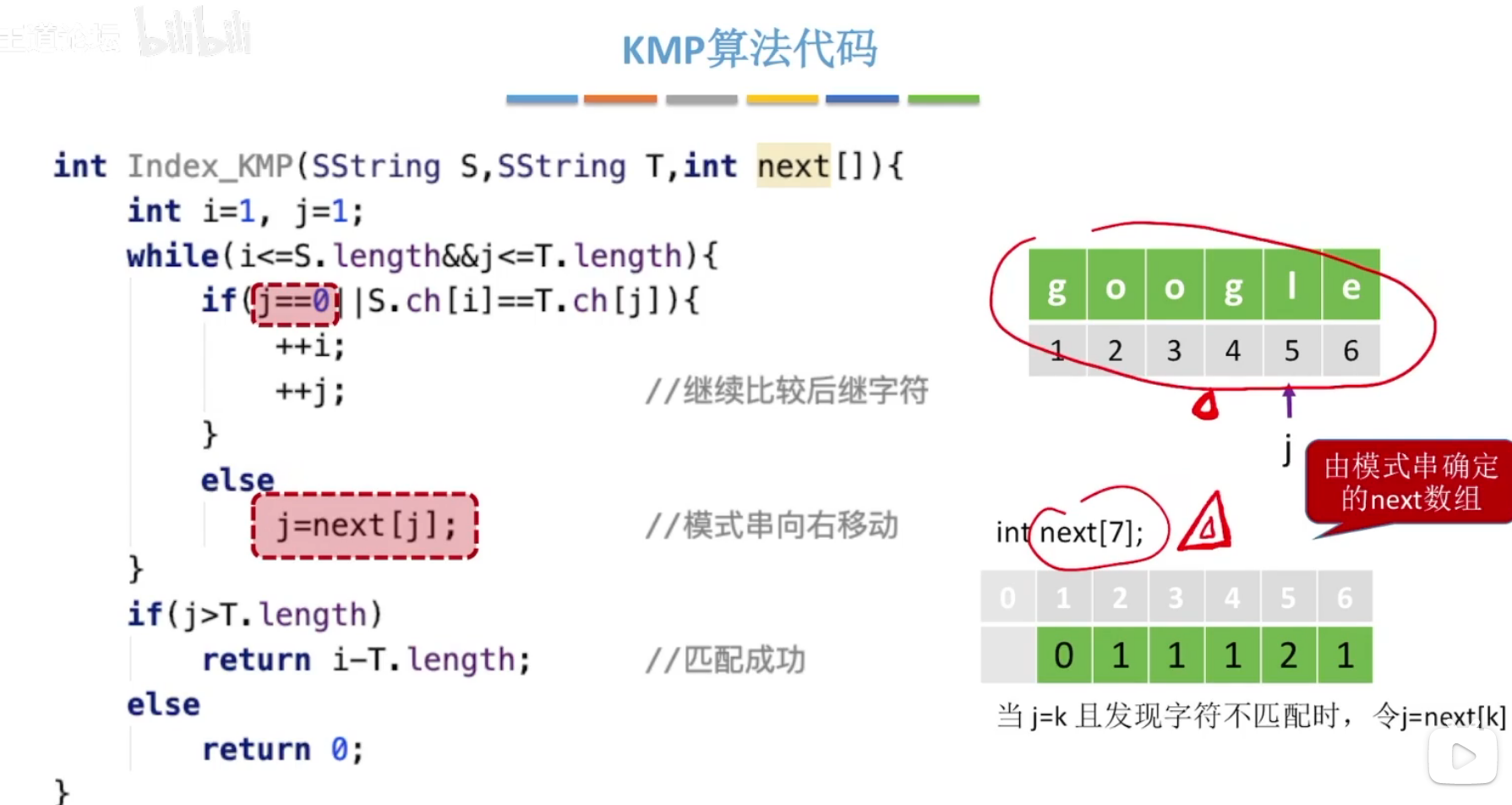
求next数组

next[j] = s的最长相等 前后缀长度 +1
特别的,next[1]=0 ,next[2]=1,因为当j=next[1]=0时,会同时j++,i++。
KMP算法优化,对next数组的优化。
增加nextval数组,即模式串中,所有与第一个字符相同的字符(下标为j),其nextval[j]=0,即等于nextval[1]=0。而其余nextval的值与next数组相同。

五、树与二叉树
1、树
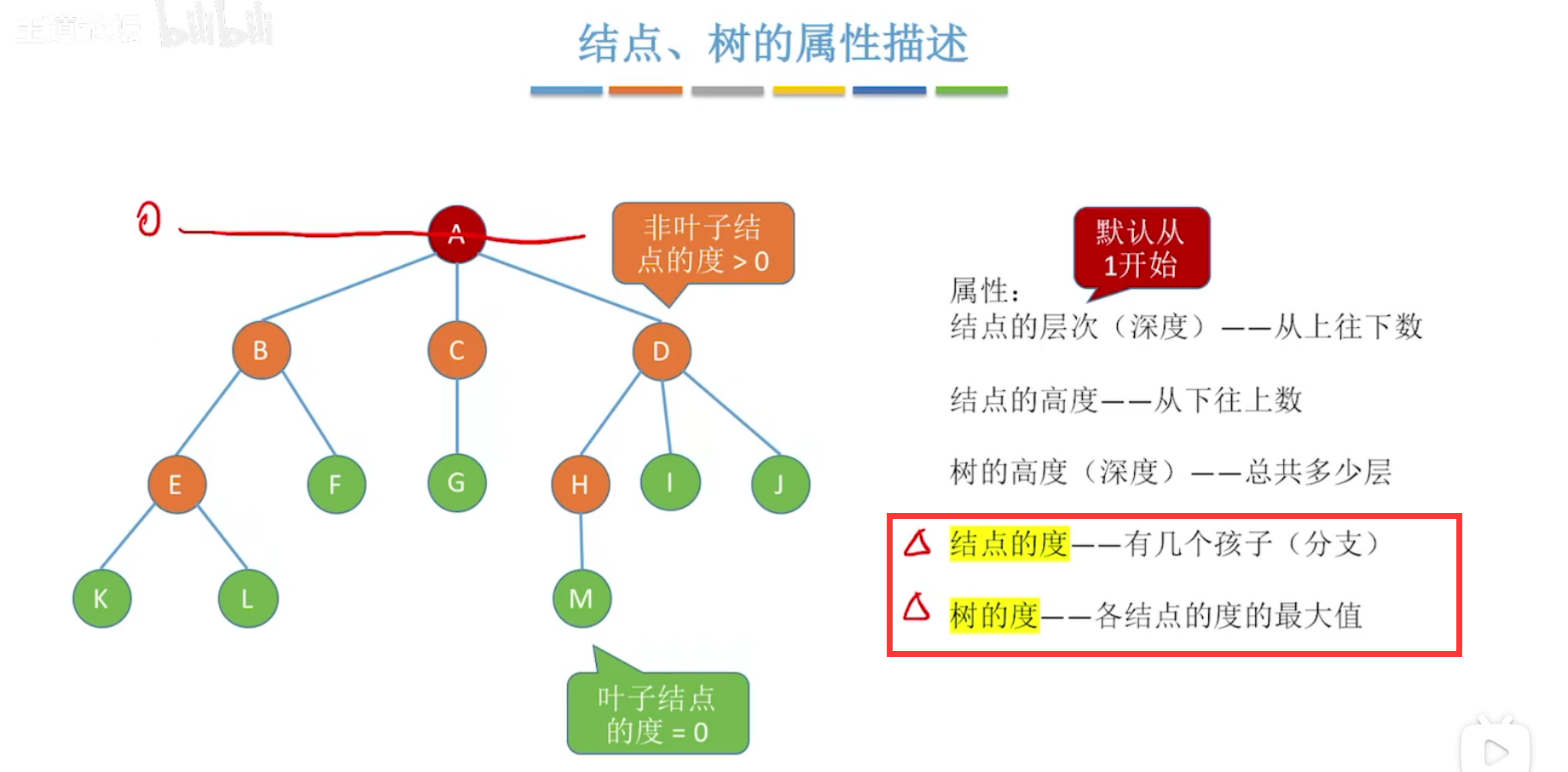
定义和基本术语:
结点的度、树的度
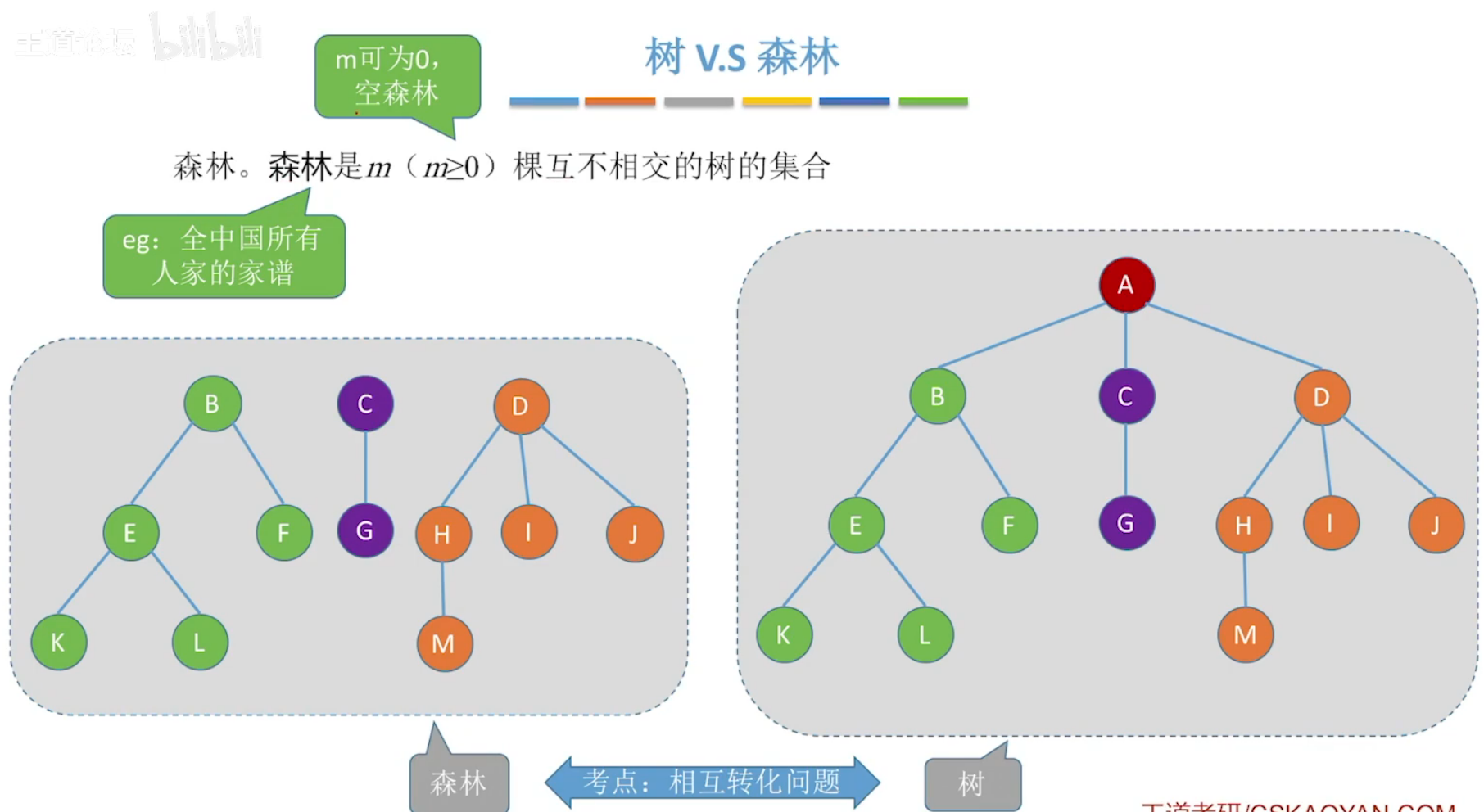
森林,多棵树挨在一起。
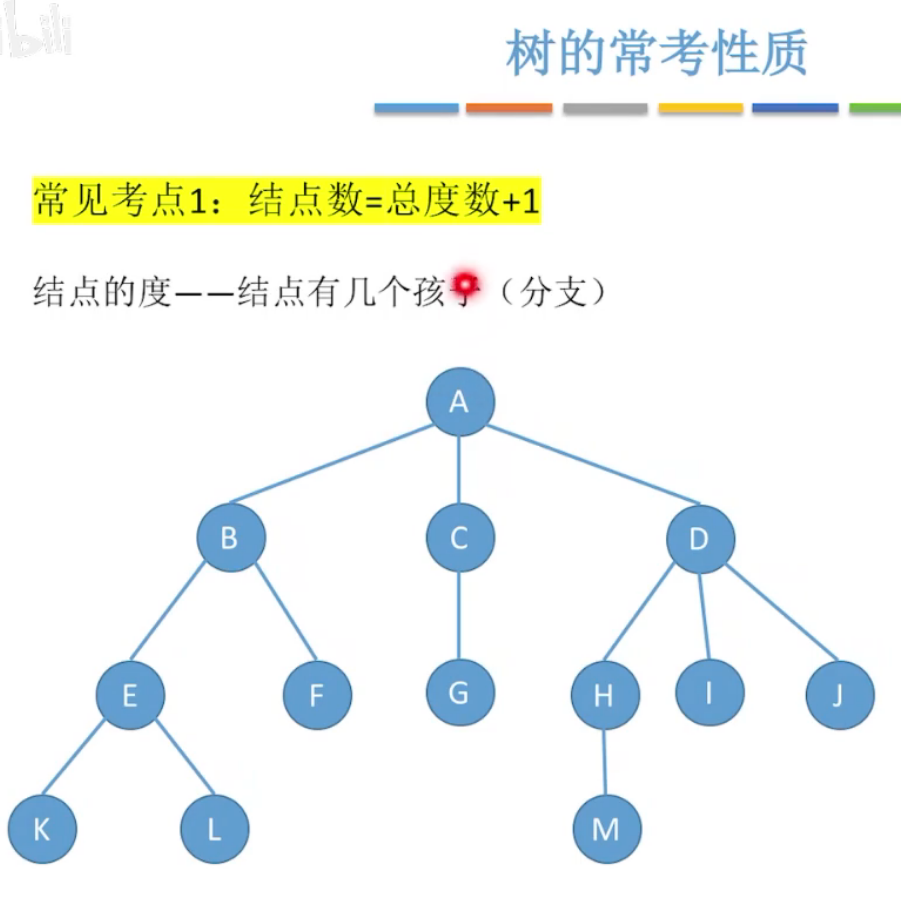
树的性质
结点数 = 总度数+1
m叉树:第i层,至多有m^(i-1)个节点
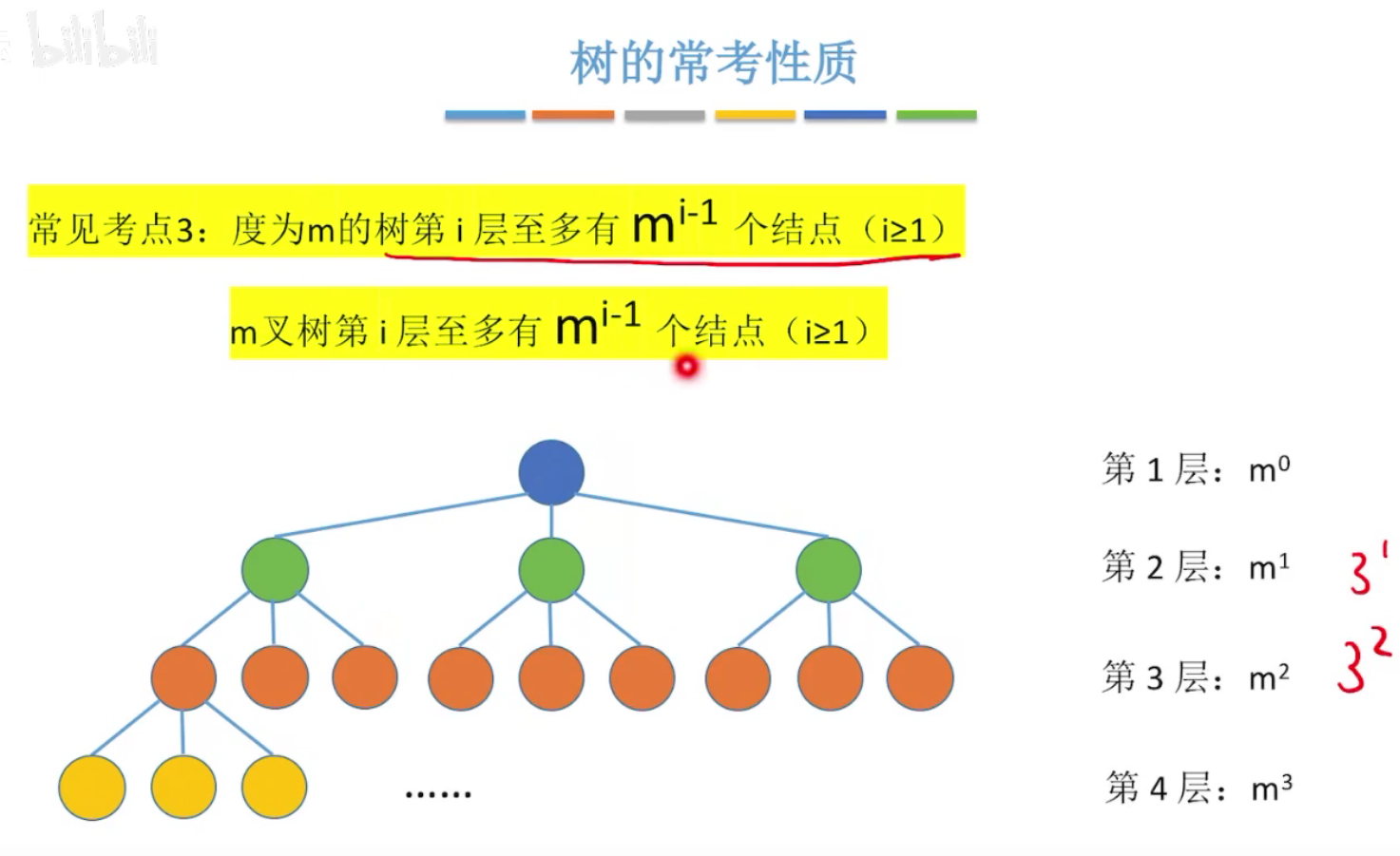
2、二叉树
(1)满二叉树、完全二叉树
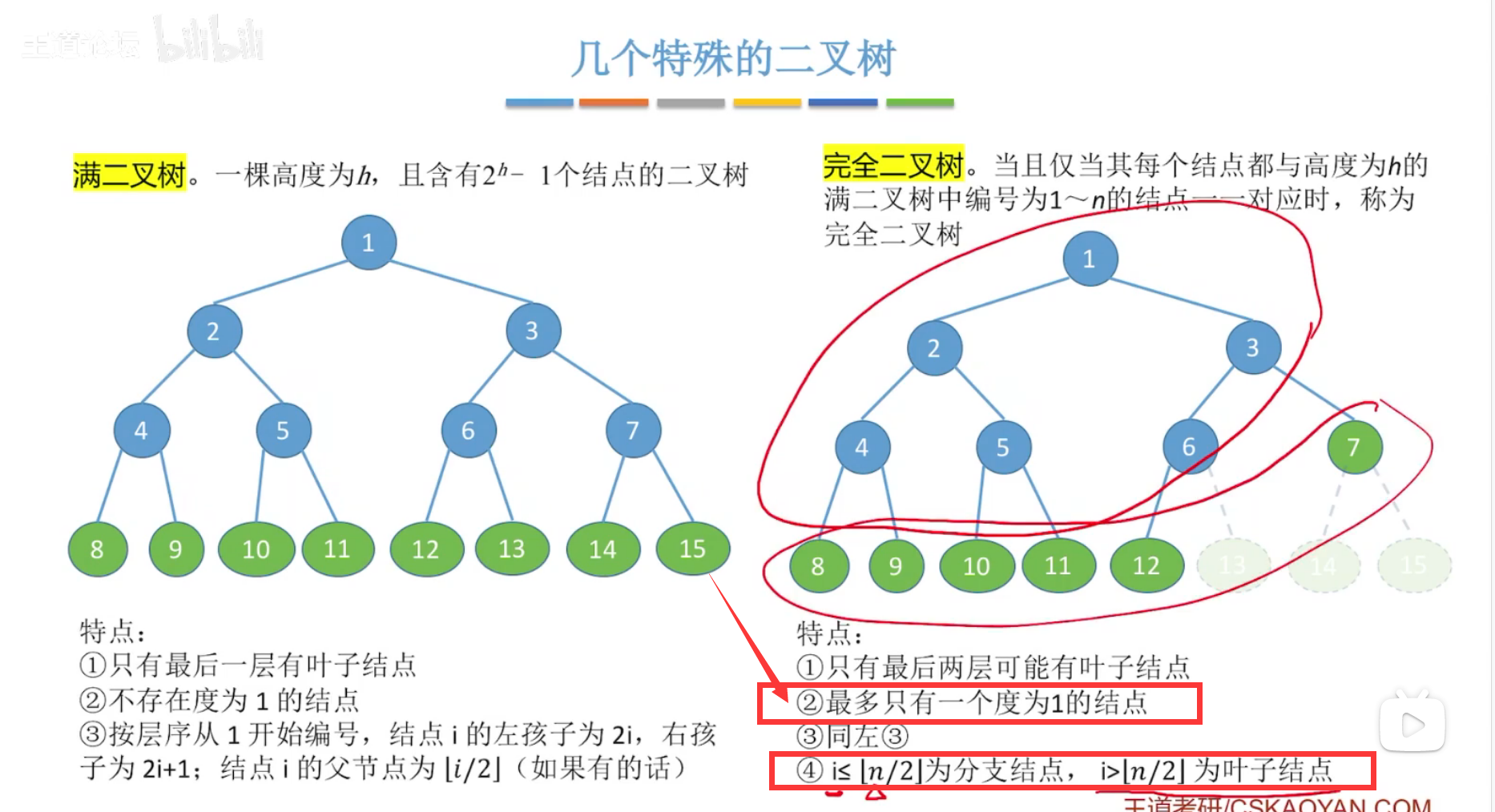
完全二叉树,
编号一一对应于满二叉树,只能依次删去编号大的结点。
最多只有一个度为1的结点,且为左孩子结点。
(2)二叉排序树、平衡二叉树
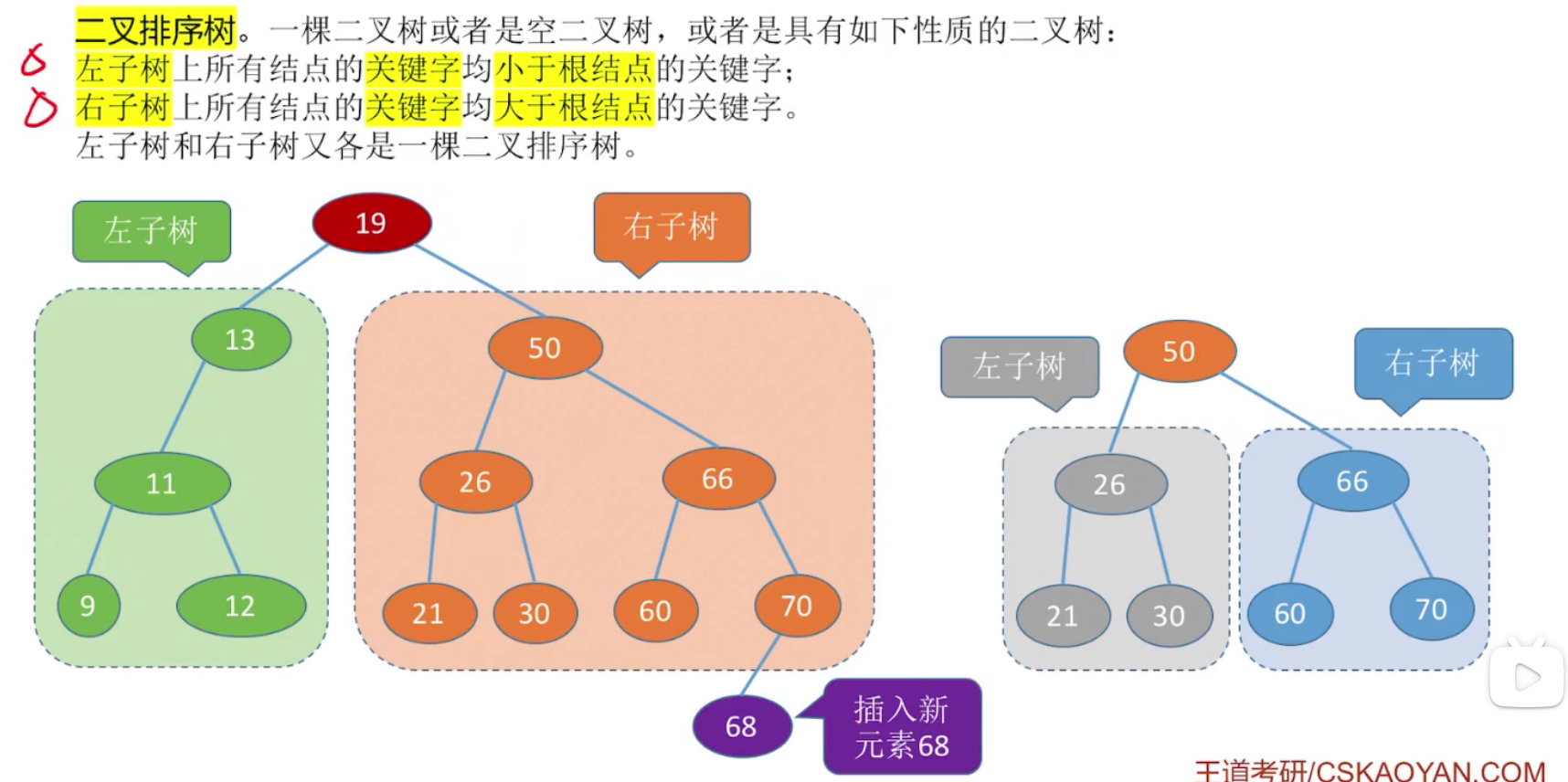
左子树结点小于根结点,
右子树结点大于根节点。
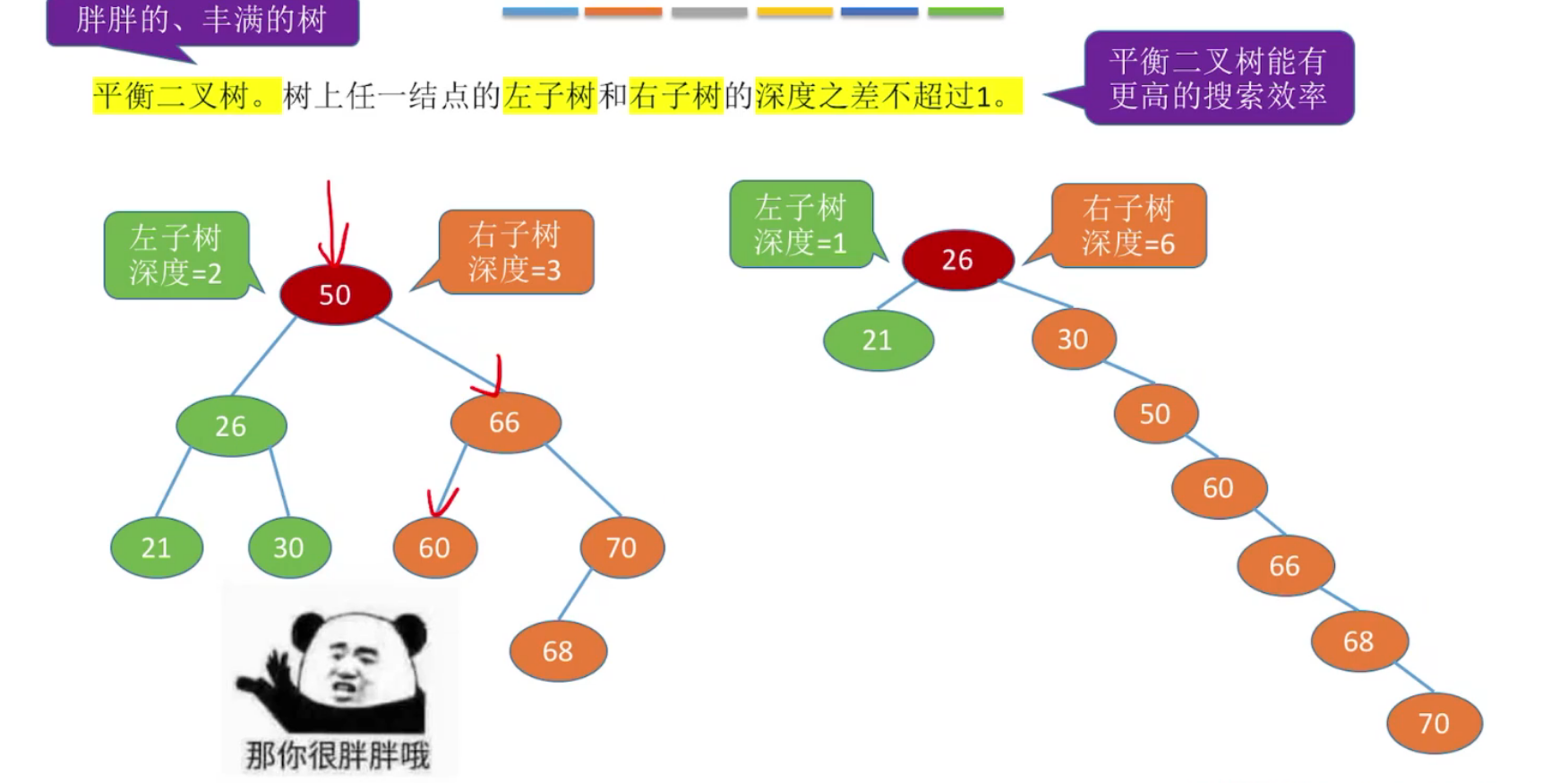
将二叉排序树优化为平衡二叉树,利于查找效率。
(3)二叉树的存储
顺序存储:开辟静态数组,只适合满二叉树,非满二叉树则按照满二叉树存储。
链式存储:链表,两个结点指针,利于存储和查找子节点,不利于查找父节点,需要从根节点开始遍历。
(4)二叉树的遍历
先中后序遍历
先序遍历:根左右
中序遍历:左根右
后序遍历:左右根

递归的访问。分支节点展开法。
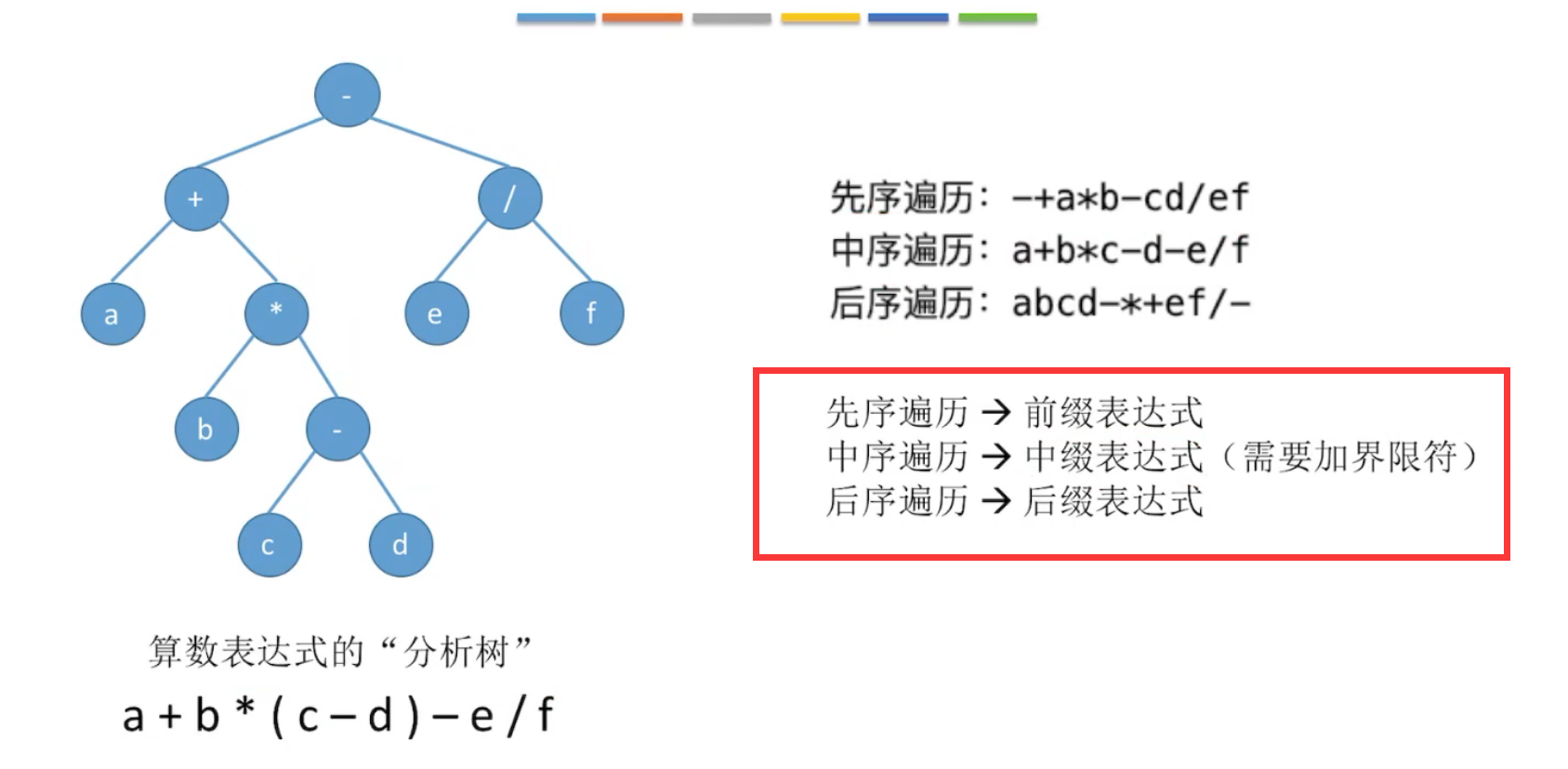
先序遍历代码,

中序遍历代码
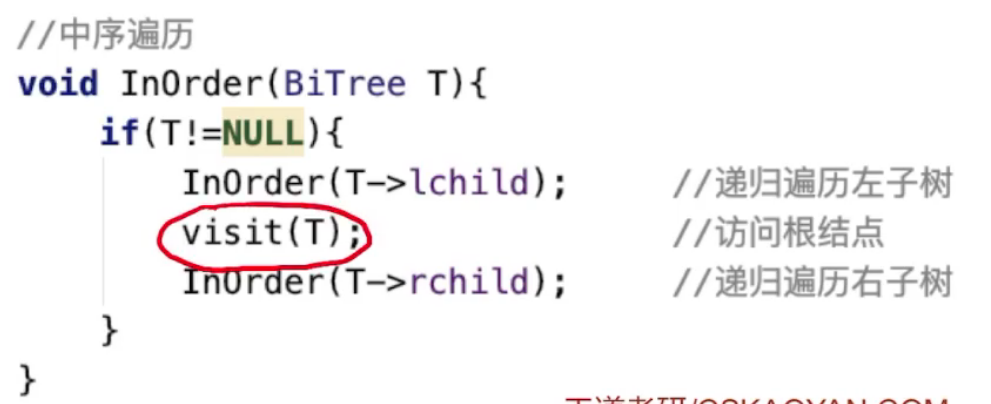
后序遍历代码

二叉树的层次遍历:利用队列实现

头结点p 出队列,访问p节点,再将p结点的左右孩子入队。
(5)由二叉树遍历序列 推出二叉树
两个序列才可确定一个二叉树,且都得包含中序。
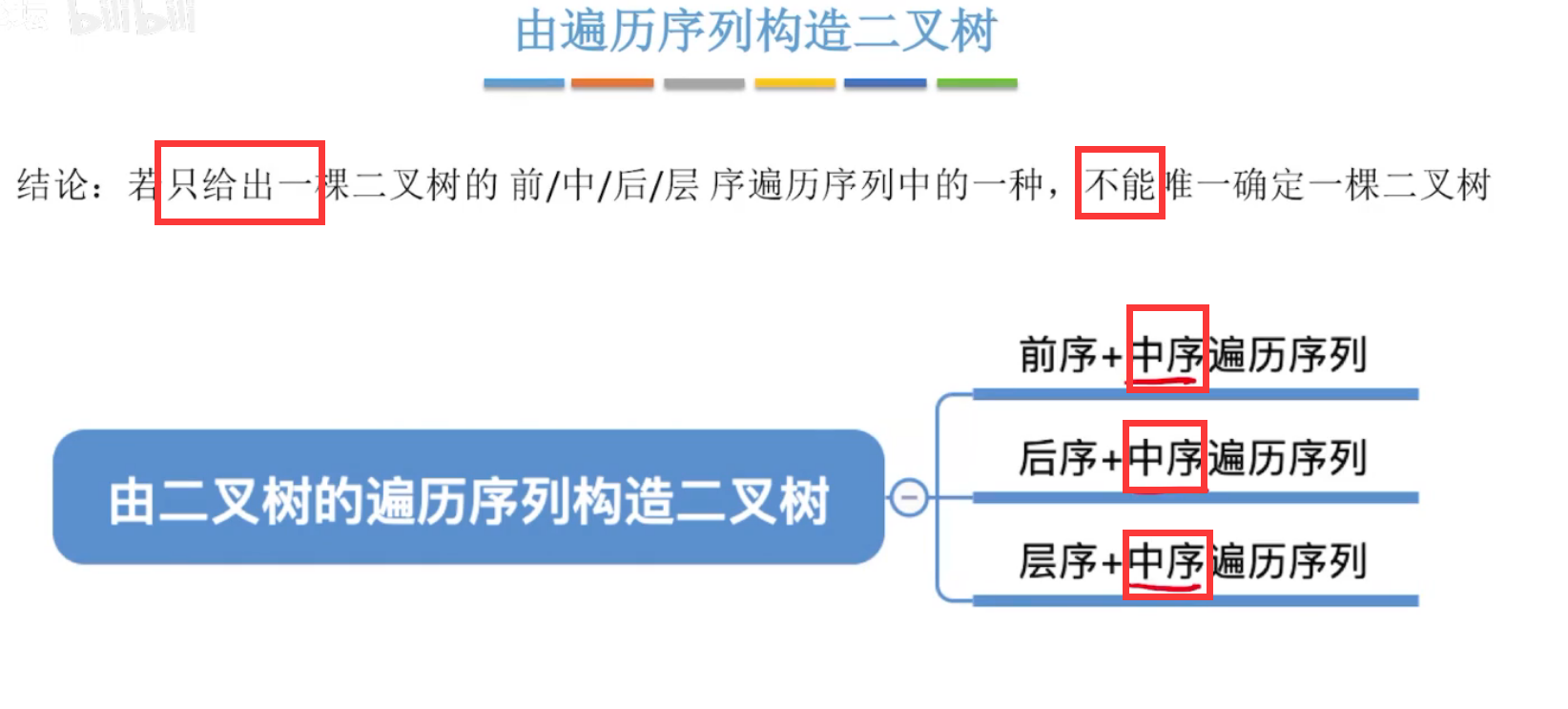
前序+中序:先确定根结点
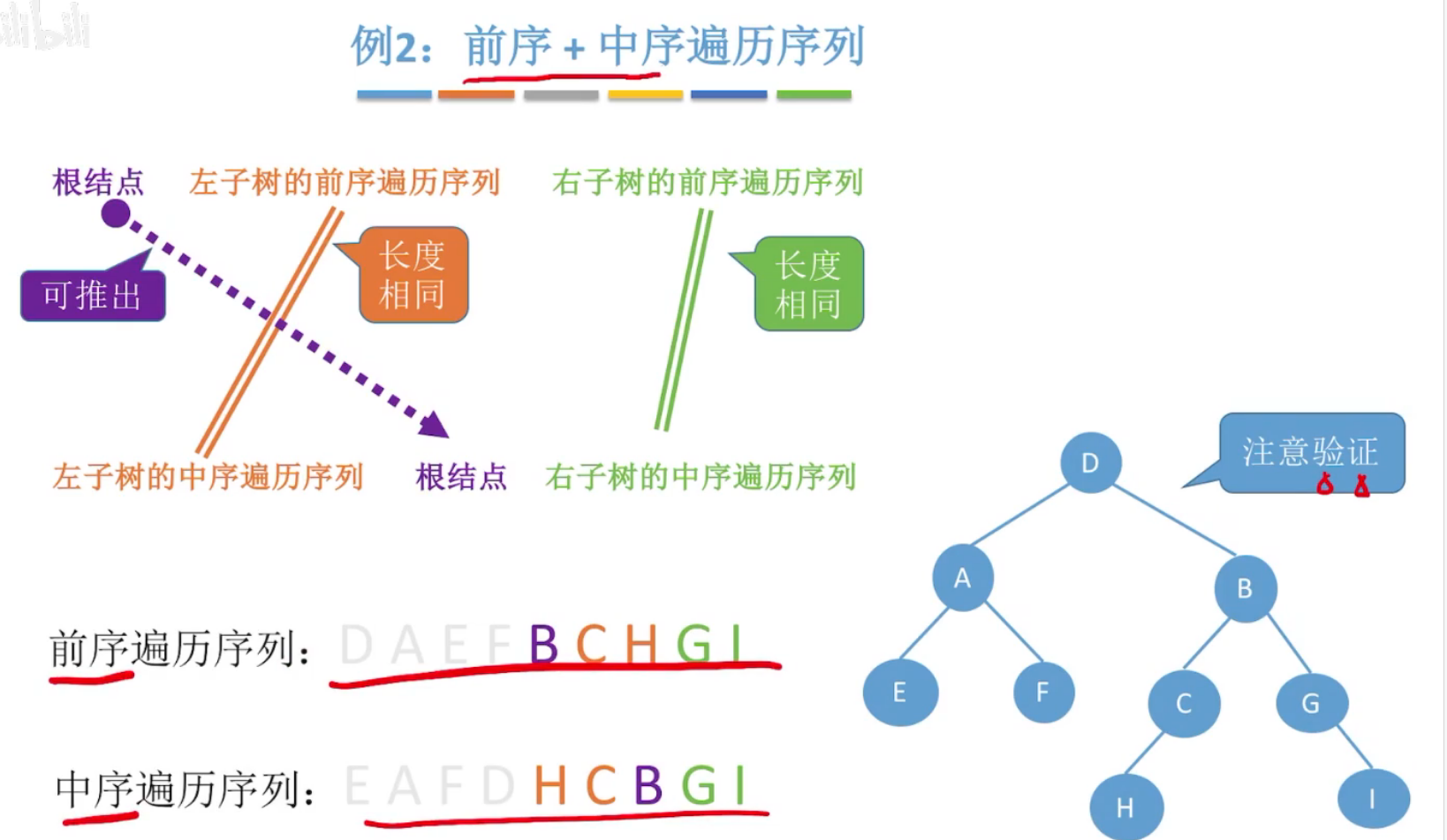
后序+中序:后序中最后出现的,必是根结点。
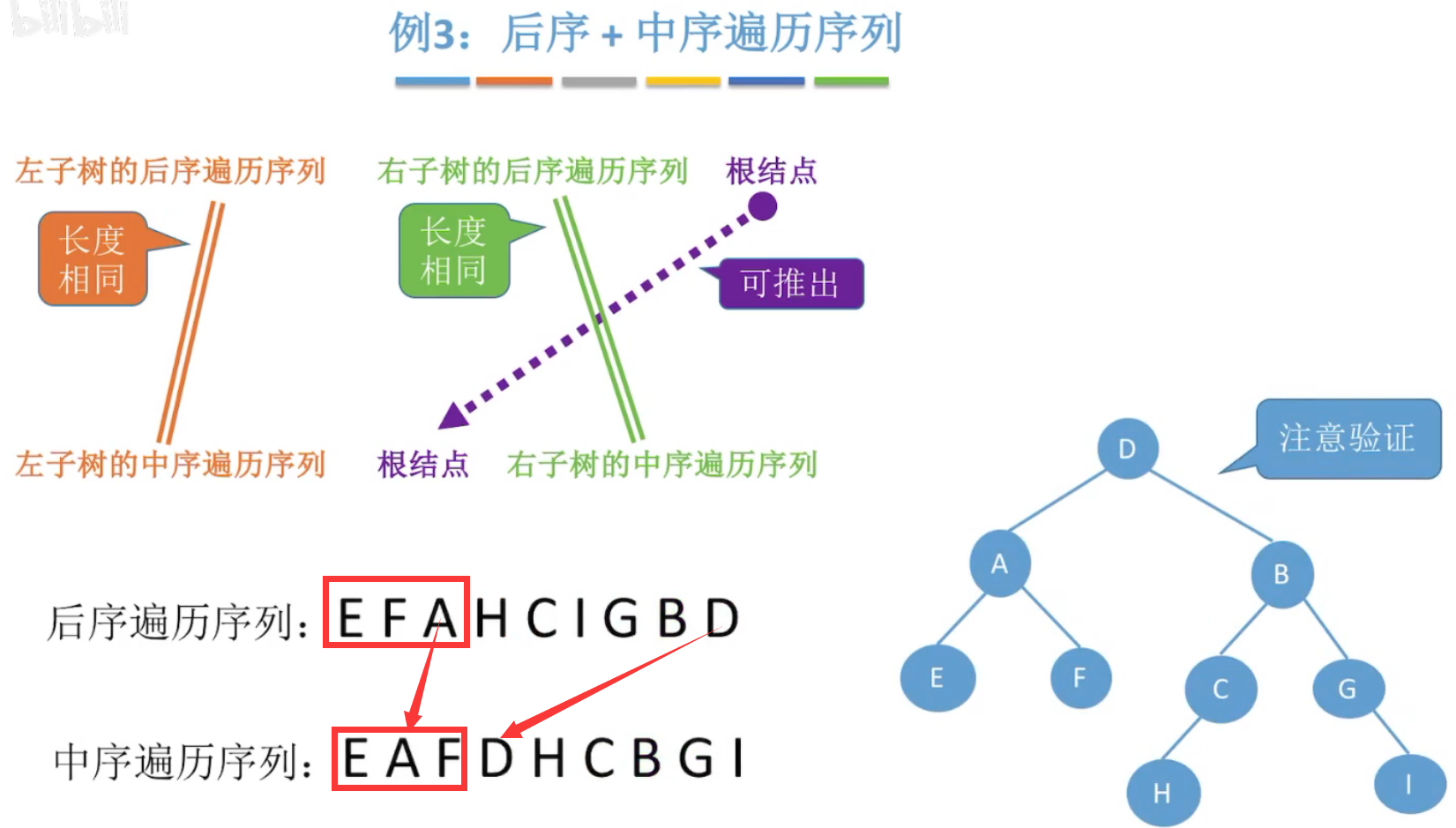
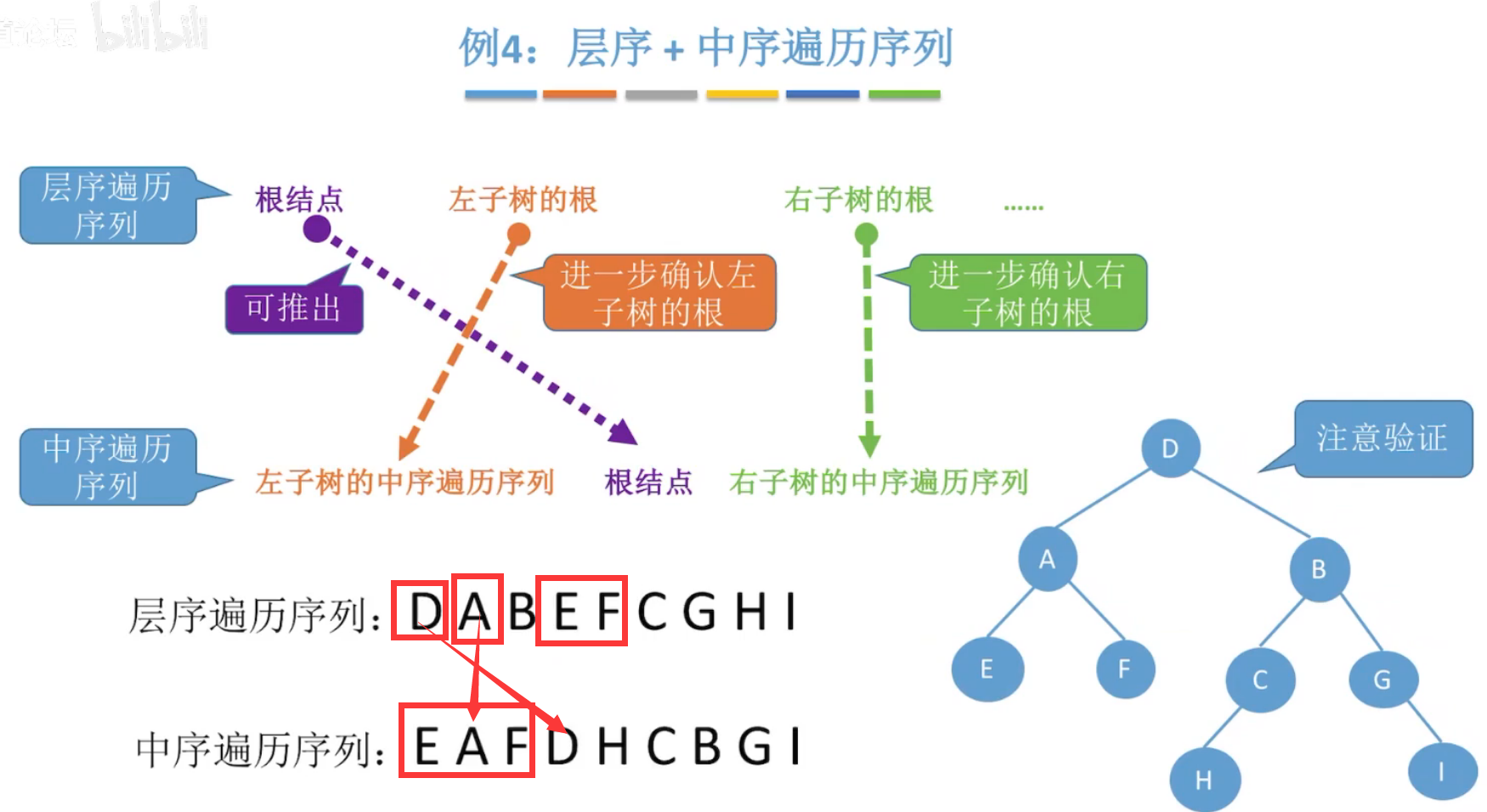
层序+中序:层序中先出现的必是根结点
(6)线索二叉树
空的结点指针,左结点指向前驱,右结点指向后继。
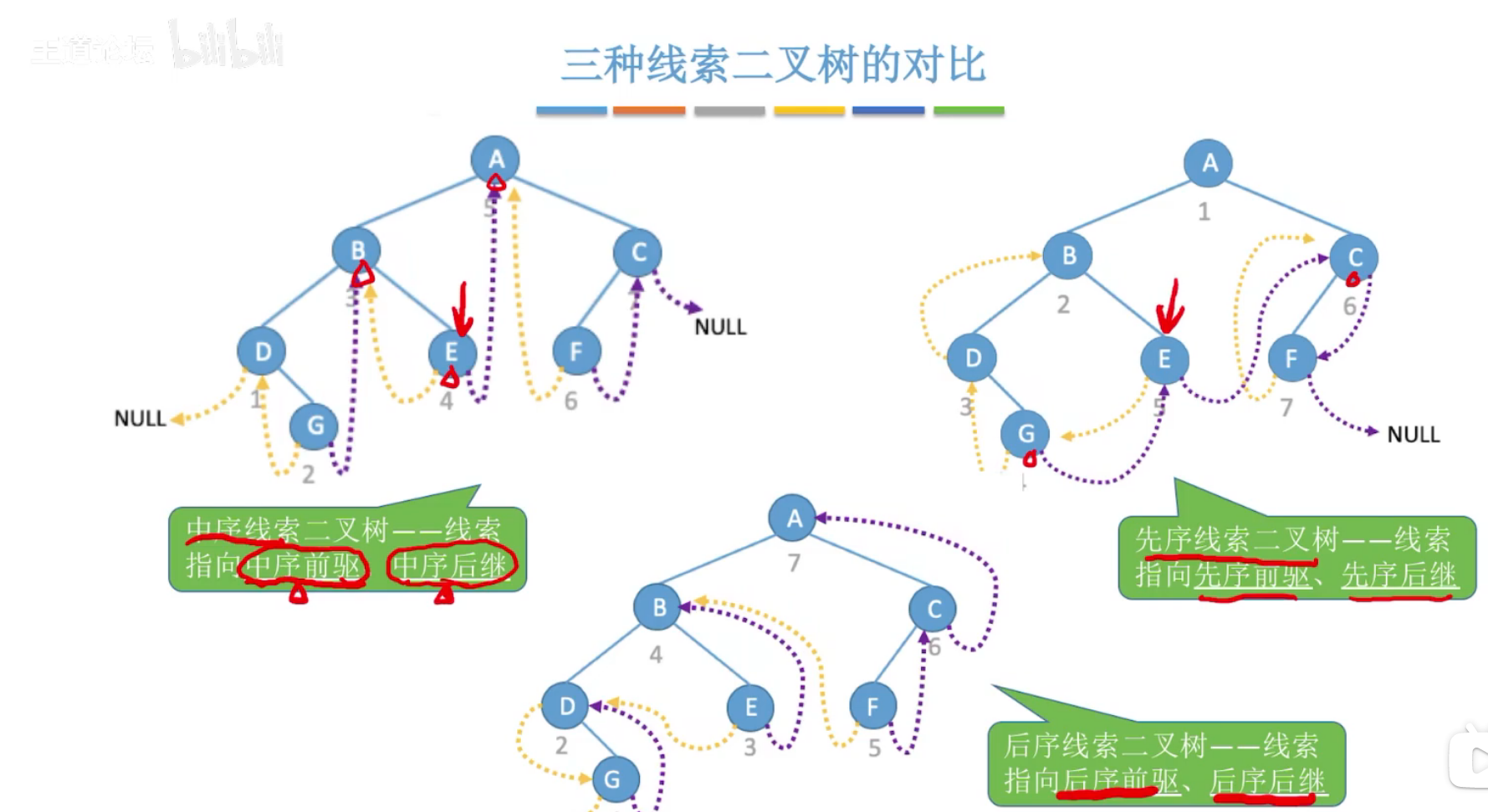
每个结点的前驱和后继,与其所对应(先序、中序、后序)序列中的前后位置一致。
3、树的存储结构
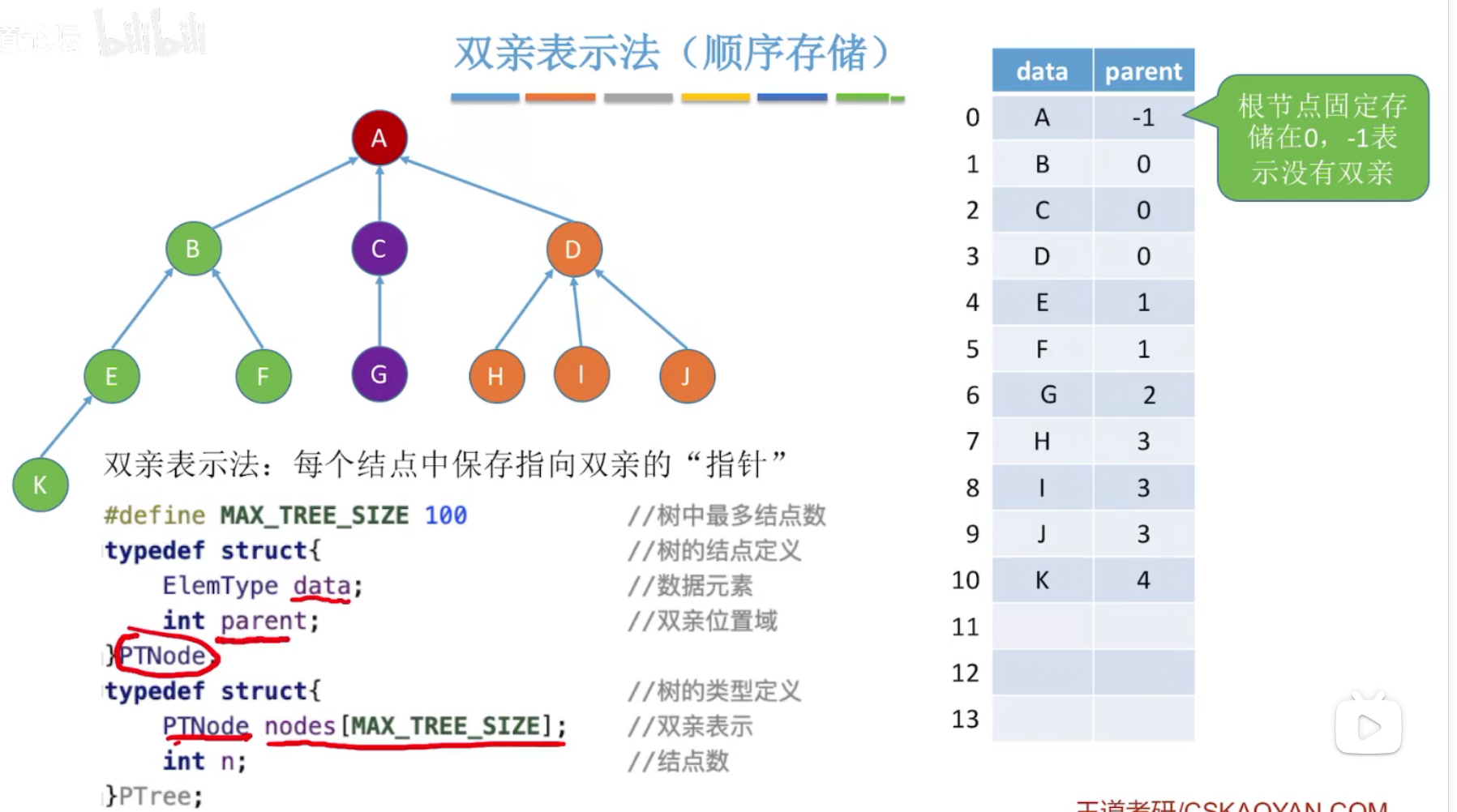
(1)双亲表示法
定义结构体,成员parent记录父节点在结构体数组中的下标
(2)孩子表示法
成员firstChild为链表指针,指向孩子结点,(并非孩子结点本身,而是记录孩子结点下标的数据结构,链表)
h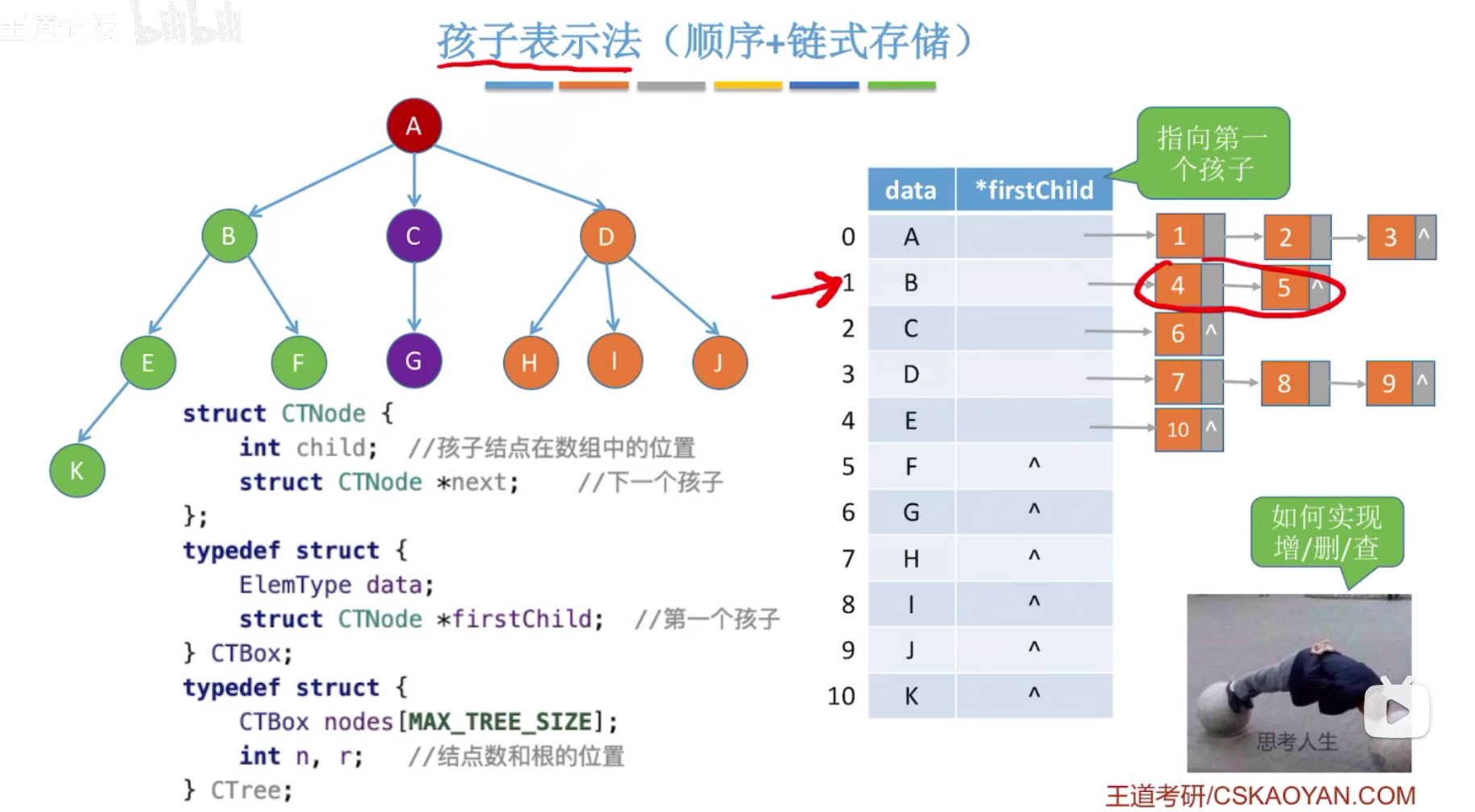
(3)孩子兄弟表示法
右指针指向有兄弟结点(与自己同一个父结点的结点,如E、F互为兄弟结点,H、I、J互为兄弟节点)。
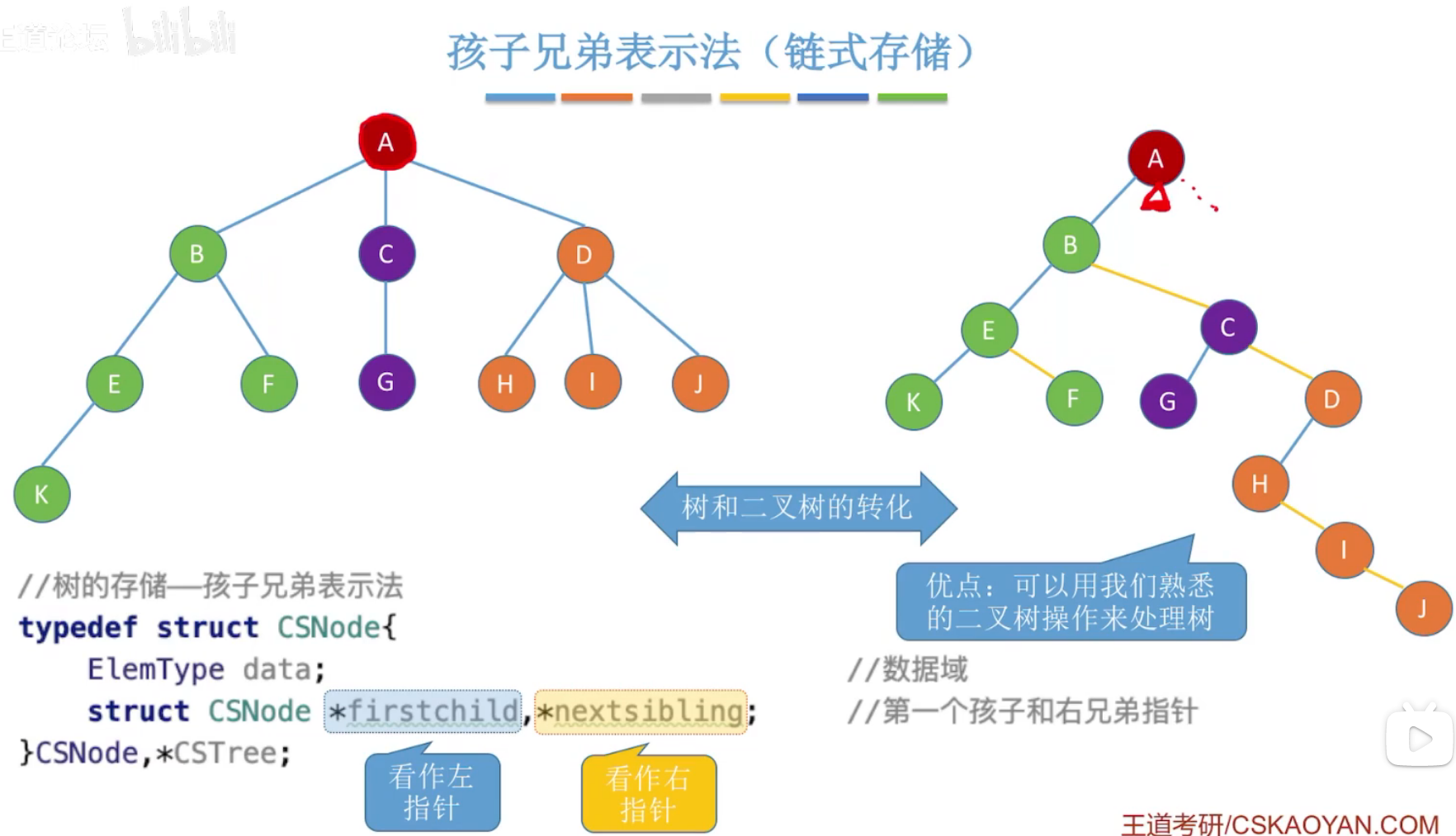
4、森林、二叉树-互相转换
森林转二叉树
将森林所有根结点看作兄弟结点,利用孩子兄弟表示法表示为二叉树。
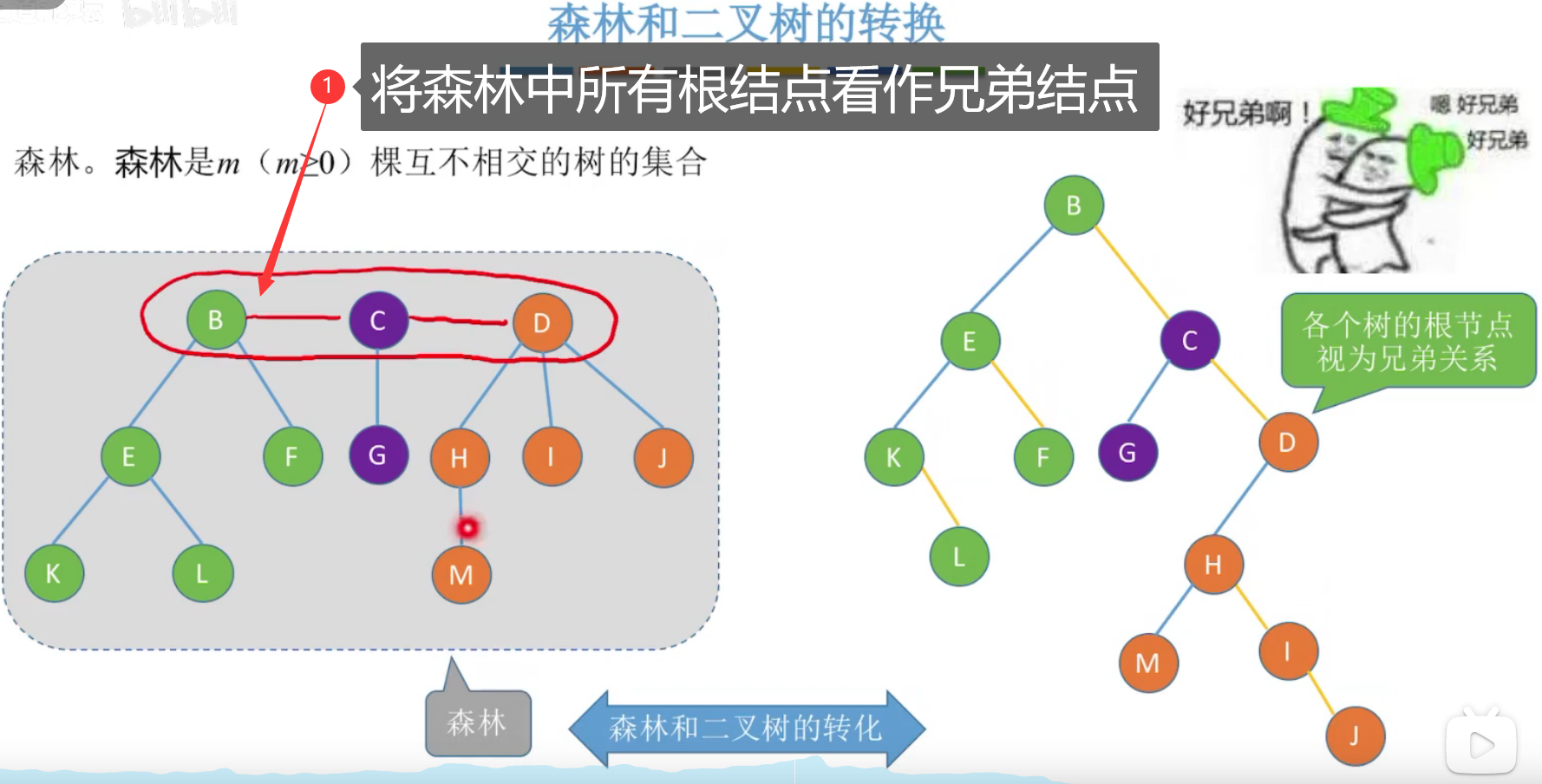
二叉树转森林
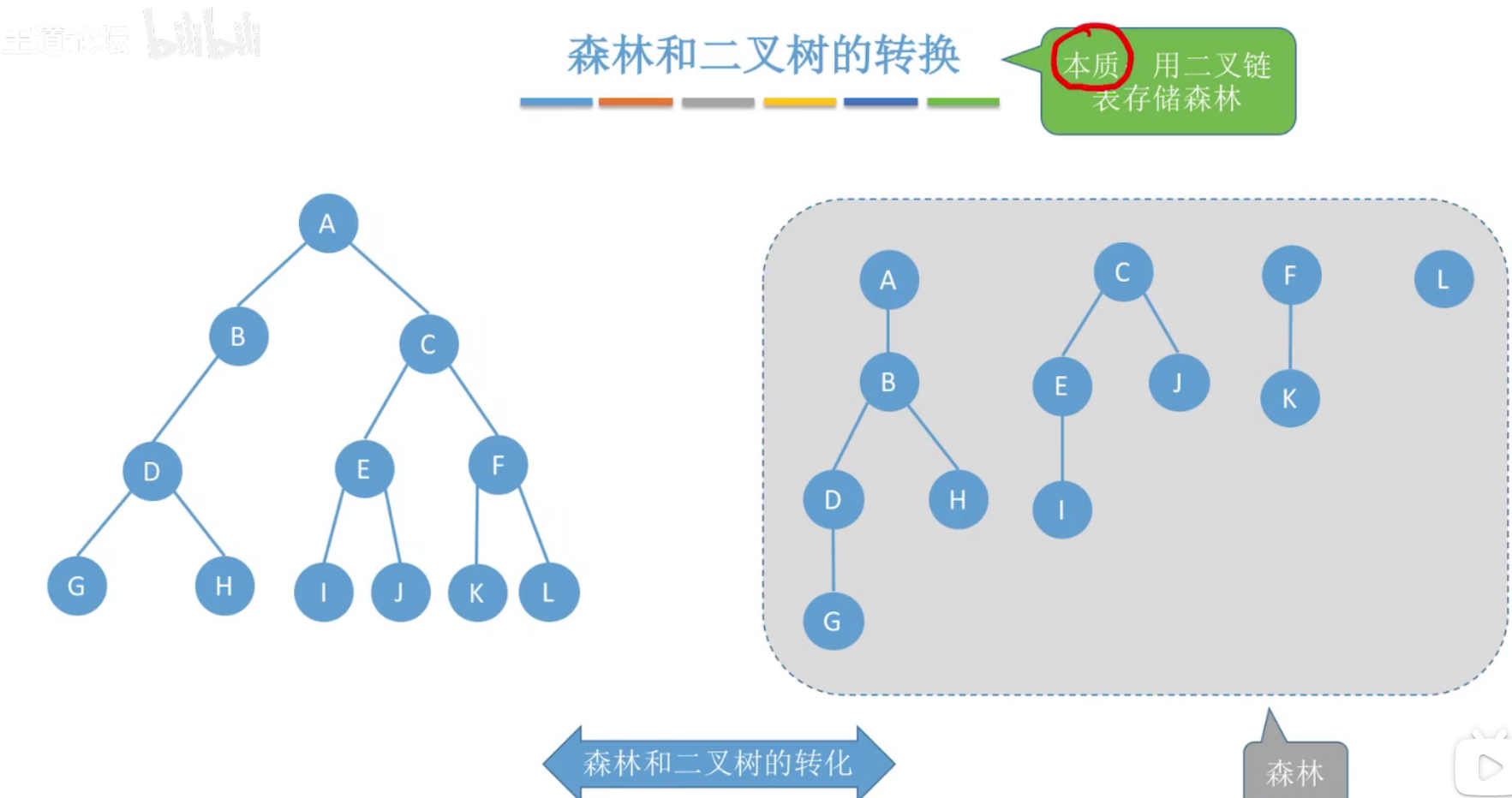
5、树、森林的遍历
(1)树的遍历
-
先根遍历:先访问根节点,再依次访问所有子节点,每个子结点依然按照先根遍历。
类似于先序遍历-根左右
该访问序列 = 对应二叉树的先序遍历序列
-
后根遍历:先依次访问所有子结点,最后访问根结点,对每个子树再依然按照后跟遍历。
类似于后序遍历-左右根
该访问序列 = 对应二叉树的中序遍历序列
-
层次遍历:用队列实现。一层一层依次访问。
(2)森林的遍历
-
先序遍历森林:效果等同于依次对各个树进行先根遍历
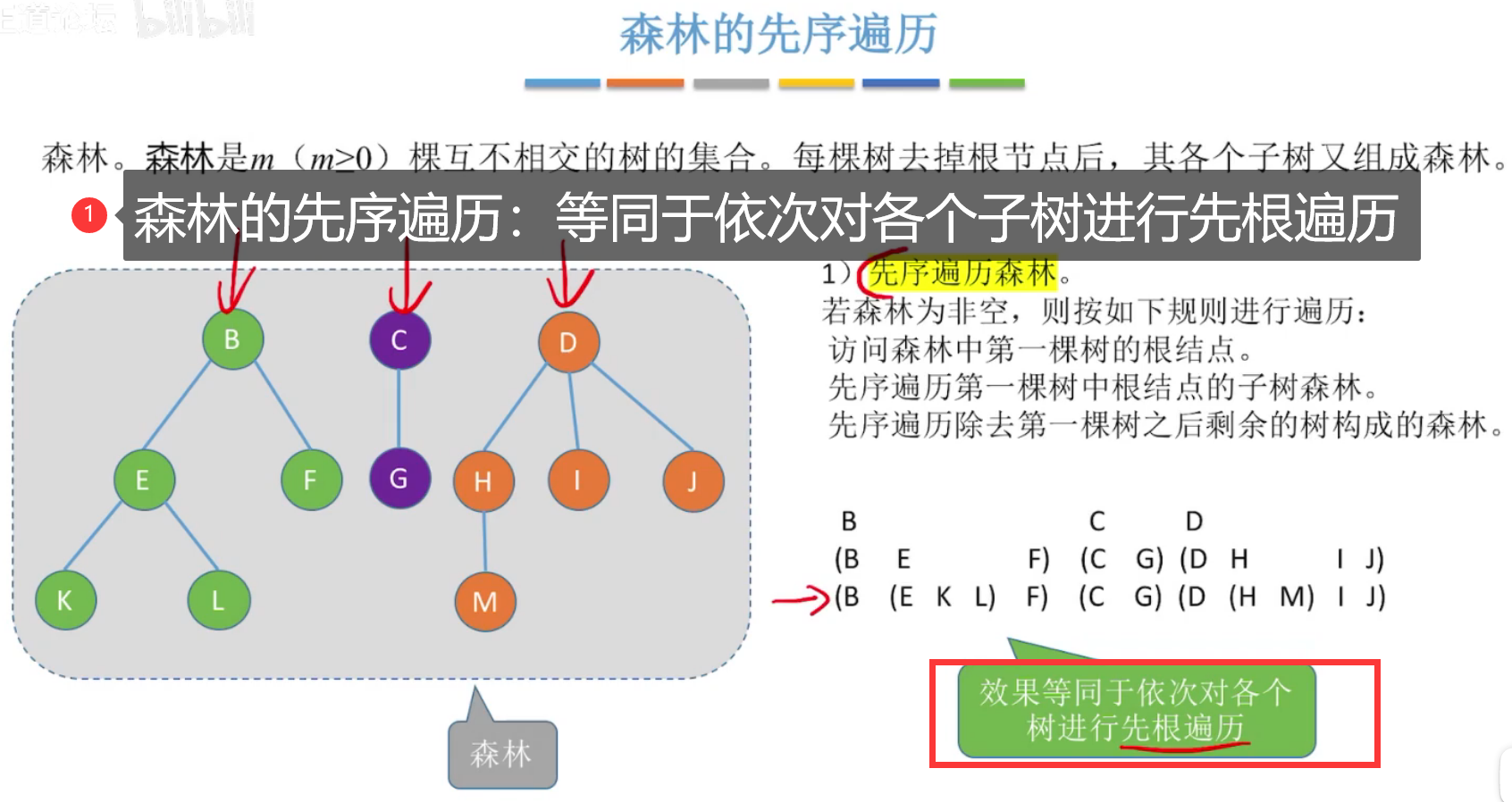
该序列 = 森林对应二叉树的先序遍历序列
-
中序遍历森林:等同于依次对各个树进行后跟遍历得到的序列
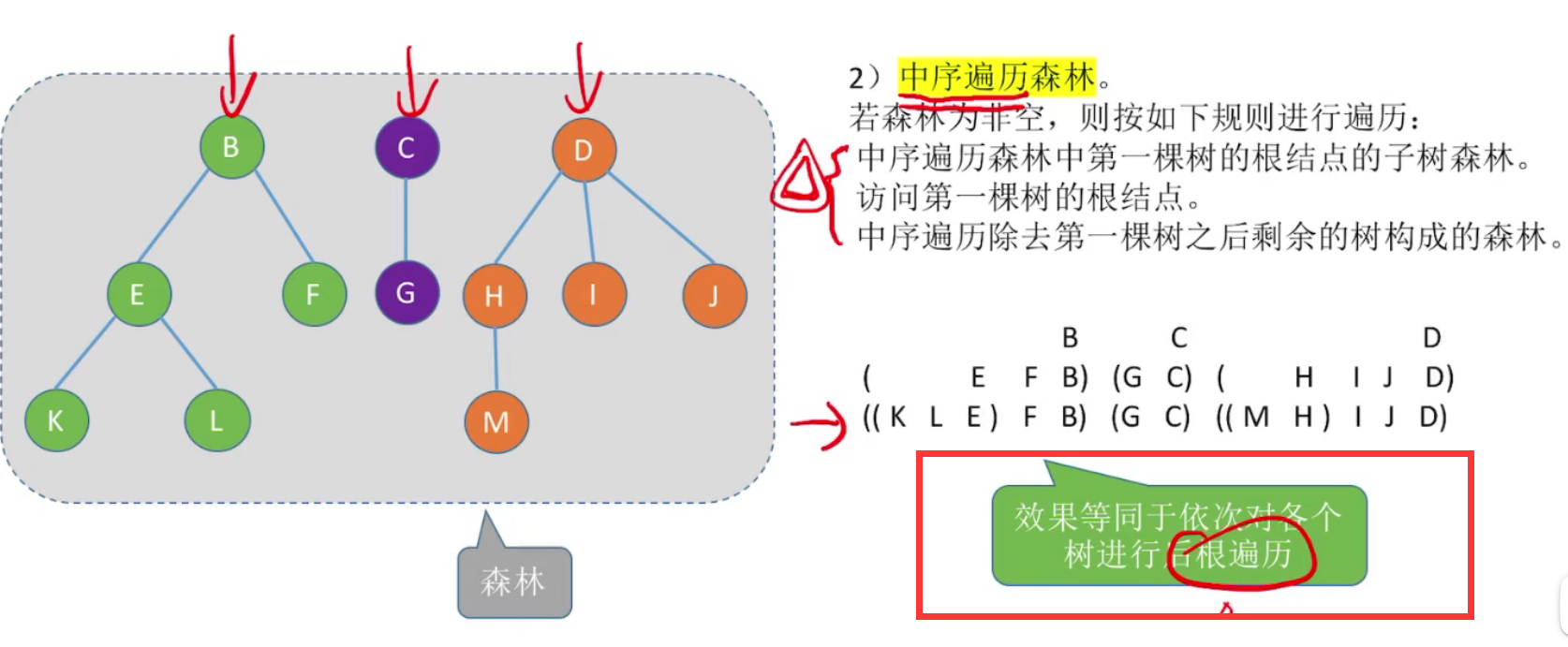
该序列 = 森林对应二叉树的中序遍历序列
6、二叉查找树(二叉排序树)BST
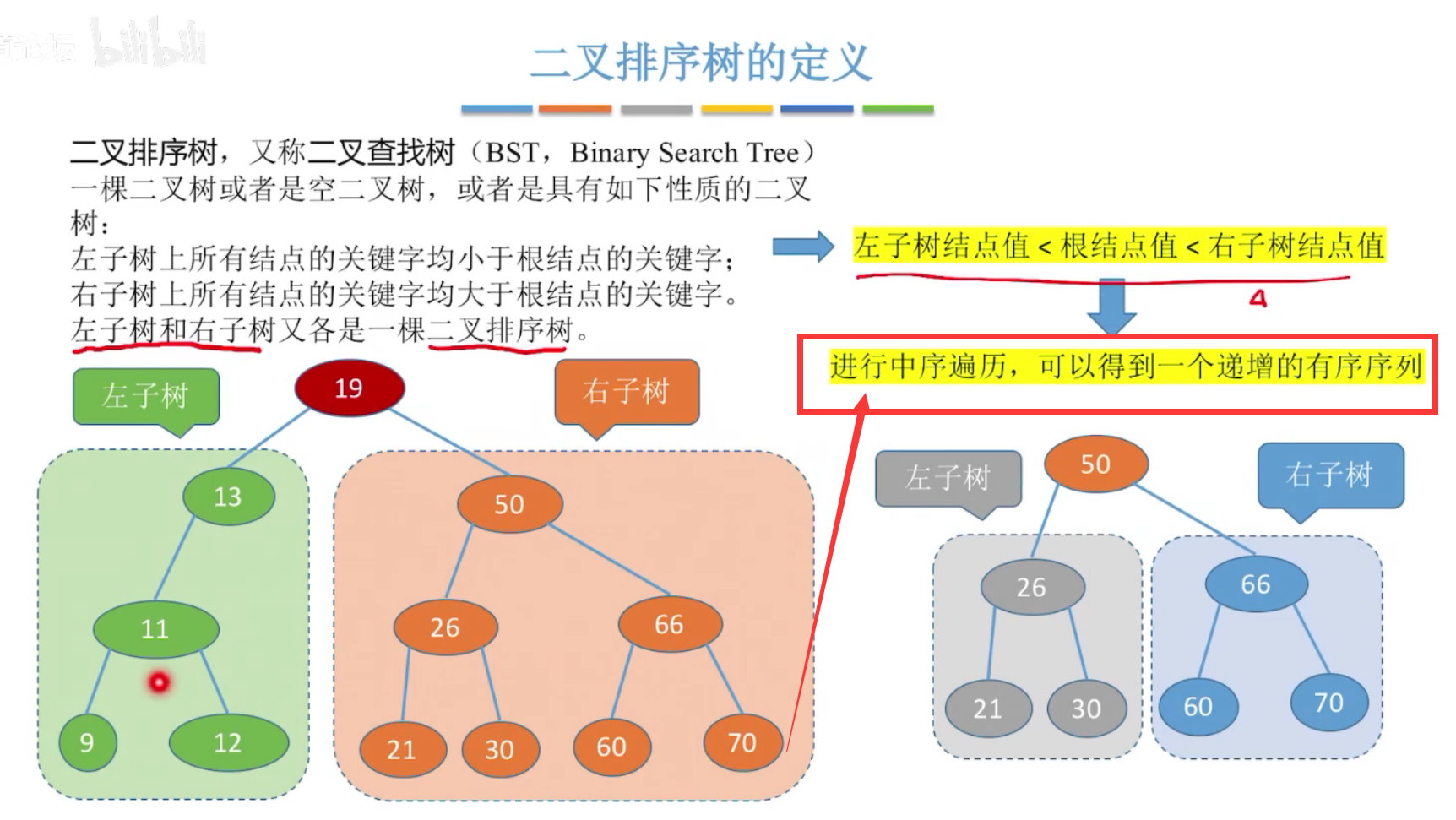
对二叉排序树进行中序遍历,得到一个递增的有序序列。
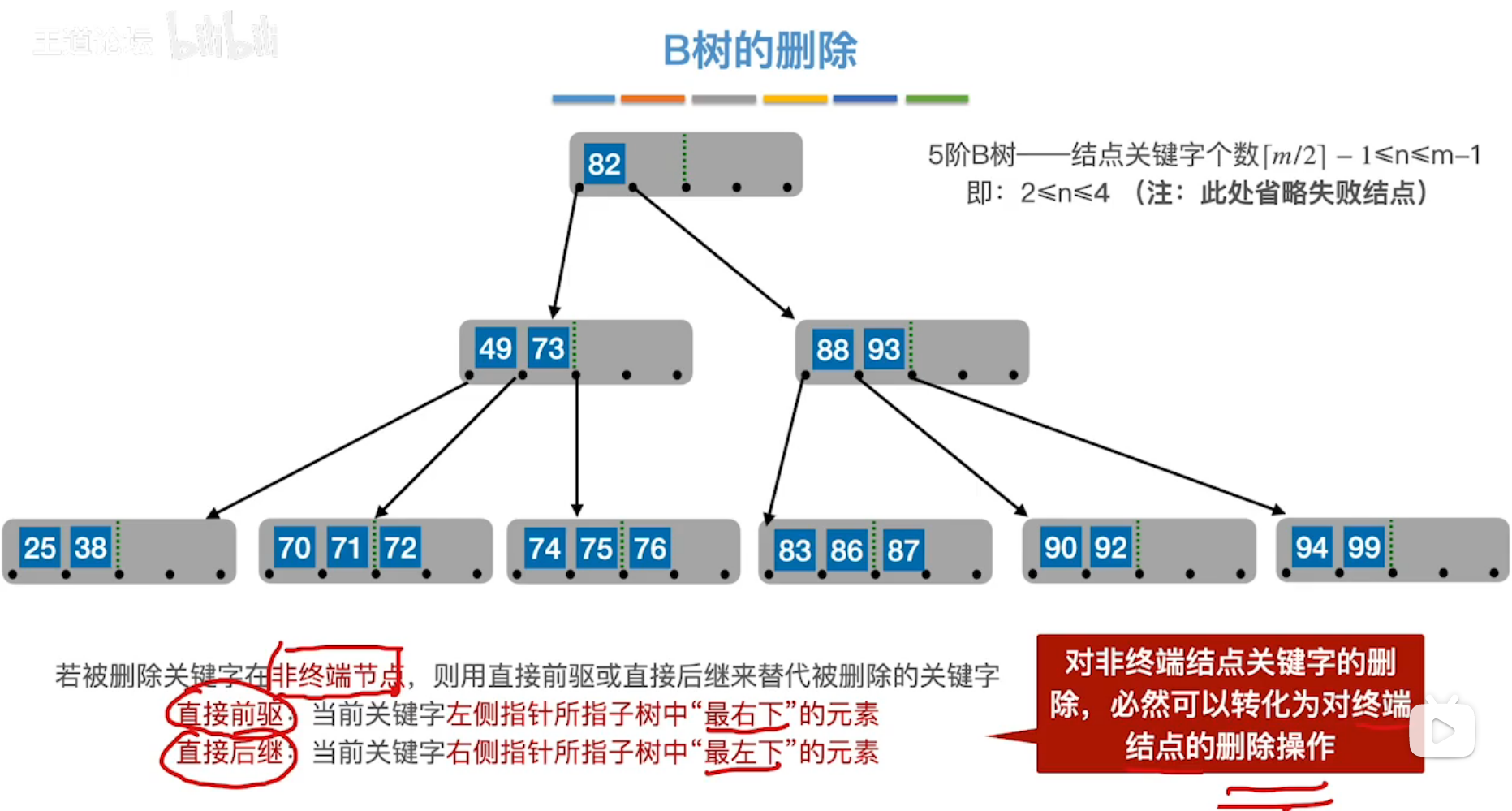
对二叉查找树的删除操作
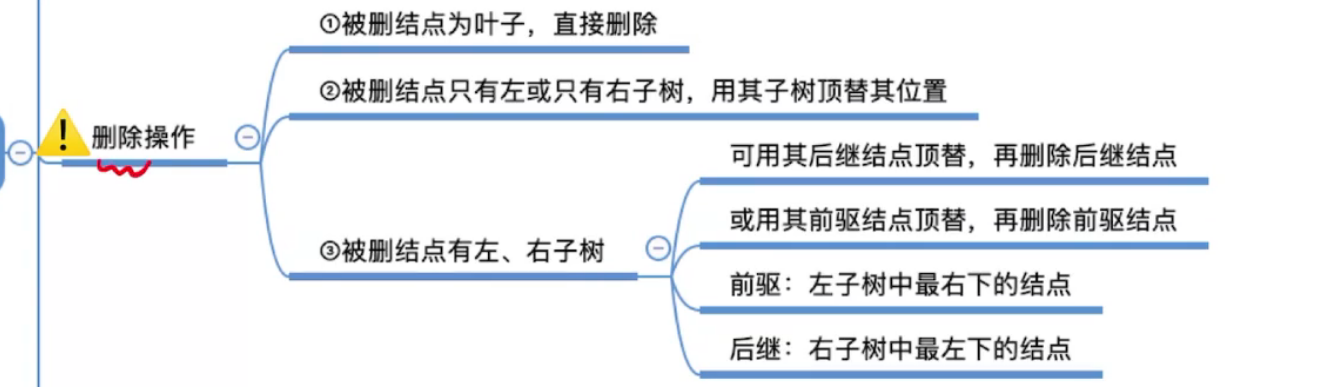
最麻烦的是第三种情况:被删结点同时有左、右子树,两种方法
- 用前驱结点顶替,即左边最大的数,左子树中最右下的结点。
- 用后继结点顶替,即右边最小的数,右子树中最左下的结点。
7、平衡二叉树:BBT、AVL树
定义:树上任意节点的左子树与右子树的高度之差不超过1。
结点的平衡因子:左子树高-右子树高
平衡二叉树各个结点的平衡因子只能是-1,0,1。
考点:平衡二叉树中插入一个结点后不再平衡,将其调整恢复为平衡二叉树。
四种情况导致不平衡(A为最小不平衡二叉树的根节点)
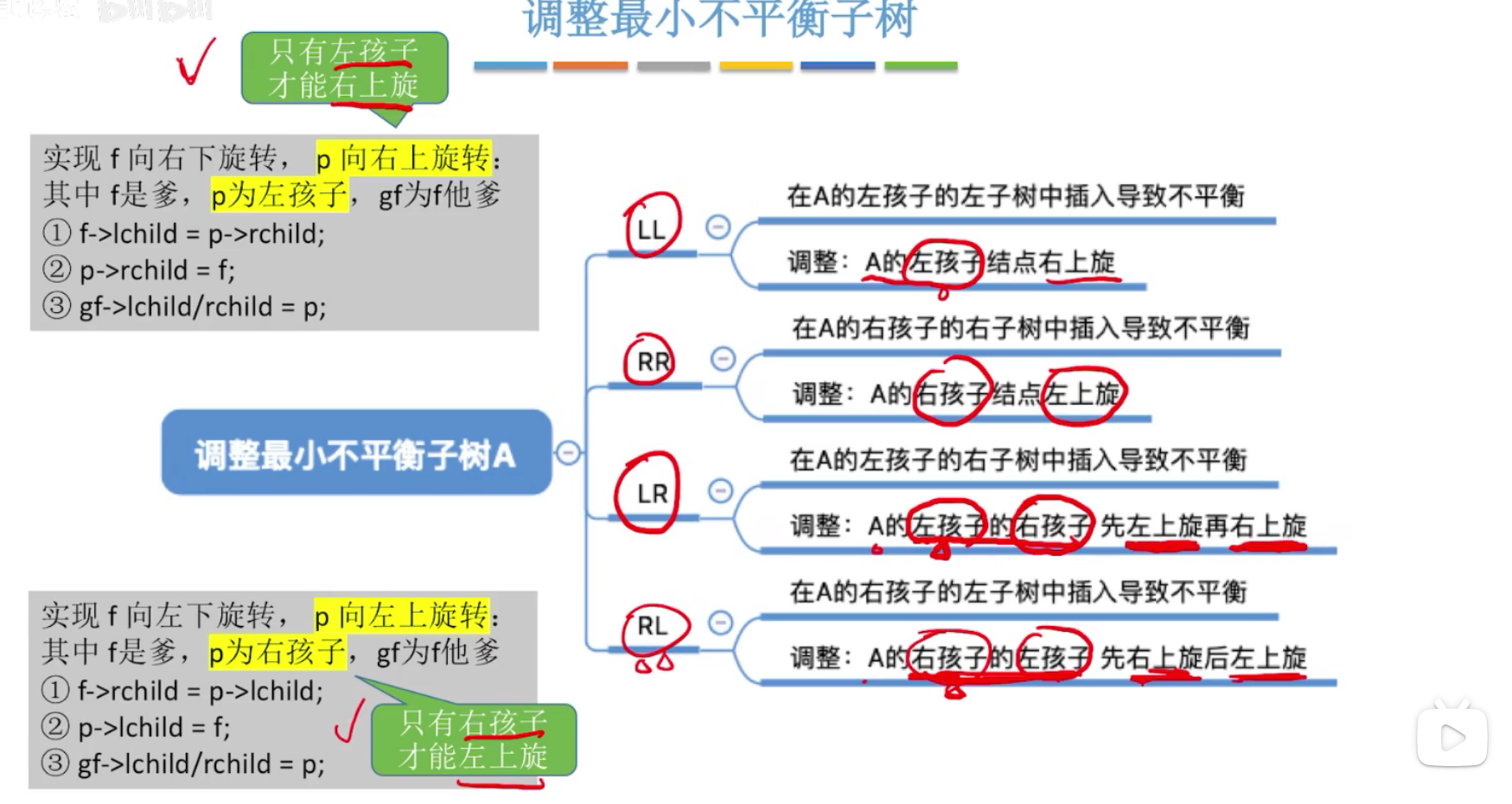
注意LR、RL型,需要旋转两次才能恢复。
LR:在A的左孩子的右子树中插入导致不平衡
RL:在A的右孩子的左子树中插入导致不平衡
8、哈夫曼树
结点的权、结点的带权路径长度、树的带权路径长度
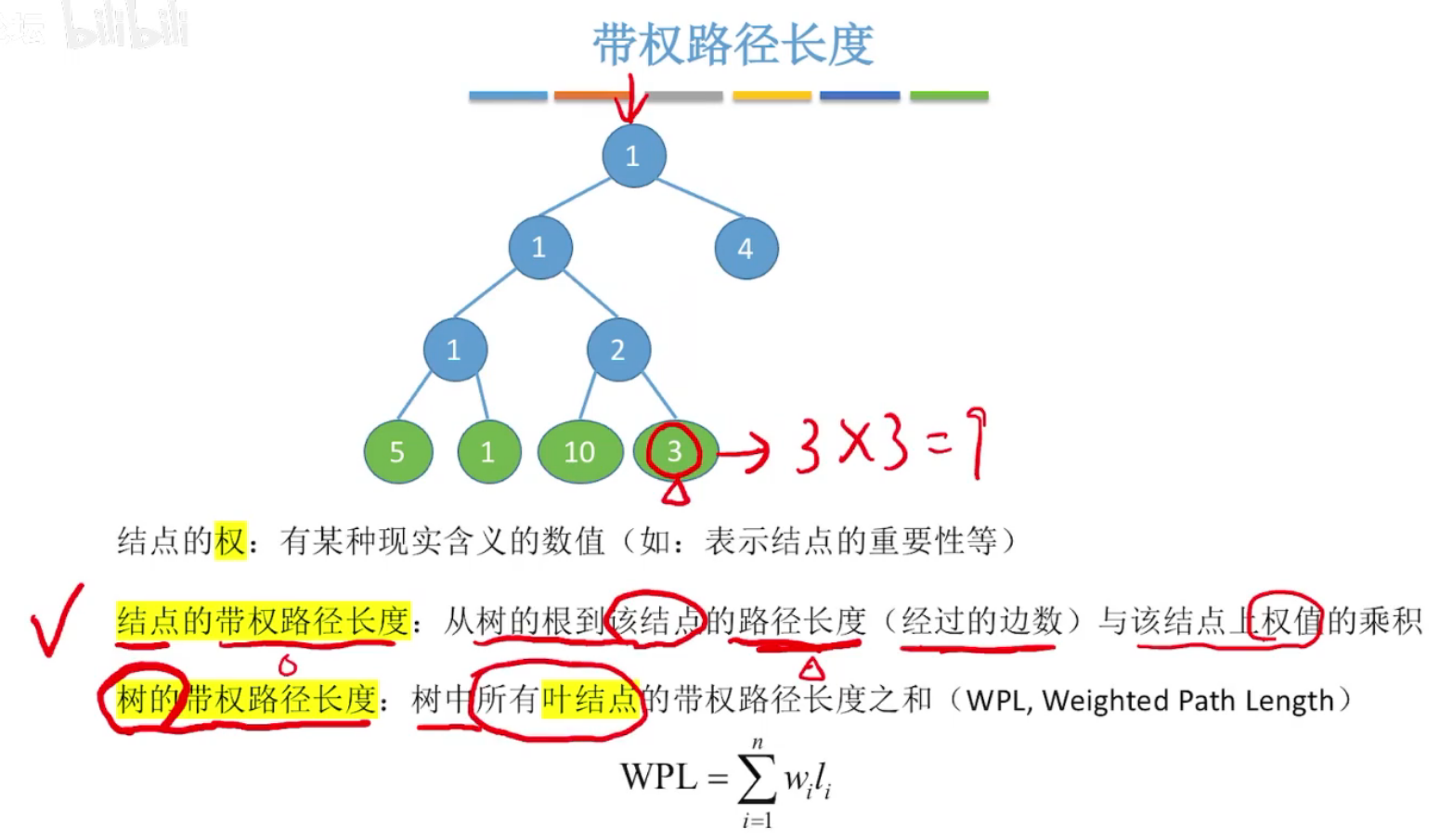
注意:树的带权路径长度,只算叶结点。
哈夫曼树:在含有n个带权叶结点的二叉树中,带权路径长度最小的二叉树称为哈夫曼树,也称为最优二叉树。
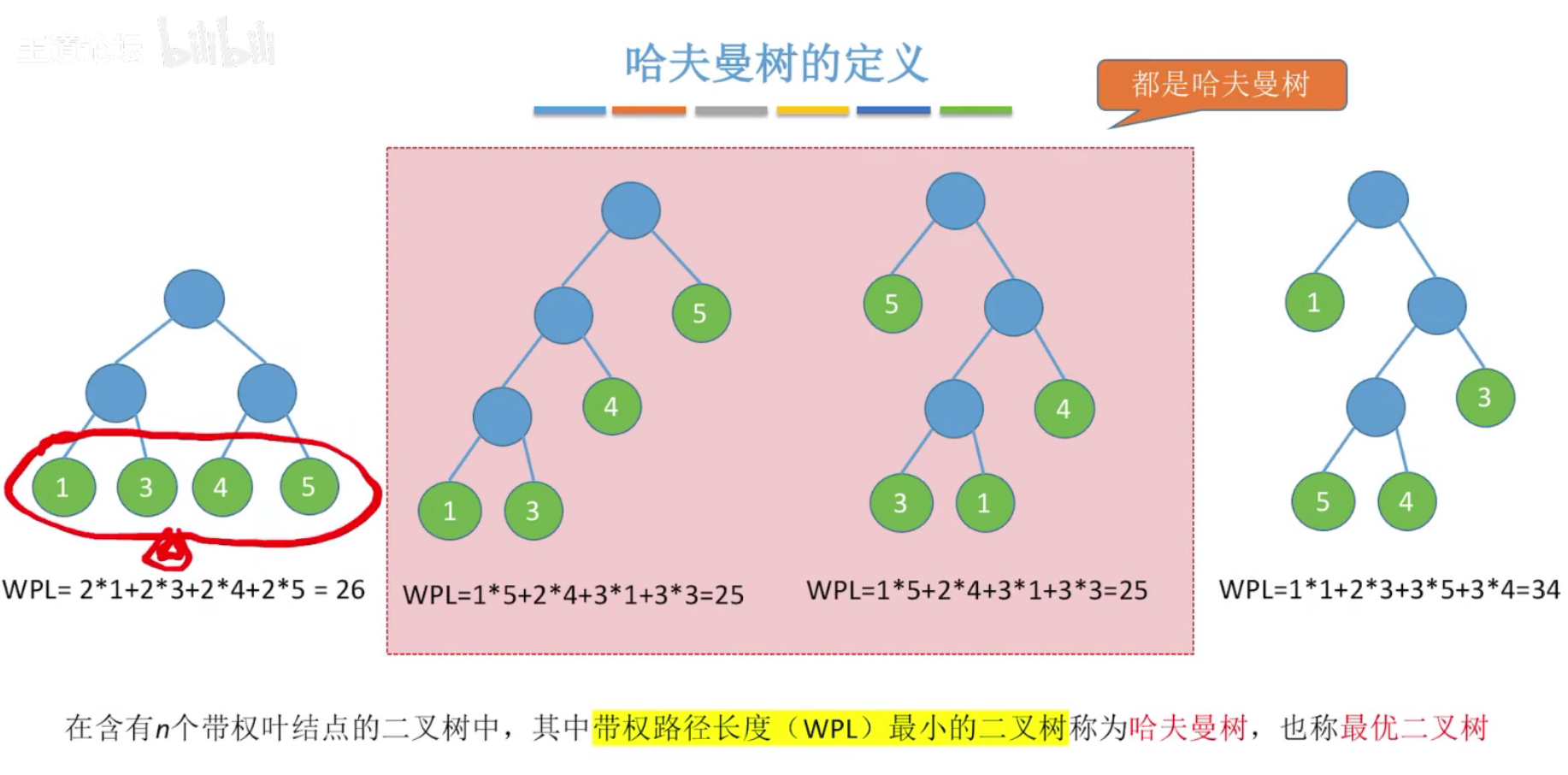
哈夫曼树不唯一。
构造哈夫曼树:不唯一,要求树的带权路径长度最低。
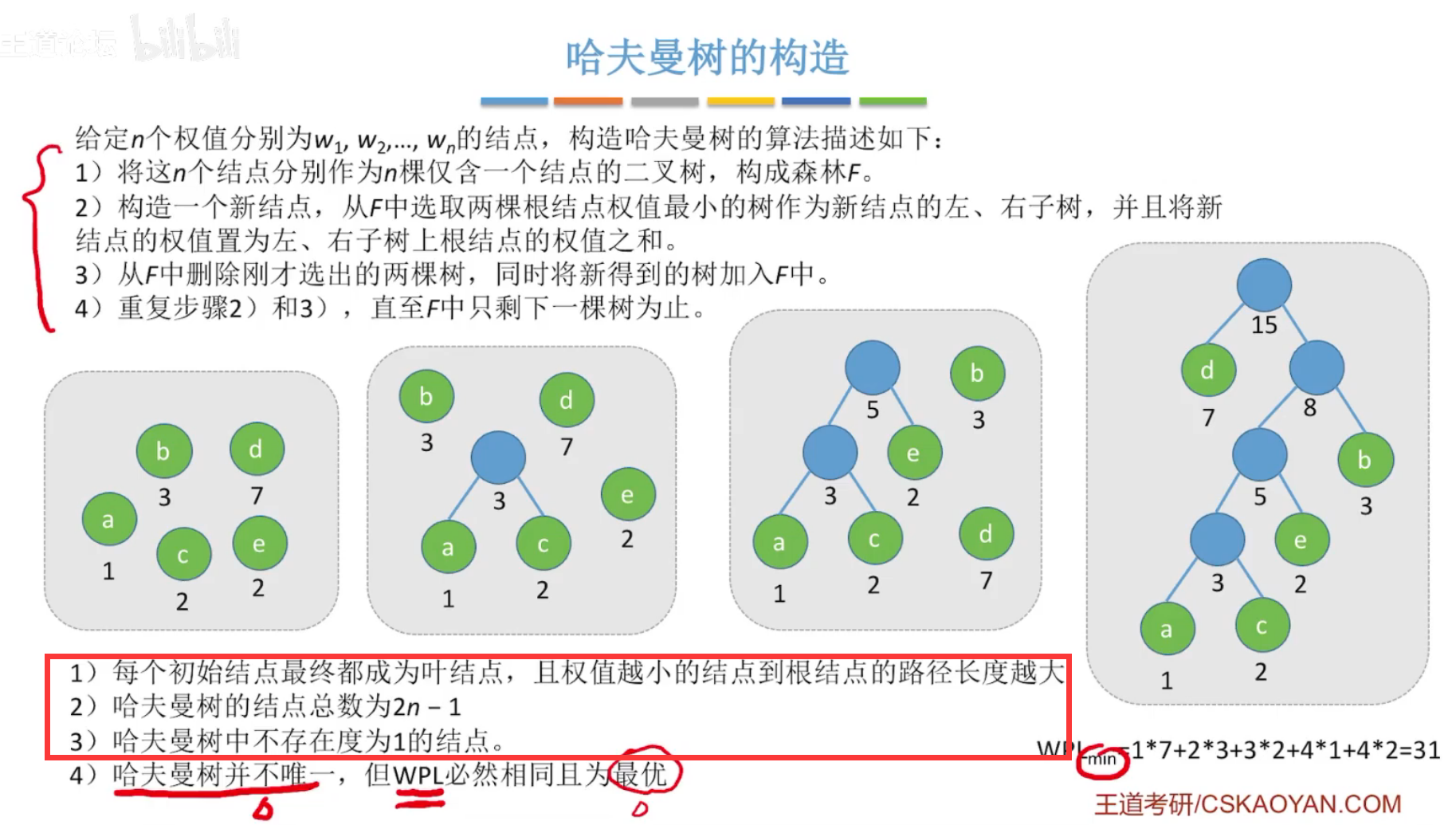
哈夫曼编码:用于数据的压缩
优先选择权值最高的结点进行编码,使其带权路径最小。
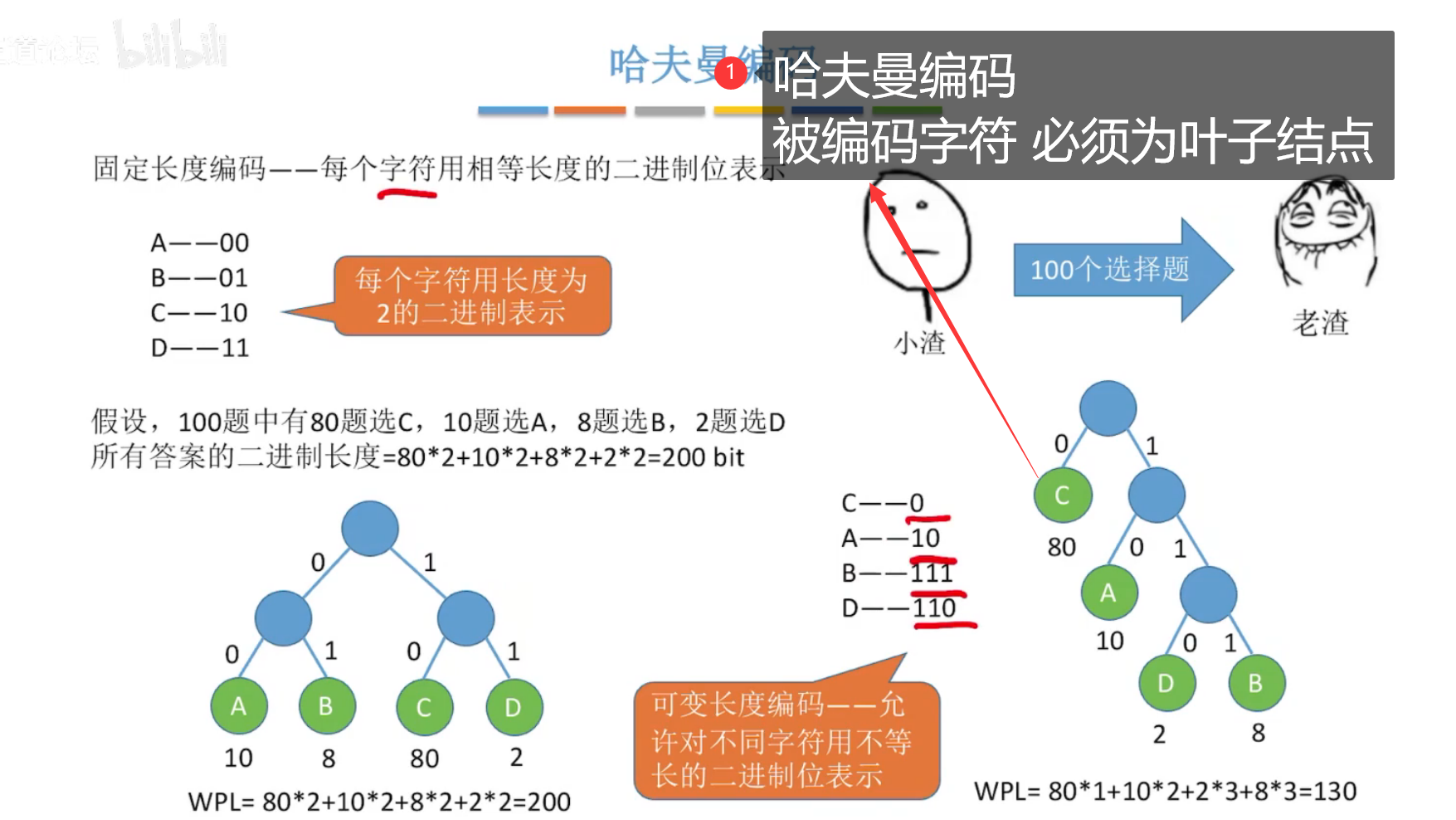
前缀编码:指没有一个编码是另一个编码的前缀。用于统一哈夫曼树的表示。
六、图
1、图的基本概念
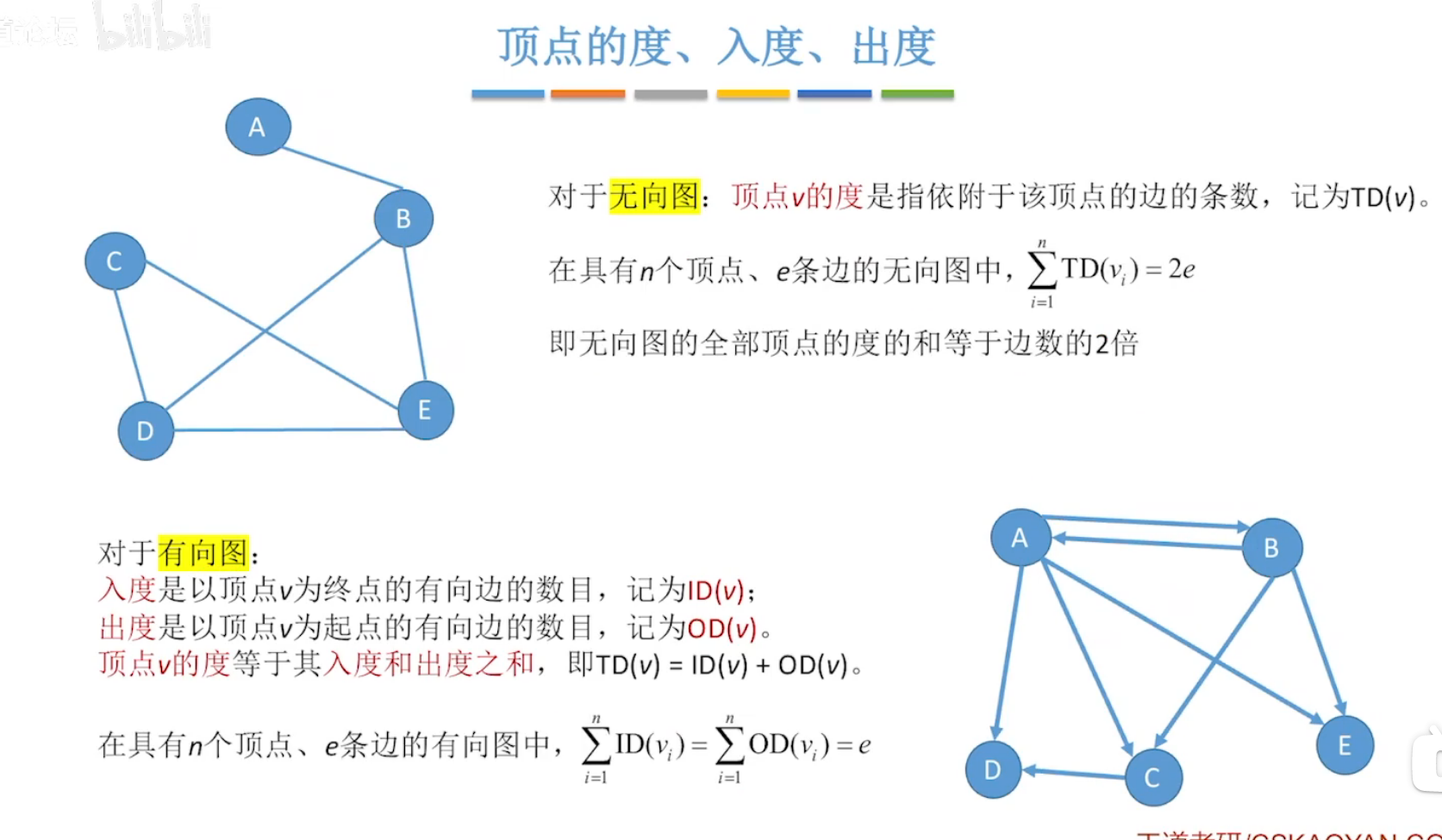
图G由顶点集V和边集E组成
图不可以是空图(即顶点集不能为空,但边集可以为空)。(边的两头必须连有顶点)
图分为无向图和有向图,
无向图中的无向边表示为(v,w)或(w,v),w、v为顶点。
有向图中的有向边表示为<v,w>或<w,v>,w、v为顶点。
无向图:顶点v的度,指依附于该顶点的边的条数。记为TD(v)
有向图:分为入度和出度,分别记为ID(v)和OD(v)
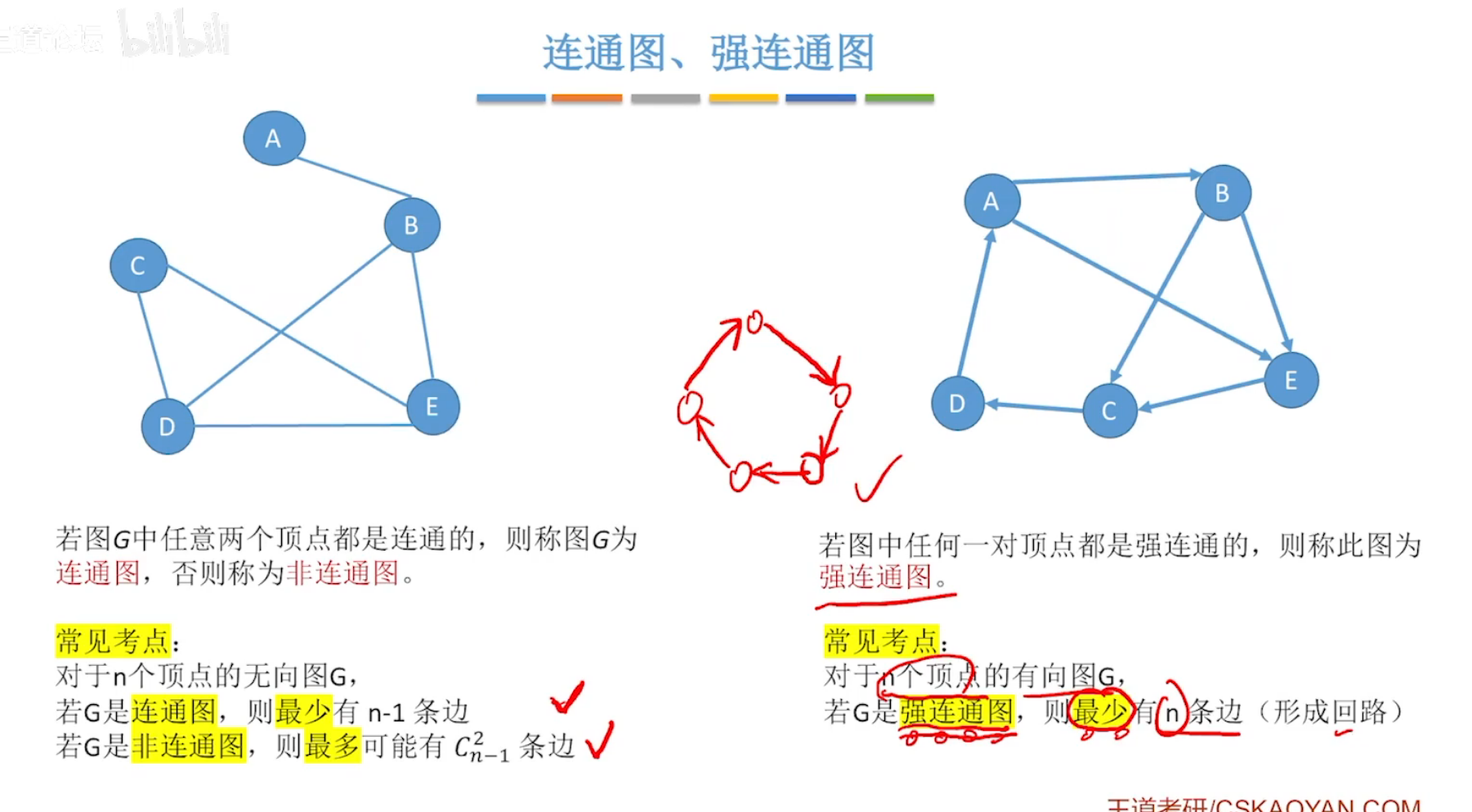
连通图与强连通图
子图与生成子图
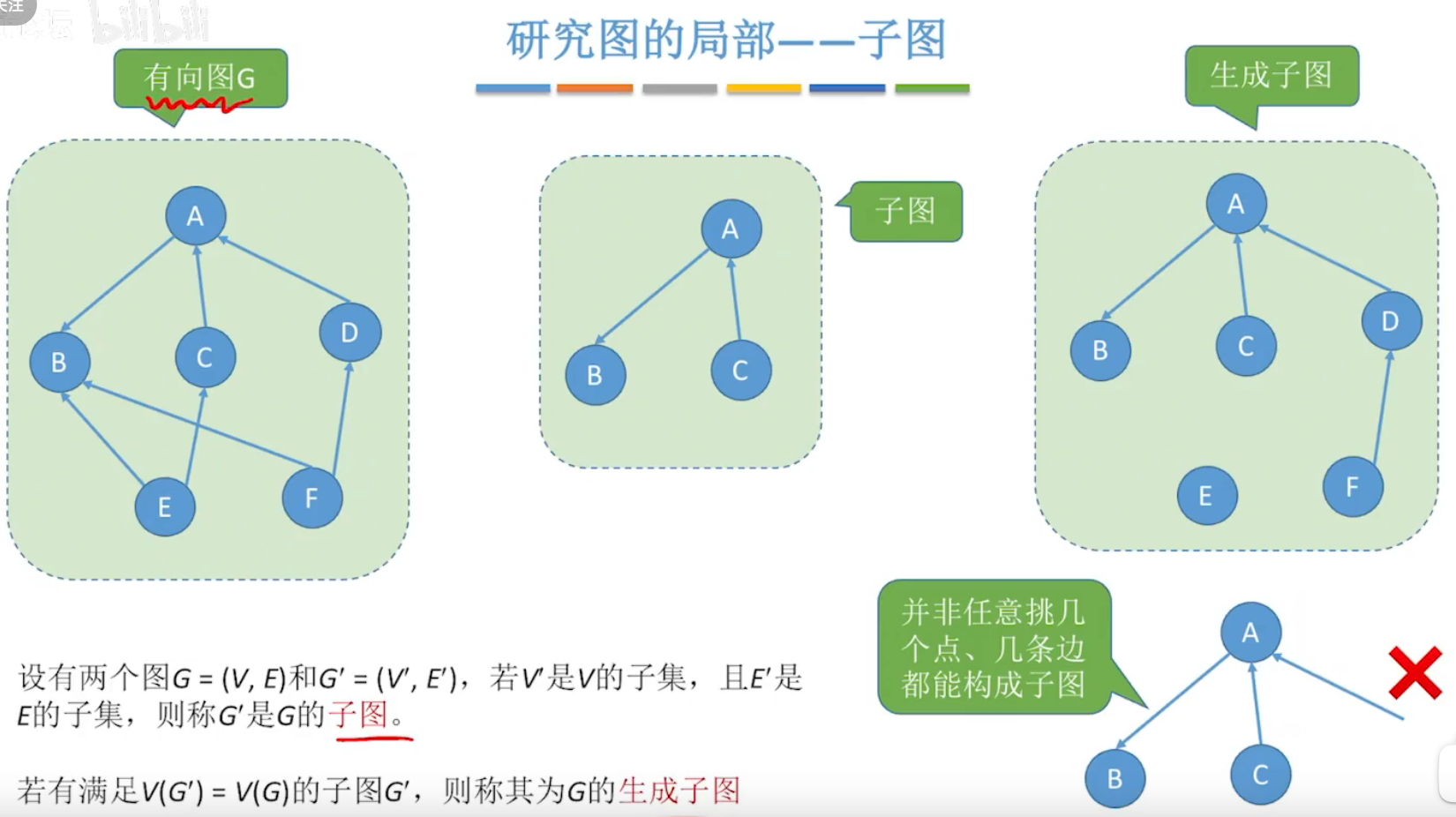
极小连通子图,即生成树
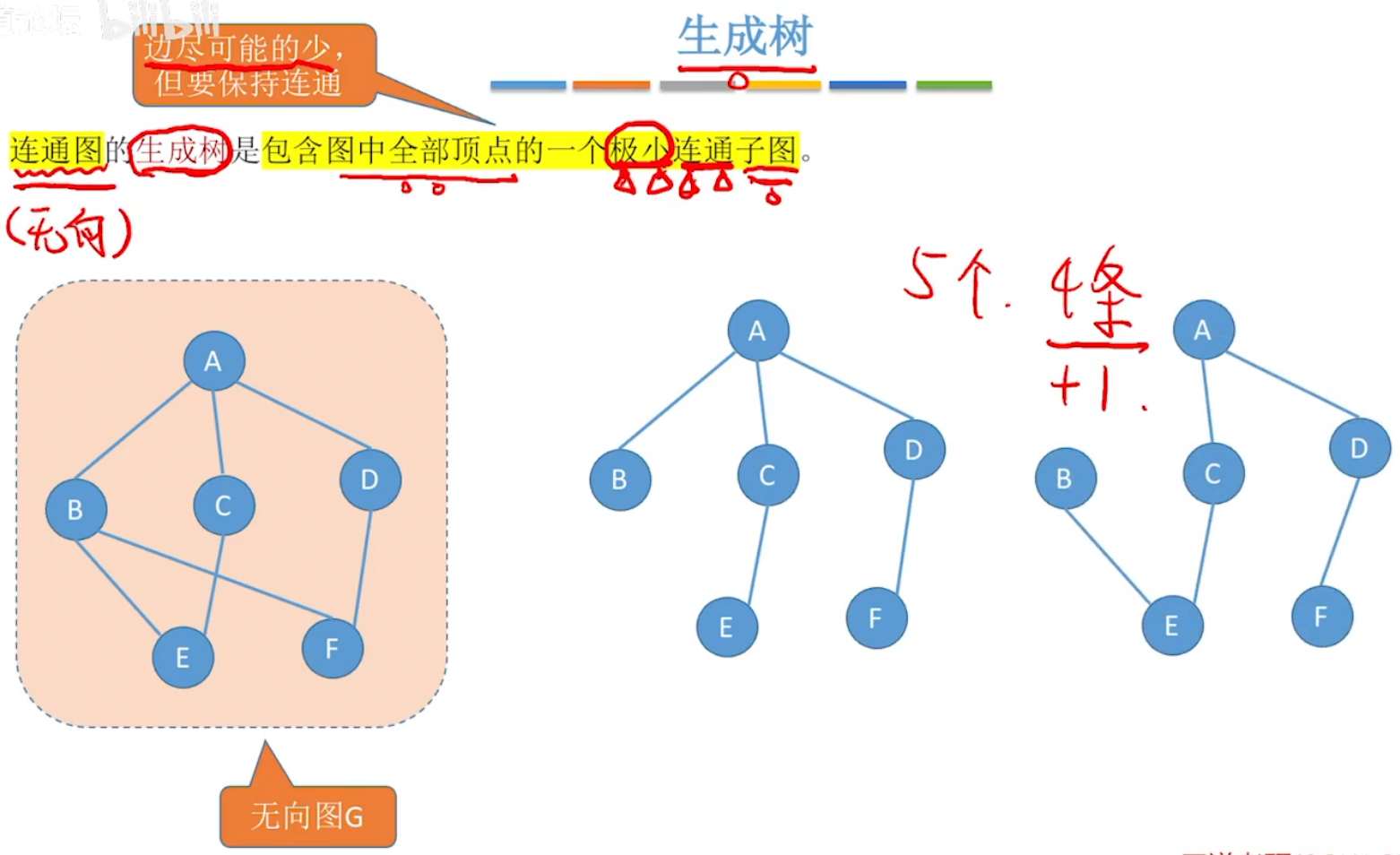
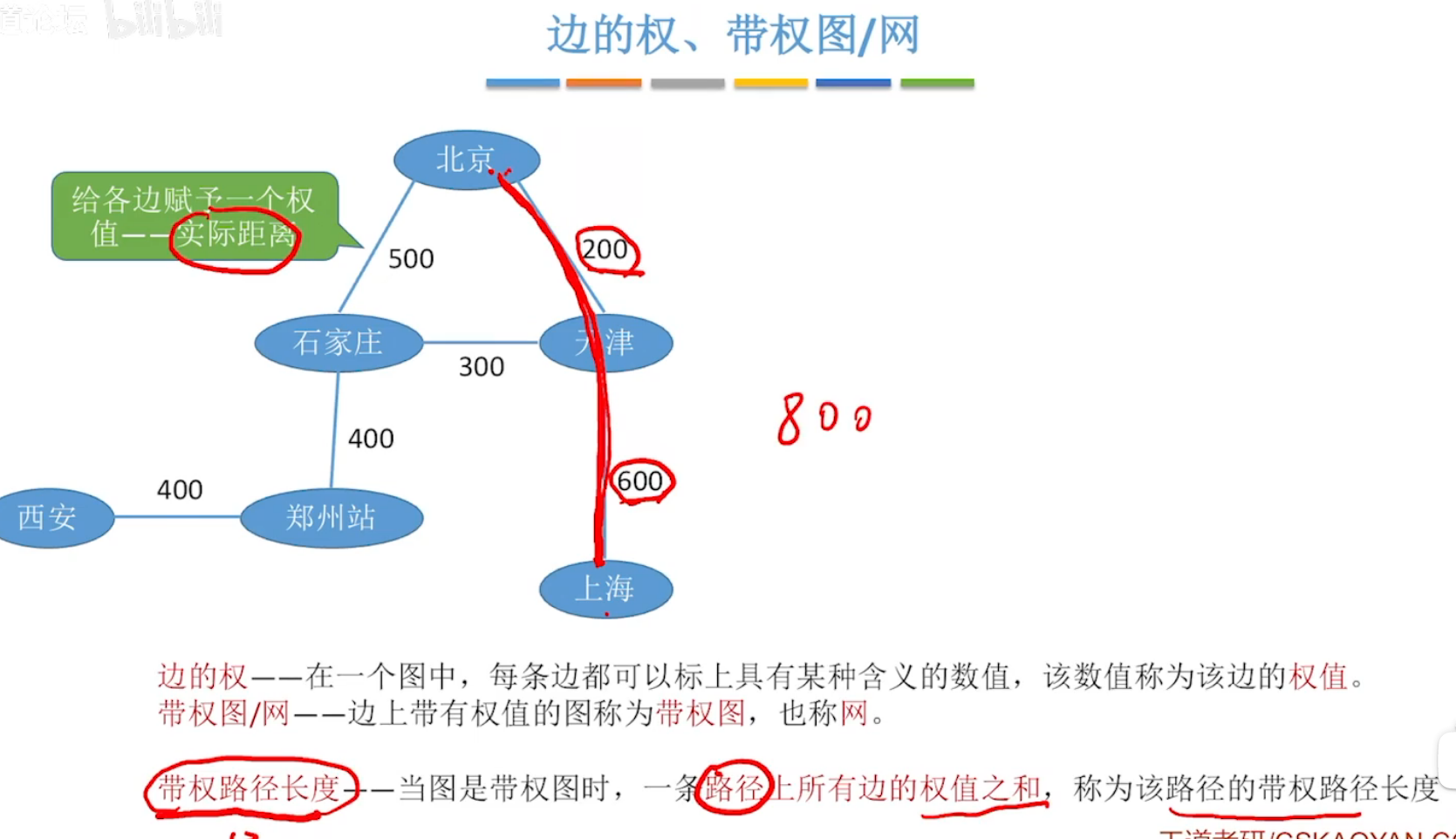
边的权、带权图/网、带权路径长度
无向完全图,有 C n 2 C_{n}^{2} Cn2个边
有向完全图,有2 C n 2 C_{n}^{2} Cn2边
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z6Pbs9Tn-1679123186441)(https://gitee.com/cht1/Image/raw/master/image-20230310130504883.png)]
2、图的存储
- 邻接矩阵
- 邻接表
- 十字链表
- 邻接多重表
(1)邻接矩阵法
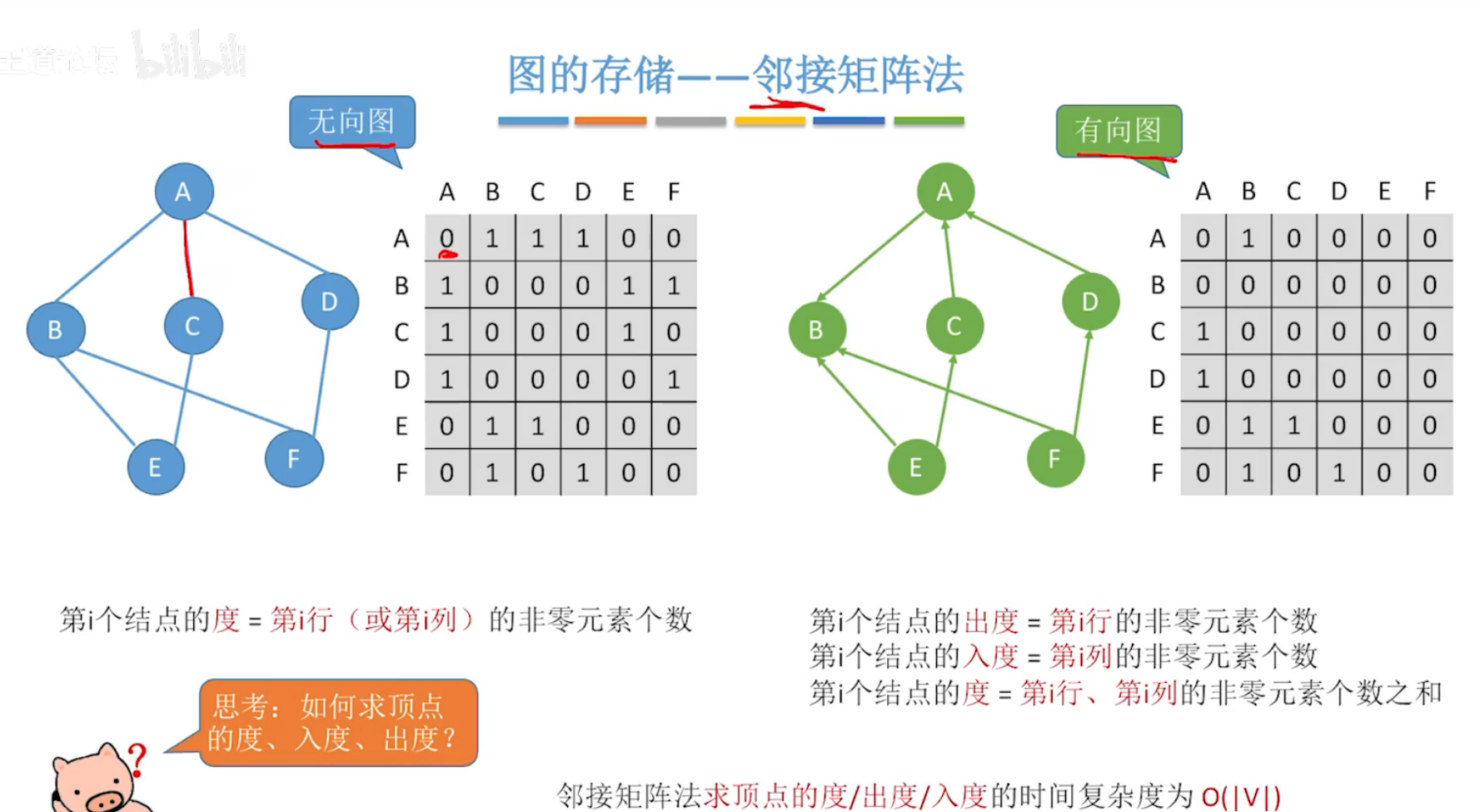
无向图:存储的邻接矩阵为对称矩阵。
有向图:矩阵(二维数组)a[i][j]为1,表示顶点i 到顶点j 是连通。
若为带权图,则用二维数组中的1 替换为权值。
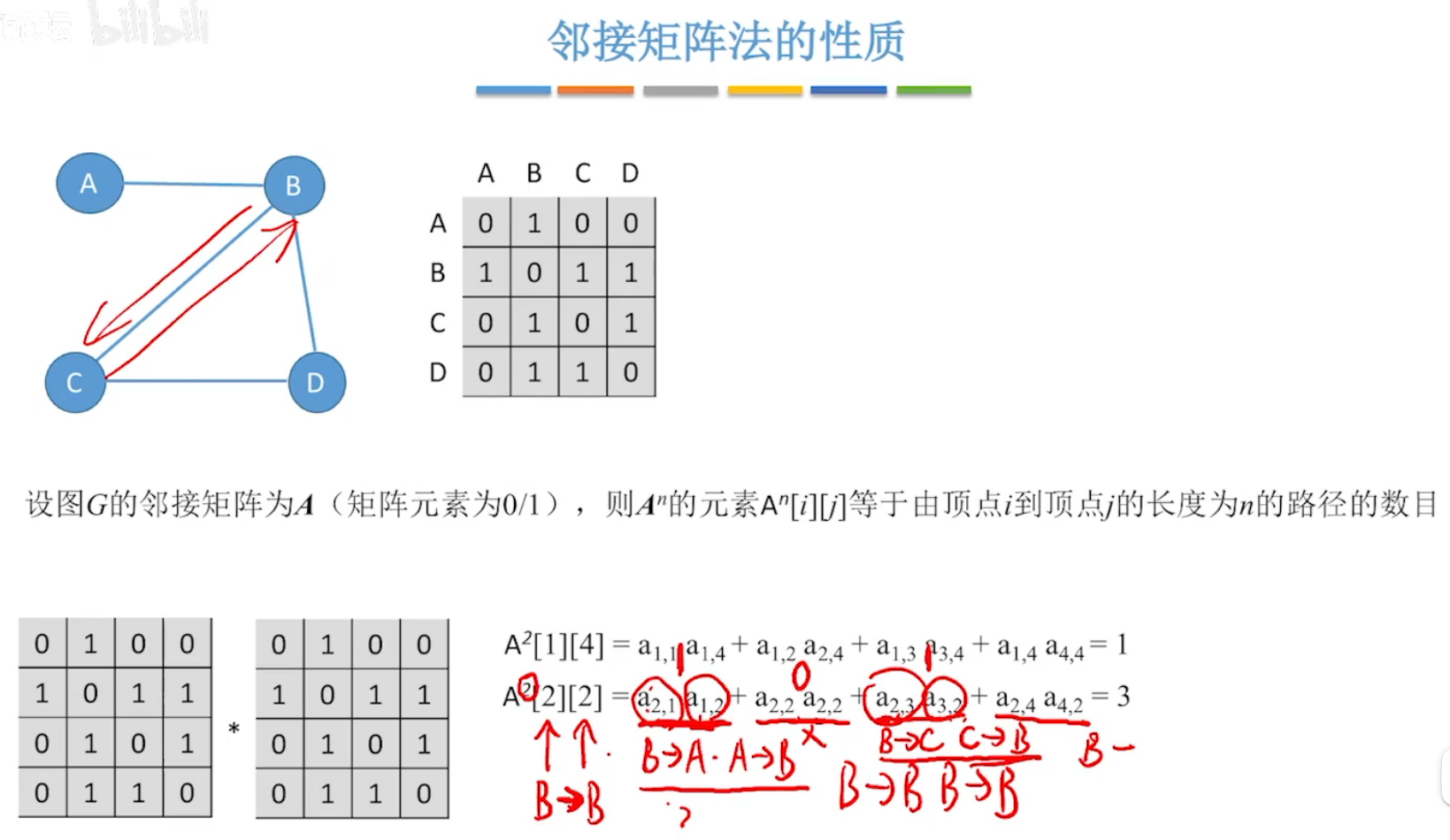
对于无向图,矩阵相乘,意义:an[i] [j]的值表示由顶点i到顶点j的长度为n的路径的数目。
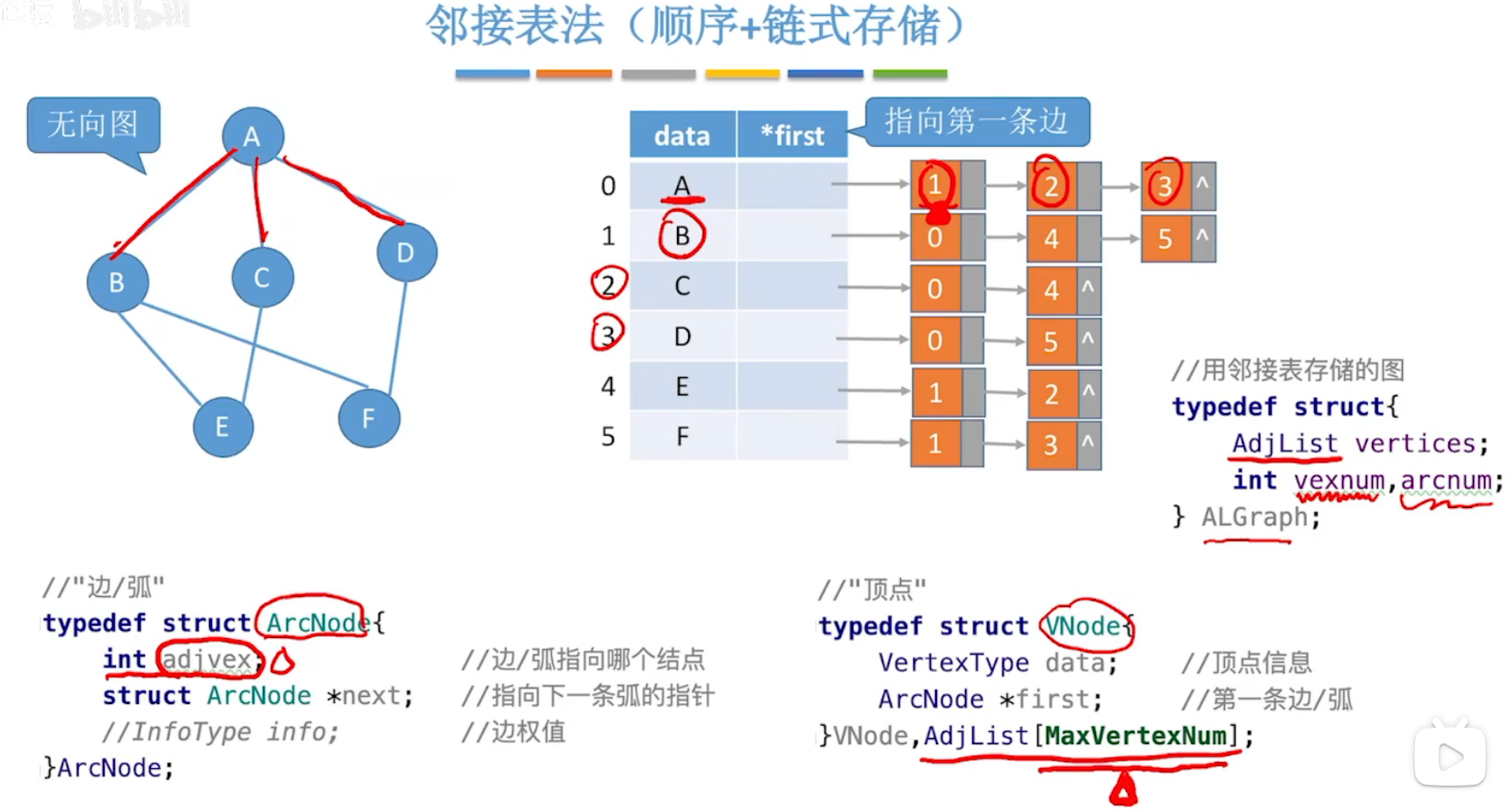
(2)邻接表
顺序存储+链式存储,例如:
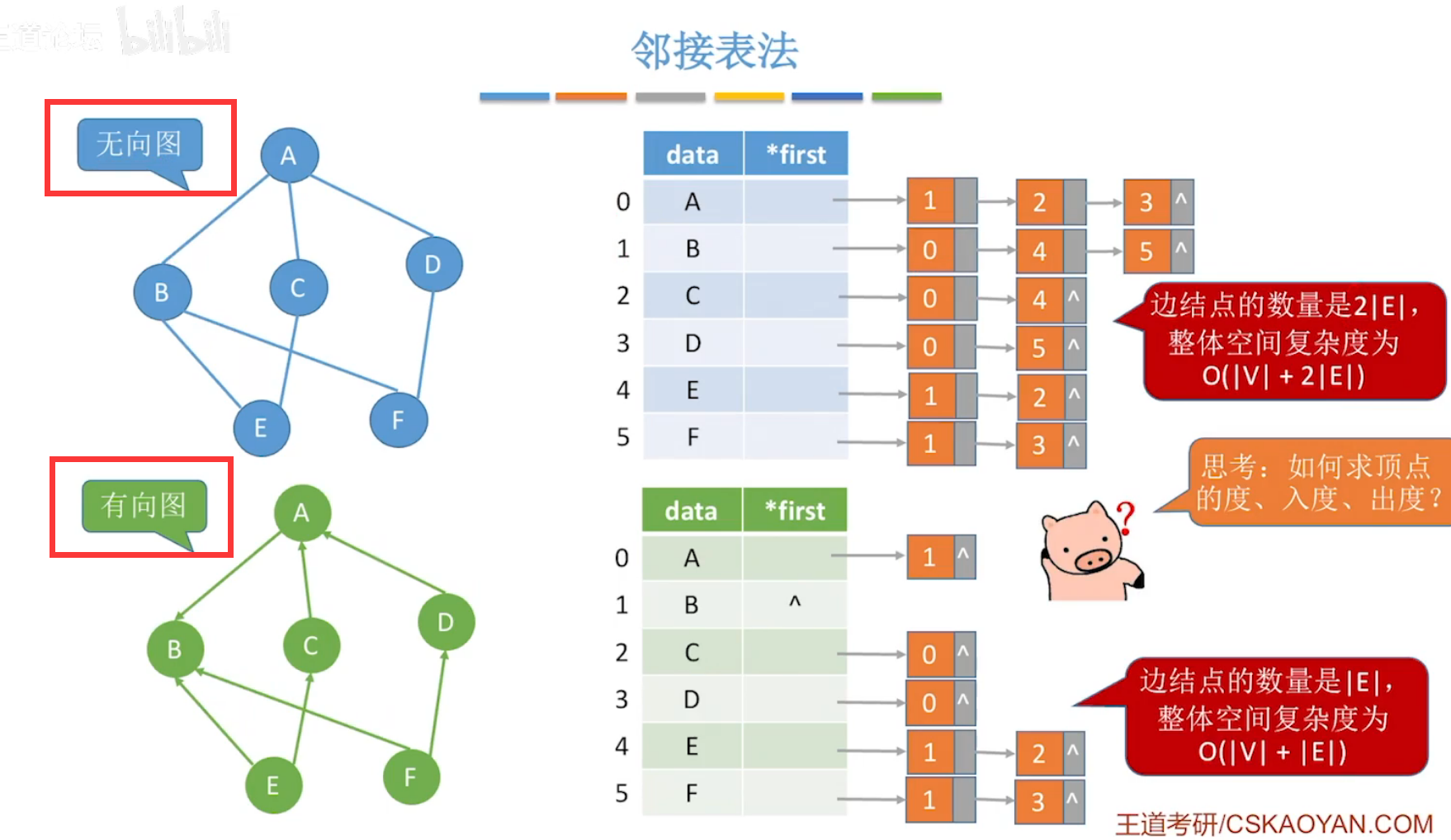
无向图:
- 边结点的数量,是实际结点数量的两倍。
- 无向图的度,只需要遍历边结点,有多少边结点,该结点就有多少度。
有向图:
- 边结点指针表示该结点的出度。
- 要机算某结点的入读,则要遍历所有结点的出度。
对于给定的图,其邻接矩阵唯一,但邻接表不唯一!
邻接表的代码表示:
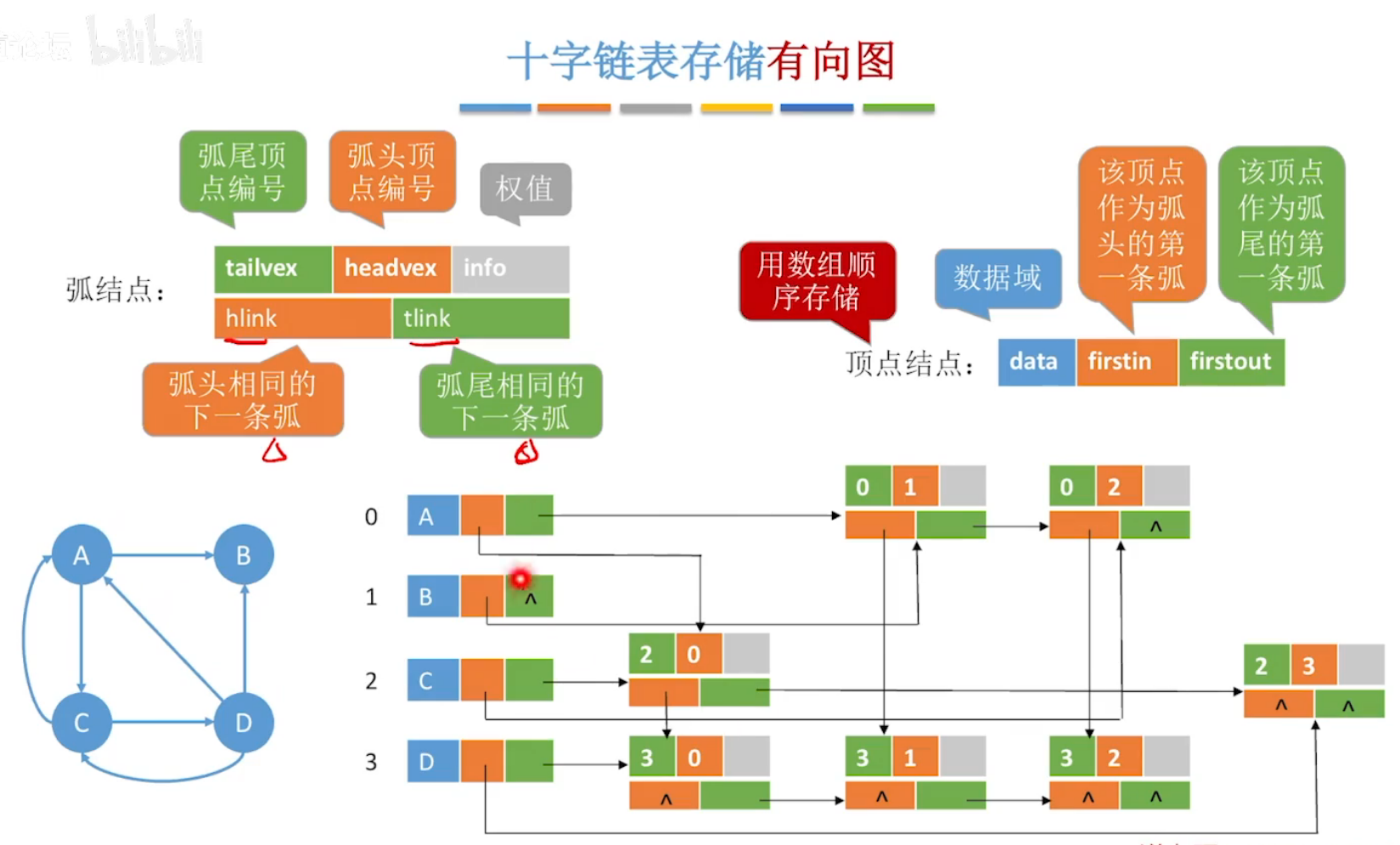
(3)十字链表:存储有向图
有向图
横着的一行为该行顶点的出度边,由绿色指针指向下一个。
竖着的一列为该列顶点的入度边,由黄色指针指向下一个。
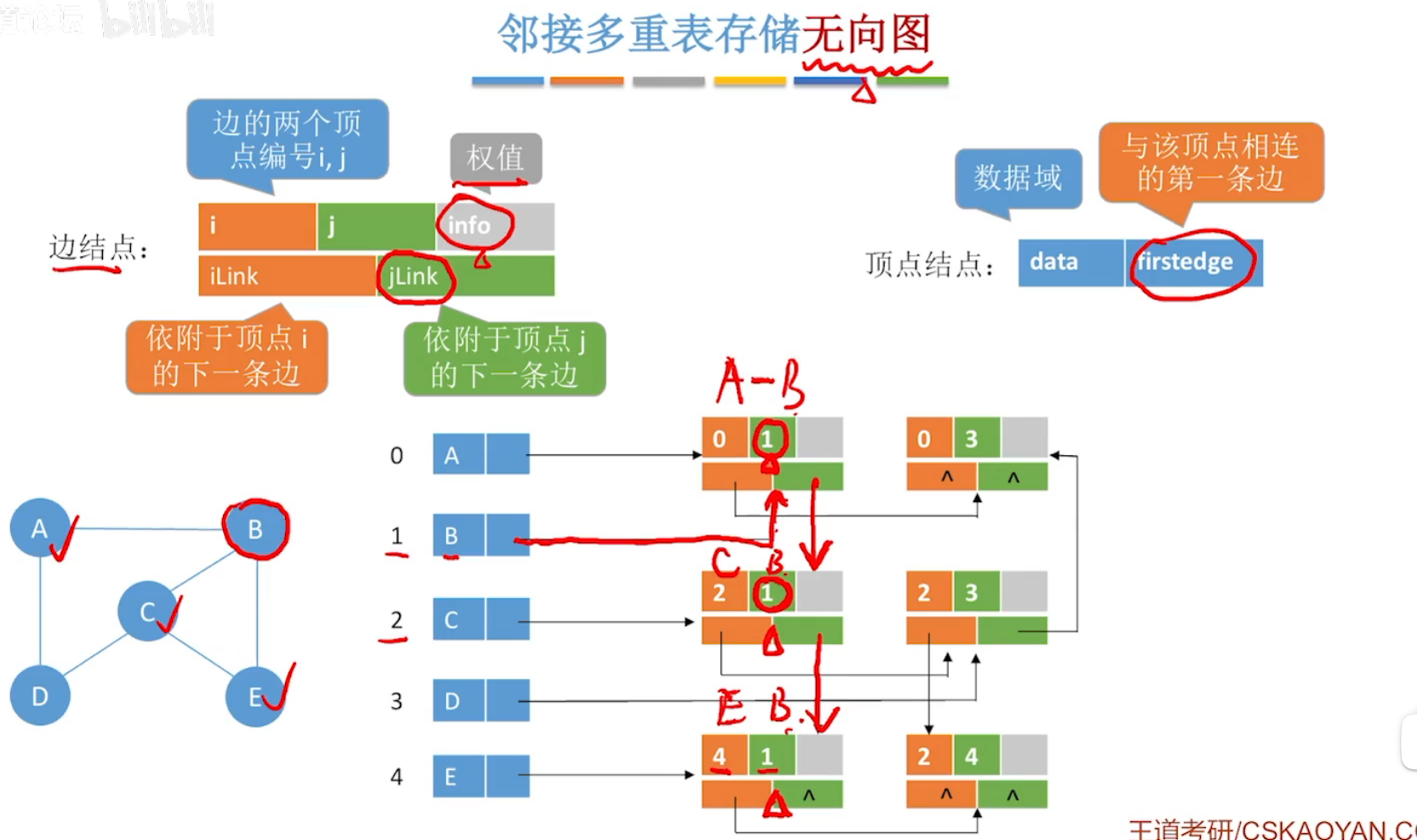
(4)邻接多重表:存储无向图
无向图,易于删除结点或边。
横着的一行,表示与该行顶点相连的边,由黄色指针指向下一个。
竖着的一列,表示与该列顶点相连的边,由绿色指针指向下一个。
3、图的基本操作
基于邻接矩阵和邻接表,所以重点还是熟记图的存储方式

4、图的遍历
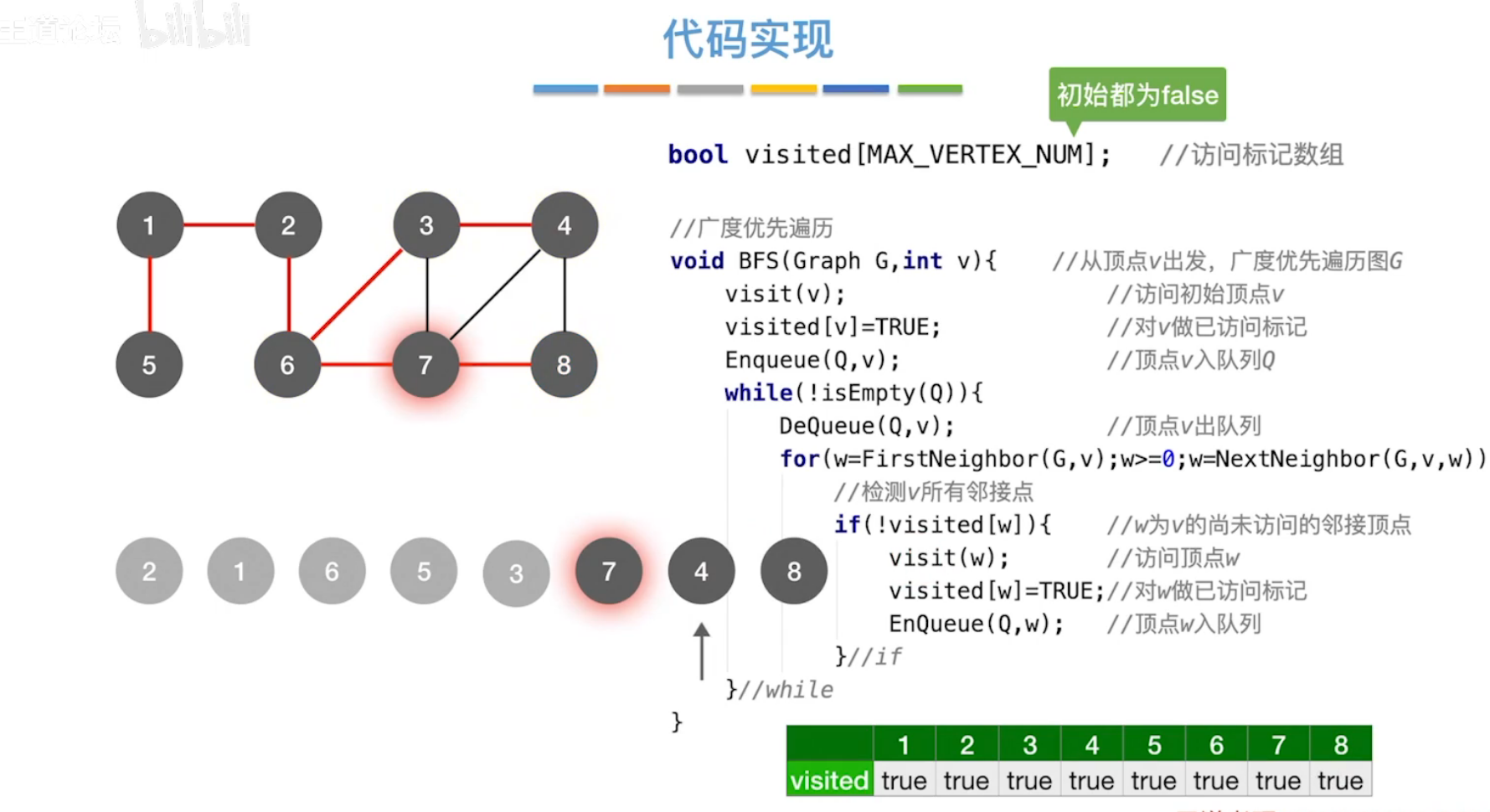
(1)广度优先遍历BFS
基于队列。
增加一个visied[N]数组,记录结点是否被访问过
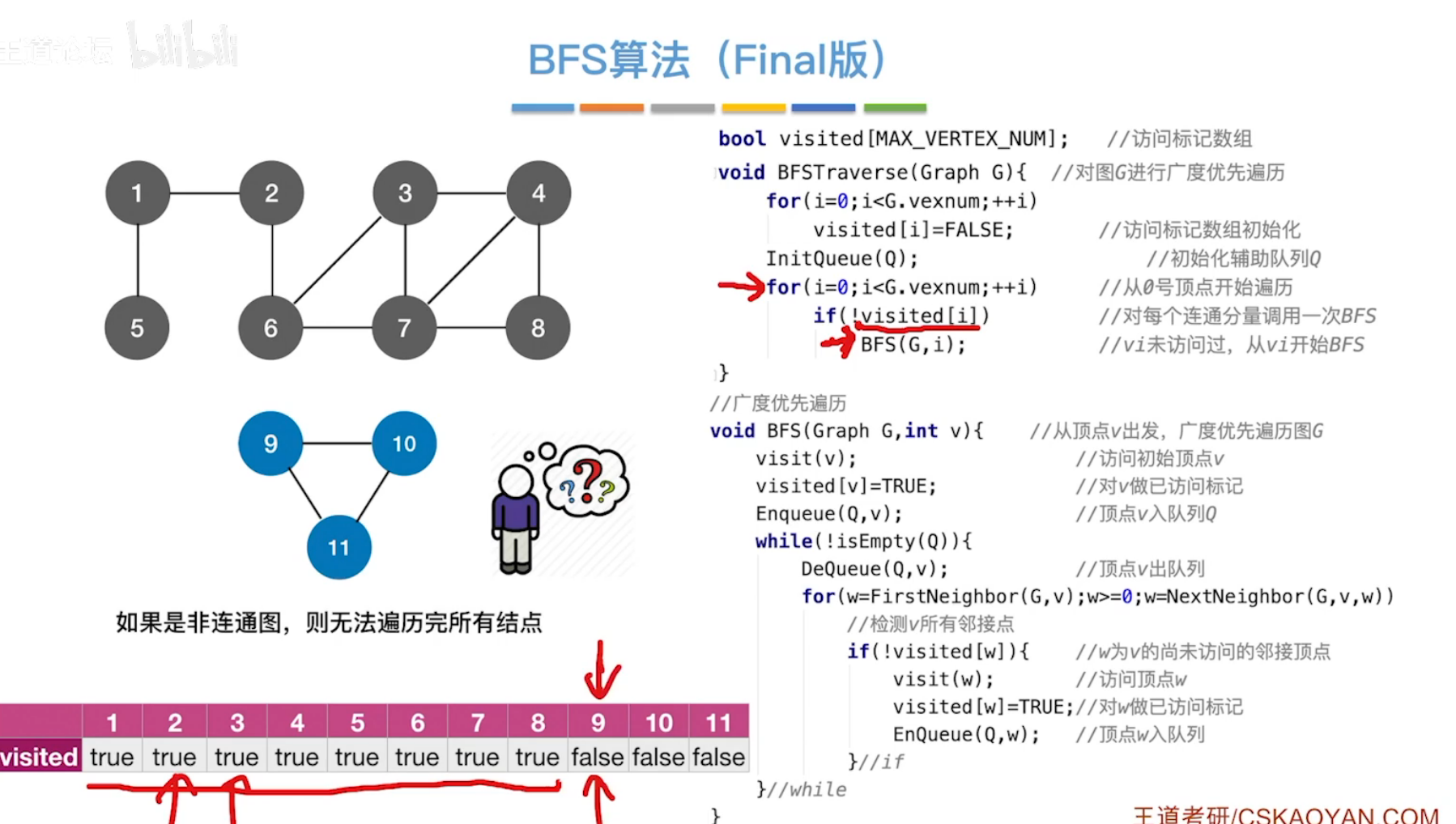
优化版:访问非连通图。
增加一个for循环,扫描未访问的结点数组,调用BFS。
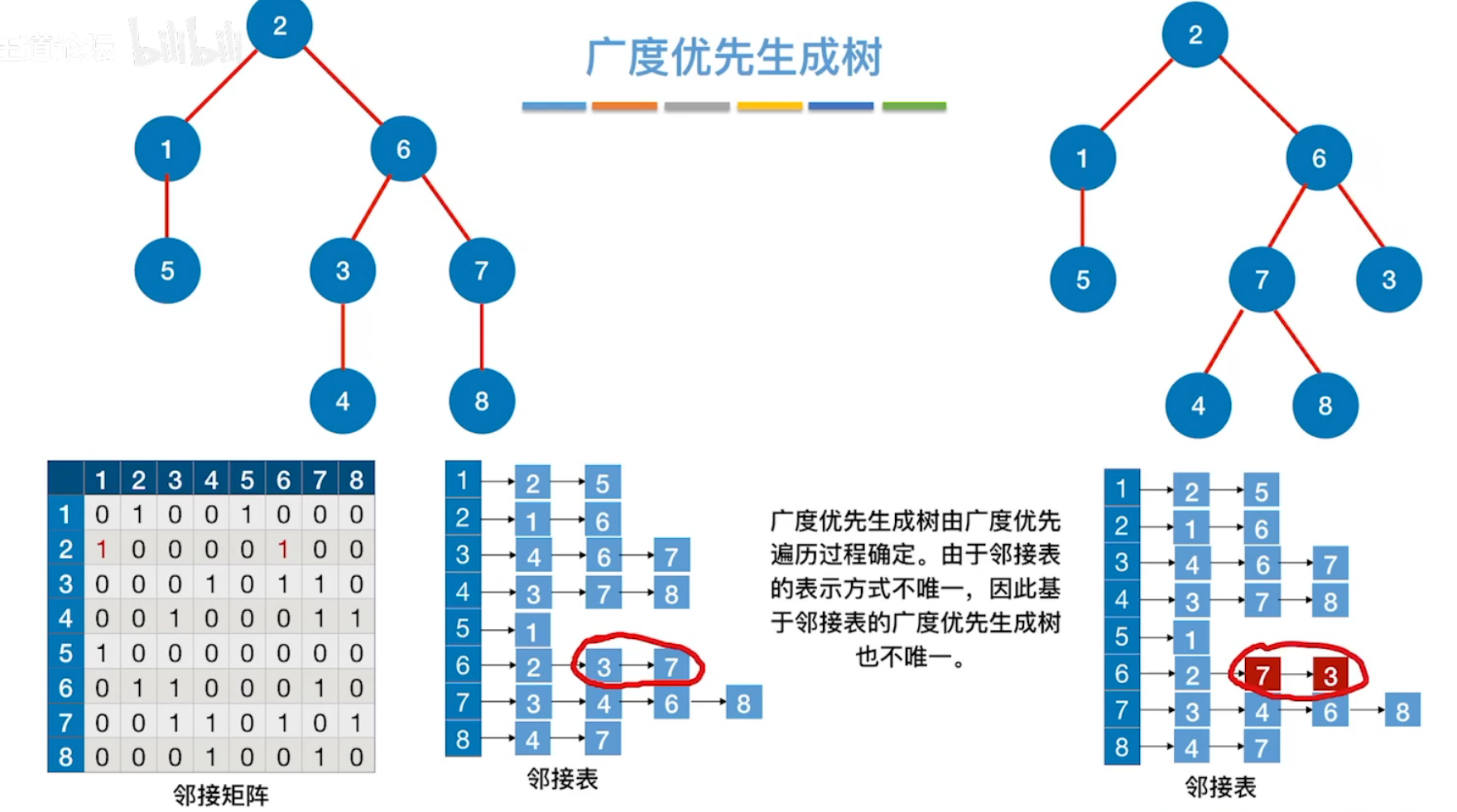
广度优先生成树:根据广度优先遍历过程依次访问的结点队列,生成的树。
注意左方邻接表,是3比7先入队列,故4是3的子结点,最后8是7的子结点。
因为邻接表不唯一,故其广度优先生成树不唯一;
而邻接矩阵唯一,故其对应的广度优先生成树唯一。
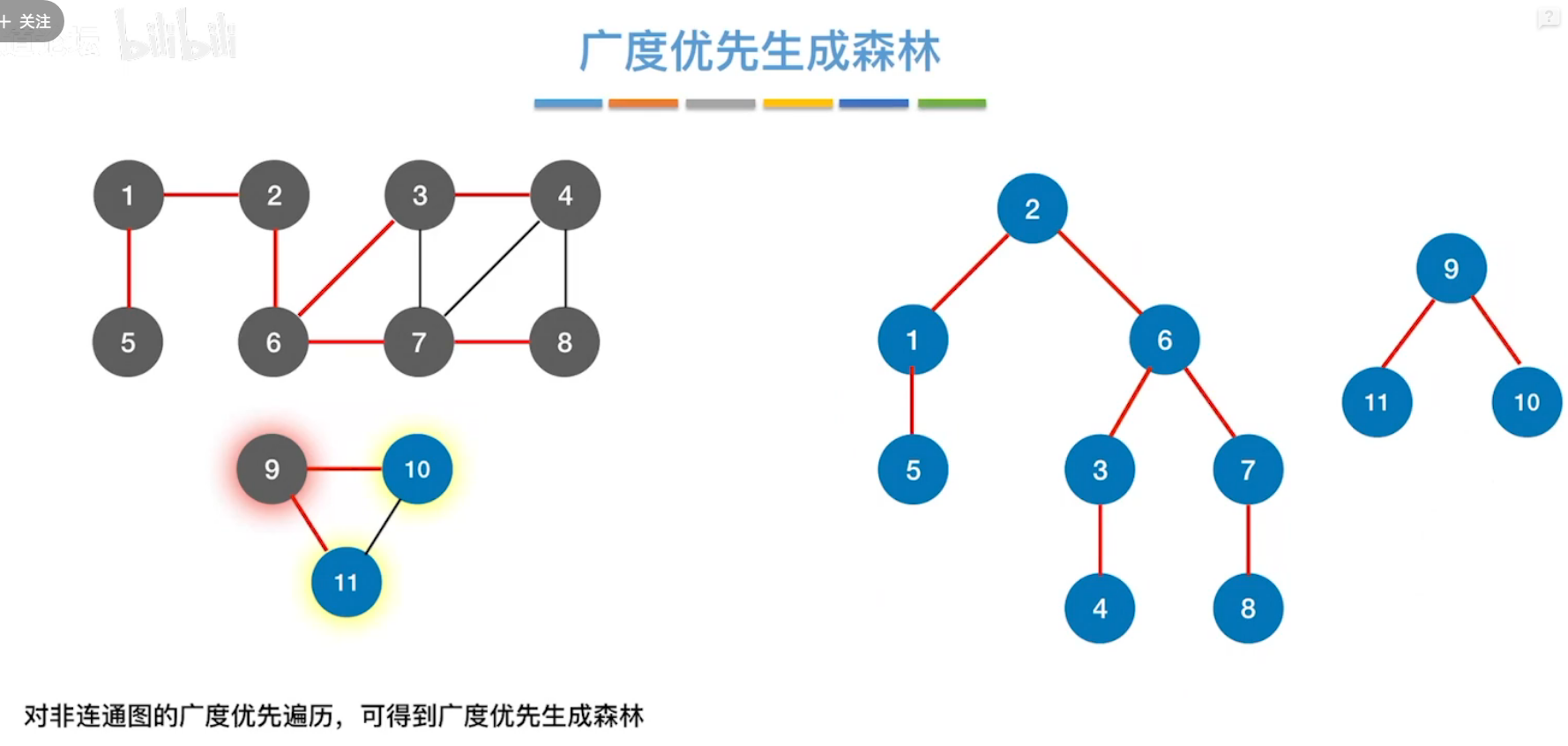
对应的,遍历非连通图,有广度优先生成森林
(2)深度优先遍历DFS
类似于树的先根遍历。
求深度优先遍历序列
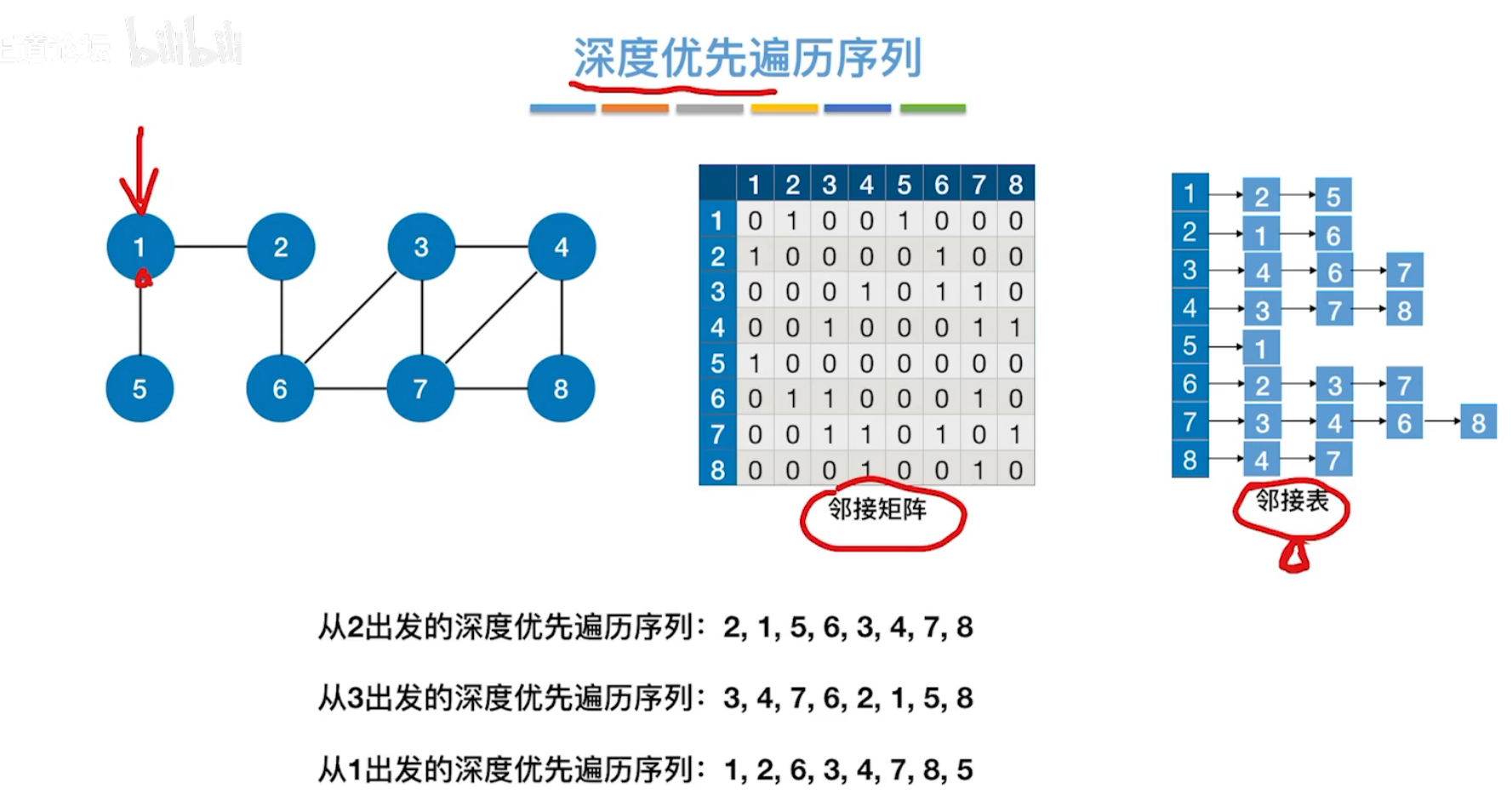
同样,邻接表不同,生成的深度优先序列也不同。
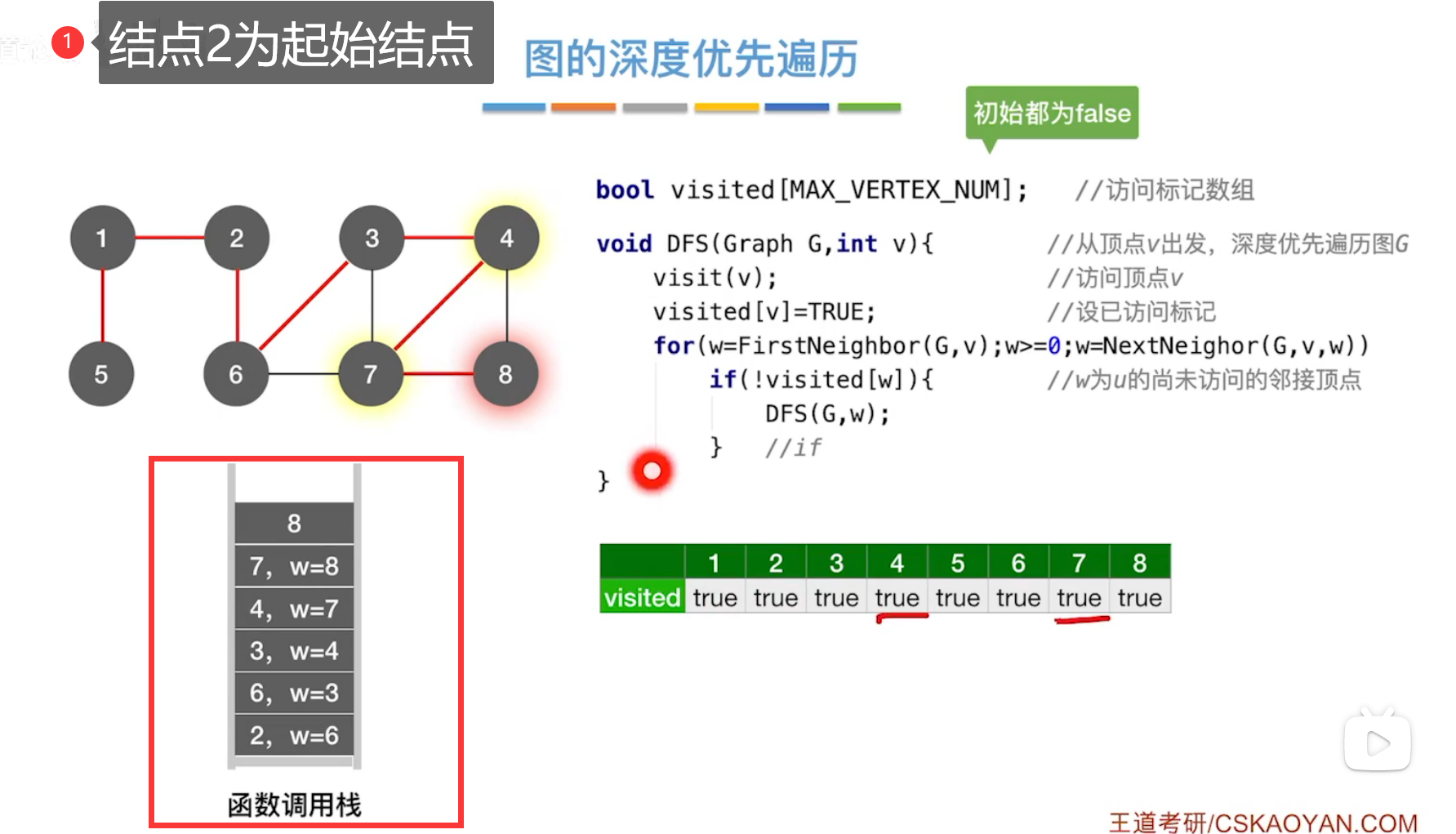
也有深度优先生成树、深度优先生成森林。
5、最小生成树MST
最小生成树:带权连通图中,求各边权值之和最小的生成树。
(1)Prim普里姆算法
前提:两个结点之前不能出现回路。
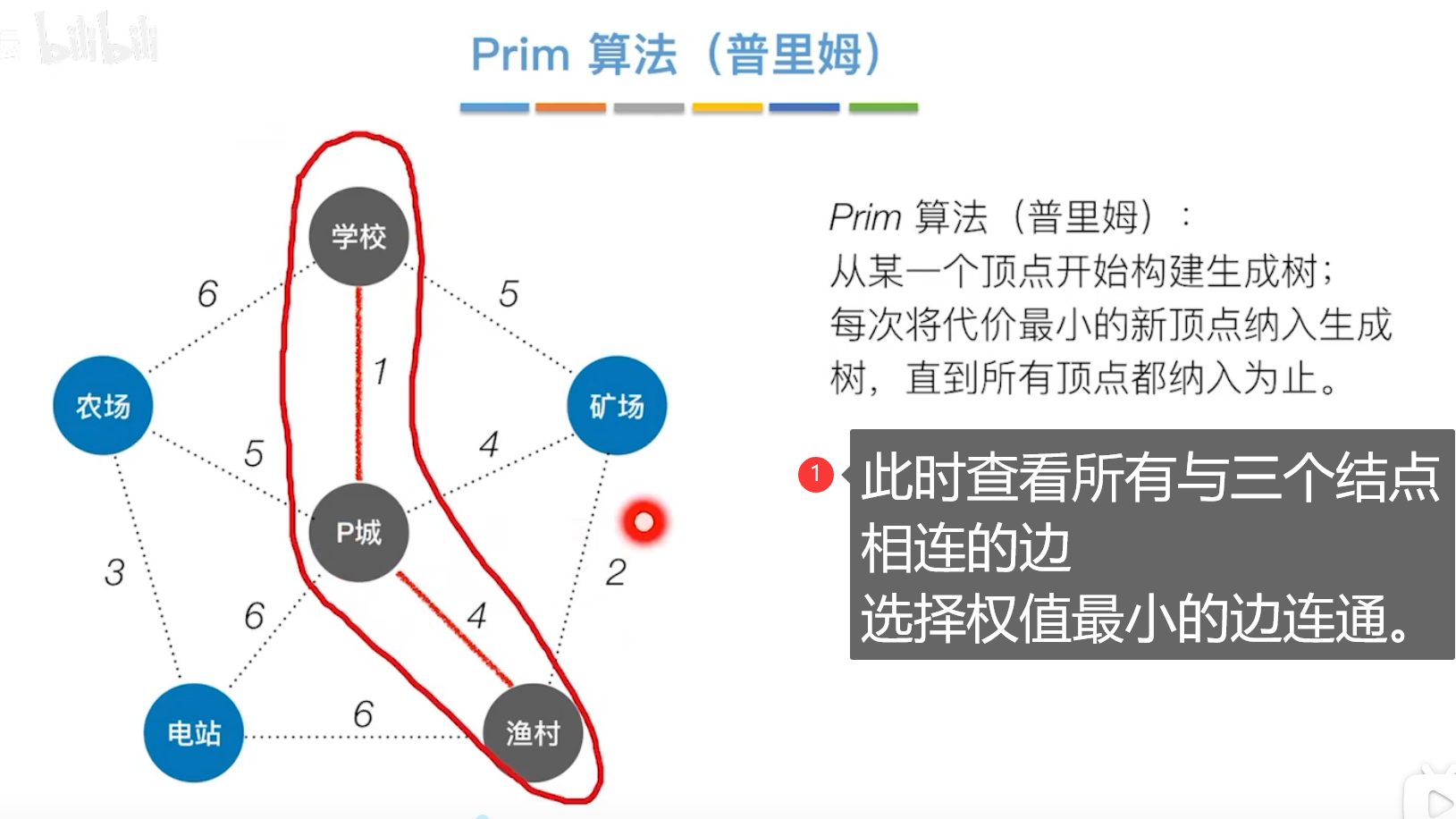
注意每次选新顶点时,是选择当前已经连通的结点的所有相连边。
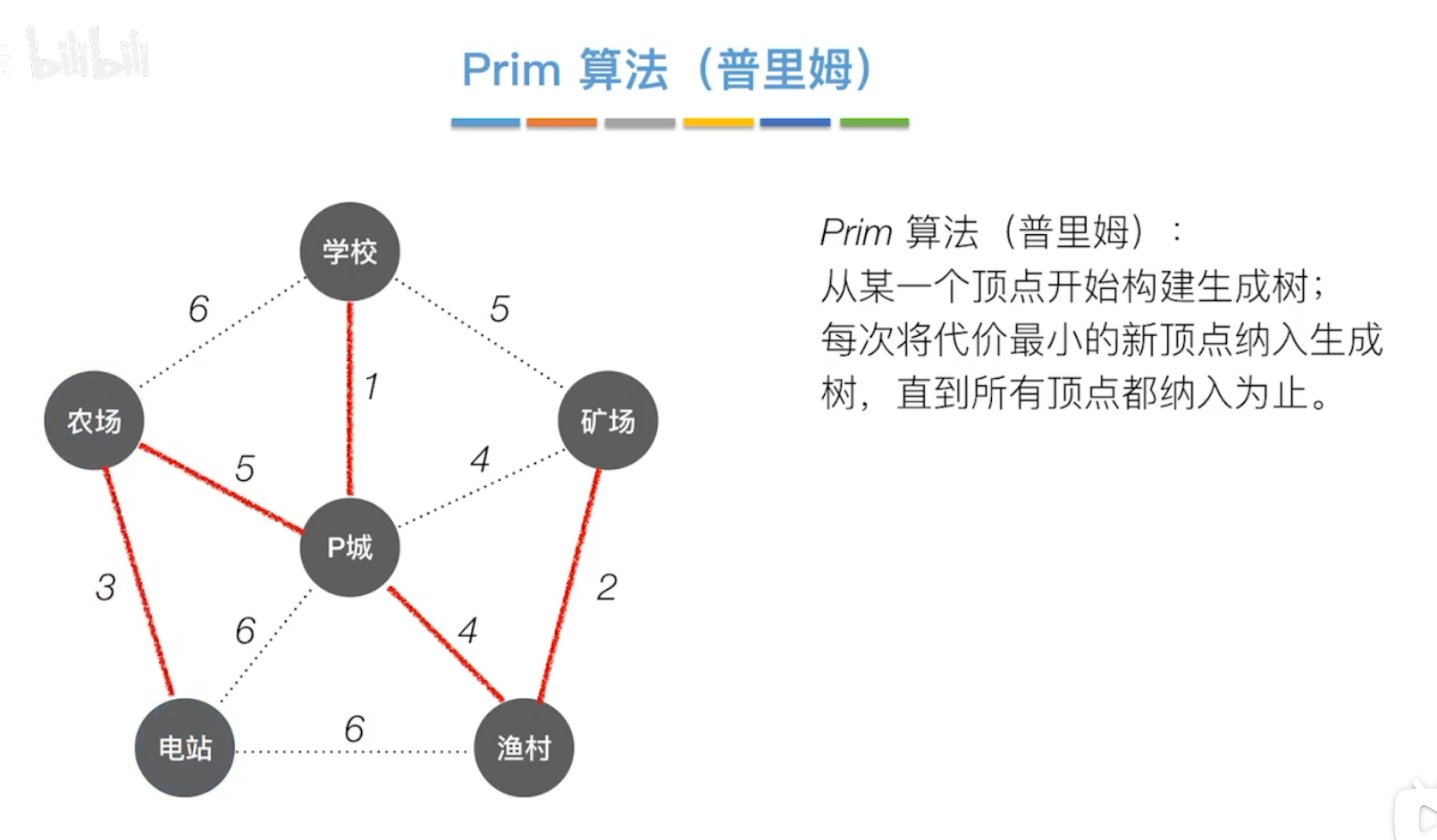
(2)Kruskal克鲁斯卡尔算法
每次选择一条权值最小的边,
如果一条边两头的结点已经连通,则不选。
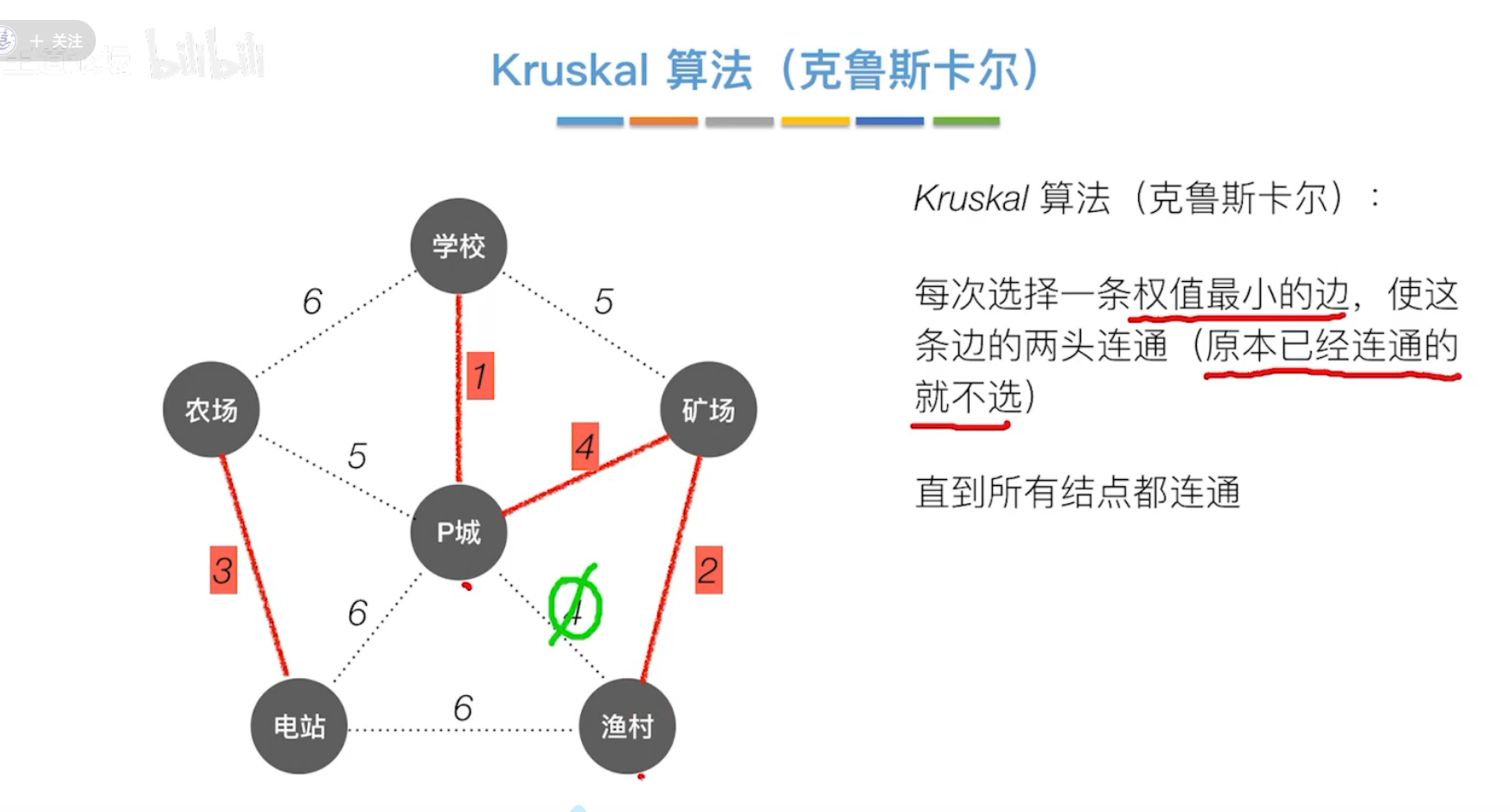
(3)二者差别

6、最短路径问题
(1)DFS算法
DFS算法代码:
数组d[]记录从起始顶点到各个结点的距离。
数组path[]记录到各个结点路径中的“直接前驱”。
数组visited[]记录该结点是否访问。
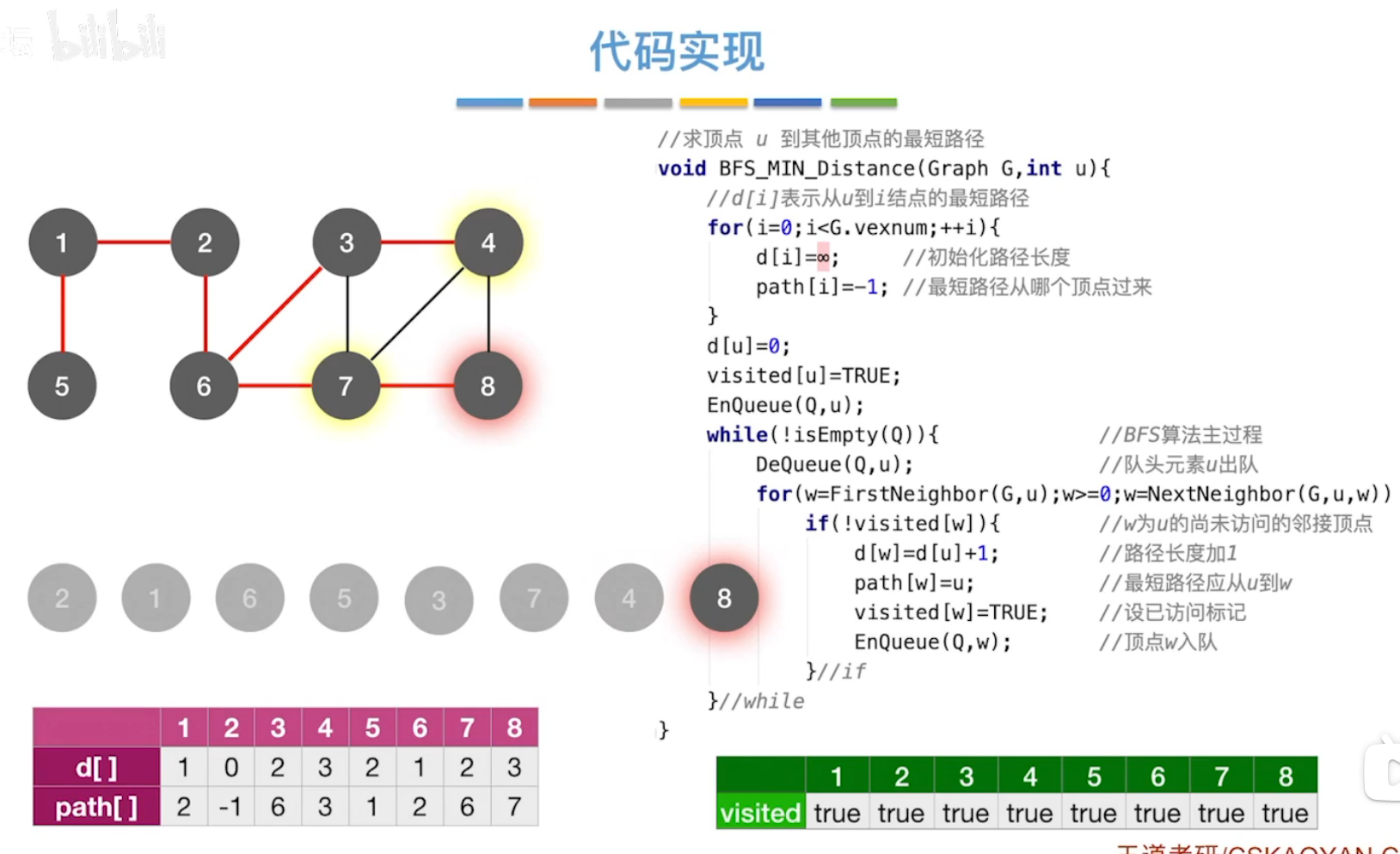
DFS不是和带权图的最短路径问题。(只适合无权图)
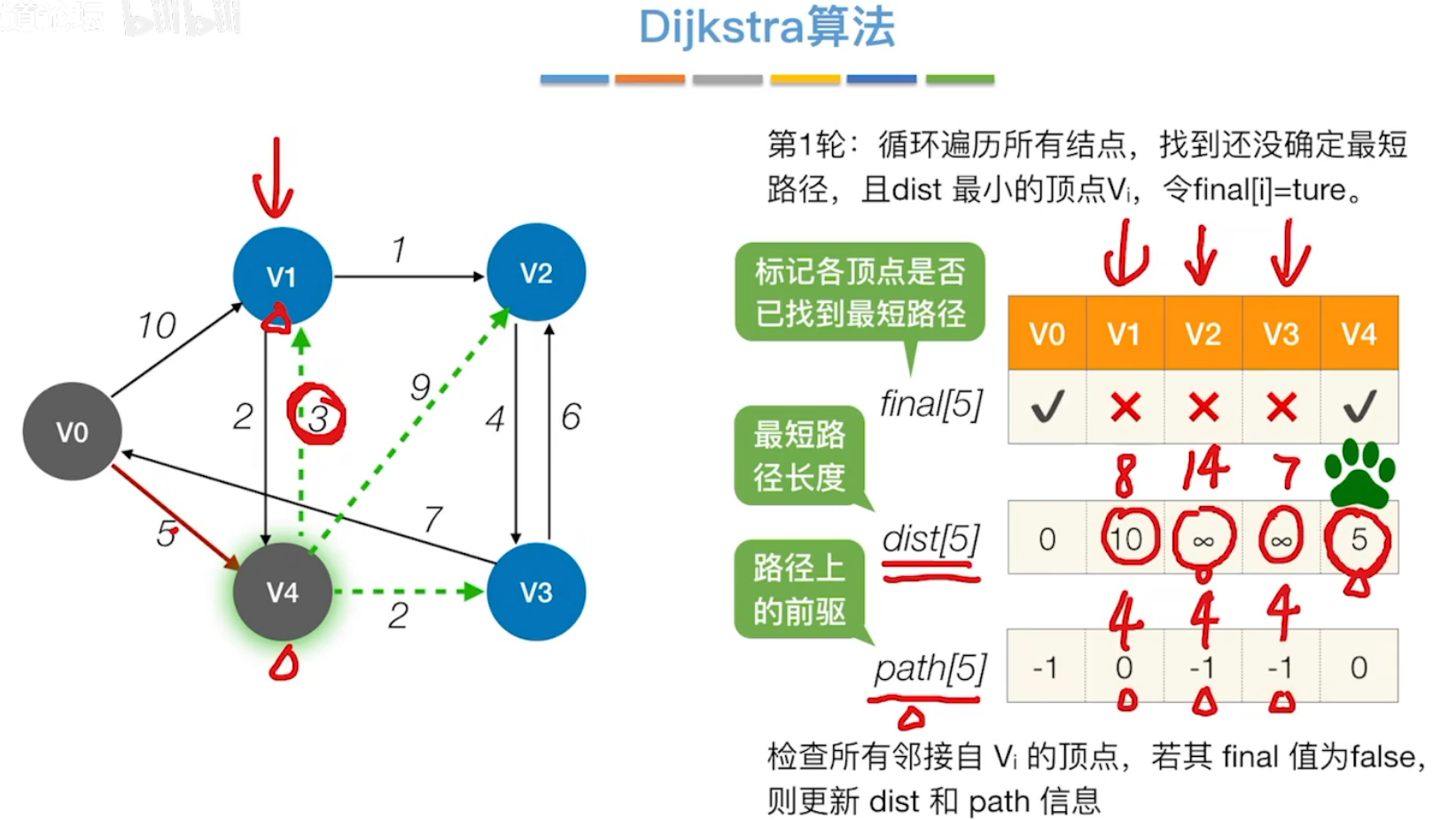
(2)Dijkstra算法(迪杰斯特拉算法)
Dijkstra算法可以用于带权图的最短路径问题,但是不适合有负权值的带权图。
算法手算过程:
初始化以下三个数组:
- final数组中,起始结点的值为true,其余为false。
- dist数组中记录从起始结点到各个结点的路径长度
- path数字记录从起始结点到该结点的路径上,该结点的直接前驱。
**第一轮:**循环遍历所有结点,找到还没确定最短路径,且dist最小的顶点V4。
再检查所有临界V4的顶点,若其final值为false,则更新dist和path信息。
更新:即重新计算起始结点经过V4再到达其余结点的距离,若小于dist中记录的值,则更新其dist值,同时更新path数组中记录的直接前驱。
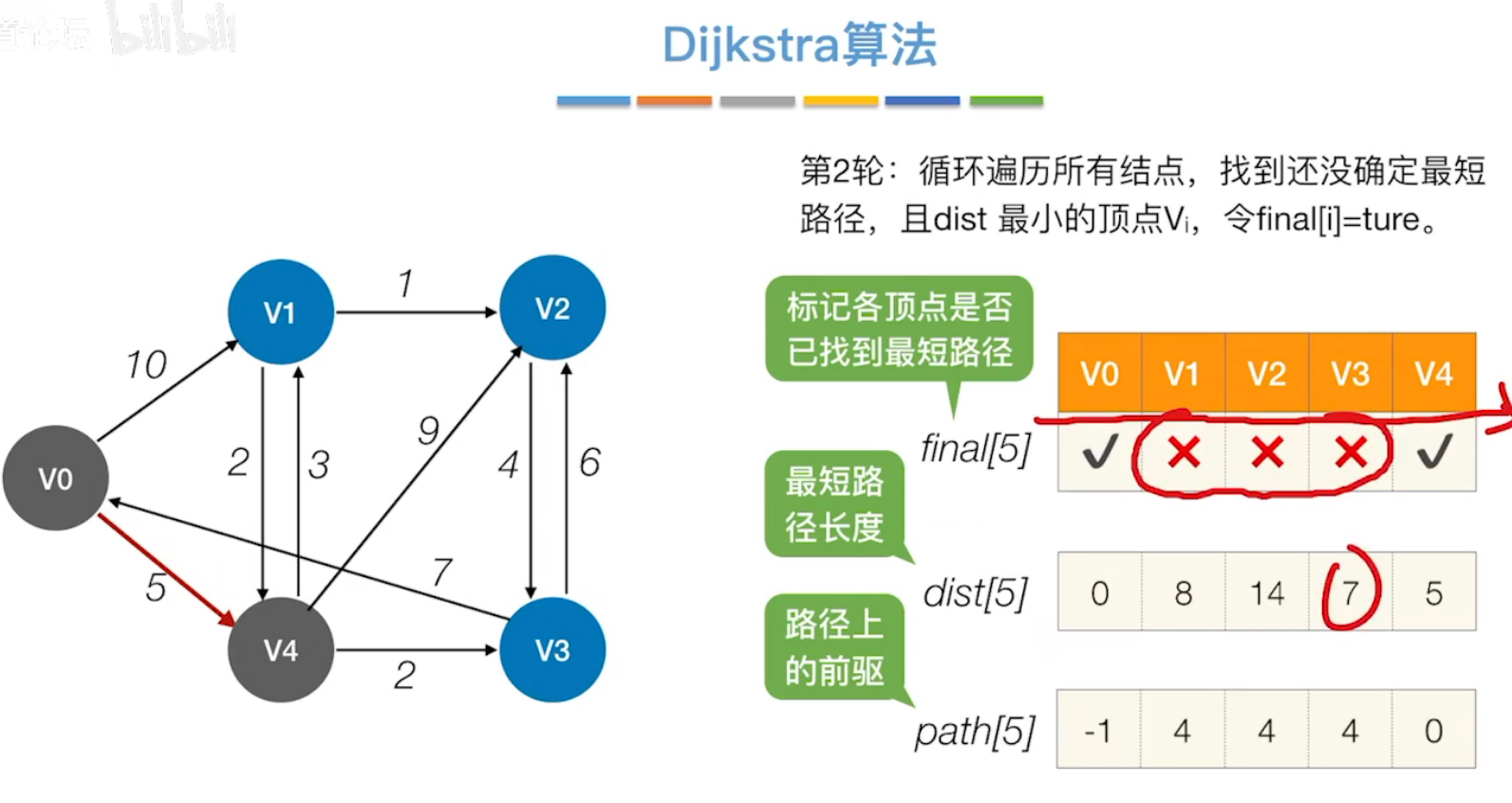
**第二轮:**在第一轮的基础上,循环遍历所有结点,找到还没确定最短路径,且dist最小的顶点Vi(这里为V3,其dist值为7),先令V3的final值为true,再从v3出发,执行第一轮中的检查+更新操作。
后序每轮操作与第二轮相同,不断检查、更新。
最终结果为:
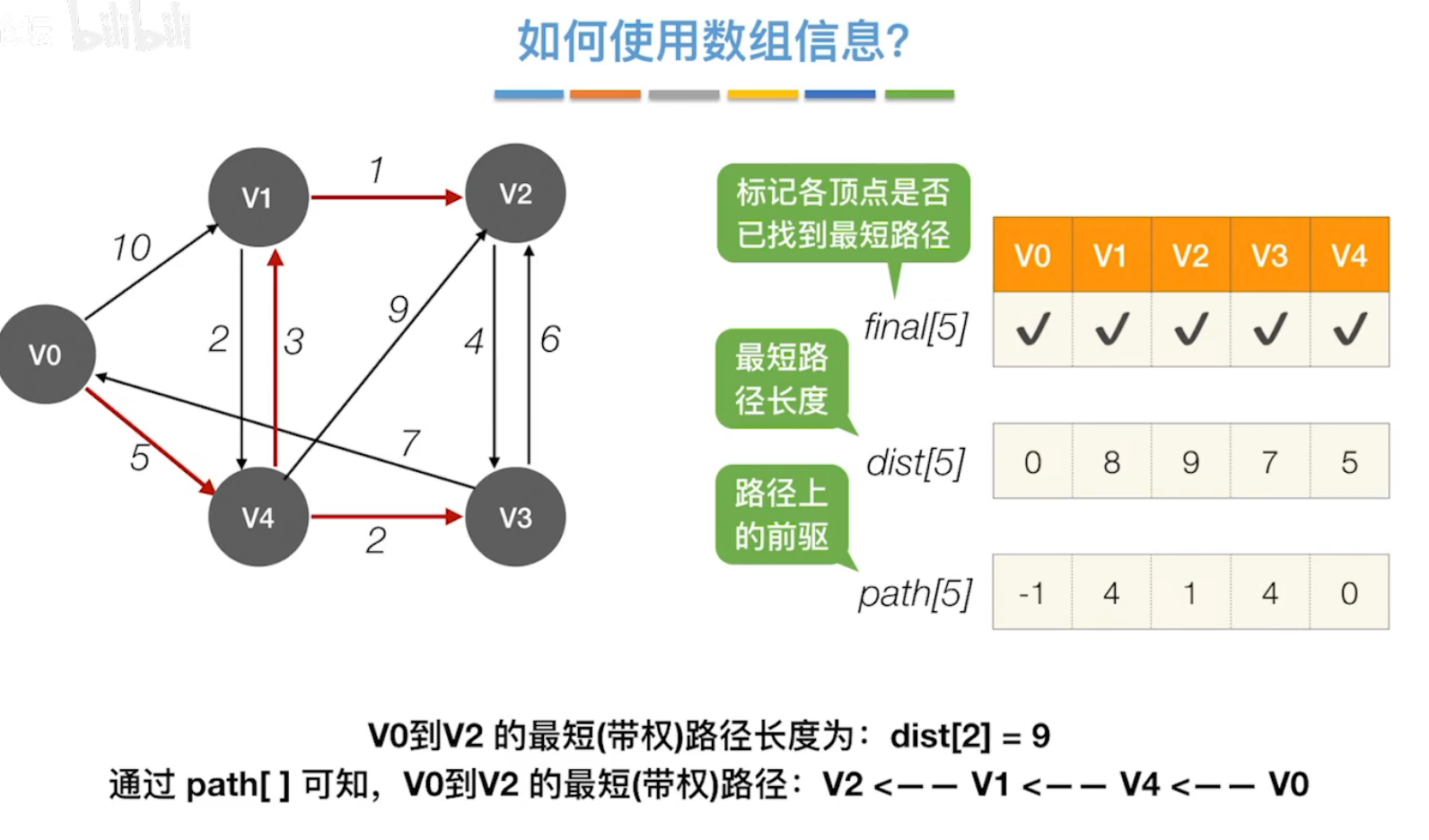
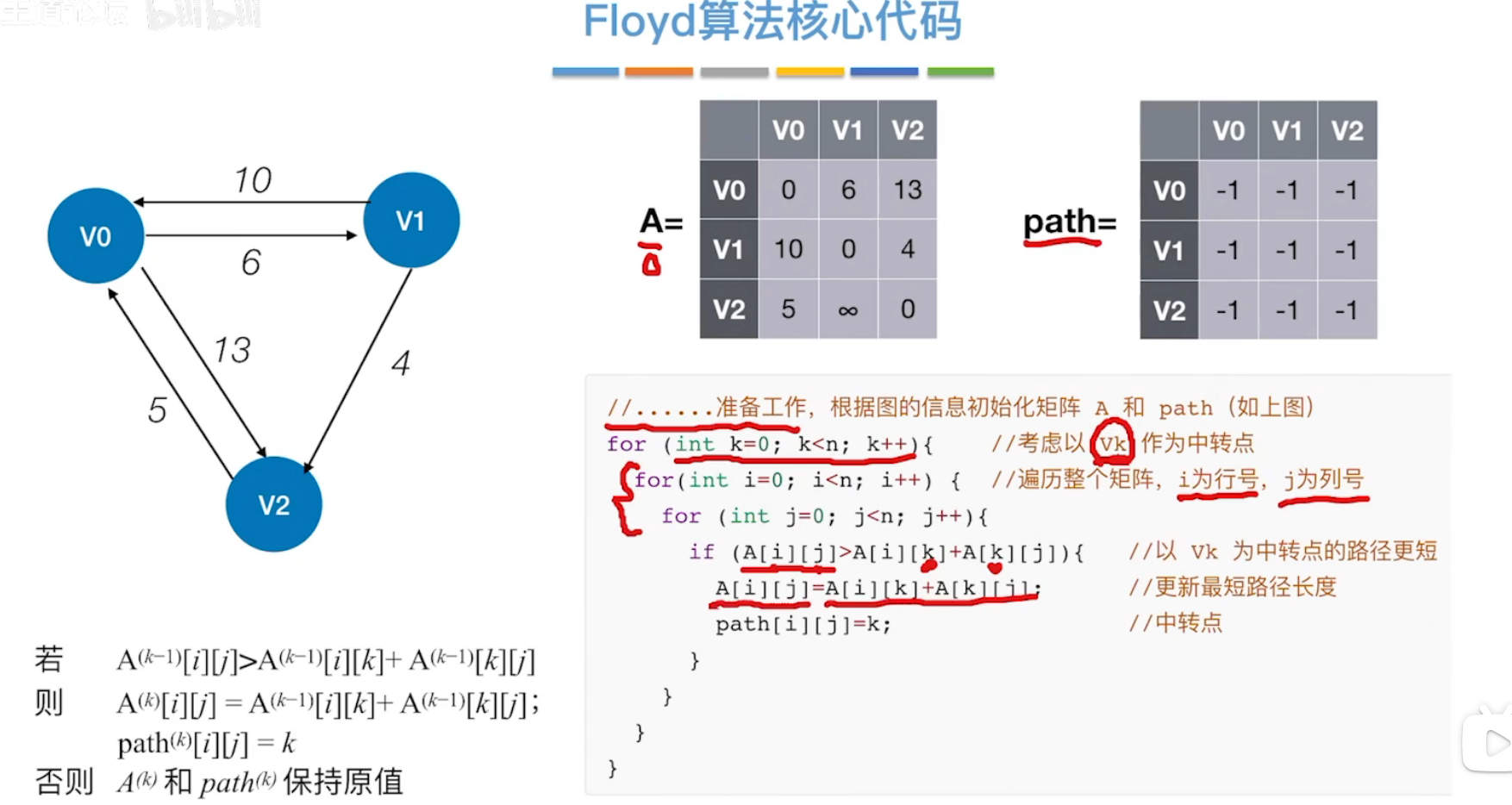
(3)Floyd算法

利用两个数组,表示路径的临界矩阵表A[],表示含中转点的中转点记录表path[]
核心代码如下:
- 第一个for循环,表示以k结点为中转点,后两个循环表示依次遍历
i行j列的位置,接着if语句中,A[i][k]+A[k][j]表示结点i以结点k作为中转点到达结点j的距离。
每轮只选择一个点作为中专点,但实际上经过多轮更新下来,就已经考虑了经过多个中转点的情况。
如下图,以v2作为中转点计算v0到v3时,实际的结果为,v0 到v2,v2又以v1为中转点,最后才是v1到达v3。
表面上时v0 -> v2 -> v3 ,实际上时v0 -> v2 -> v1 -> v3
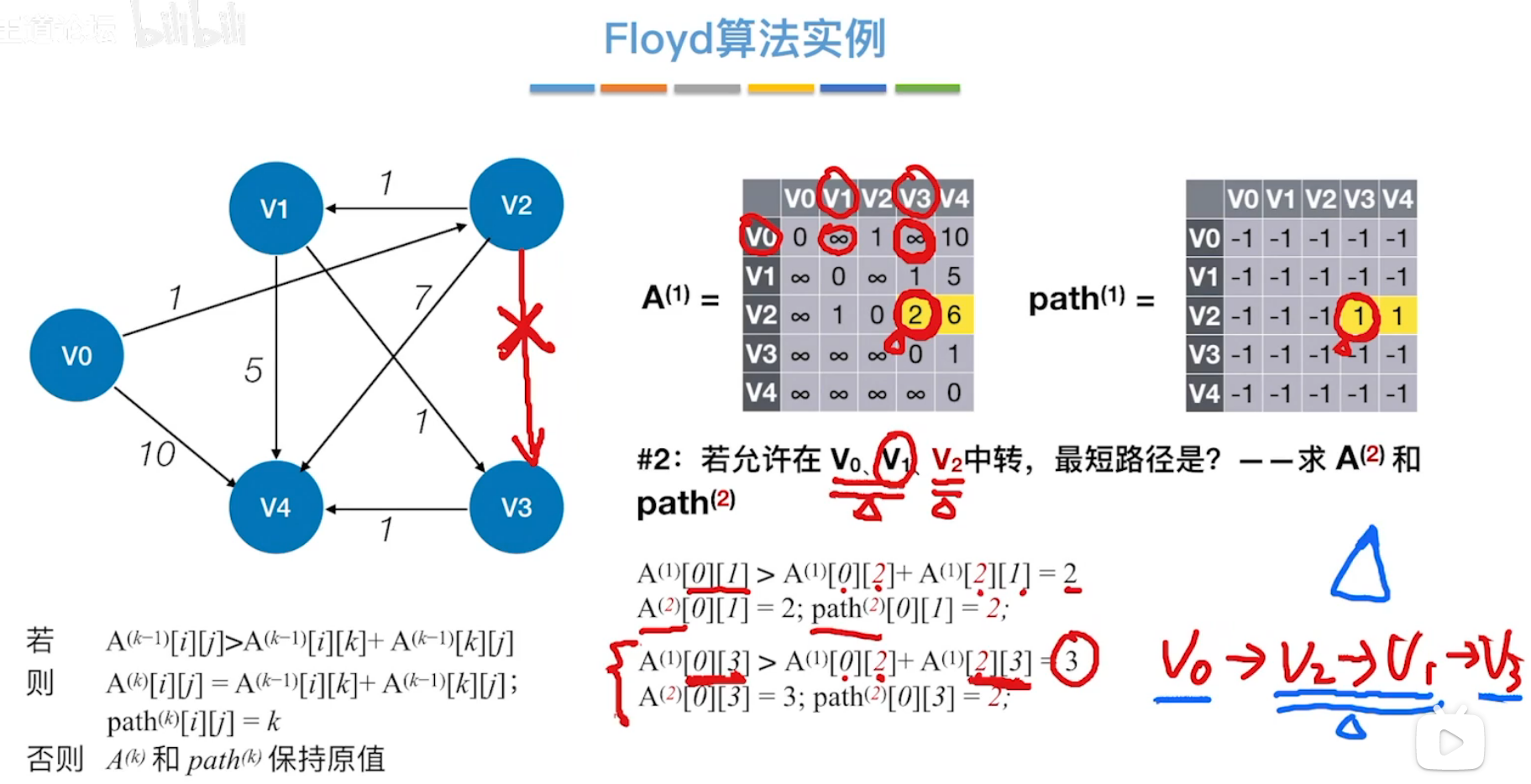
**Floyd特点:**能解决带负权值的图,但不能解决带”负权回路“的图。
7、有向无环图
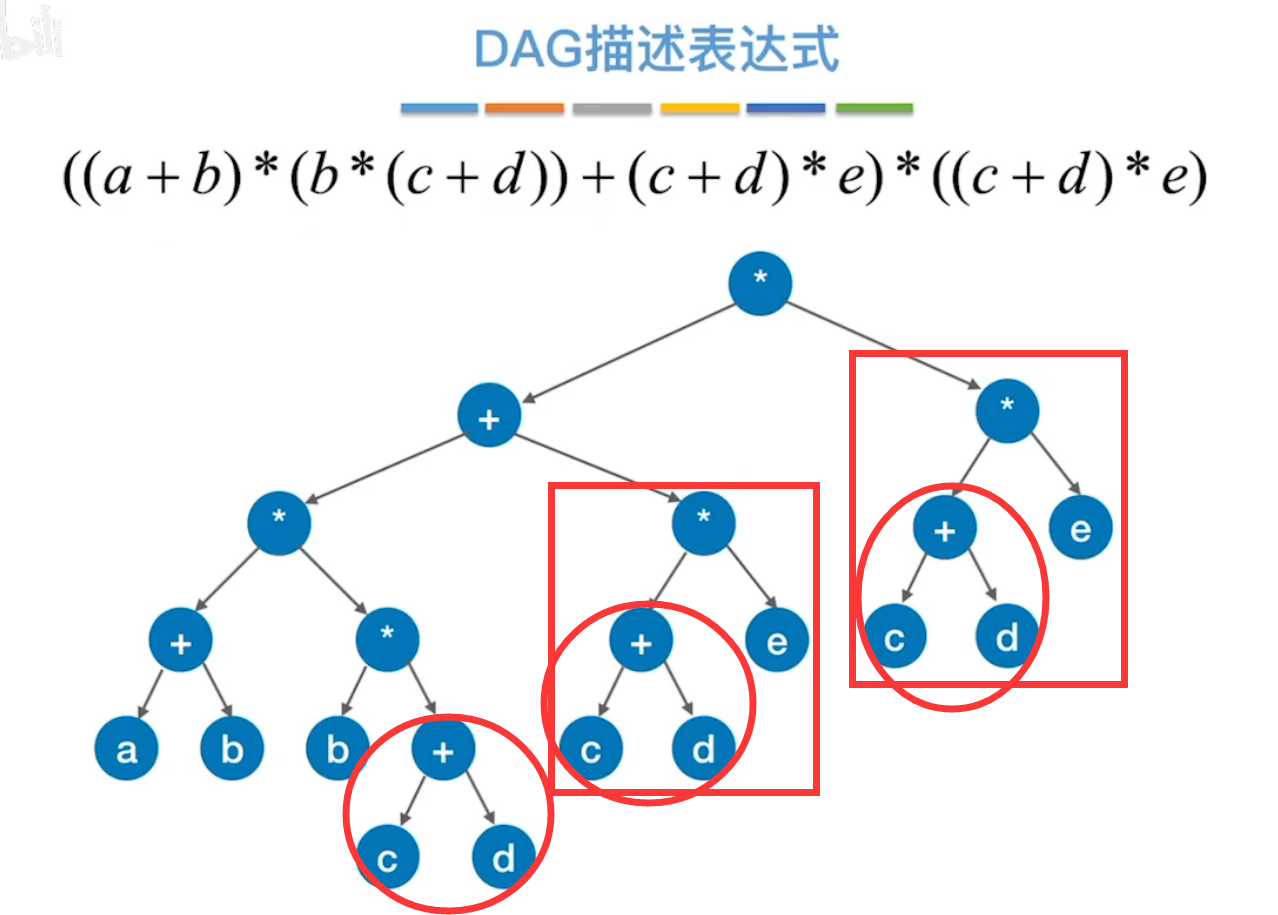
(1) 有向无环图 描述表达式
考点:用树来表述算数表达式,存在重复结点,浪费空间,删去重复结点,使不同的父节点指向相同的子结点,利于节省空间,形成有向无环图。
例如:
用树来表示算术表达式,标匡的表示重复结点。
优化之后:
用有向无环图表述算数表达式。
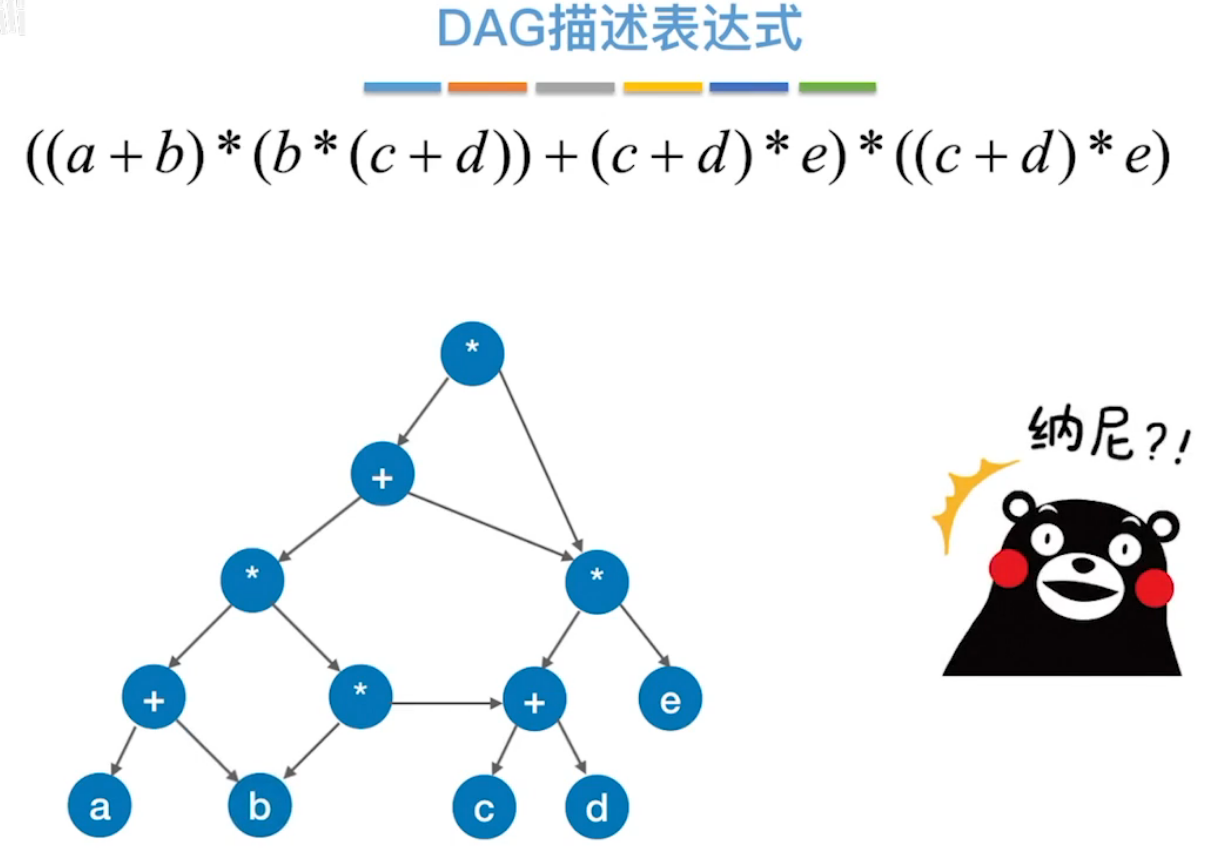
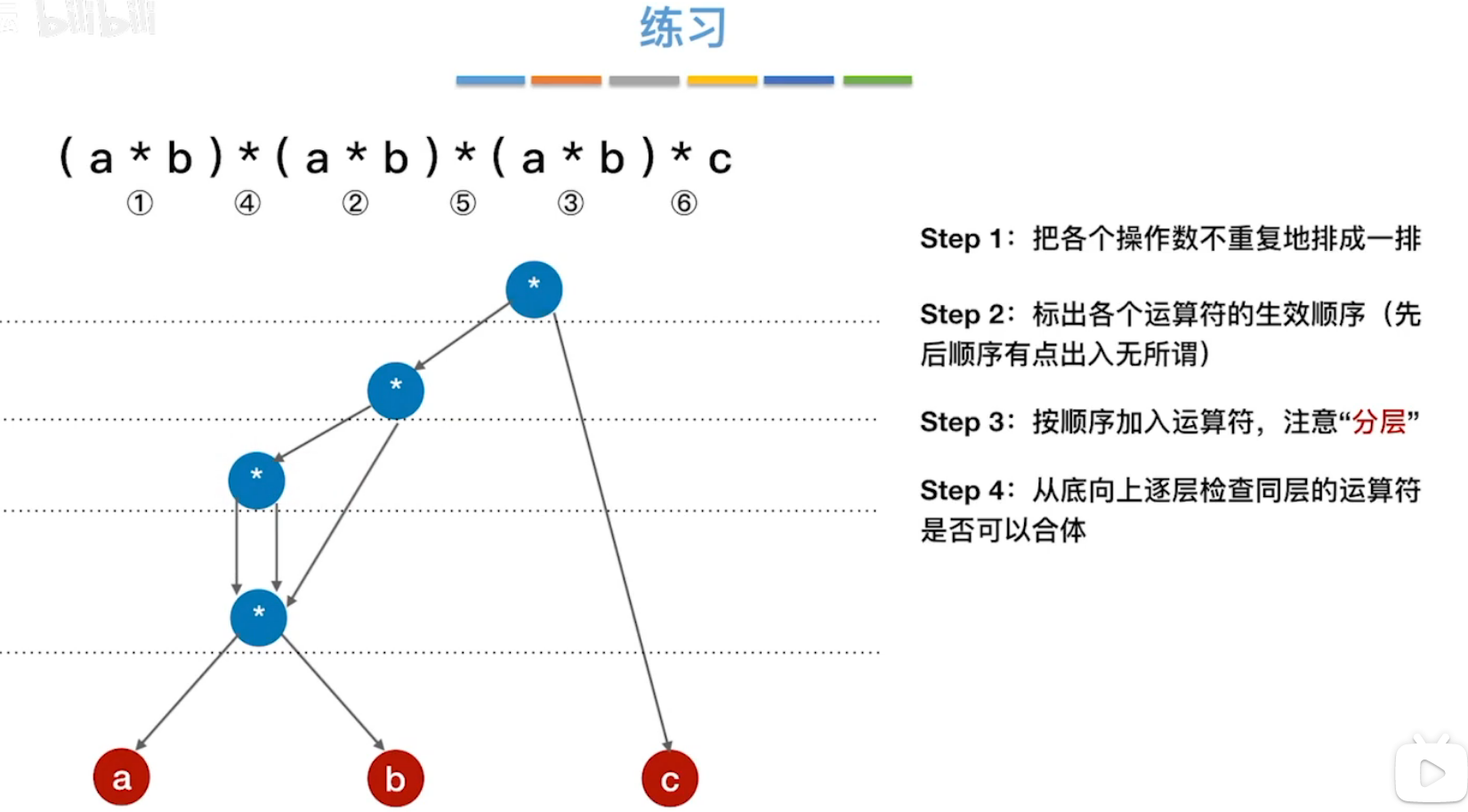
练习:
(2)有向无环图 拓扑排序
AOV网:有向无环图,用顶点表示活动的网。
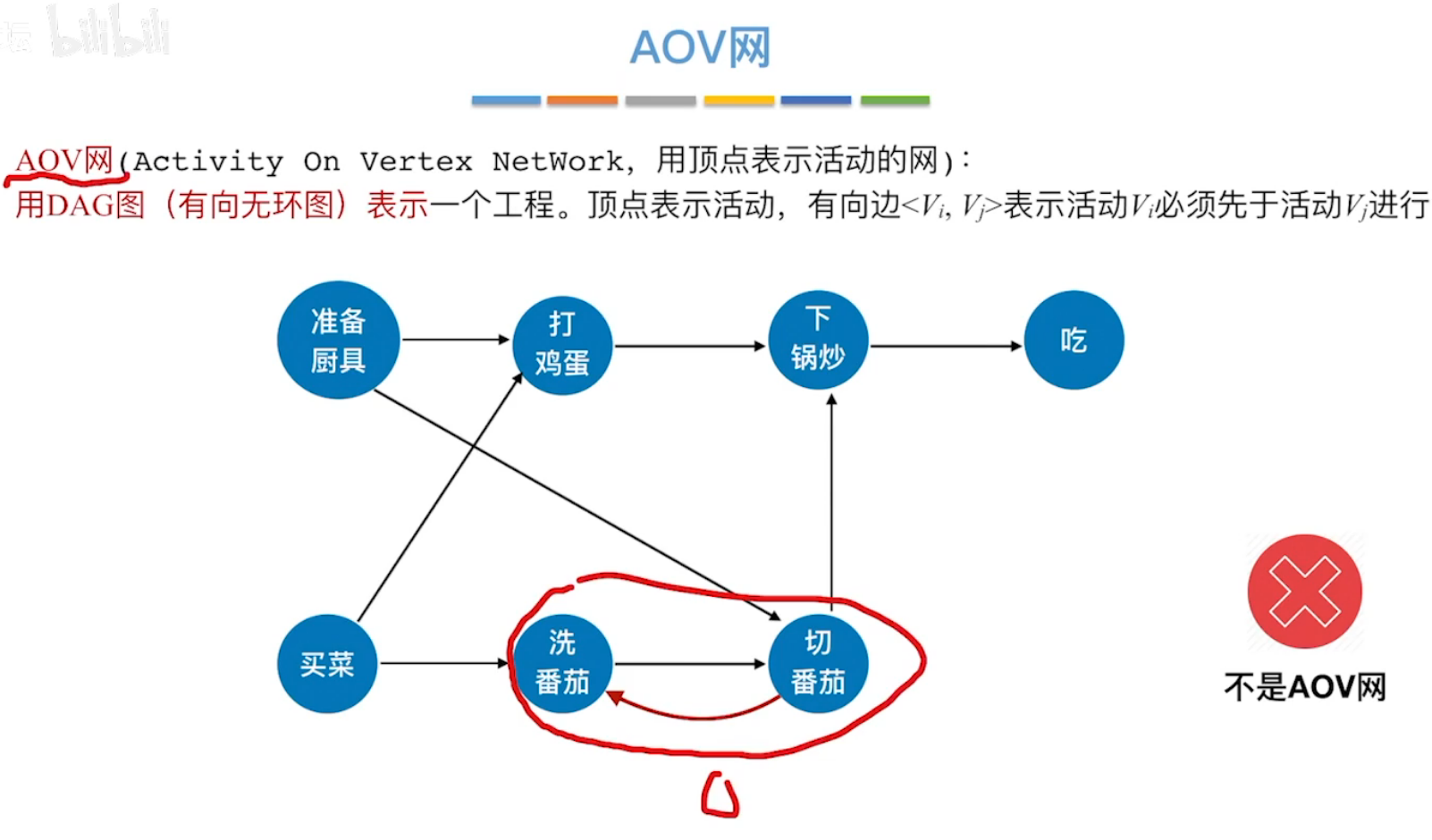
拓扑排序:即找到AOV网中记录的工程,的先后顺序。
方法:每次寻找入度为零的结点(无前驱结点的结点),将其抽出,放入队列,同时更新新的AOV网。
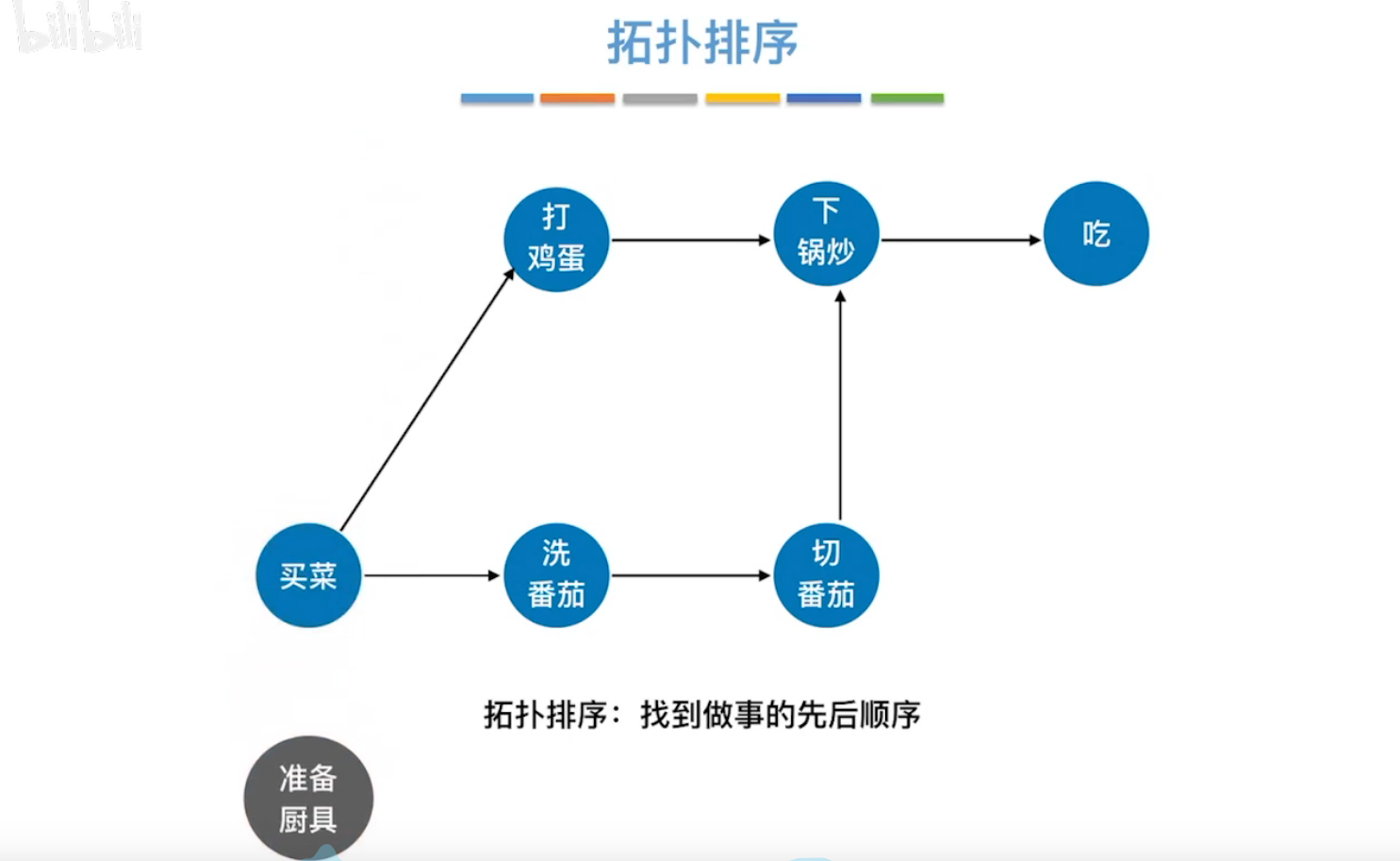
反复重复刚才的方法,即可得到下图的拓扑排序序列。
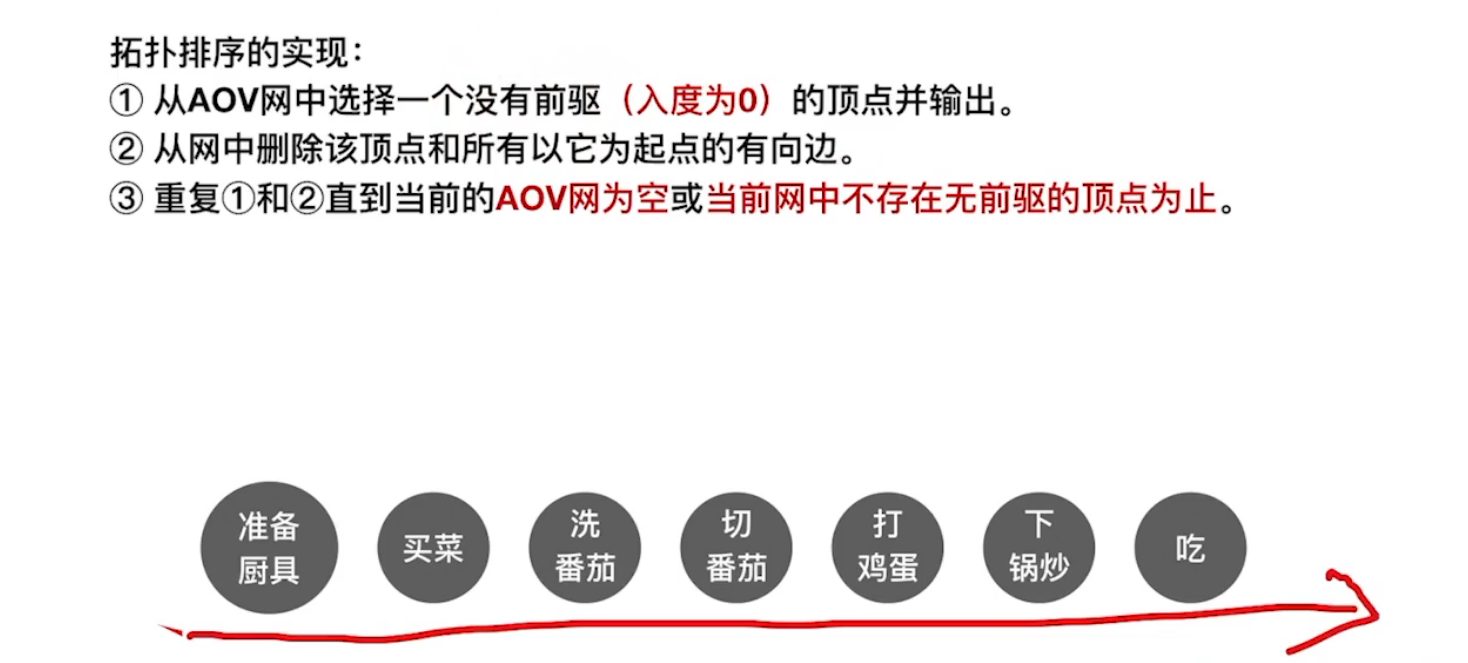
逆拓扑排序:考虑出度为0的结点(无后继结点的点)。
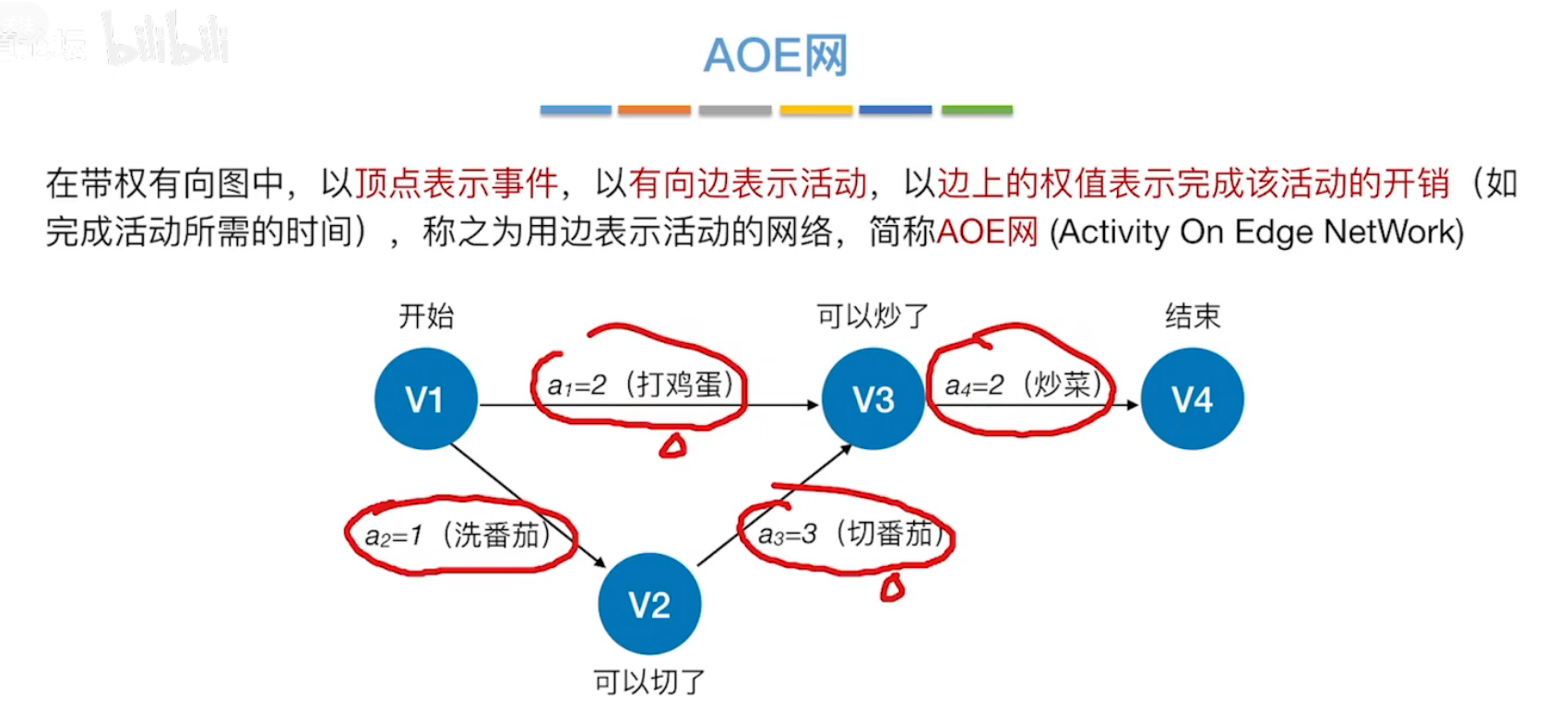
8、关键路径
AOE网,以边来表示活动。(AOV网:以结点来表示活动)。
AOE网中,边表示活动,结点表示事件。
关键路径:所有从源点到汇点的有向路径可能又多条,所有路径中,具有最大路径长度的路径成为关键路径,关键路径上的活动称为关键活动
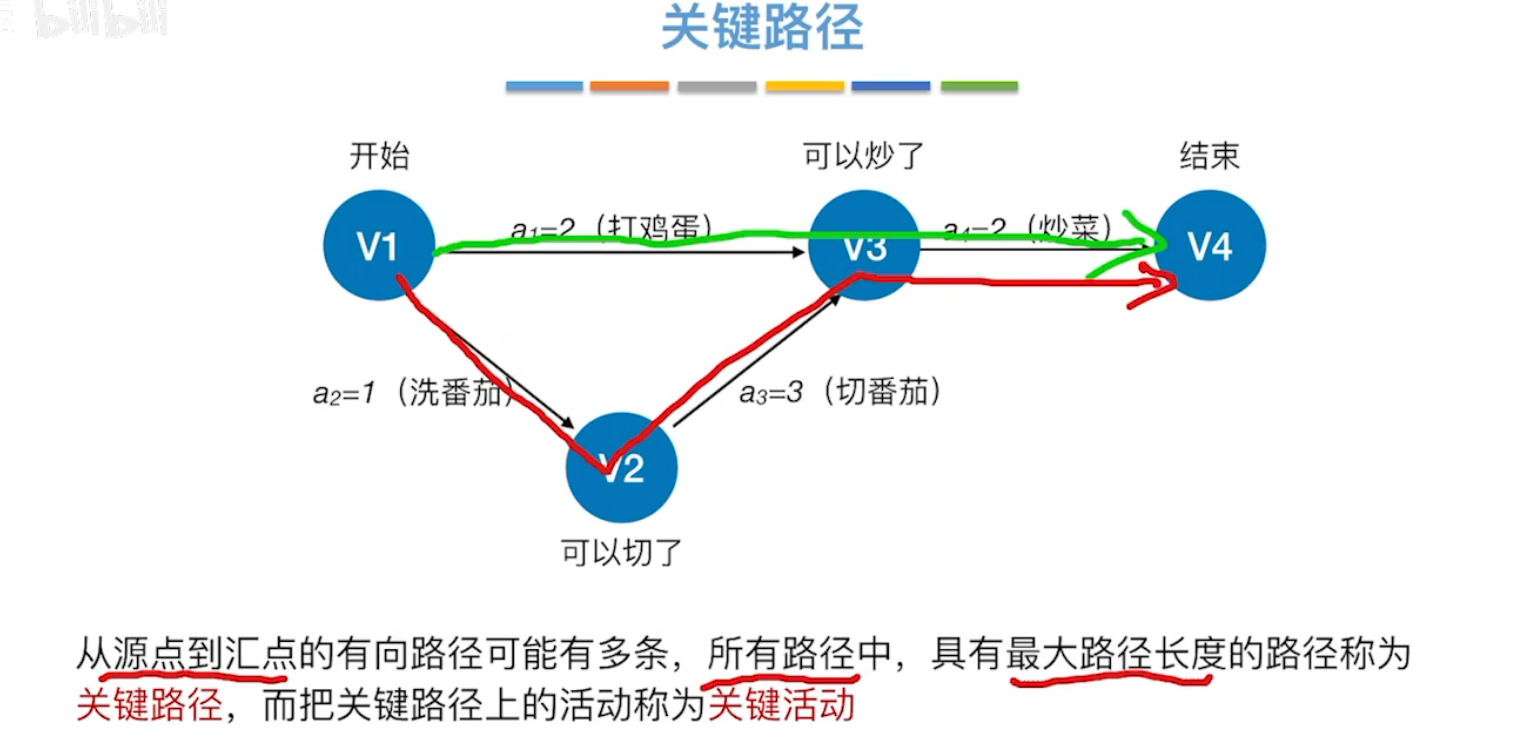
完成整个工程的最短时间,就是关键路径的长度。
若关键路径的长度不能按时完成,则整个工程的完成时间都会增大。


最早开始时间:从左往右,挨个结点的算,每次选择最大入度边。
最晚开始时间:从右往左,逆推,挨个结点,用总时间减去每个边的活动时间。
活动的最迟发生时间 - 活动的最早发生时间 = 所求活动的时间余量。
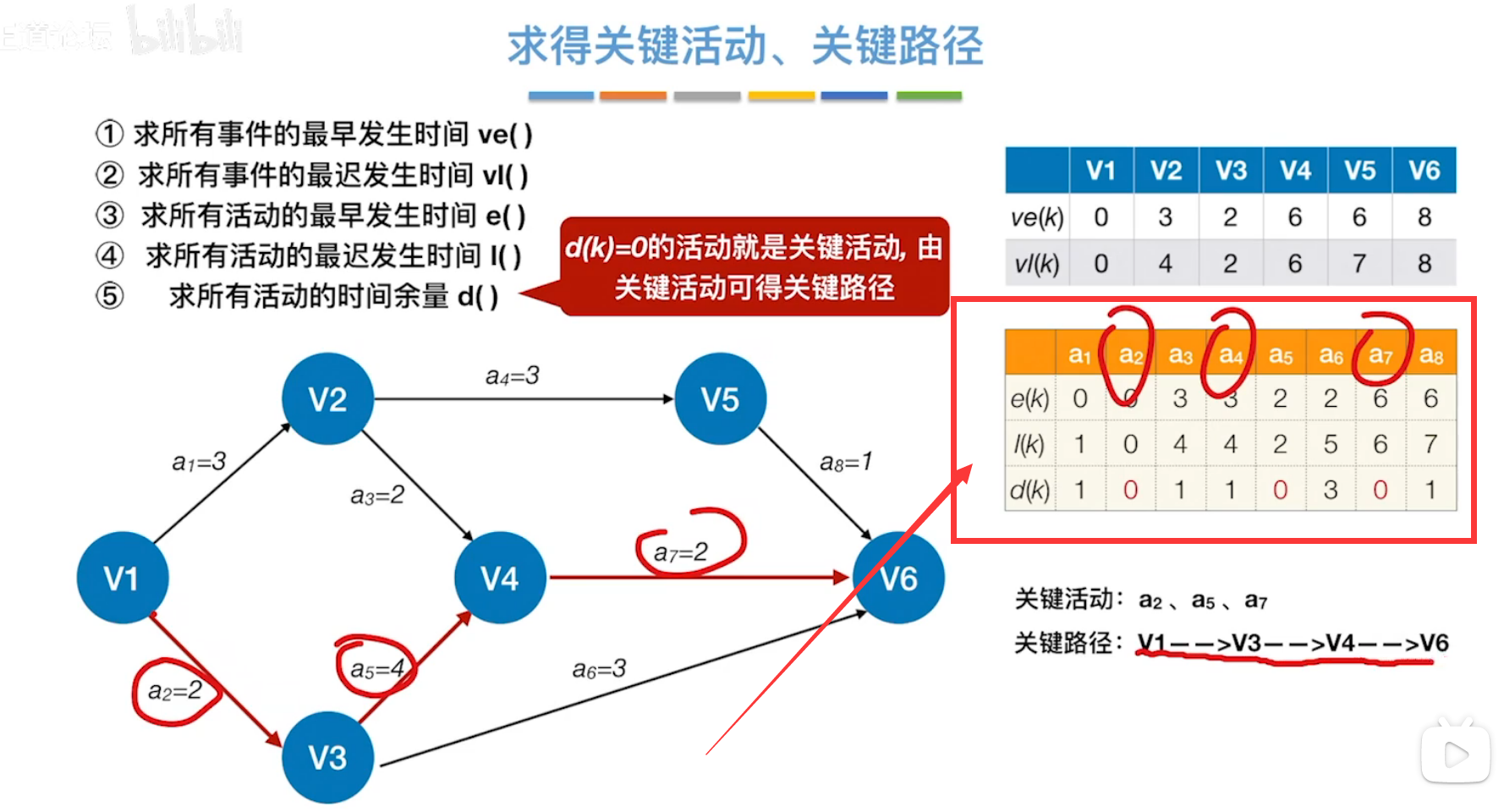
时间余量为零的活动表示关键活动(上图中为a2,a5,a7),即该活动一刻也不能拖延的执行,否则直接影响整个工程的完整时间。
特点:
-
当关键活动时间缩短,该关键活动可能变成非关键活动。
即:并不是关键活动时间约压缩,工程总时间就约少。
-
关键路径可能有多条。
即只压缩一条关键路径上的活动时间,并不一定压缩整个工程时间。
而应该压缩那些包含在所有关键路径里的"公告"关键活动
七、查找
1、查找基本概念
关键字:唯一标识数据元素的数据项。
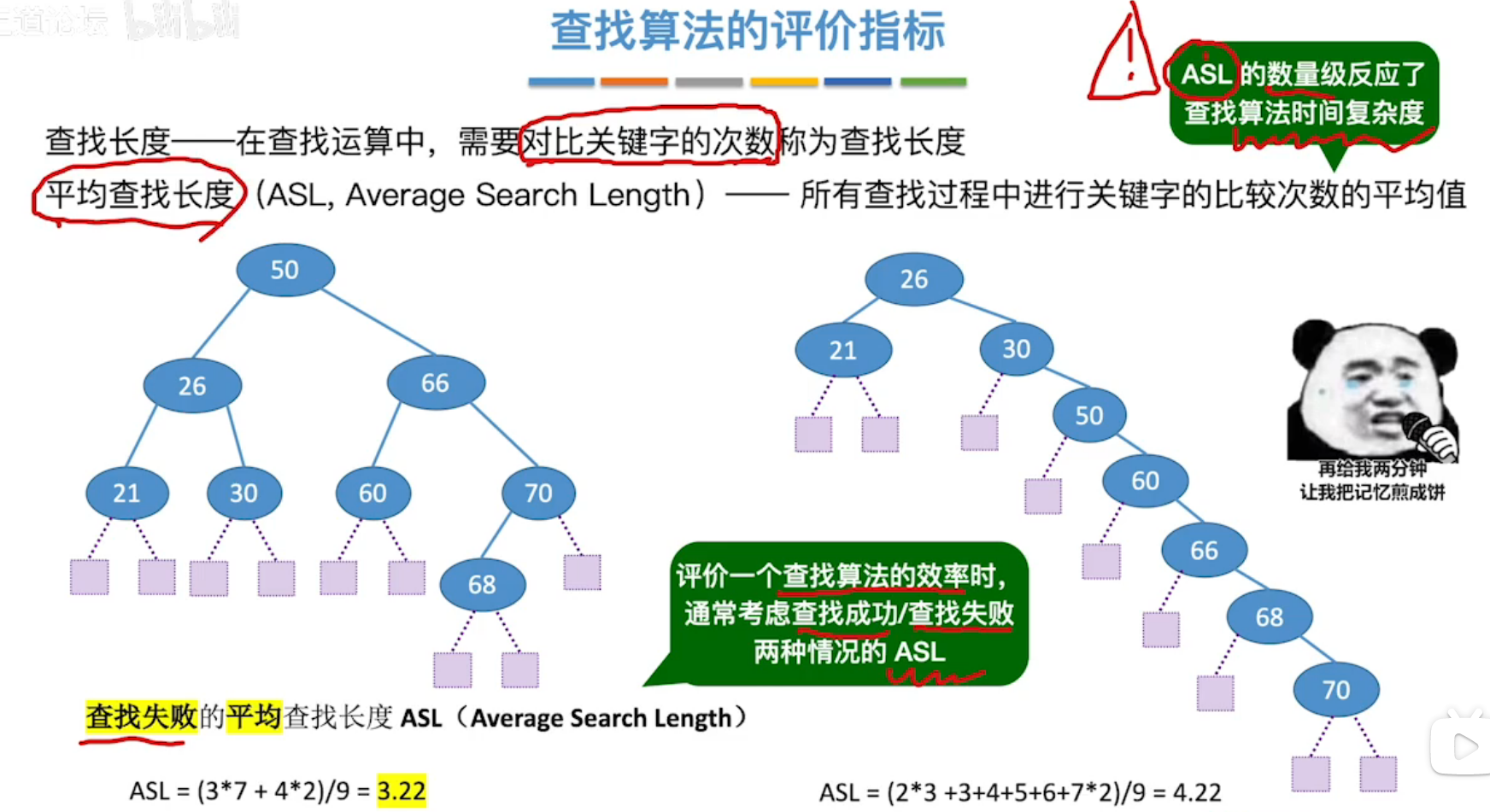
查找长度:在查运算中,需要对比关键字的次数称为查找长度。
平均查找长度(ASL):所有查找过程中进行关键字比较次数的平均值。
考点:计算各种查找的ASL(画出查找树)。考察查找判定树。
2、查找算法
(1)顺序查找
复杂度:O(n)
从头到尾遍历

增加哨兵的顺序查找:

优化:
- 若表中元素有序:怎加判断大于(小于)目标关键字时,查找失败。
- 若关键字的查找概念不同:按照查找概念降序排序(增加一个查找概念的权值)
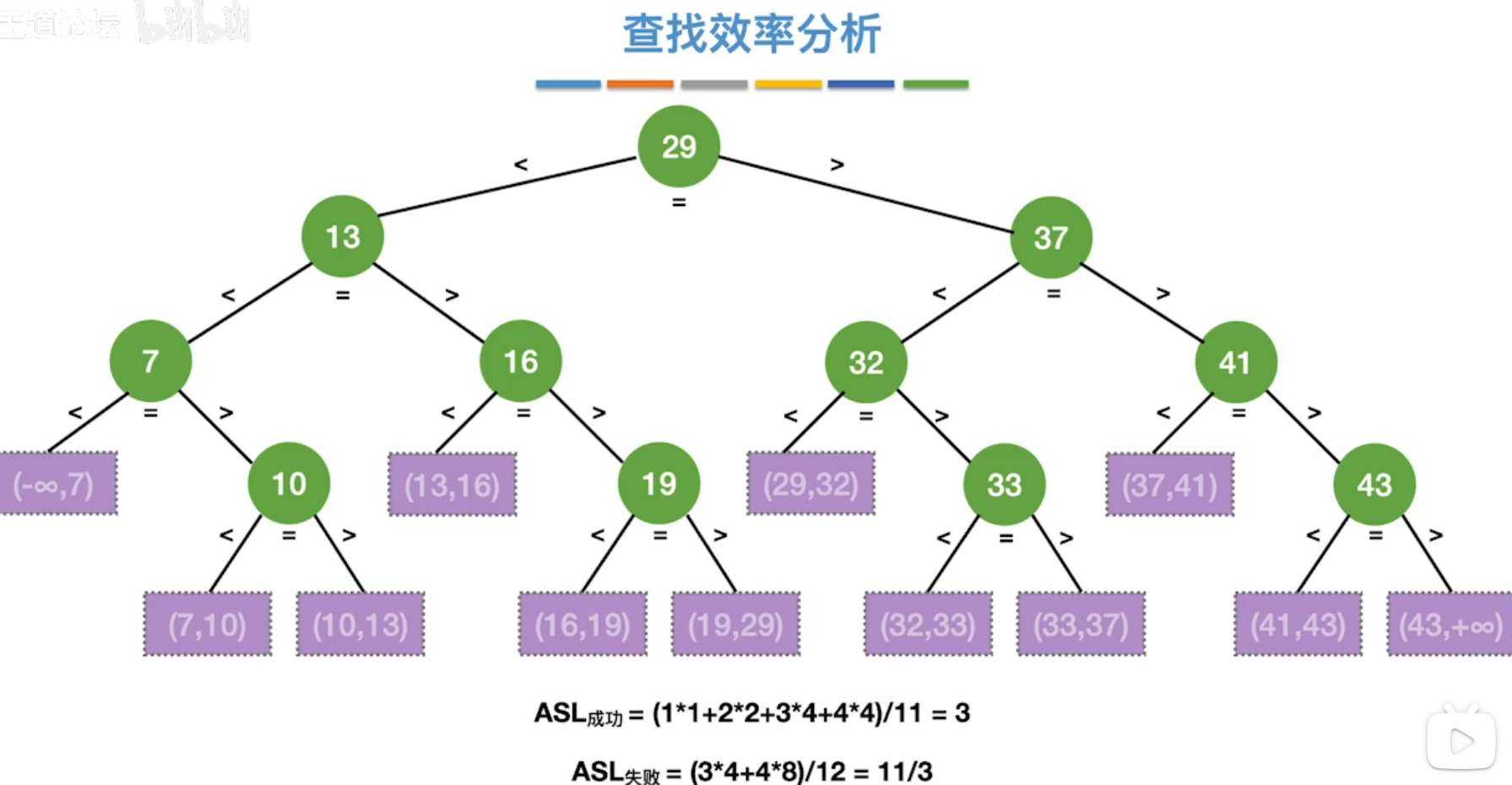
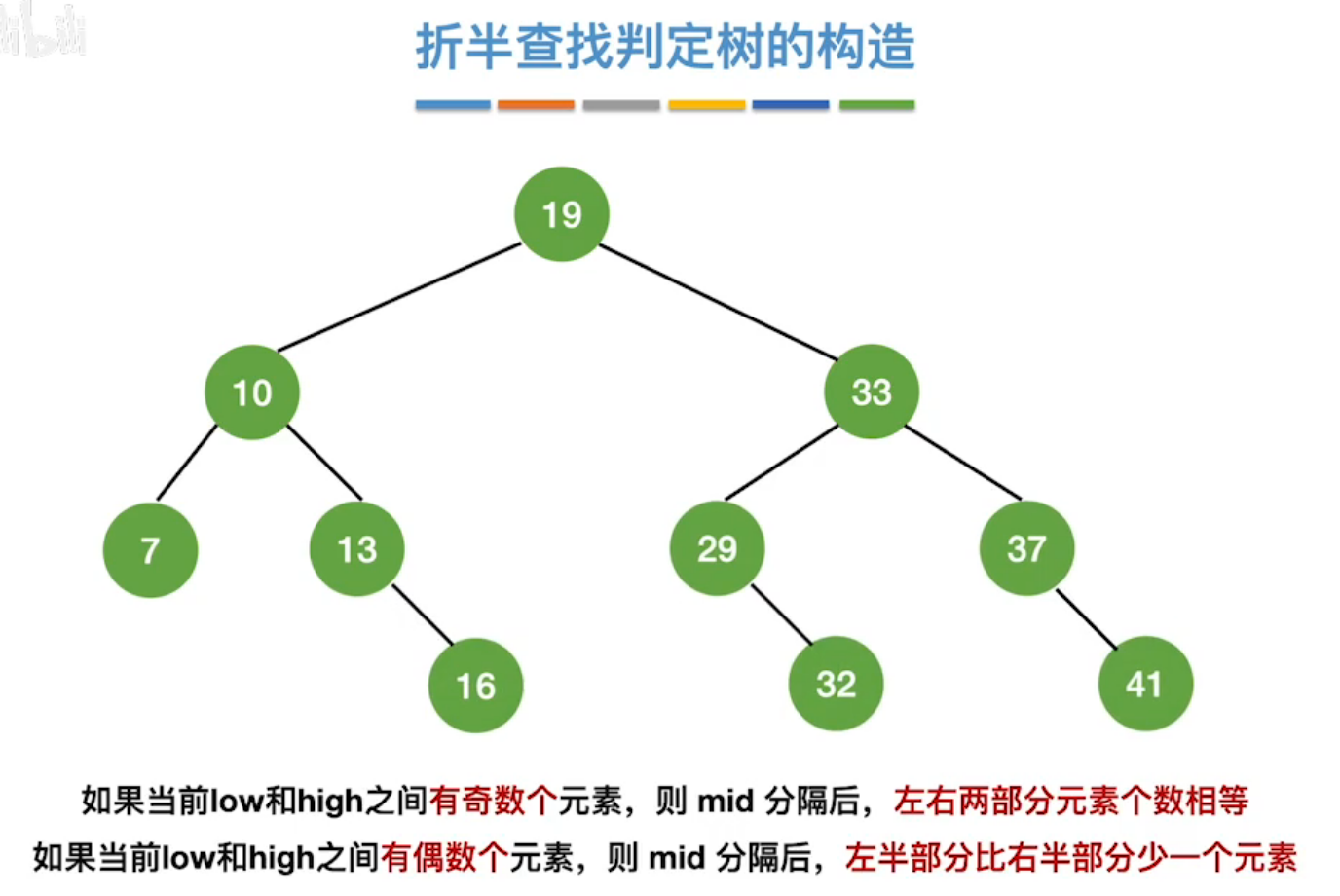
(2)折半查找(二分查找)
复杂度:O(log2n)
适用于有序的顺序表
/* 你的代码将被嵌在这里 */
//L是用户传入的一个线性表,其中ElementType元素可以通过>、==、<进行比较,并且题目保证传入的数据是递增有序的。
//函数BinarySearch要查找X在Data中的位置,即数组下标
//(注意:元素从下标1开始存储)。找到则返回下标,否则返回一个特殊的失败标记NotFound。
Position BinarySearch(List L, ElementType X) {
int low = 1;
int high = L->Last;
while (high >= low) {//包含等于的情况。
int mid = low + (high - low) / 2;//这样写,防止溢出。
if (L->Data[mid] == X)
return mid;
if (L->Data[mid] > X)
high = mid - 1;
else
low = mid + 1;
}
return NotFound;
}
分析查找效率,计算ASL。
画出判定树
(3)分块查找
复杂度:
块内无序、块间有序。
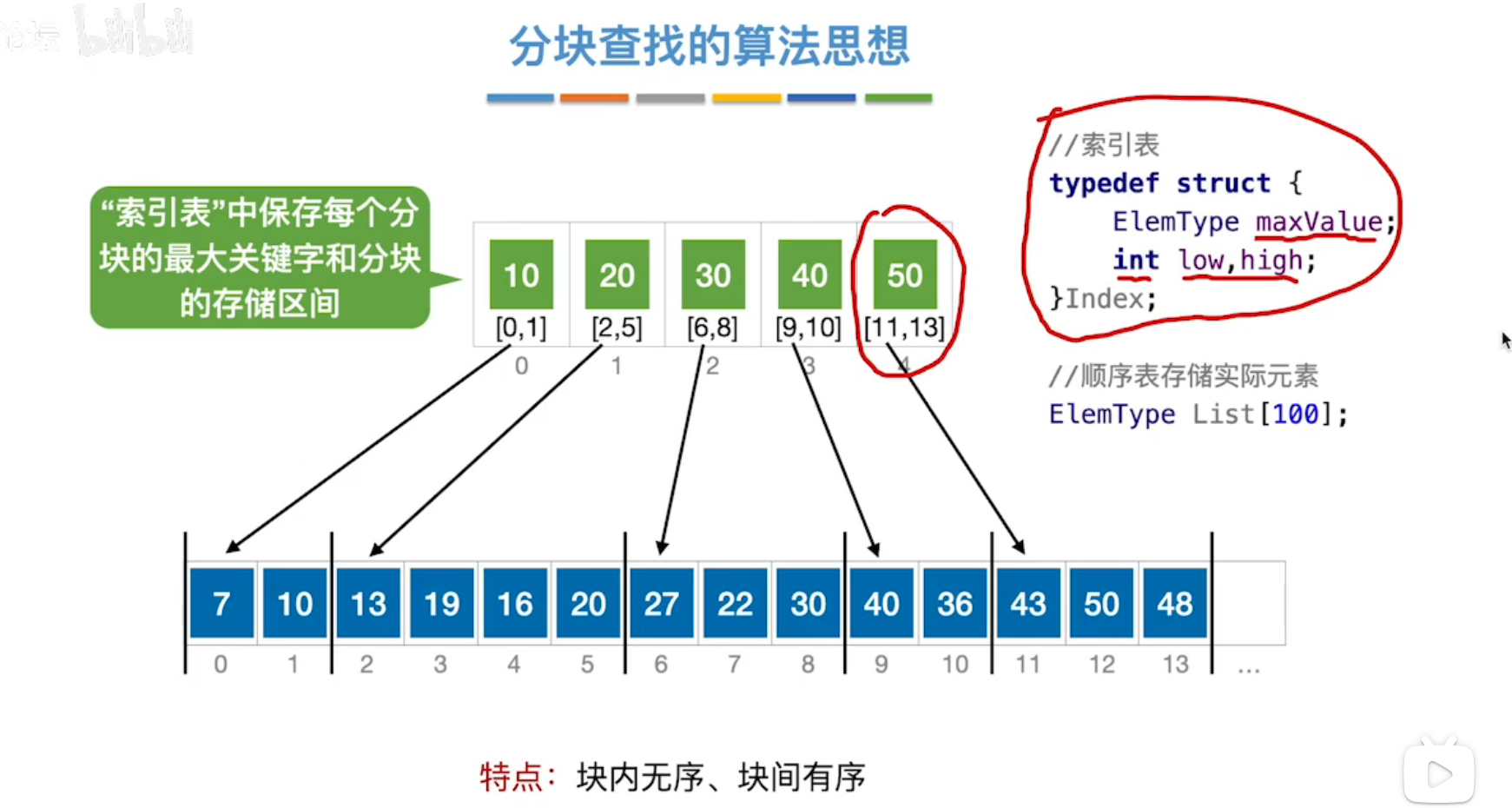
确定查找目标,先在所应表中查找对应块,再在块中查找。
优化:改为链式存储,利于增加和删除。
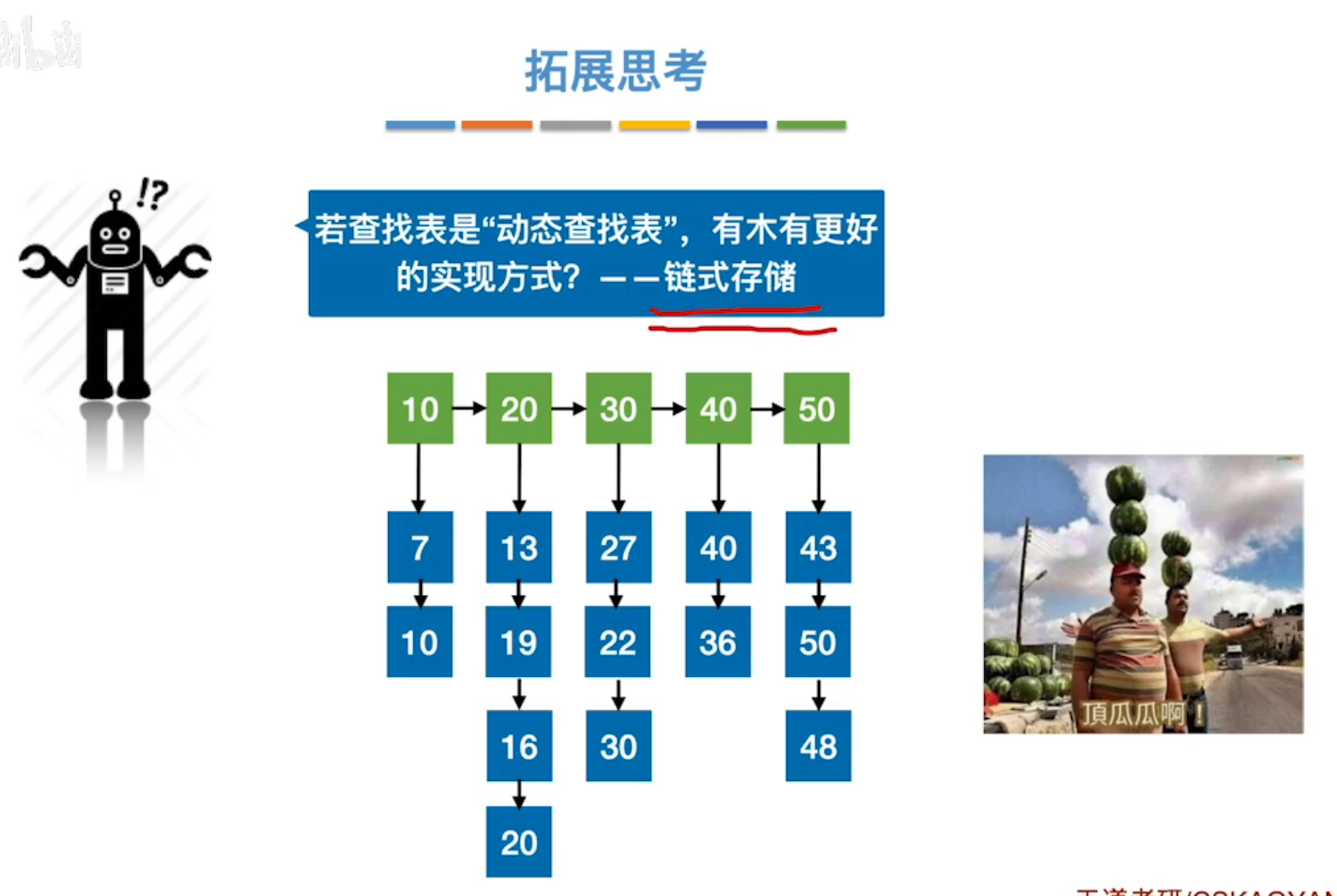
3、B树
(1)B树
二叉查找树
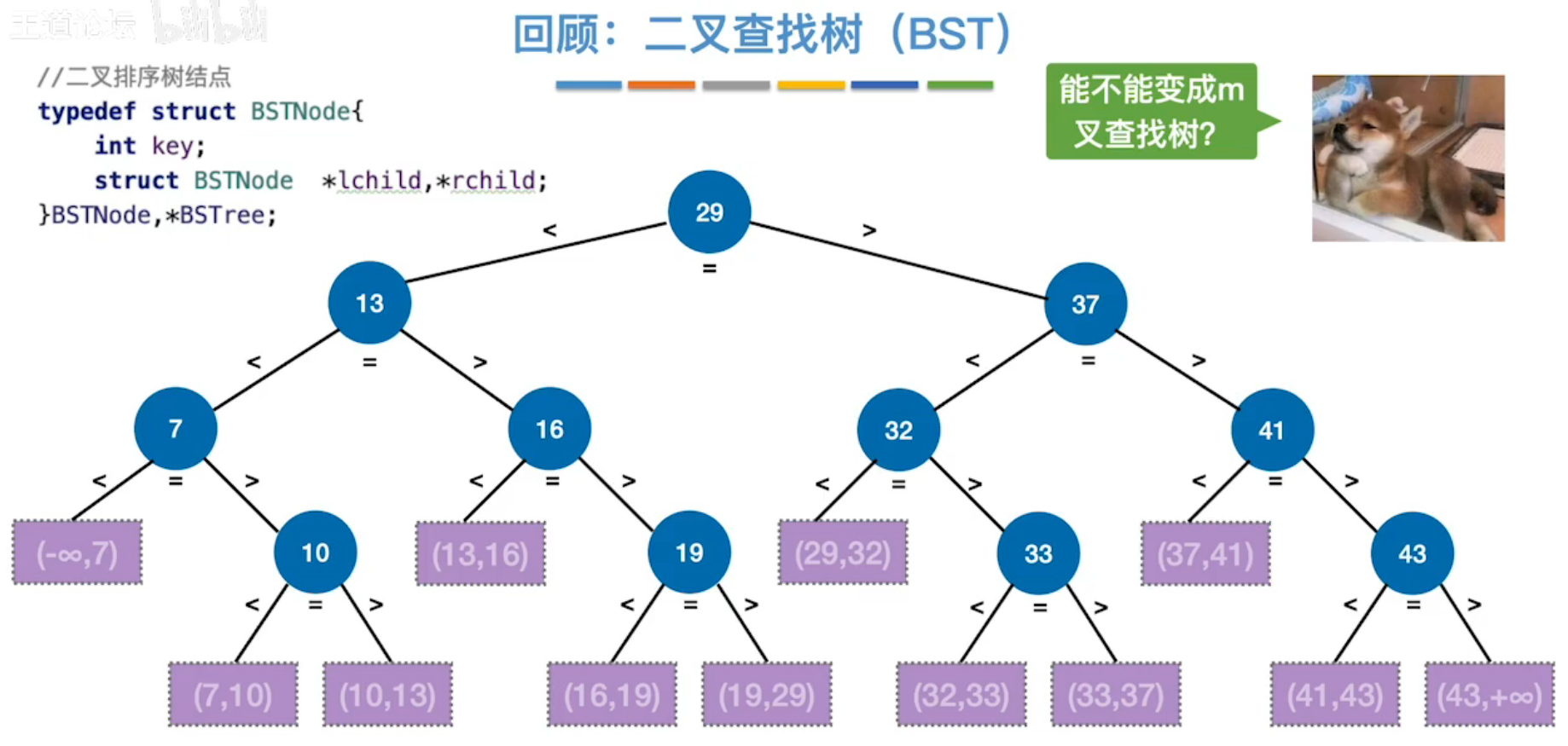 ]
]
五叉查找树
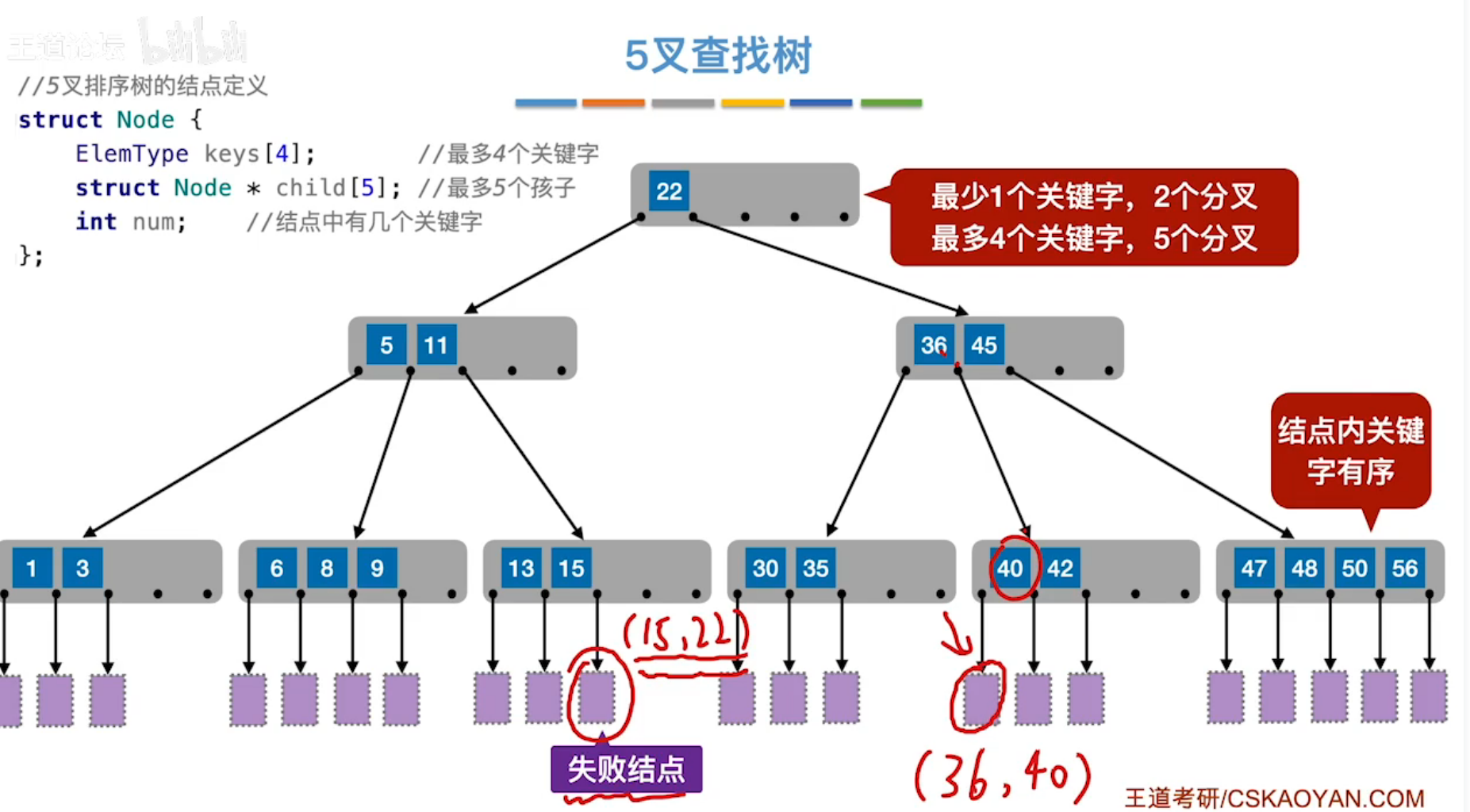 ]
]
特殊情况:若在每个节点中只保存一个关键字,则五叉查找树退化为二叉查找树。
规定①:m叉查找树,除根节点外,任何结点至少有[m/2]个关键字,以保证效率(根节点至少两个分支)。
例如:五叉查找树除根结点外,任何结点至少有2个关键字,至少有三个分支。
B树:m叉查找树中,满足规定①的同时,规定②任何一个结点,其所有子树高度都要相同。
例如上图,则为5阶B树
五阶B树:规定任何一个结点的所有子树高度相同,除根节点外,任何结点至少含有两个关键字、三个分支。
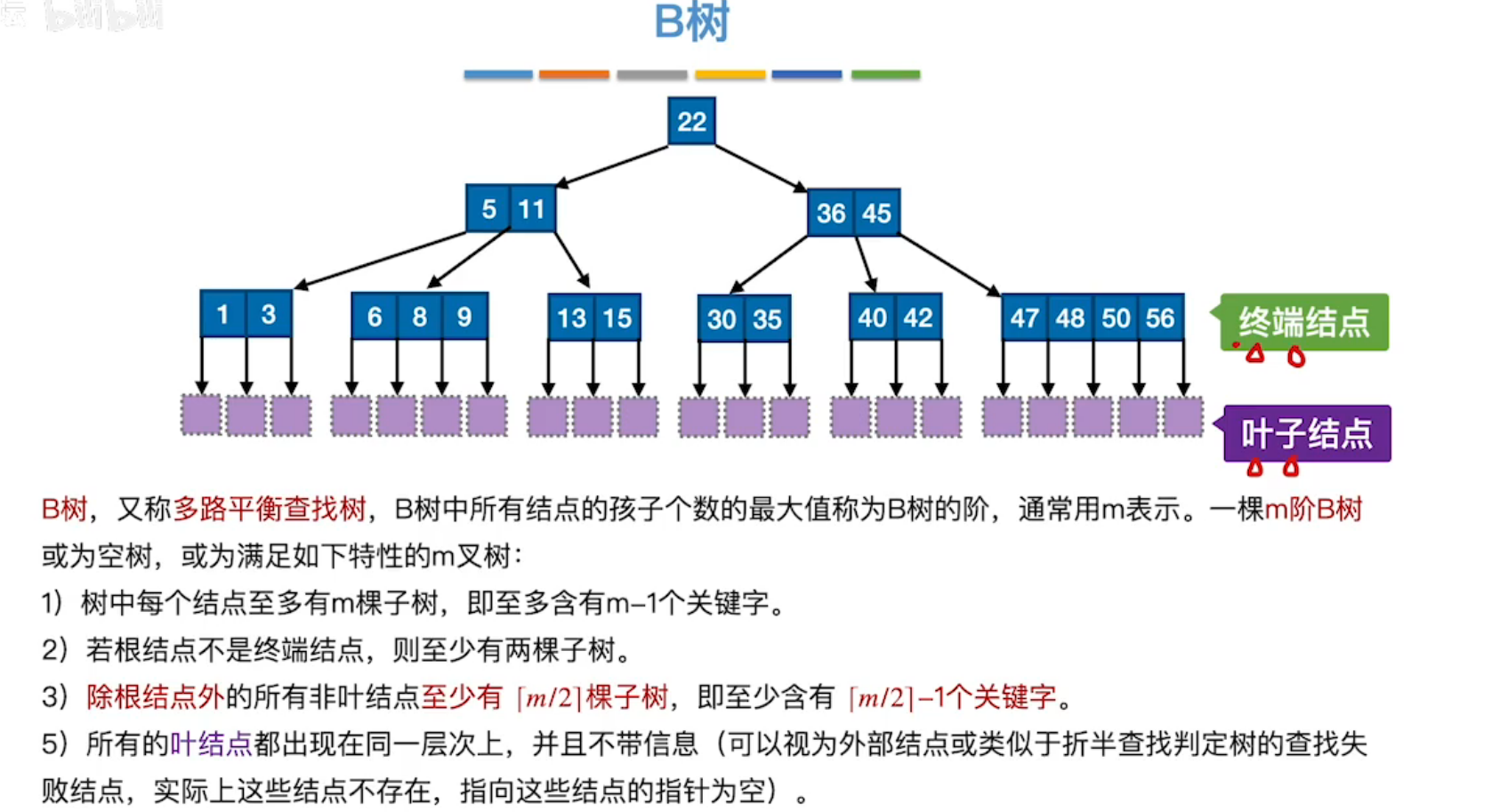 ]
]
注意:B树的叶子结点为最下层的所有失败结点,本质上就是一个NULL指针。
(2)B树的插入和删除
插入时,依然保持各结点内关键字有序。
若当前结点满了,将中间的关键字提到父节点去。
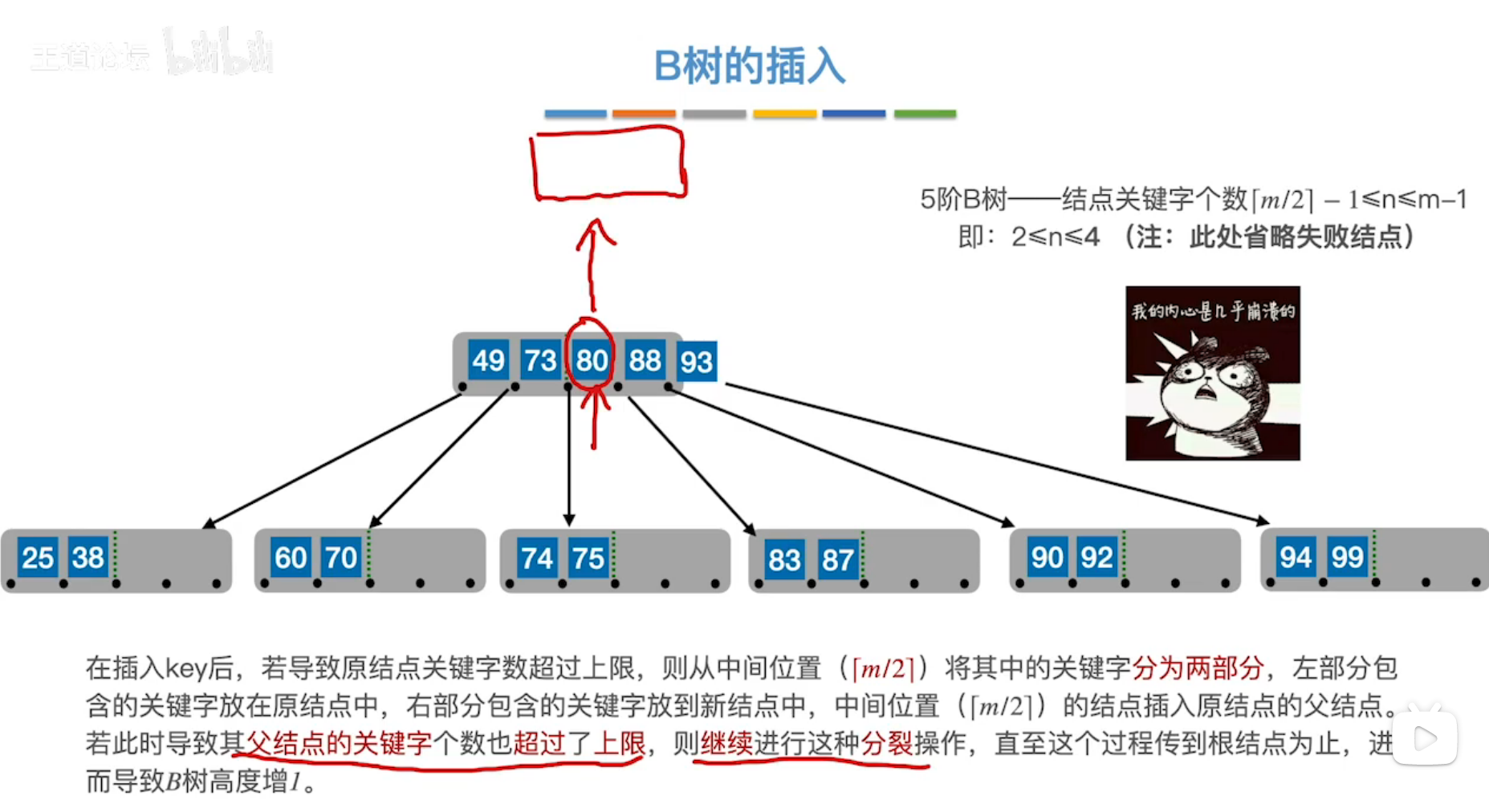
删除时,类似于平衡二叉树的删除,寻找其直接前驱或直接后继替代,使对非终端结点关键字的删除,转化为对终端结点的删除操作。
 ]
]
同时,进行一些调整,使其保持B树的特性。
(3)B+树
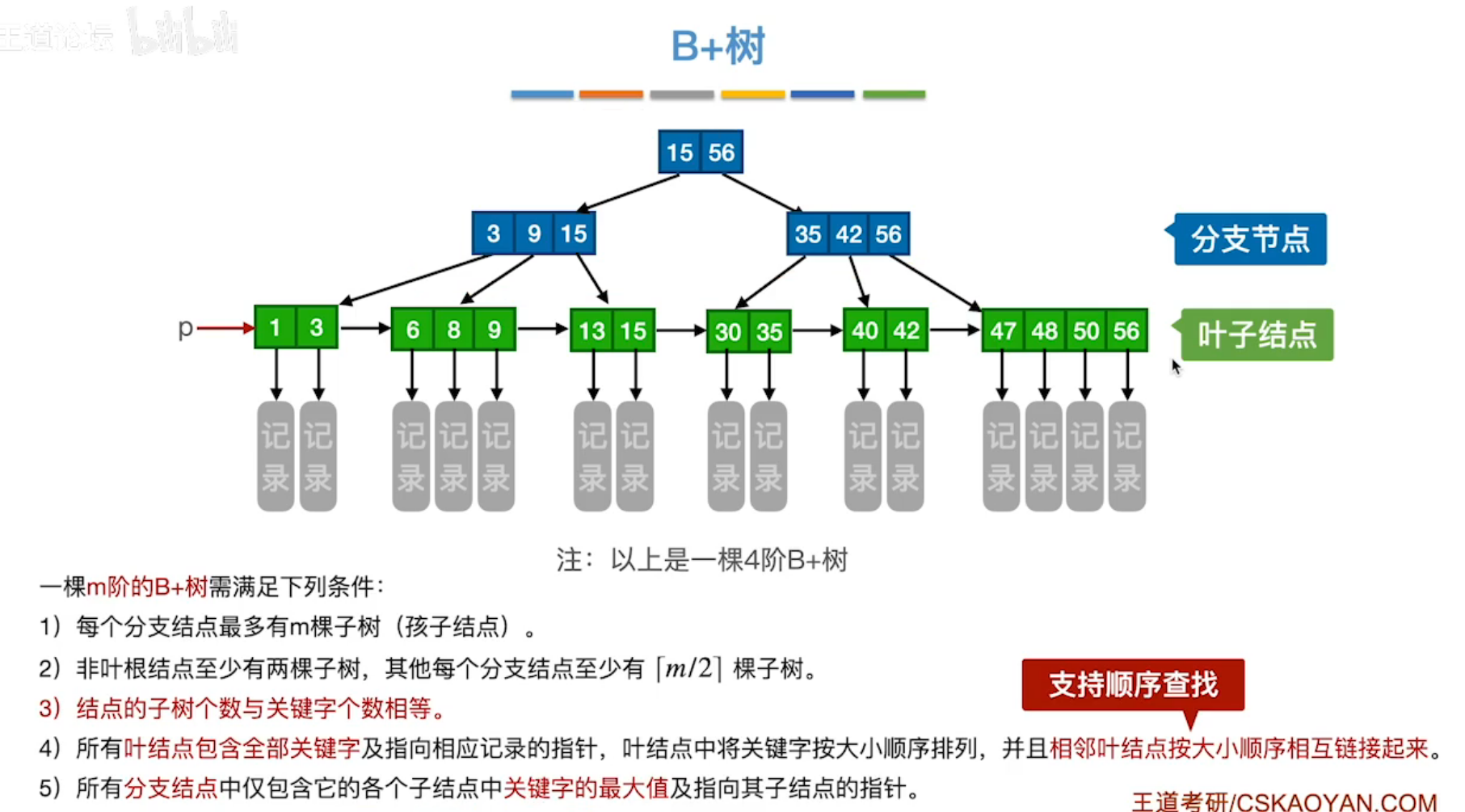
-
与B树不同,B+树各结点的子树个数与关键字个数相同。
B树中,子树个数 = 关键字个数+1
-
所有信息存储在叶结点,也就是说非叶结点只是一个索引,指向子树 ,非叶节点与叶节点会有相同关键字。
B树中,非叶节点也存储信息,各节点关键字不重复。
-
所有叶节点也是练成一条有序链,p表示链表头。
B+树的优点:使一块磁盘存储更多的关键字,利于索引速度。

4、散列查找
散列查找:用数组实现,存储指针,
(1)拉链法 处理关键字冲突
计算散列函数的ASL。(平均查找长度)
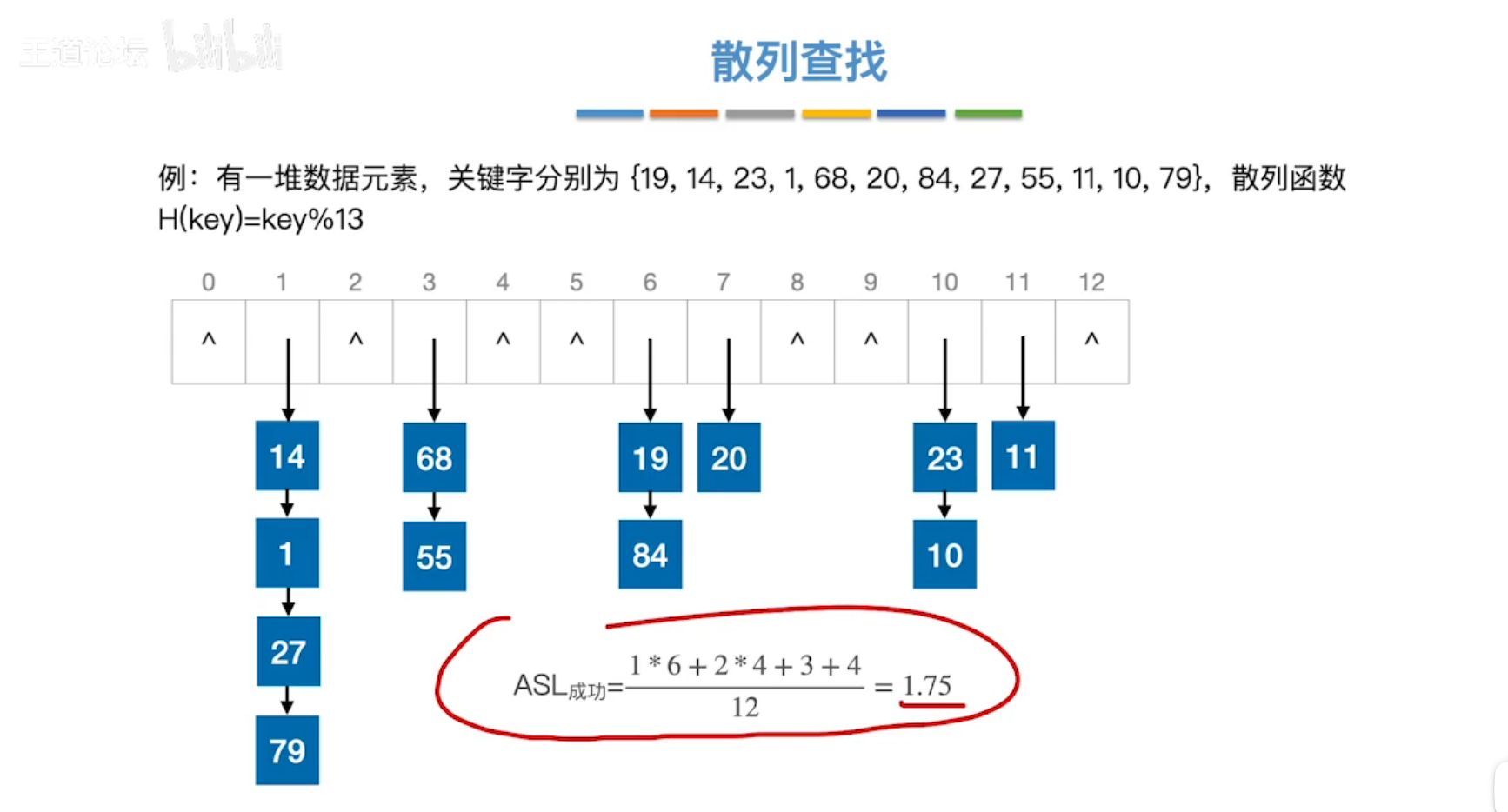
装填因子α = 表中记录数 / 散列表长度
(2)散列函数
- 除留余数法

注意选一个素数p,如果在关键字的值分布不均匀时,对素数取模会使结点分布更均匀,提高查找效率。
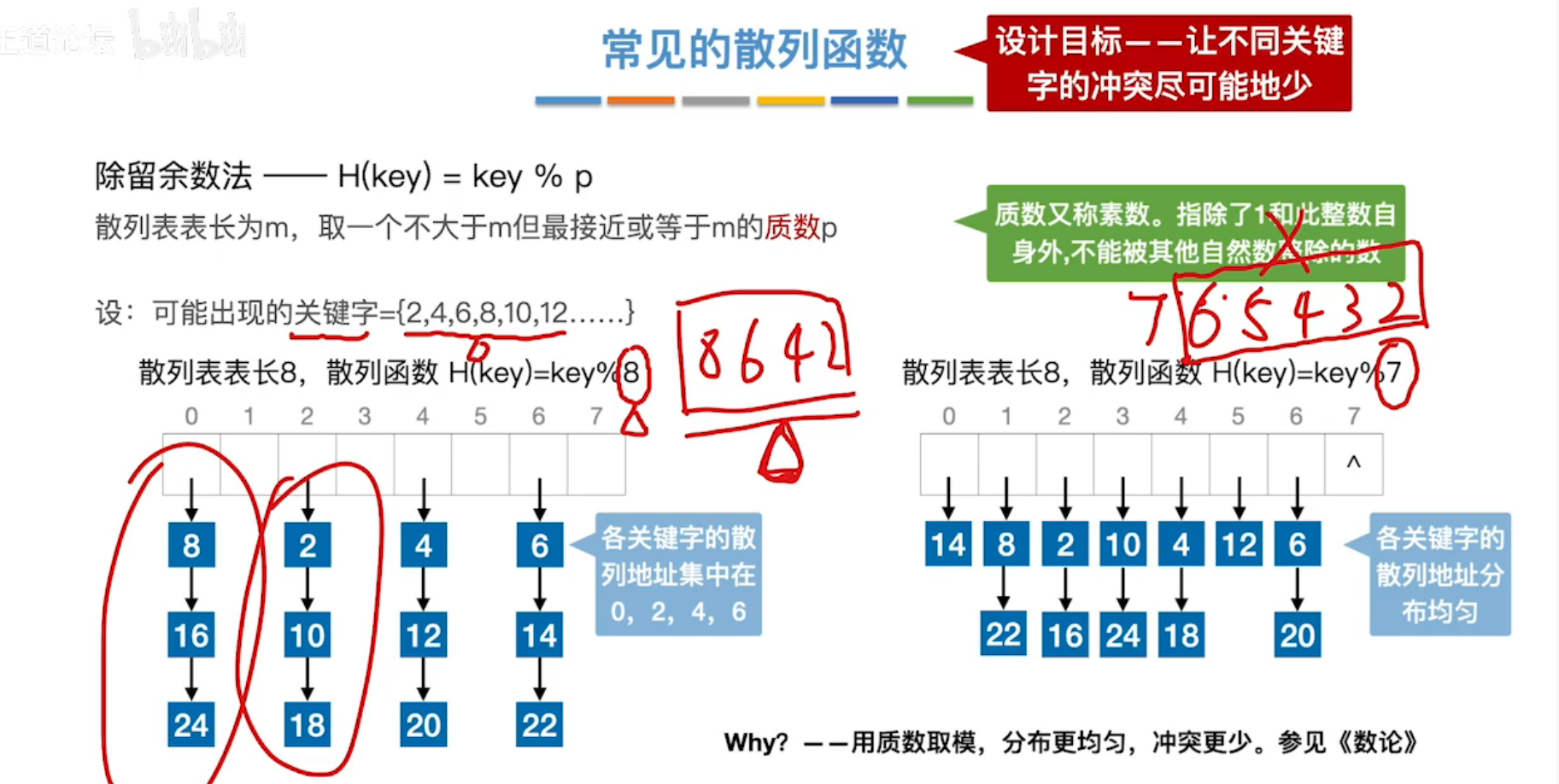
- 直接定址法
直接用关键字作为查表地址,或对关键字进行线性变化后再定址。

适用于关键字分布基本连续的情况。
若关键字分布不连续,则空位较多,造成存储空间的浪费。
- 数字分析法
选取数码分布较均匀的若干位作为散列地址
例如:手机号只取后四位作为散列地址,进行构造表、查找。
- 平方取中法
取关键字的平方值的中间几位作为散列地址。

如图,这种方法得到的散列地址与关键字的每一位都有关系。
(3)开放定址法 处理关键字冲突
Hi = ( H(key) +di) % m
H(key) = key%13,正常的求模运算,注意这里13不等于m,取小于等于m的最大素数13。
di 为给定的增量序列。
 ]
]
三种方法求增量序列di :线性探测法,平方探测法,伪随机序列法。

- 线性探测法
**增量序列di**为线性序列:0,1,2,3,4……,k(k<=m-1)

注意每移动i个位置,则表示Hi ,同时对应 di,即每次冲突,则重新计算Hi,i会+1。
特别注意:删除操作
删除一个元素后,要用特殊数字标记该位置已删除,否则引起查找失败。
- 平方探测法

0为起始,然后是先正后负:+1,-1,+4,-4。
平方探测法的小坑。

- 伪随机序列法
di 为某个伪随机序列。
(4)再散列法 处理关键字冲突
多准备几个散列函数。

八、排序
算法稳定性:指关键字相同的元素,在排序之后的相对前后位置不变,则称为该算法具有稳定性。

1、插入排序
平均时间复杂度:O(n2)。
当序列接近有序时,算法的最优时间复杂度接近O(n)。
规定左端有序,右端无序,依次从右端与一个关键字,插入左端,使左端有序序列逐渐增大,右端无序序列逐渐减小。
适用于顺序表、链表。
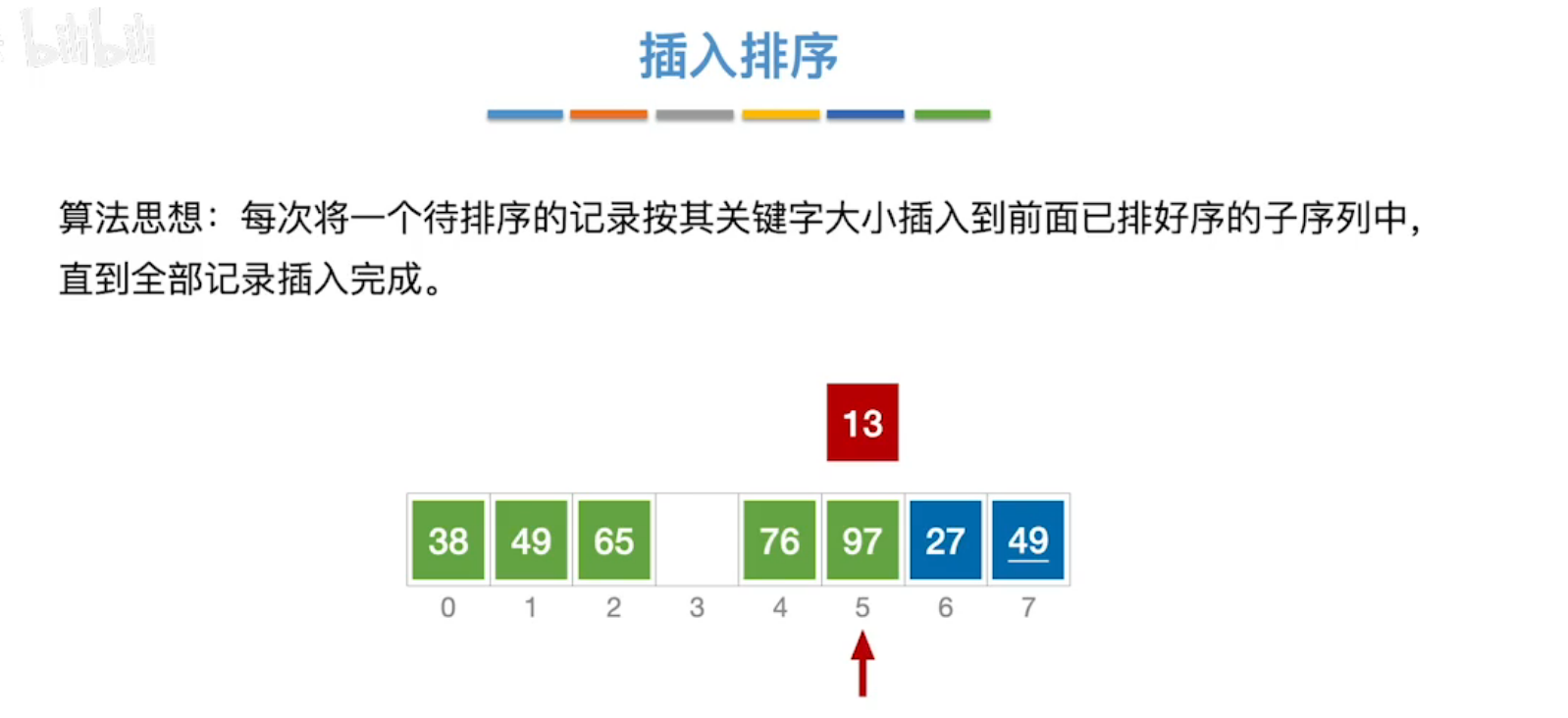
代码示例:

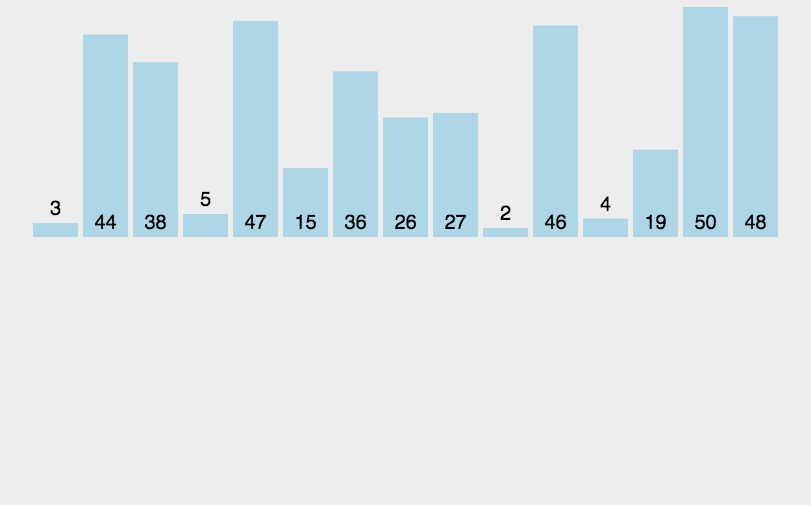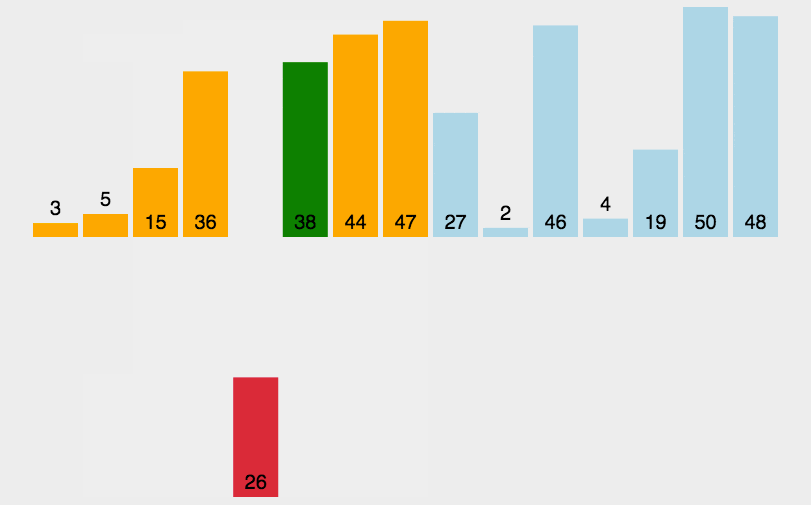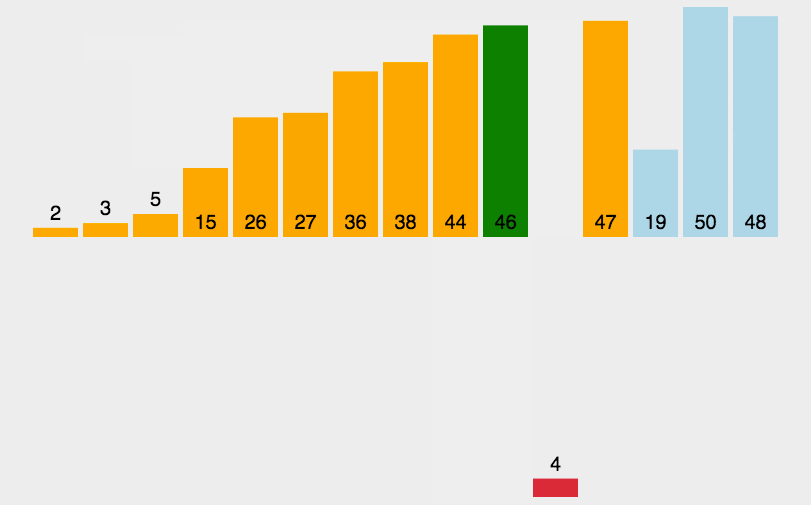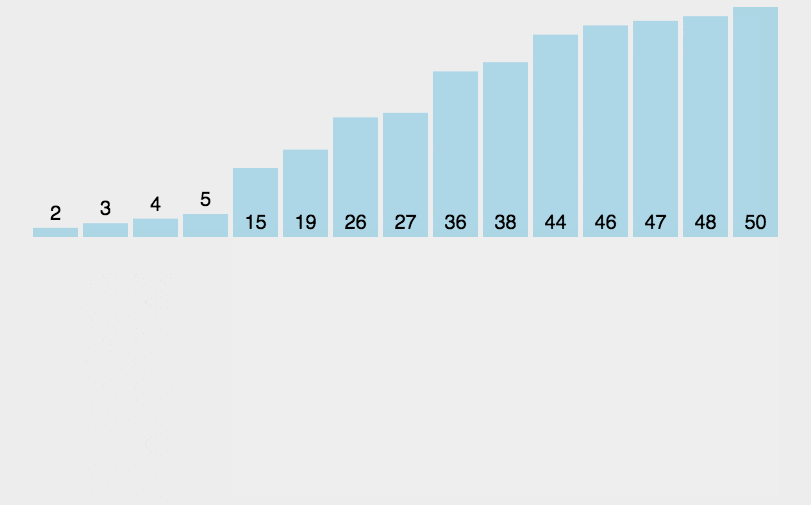
//规定左端有序。
void InsertionSort(int a[], int n) {
int i, j;
for (i = 1; i < n; i++) {
int temp = a[i];
for (j = i; j > 0 ; j--) {
if (temp < a[j - 1]) {
a[j] = a[j - 1];
}
else {
break;
}
}
a[j] = temp;
}
}
带哨兵的处理方式

优化:在左端查找插入位置时,使用折半查找,找到位置再插入。

2、希尔排序
在插入排序的基础上优化而来。
对一个序列进行逐次分组,组内插入排序,使该序列相对有序,然后逐渐减少分组数量,组内插入排序,直至该序列为一个分组,又对这个整体进行插入排序。
因为序列已经相对有序,所以时间复杂度会稍微降低。
时间复杂度:未知(优于直接插入排序)
该算法不稳定,且仅使用与顺序表。
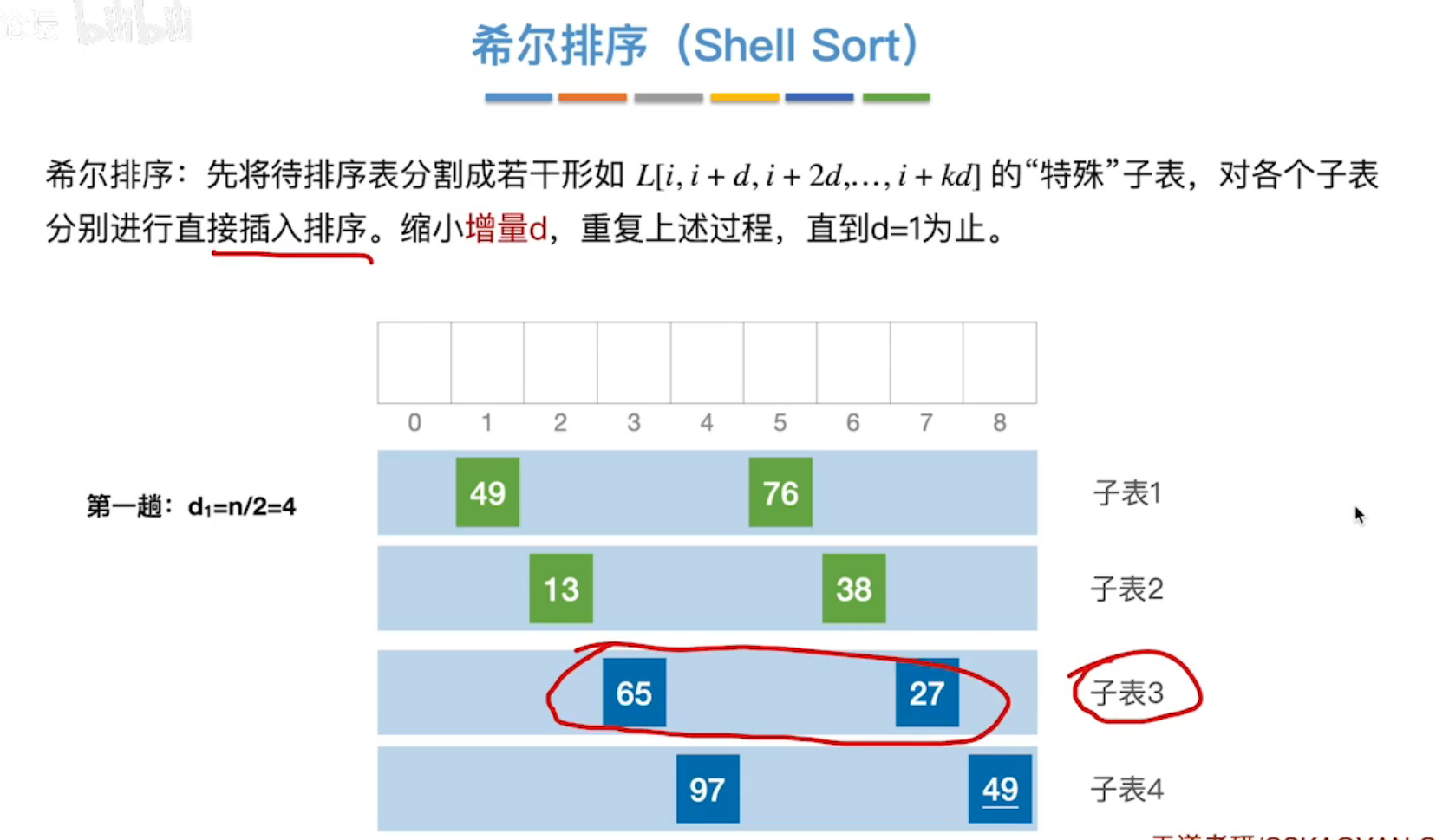
常考点:给定增量d,求每一轮的排序结果。
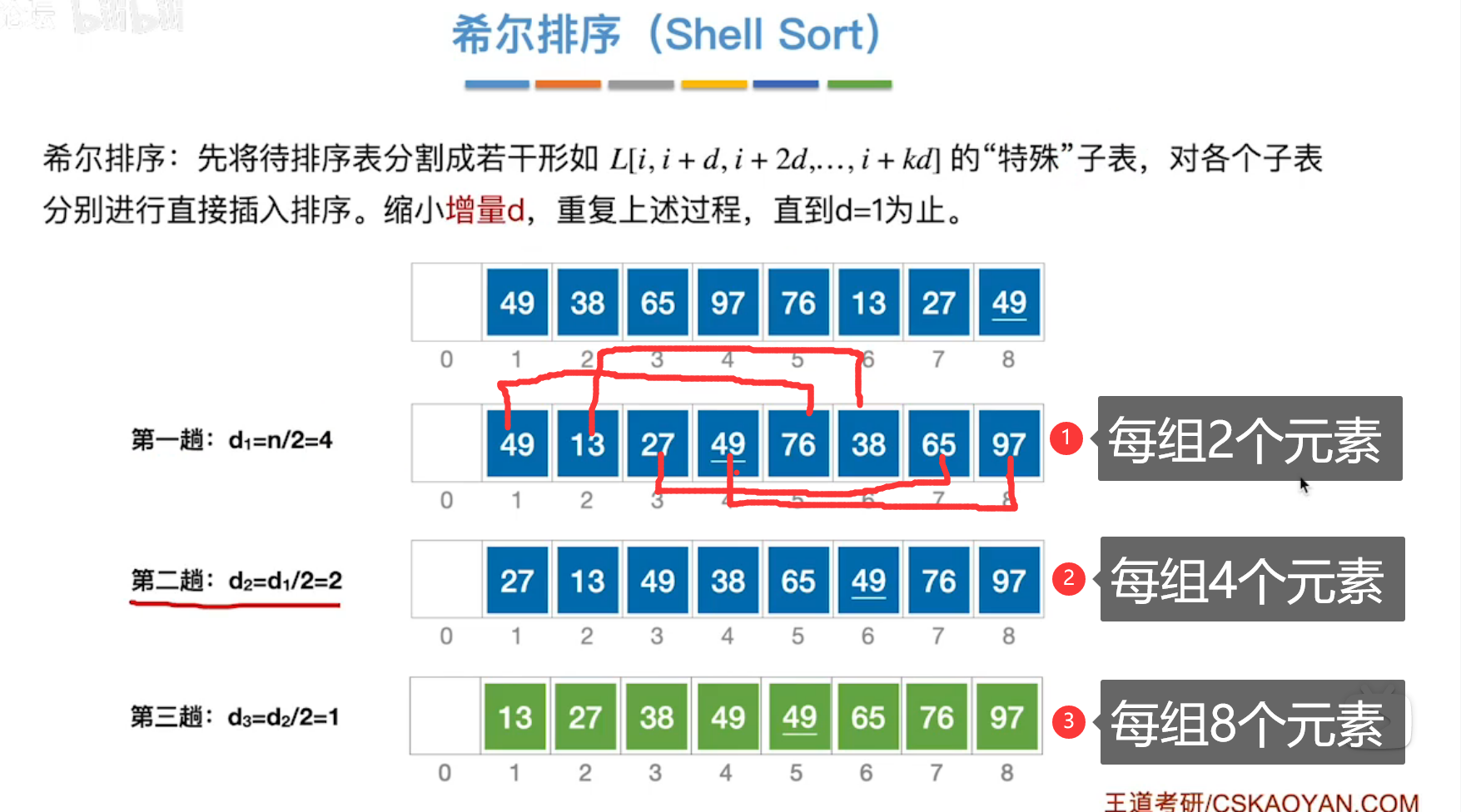 ]
]
代码如下:
//希尔排序
void ShellSort(int a[], int n) {
int i, j, d;
for (d = n / 2; d >= 1; d /= 2) {//按增量d分组,增量d每次减小两倍。
for (i = d + 1; i < n; i++) {//每个i都有一个对应的分组,再组内进行插入排序。
int temp = a[i];
for ( j = i-d ; j >= 0; j -= d) {
if (temp < a[j]) {
a[j+d] = a[j];
}
else {
break;
}
}
a[j + d] = temp;
}
}
}
3、冒泡排序
冒泡排序:从左往右(从右往左)遍历,让依次相邻的连个元素两两比较,每一轮下来都能得到一个最值,放在另一端,最后得到有序的序列,该算法具有稳定性。
时间复杂度:O(n2)。
最坏的情况:该序列为逆序有序,时间复杂度O(n2)。
最好的情况:该序列为正序语序,时间复杂度O(n)。
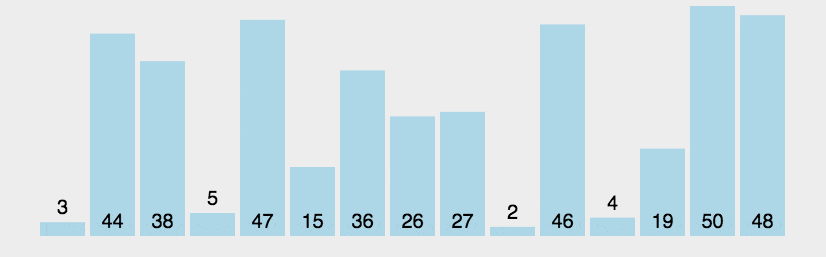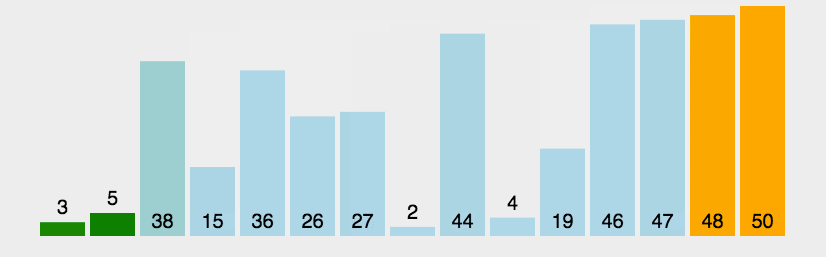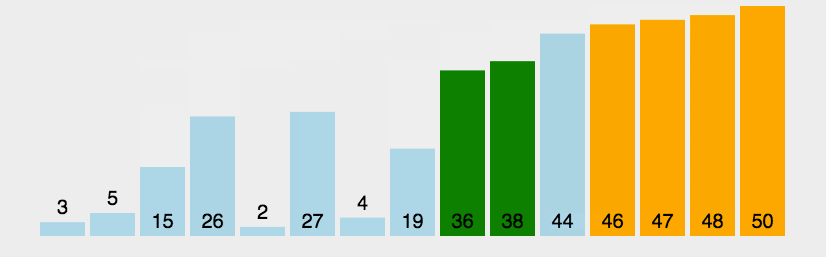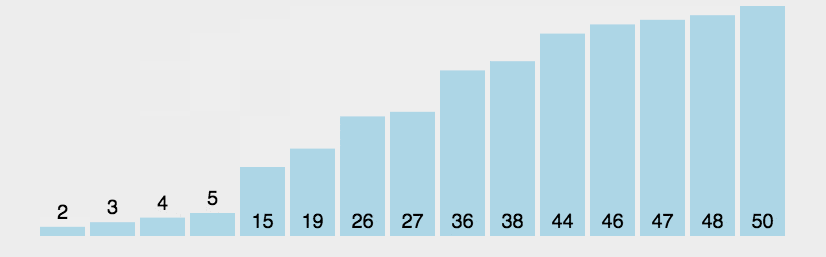
//冒泡排序,从左往右遍历,使右端有序。
void BubbleSort(int a[], int n) {
int i, j;
for (i = n-1; i > 0; i--) {//注意这里是i=n-1,然后i--。
int flag = 0;
for (j = 0; j < i; j++) {//逐个冒泡过程
if (a[j] > a[j + 1]) {
int temp = a[j];//交换
a[j] = a[j + 1];
a[j + 1] = temp;
flag = 1;
}
}
if (flag == 0) {//若本轮未发生交换,则说明已经有序。
return;
}
}
}
//原始的冒泡排序没有flag,这里是用于优化,可以删去。
4、快速排序
- 快速排序,是所有排序中平均性能最优的算法。但不稳定。
快速排序:每一轮,以组内首个关键字为枢轴元素,根据序列是否大于枢轴元素,将其分为左右两部分,将枢轴元素插入中间,得到第二轮的序列。
又分别将左边序列和右边序列进行上诉算法,递归执行,直至最后有序。
过程如下:
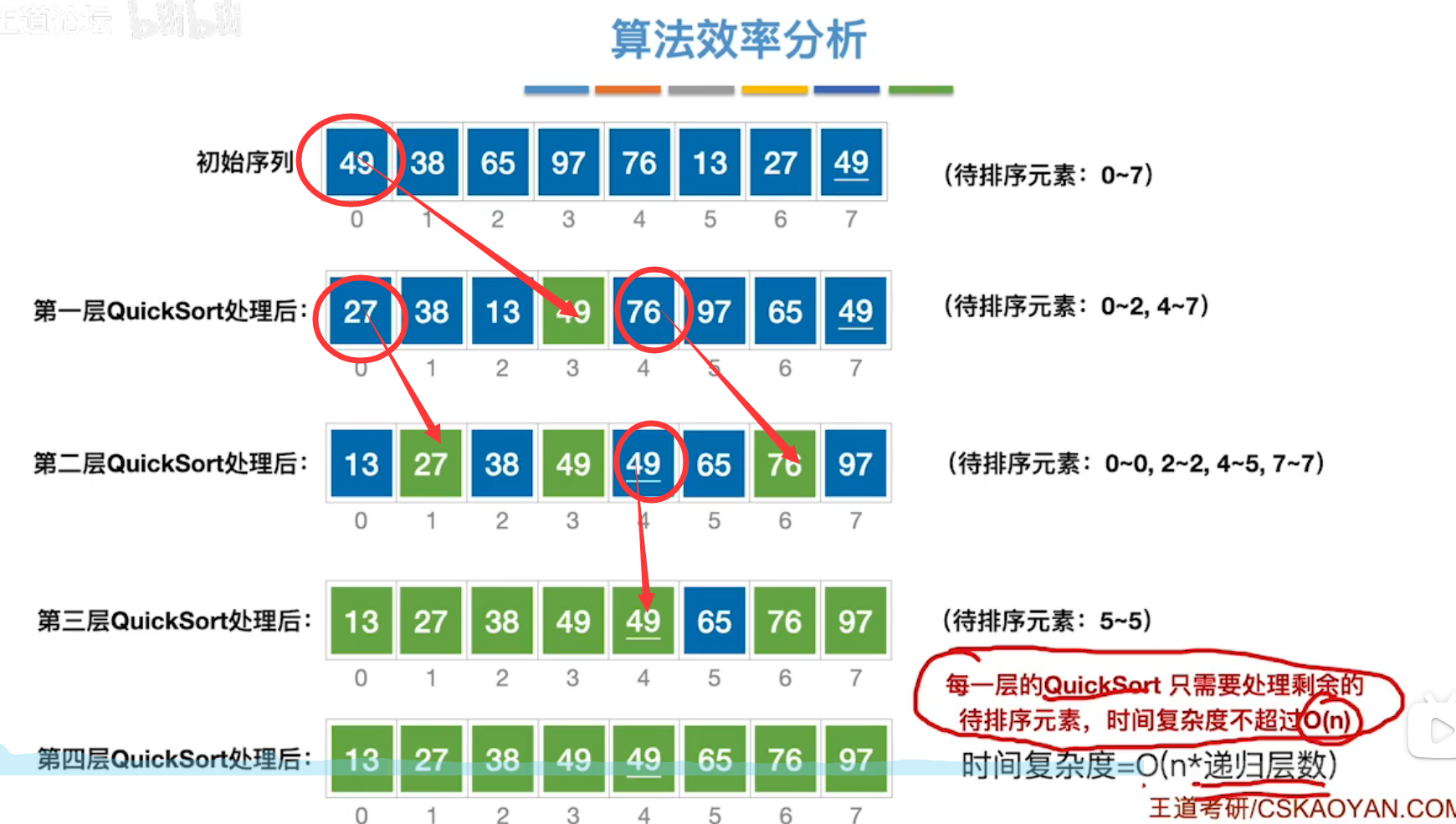
其过程相当于形成一颗二叉排序树
其递归调用的深度 = 二叉排序树的高度。(其中根节点为序列首个关键字,即枢轴元素)
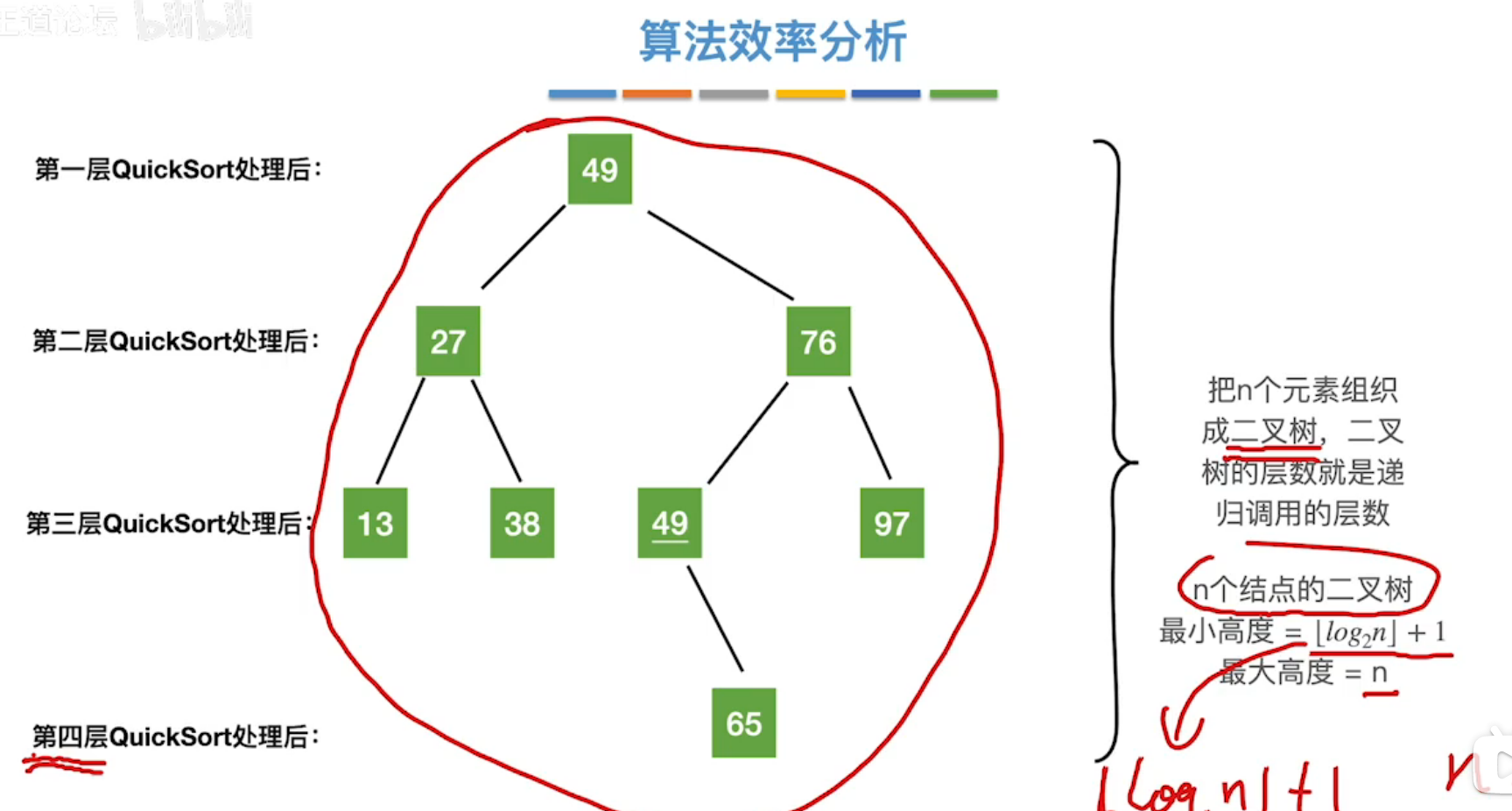
-
时间复杂度最坏的情况是:
- 序列本就有序,会进行n次递归调用。
- 时间复杂度:O(n2)。
-
时间复杂度最好的情况是:
- 其序列刚好形成一颗平衡二叉排序树,进行log2n次递归调用。
- 时间复杂度:O(nlog2n)。

优化:
若每一次选中的枢轴元素将待排序序列划分为均匀的两个部分,则递归深度最小,算法效率最高。
- 选头、中、尾三个位置的元素,取中间值作为枢轴元素。
- 随机选一个元素作为枢轴元素。
代码如下:(未优化版本)
void QuickSort(int a[], int low, int high) {
int OldLow = low;
int OldHigh = high;
if (low < high) {
int pivot = a[low];//用第一个元素作为枢轴元素。
while (low < high) {//循环结束时,必定low=high,为存放枢轴元素的位置。
while (low < high && pivot < a[high])//先从右往左 寻找比pivot小的元素x。
high--;
a[low] = a[high];//将元素x放到左端。
while (low < high && a[low] < pivot)//再从左往右 寻找比pivot大的元素y
low++;
a[high] = a[low];//将元素y放到右端。
}
a[low] = pivot;//此时low已经等于high。
//再分别对pivot左边序列和右边序列,进行递归的快速排序。
QuickSort(a, OldLow, low - 1);
QuickSort(a, low + 1, OldHigh);
}
}
5、简单选择排序
简单选择排序:每一趟在待排序元素中选择关键字最小的元素加入有序序列中。不稳定。
时间复杂度:O(n2)。

只需要进行n-1次排序。
代码如下:
//简单选择排序
void SelectionSort(int a[], int n) {
for (int i = 0; i < n - 1; i++) {//注意这里i<n-1
int min = i;
for (int j = i + 1; j < n; j++) {//注意这里j=i+1
if (a[j] < a[min]) {
min = j;
}
}
int temp = a[i];
a[i] = a[min];
a[min] = temp;
}
}
6、堆排序
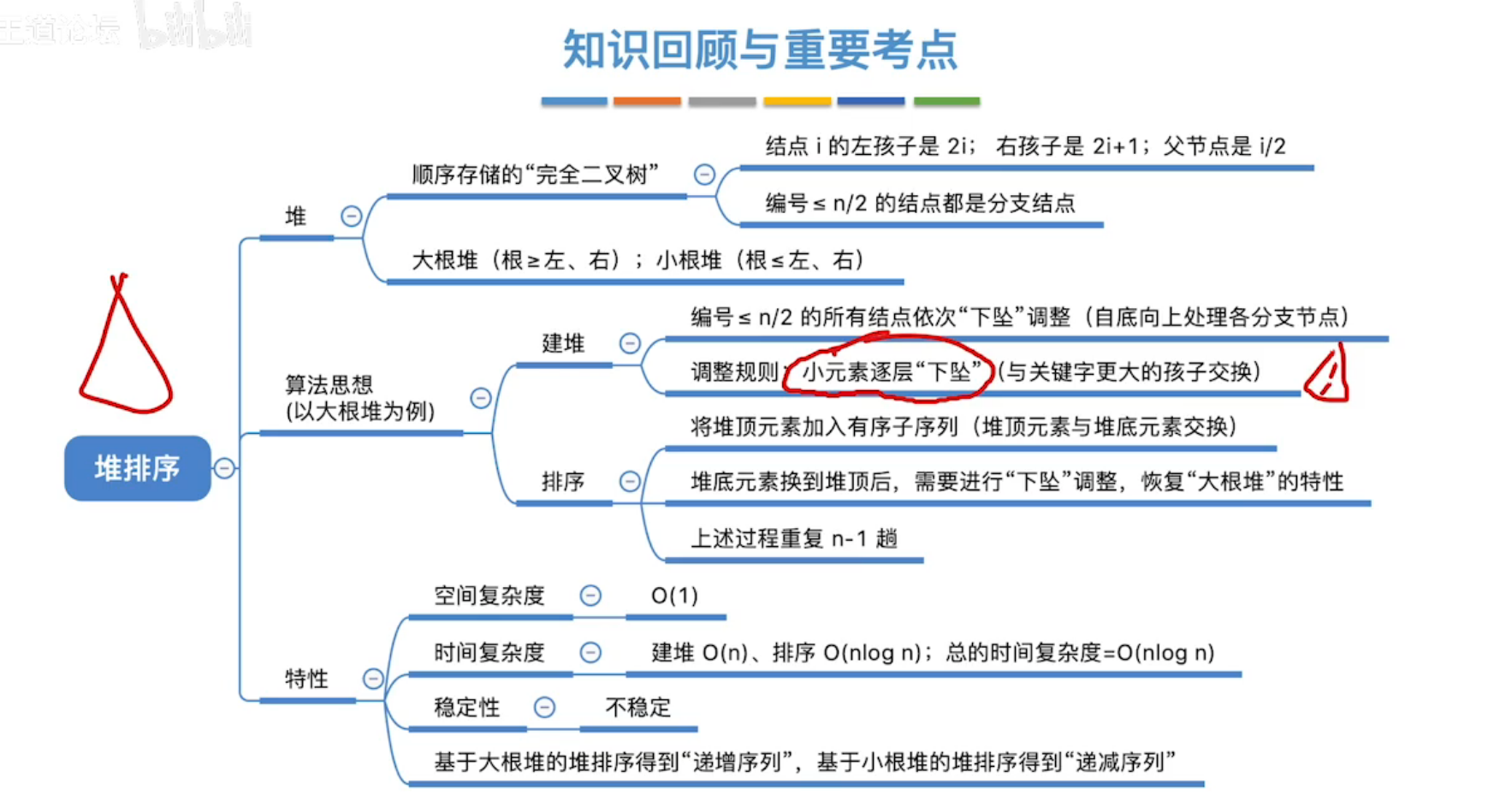
堆排序有点抽象,可直接看原视频:B站王道数据结构:堆排序
堆:将顺序存储的序列,看作一个完全二叉树,序列首个元素为根节点。
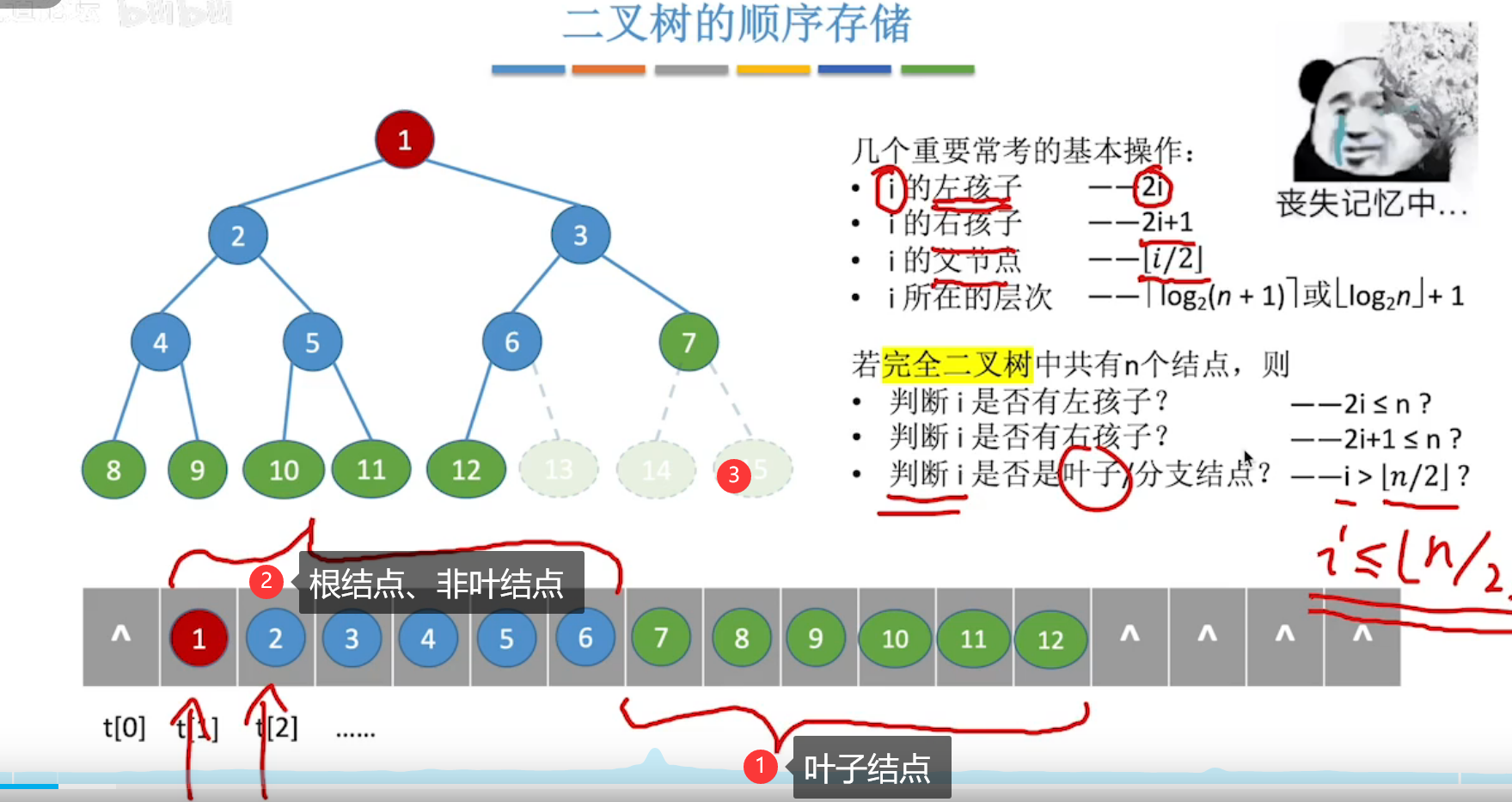
- 完全二叉树具有特性(第一个结点下标为1,不是0):
结点i的左孩子下标为2i,右孩子下标为2i+1,父结点下标为[i/2](向下取整)。结点i是否有左孩子:2i<=n?是否有右孩子:2i+1<=n?结点i是否为叶节点:i >[n/2](向下取整) ?
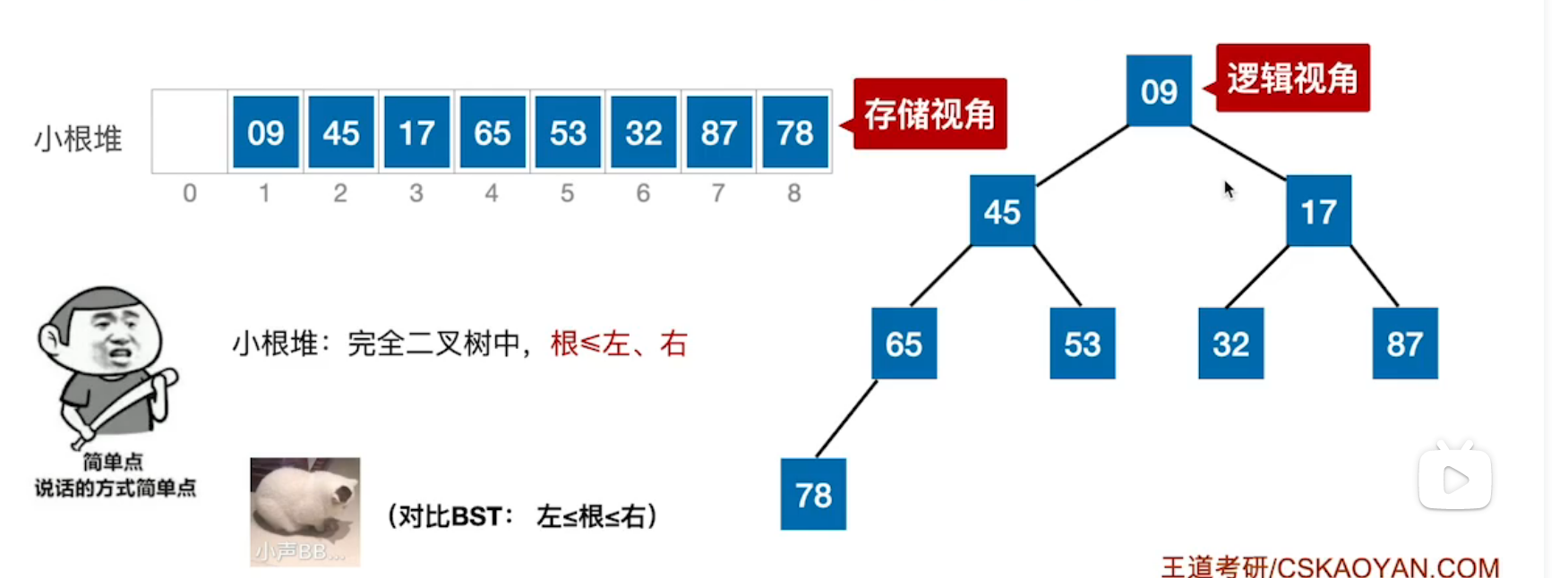
| 大根堆 | 小根堆 |
|---|---|
| 根 >= 左孩子、右孩子,根结点必定为二叉树中最大结点,且所有结点的子树同为大根堆。 | 根 <= 左孩子、右孩子,根结点必定为二叉树中最小结点,且所有结点的子树同为小根堆。 |
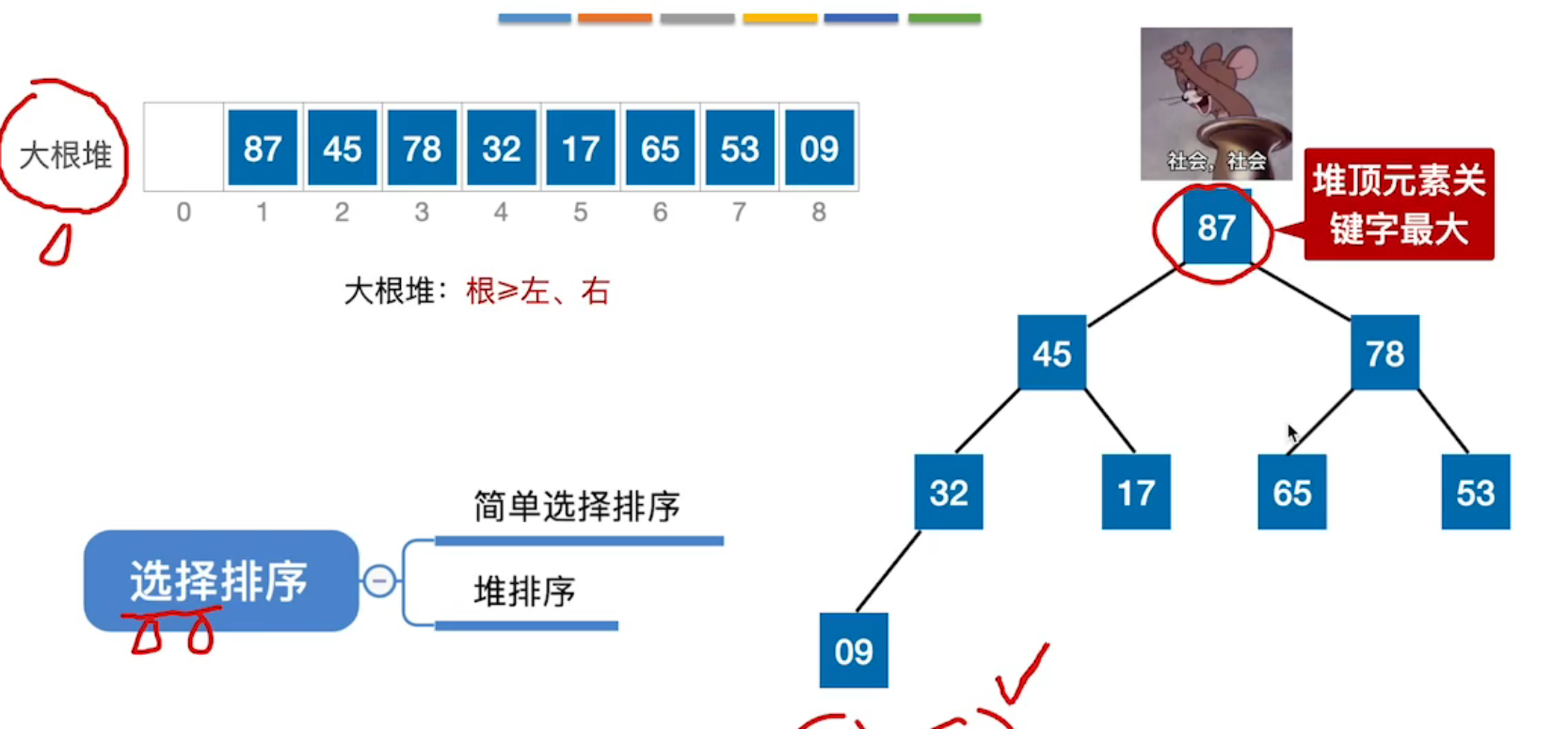 |  |
堆排序属于选择排序
- 选择排序思想:每次选择一个最值,依次放入一端,最终形成一条有序序列。
所以
- 堆排序过程是:每次将无序序列建立为大根堆(小根堆),取根结点(必为最值)放入右端形成有序序列,再次调整左端无序序列为大根堆(小根堆),又取根节点放到右端有序序列,以此往复,最终整体有序。
基于大根堆的排序过程如下:
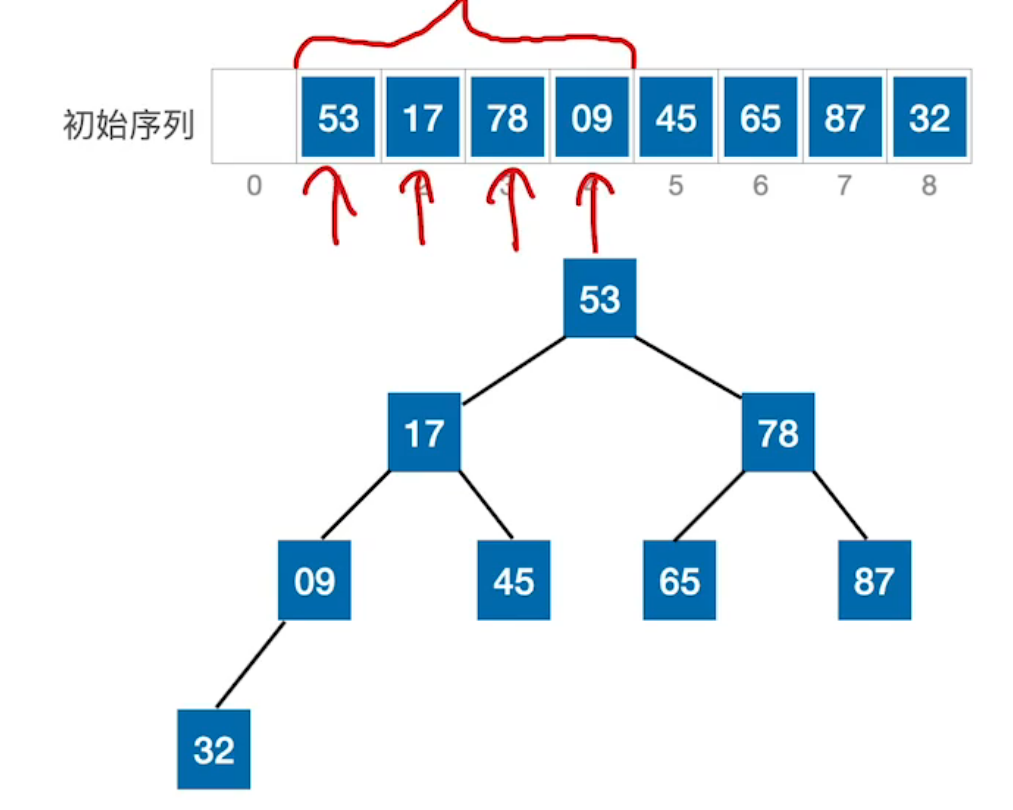
| 首先,获得初始序列,将其逻辑结构看作完全二叉树。 | 第一步:先对无序序列 建立起大根堆 |
|---|---|
 | 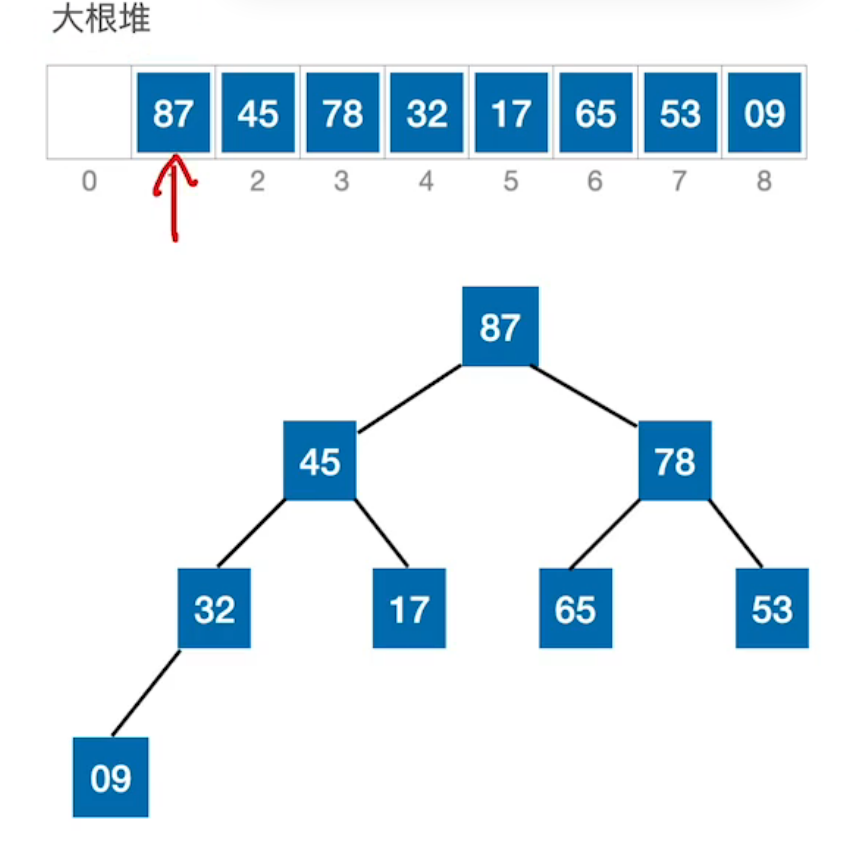 |
| 第二步:再取根结点放入右端(与末尾结点互换),形成有序序列。 | 第三步:再次将左端无序序列调整为大根堆 |
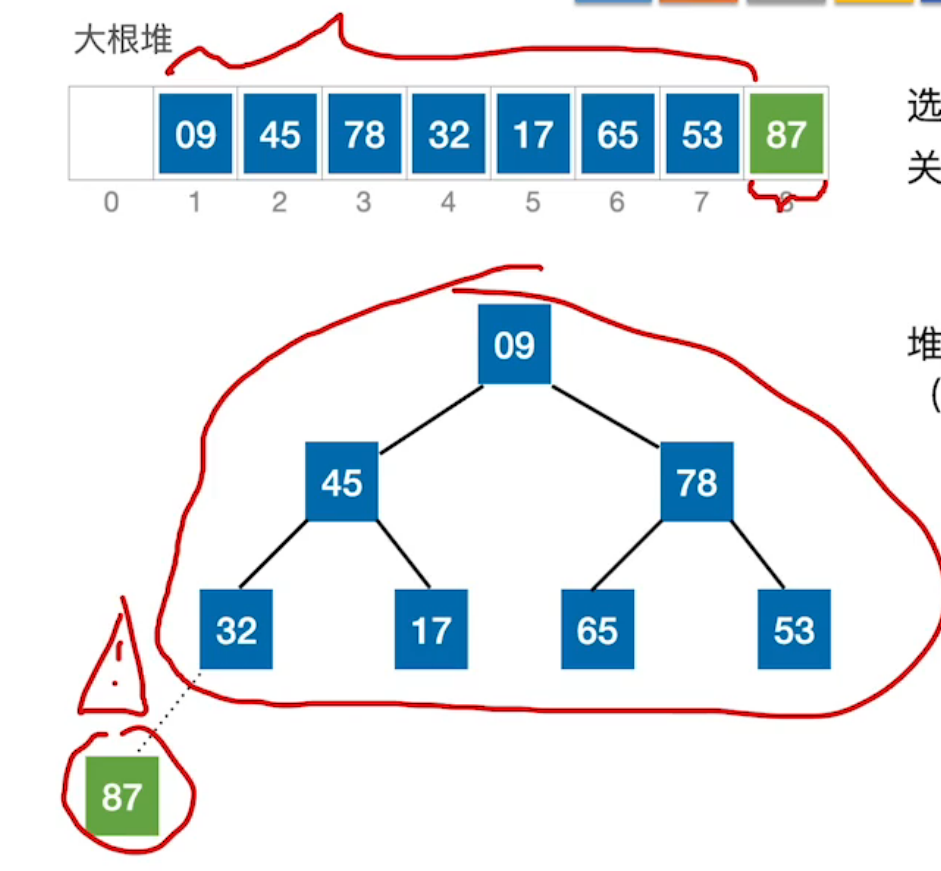 | 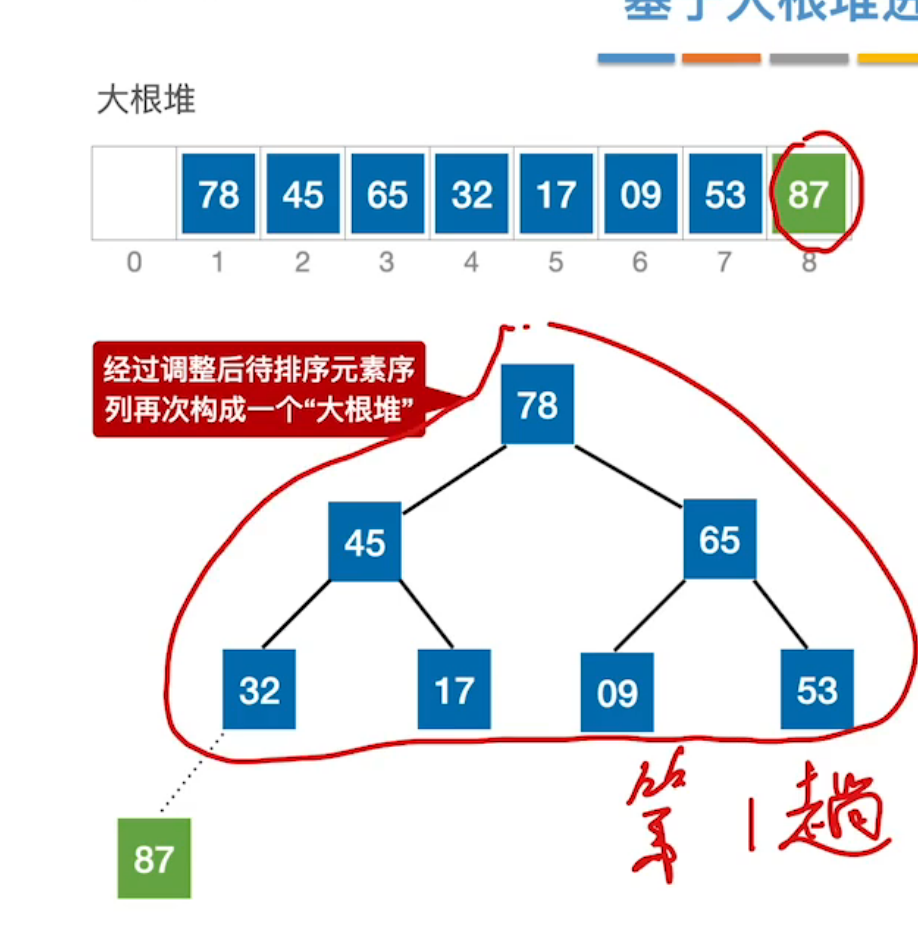 |
| 第四步:又取根结点与末尾结点互换。 | 第五步:不断重复第三步和第四步,直至整体有序。 |
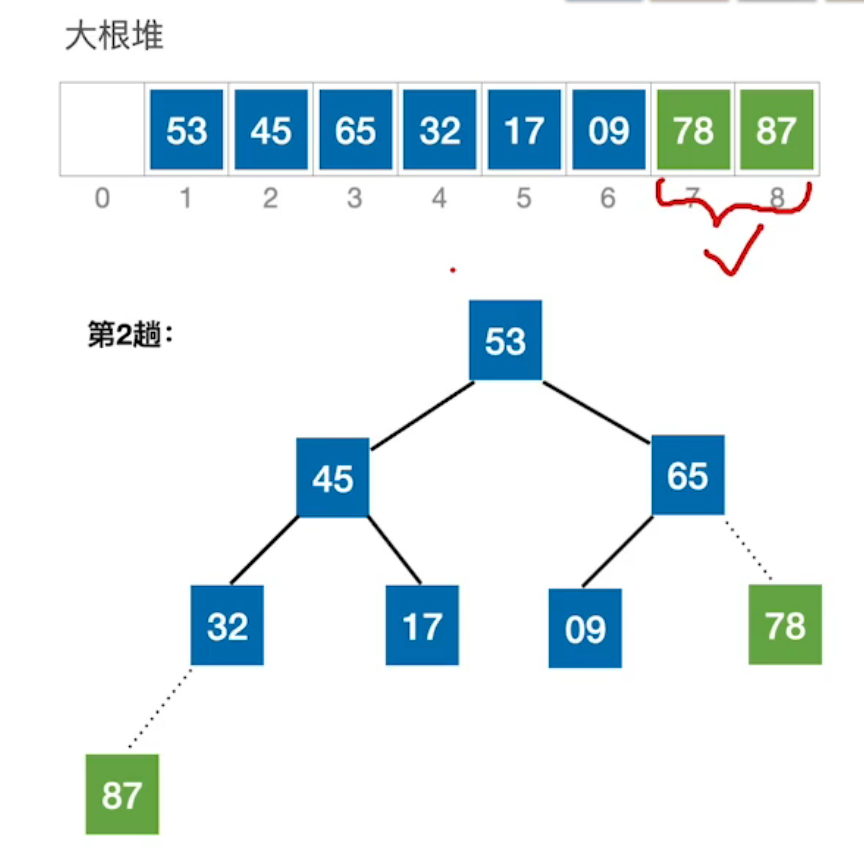 | 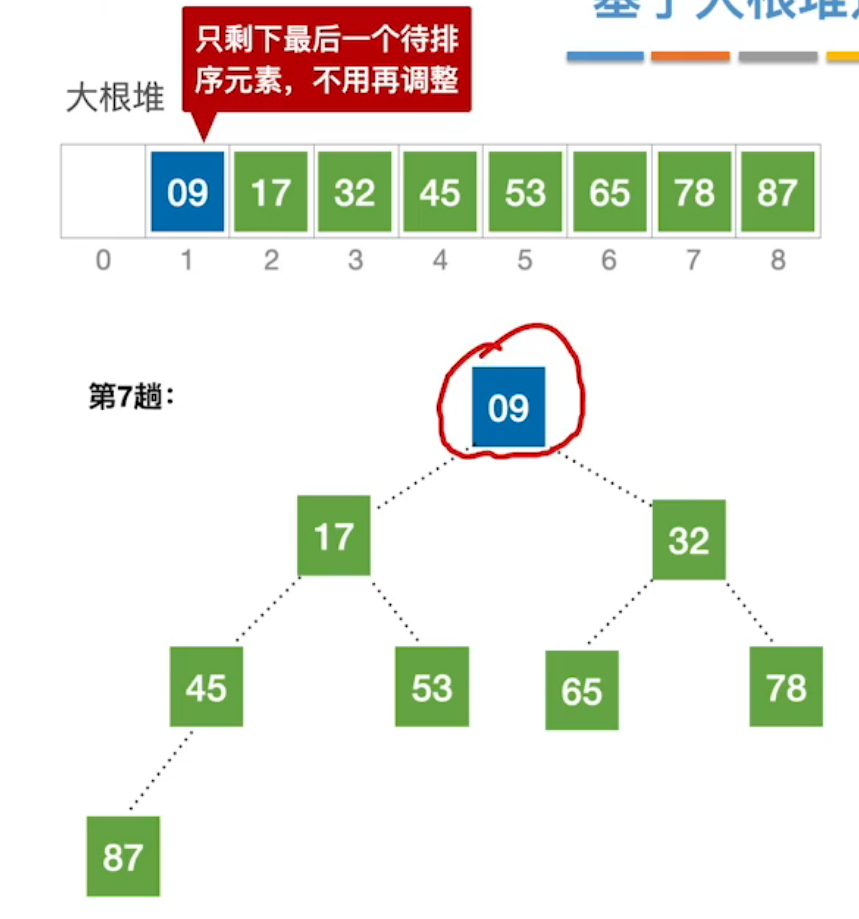 |
所以,堆排序的重点是:如何建立并调整大根堆(小根堆)。
-
大根堆建立过程:从最后一个非叶结点(下标
i=[n/2]向下取整)开始,调整根结点和叶结点形成大根堆,又对到倒数第二非叶结点(下标i-1)调整为大根堆,同样操作,依次i--,整体过程为从下往上建立。 -
大根堆调整过程:此过程发生在大根堆的根节点与尾结点互换后,此时从上往下,不断将根结点与其子结点比较大小互换(子结点必是子树的最值),依次往复,将整个树调整为大根堆。
这过程称之为(根节点不断下坠的过程)。
时间复杂度:O(nlog2n)。
细节讲不明白了,看这里。。。。:B站王道数据结构:堆排序
完整代码如下:
说明:我自定义待排序数组a[],存储的元素起始结点下标为0,但为了操作方便,进入HeapSort函数后会将其起始下标映射为1,且后序操作中不会涉及a[0]。
//堆排序完整逻辑,参数中数组a的起始下标为0。
void HeapSort(int a[], int n);
//建立大根堆
void BuildMaxHeap(int a[], int n);
//将以k结点为根的子树调整为大根堆
//从根结点开始向下每层比较,若根节点小于其子结点,则互换,直至该结点大于子结点。
void HeapAdjust(int a[], int k, int n);
//堆排序完整逻辑,参数中数组a的起始下标为0。
void HeapSort(int a[], int n) {
a--;//将起始下标为零的数组映射为起始下标为1
//但后序操作过程中并不会用到a[0],
BuildMaxHeap(a, n);//初始建堆
for (int i = n; i > 1; i--) {//n-1趟的交换和建堆过程
int temp = a[i];//交换堆顶元素和堆底元素
a[i] = a[1];
a[1] = temp;
HeapAdjust(a, 1, i - 1);//把剩下待排序的元素调整为大根堆。
}
}
//建立大根堆
void BuildMaxHeap(int a[], int n) {
for (int i = n / 2; i > 0; i--) {//从下往上调整所有非终结点。
HeapAdjust(a, i, n);
}
}
//将以k结点为根的子树调整为大根堆
//从根结点开始向下每层比较,若根节点小于其子结点,则互换,直至该结点大于子结点。
void HeapAdjust(int a[], int k, int n) {
if (n <= 1) {
return;
}
int temp = a[k];//暂存子树的根节点。
for (int i = 2 * k; i <= n; i *= 2) {//i=2*k,表示为i的左子结点。
if (i < n && a[i] < a[i + 1])//i<n,等价于i+1<=n,表示有右子树,取较大的子结点下标
i++;//a[i]<a[i+1]时表示左子树小于右子树
if (temp > a[i]) {//满足大根堆,根结点大于子结点。
break;//此时说明原始根结点已经下坠到合适位置。
}
else {
a[k] = a[i];//每次取最大的子结点,与当前根节点互换。
k = i;//调整根节点为互换的位置;
//再次回到循环,检查k=i后的根节点是否也满足大根堆,
//直至跳出循环
}
}//每轮的k都会代表当前子树的根结点。
a[k] = temp;//最后的k表示合理的位置,
}
同理小根堆算法(得到一个递减的有序序列),与大根堆算法只有两处不同,代码如下:
//小根堆排序算法,得到一个递减的有序序列
void MinHeapSort(int a[], int n) {
a--;
BuildMinHeap(a, n);
for (int i = n; i > 1; i--) {
int temp = a[i];
a[i] = a[1];
a[1] = temp;
MinHeapAdjust(a, 1, i-1);
}
}
void BuildMinHeap(int a[], int n) {
for (int i = n / 2; i >= 1; i--) {
MinHeapAdjust(a, i, n);
}
}
void MinHeapAdjust(int a[], int k, int n) {
if (n <= 1)
return;
int temp = a[k];
for (int i = k * 2; i <= n; i *= 2) {
if (i + 1 <= n && a[i] > a[i + 1])//小根堆,取左右子结点最小值。
i += 1;
if (temp > a[i]) {//小根堆,将较大值的根节点不断下坠,换上小值的子结点作为新的根节点。
a[k] = a[i];
k = i;
}
else {
break;
}
}
a[k] = temp;
}
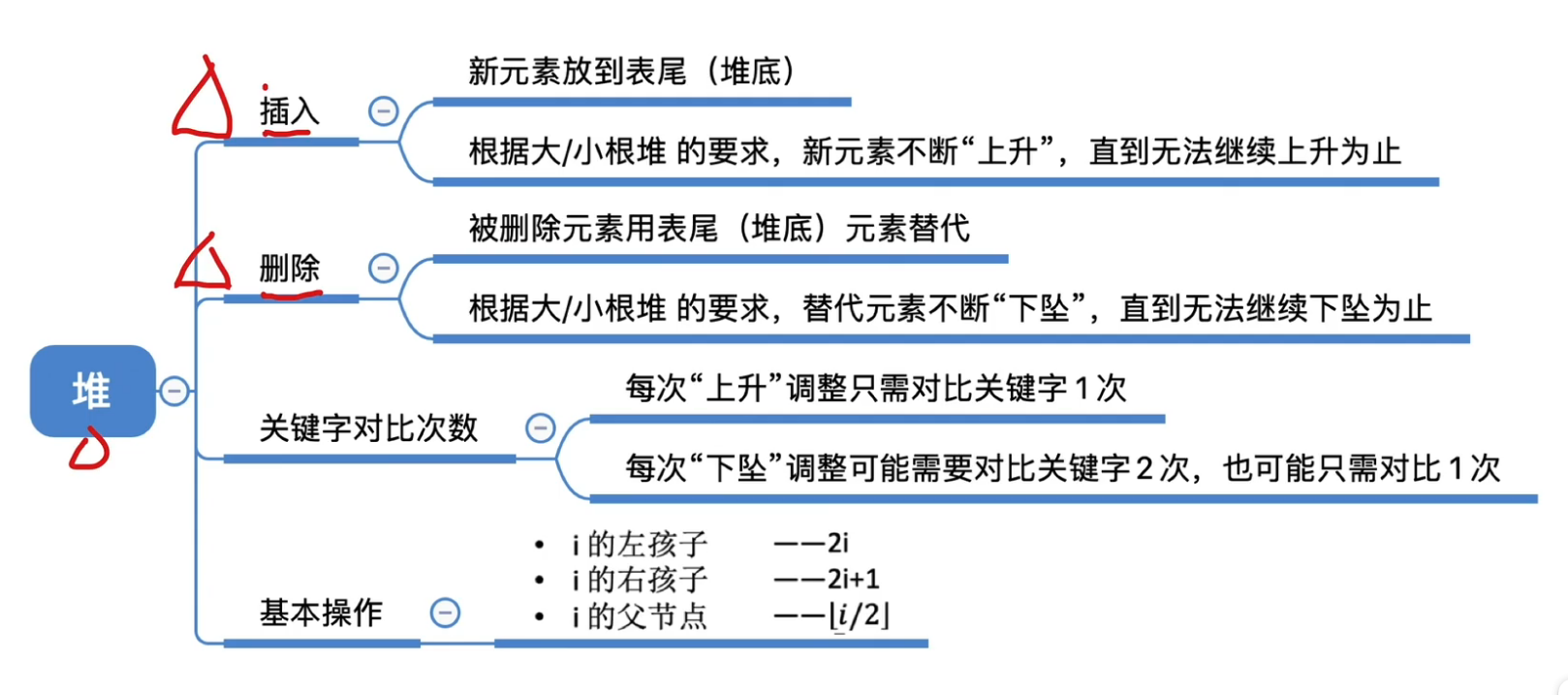
补充:堆的插入和删除
7、归并排序
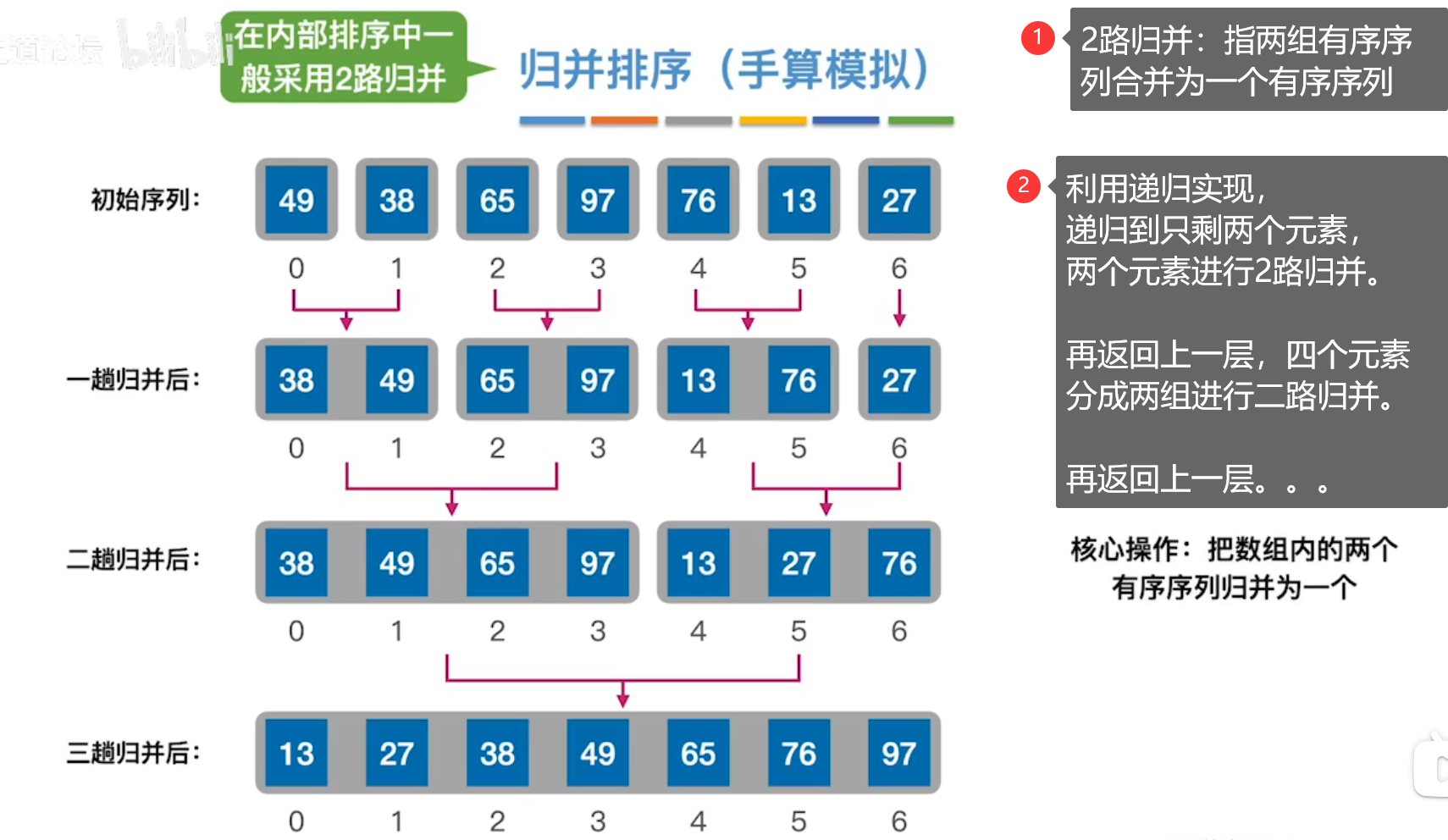
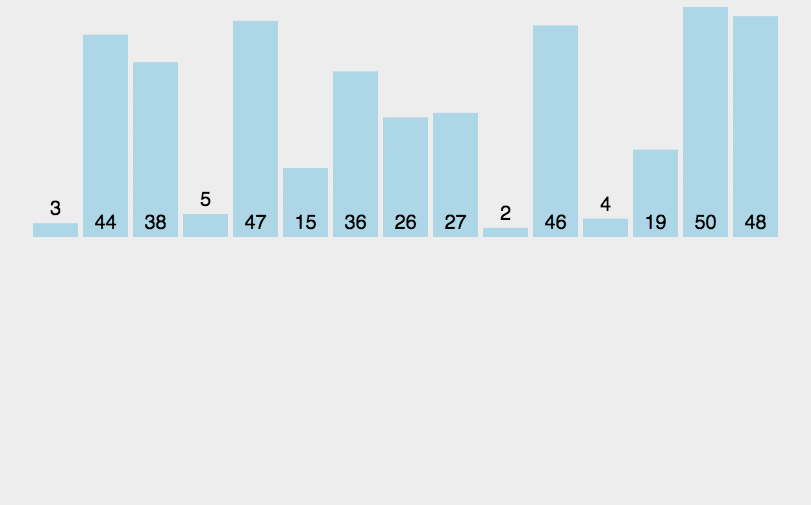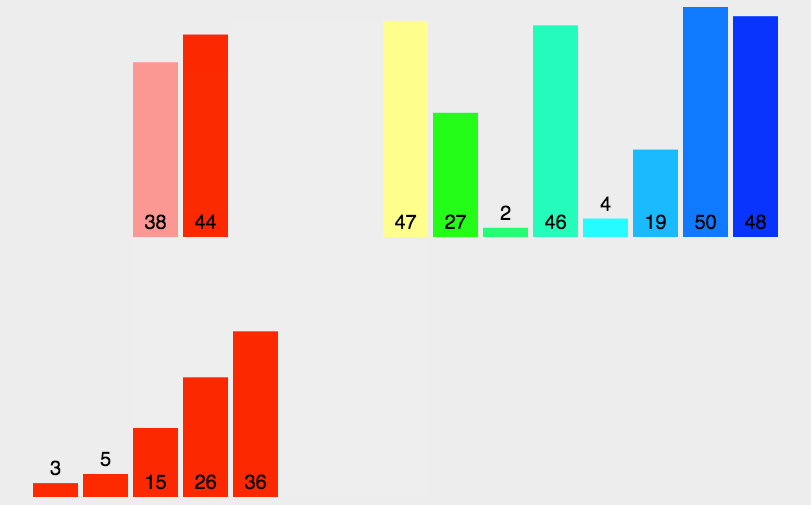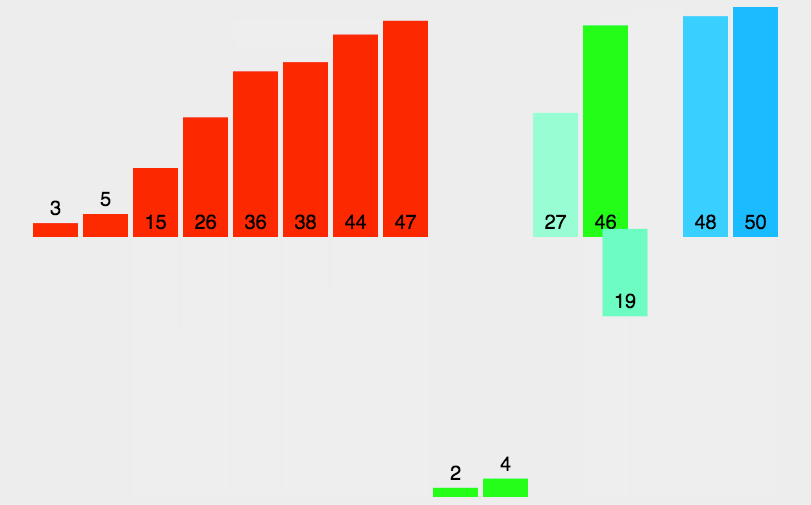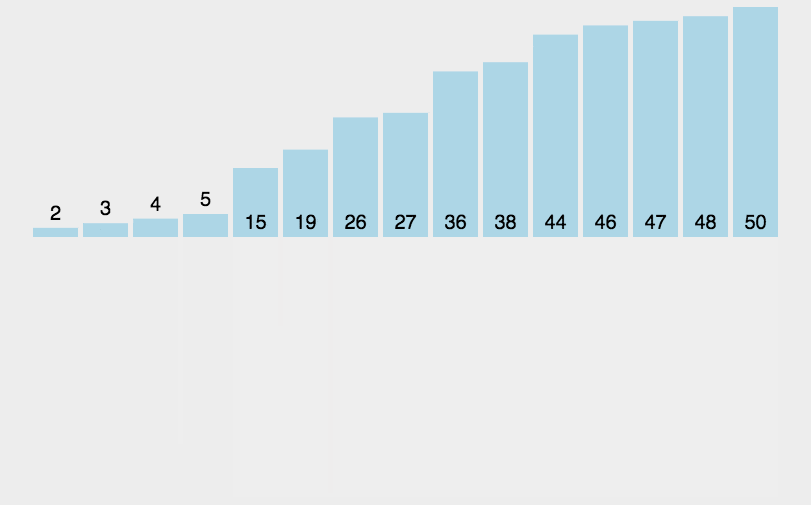
时间复杂度:O(nlog2n)。具有稳定性。
代码如下。
//归并排序
//对数组下标low到high(包含low和high)部分进行归并排序。
void MergeSort(int a[], int low, int high) {
if (high > low) {
int mid = low + (high - low) / 2;
MergeSort(a, low, mid);
MergeSort(a, mid + 1, high);
//经过上面两个归并后,将数组a分为[low,mid]和[mid+1,high]两部分,且都为有序。
//以下是对两个有序序列,二路归并的过程。
int i = low;
int j = mid + 1;
int* b = (int*)malloc(sizeof(int) * (high - low + 1));//辅助排序的数组
int k = 0;
while (i <= mid && j <= high) {
if (a[i] > a[j])
b[k++] = a[j++];
else
b[k++] = a[i++];
}
while (i <= mid)
b[k++] = a[i++];
while (j <= high)
b[k++] = a[j++];
//此时b中存储的序列有序。将其复制到数组的位置[low,high]中。
k = 0;
for (int i = low; i <= high; i++)//将排序好的有序序列复制到a数组中。
a[i] = b[k++];
free(b);
}
}
8、基数排序
基数排序不是基于比较的排序算法。具有稳定性。
比较神奇,说不明白。。。:B站王道数据结构:基数排序
口诉基数排序逻辑:
- 将待排序列分别安个、十、百……位进行分类,分类之后从高位向下回收队列,得到一个以个(十、百……)位递减的序列。
- 又进行下一趟按十(百、千……)位进行分类,重复刚才的动作,由于是在第一趟的基础上分类回收,得到的按十位递减的序列中,若十位相等,则其个位必定递减。
- 又进行下一趟按百位分类……,
- 最终得到一个递减的序列
| 基数排序动画过程如下: | ~ |
|---|---|
| 原始序列,第一趟按照“个位”进行分配。 | 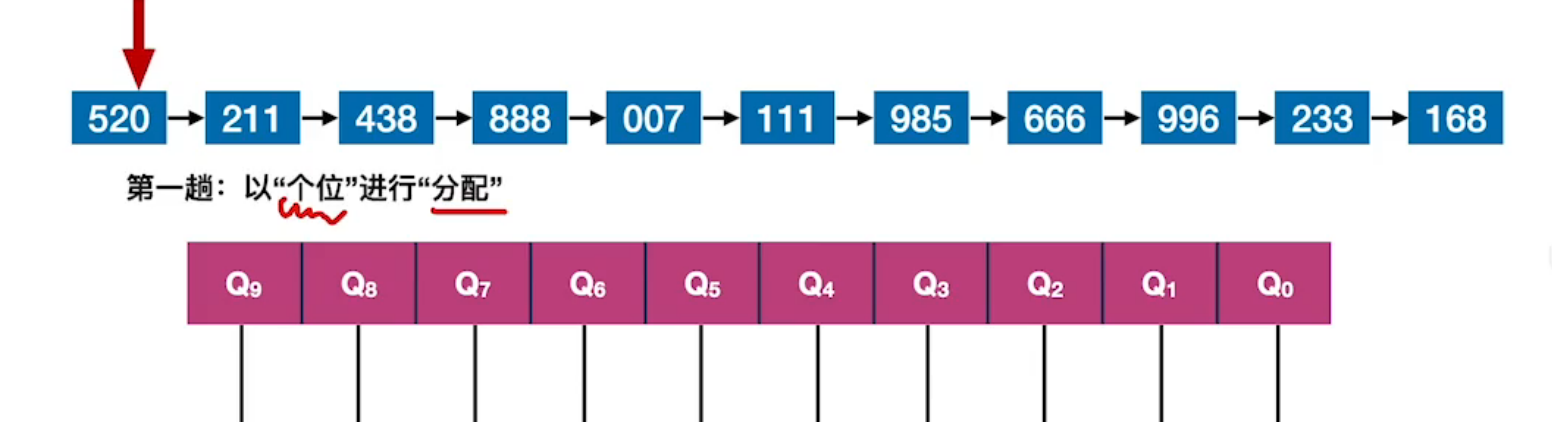 |
| 第一趟分类完成。 | 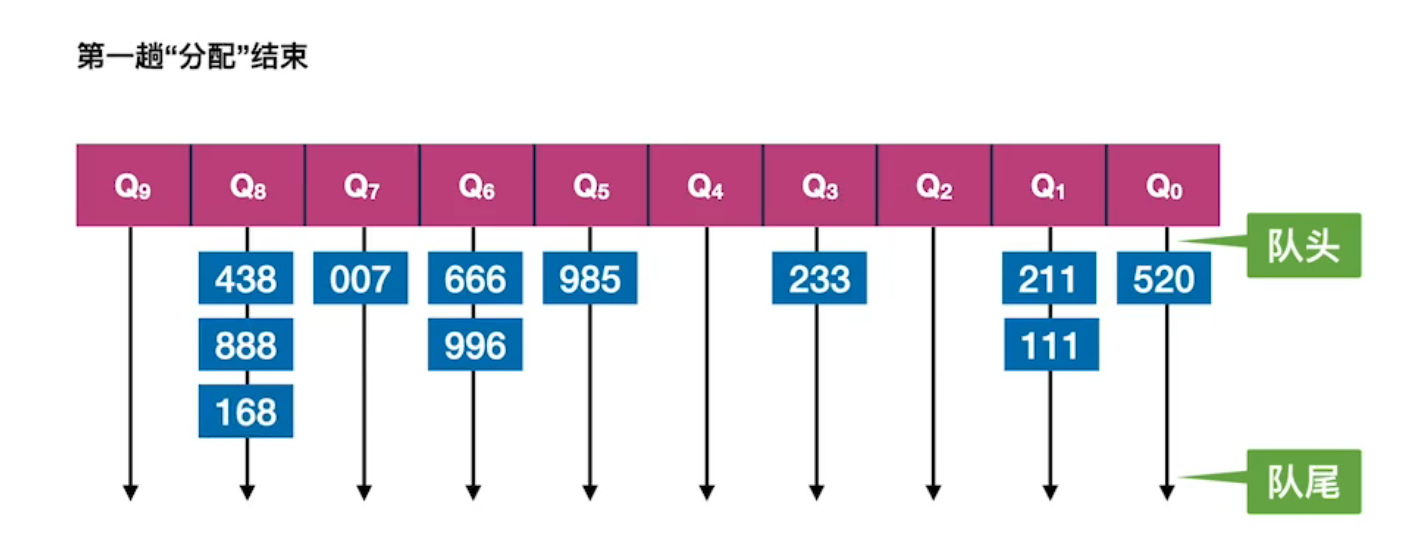 |
| 第一趟回收,得到一个按“个位”递减的序列。 |  |
| 第二趟按“十位”进行分类,由于有了第一趟分类,使“十位"相同的分组内部,其个位递减。 (因为入队时,个位越大的越先入队列) | 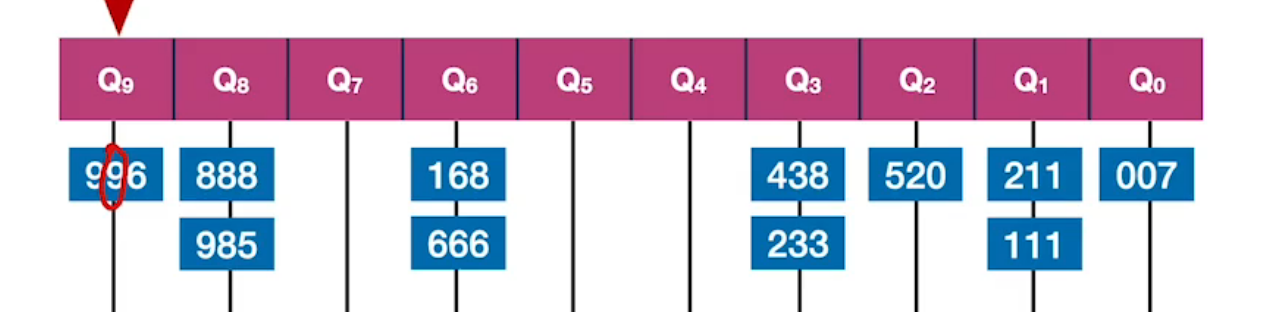 |
| 第二趟回收,得到一个按”十位“递减的序列, |  |
| 第三趟,按”百位“分类 同样,”百位“相同的分组内,其”十位“是递减的。 | 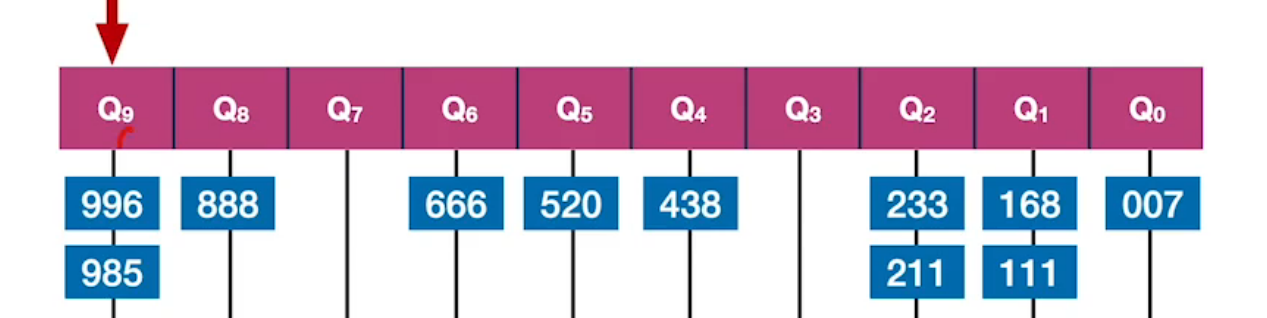 |
| 第三趟回收,最终得到一个整体有序的降序序列。 |  |
算法分析,
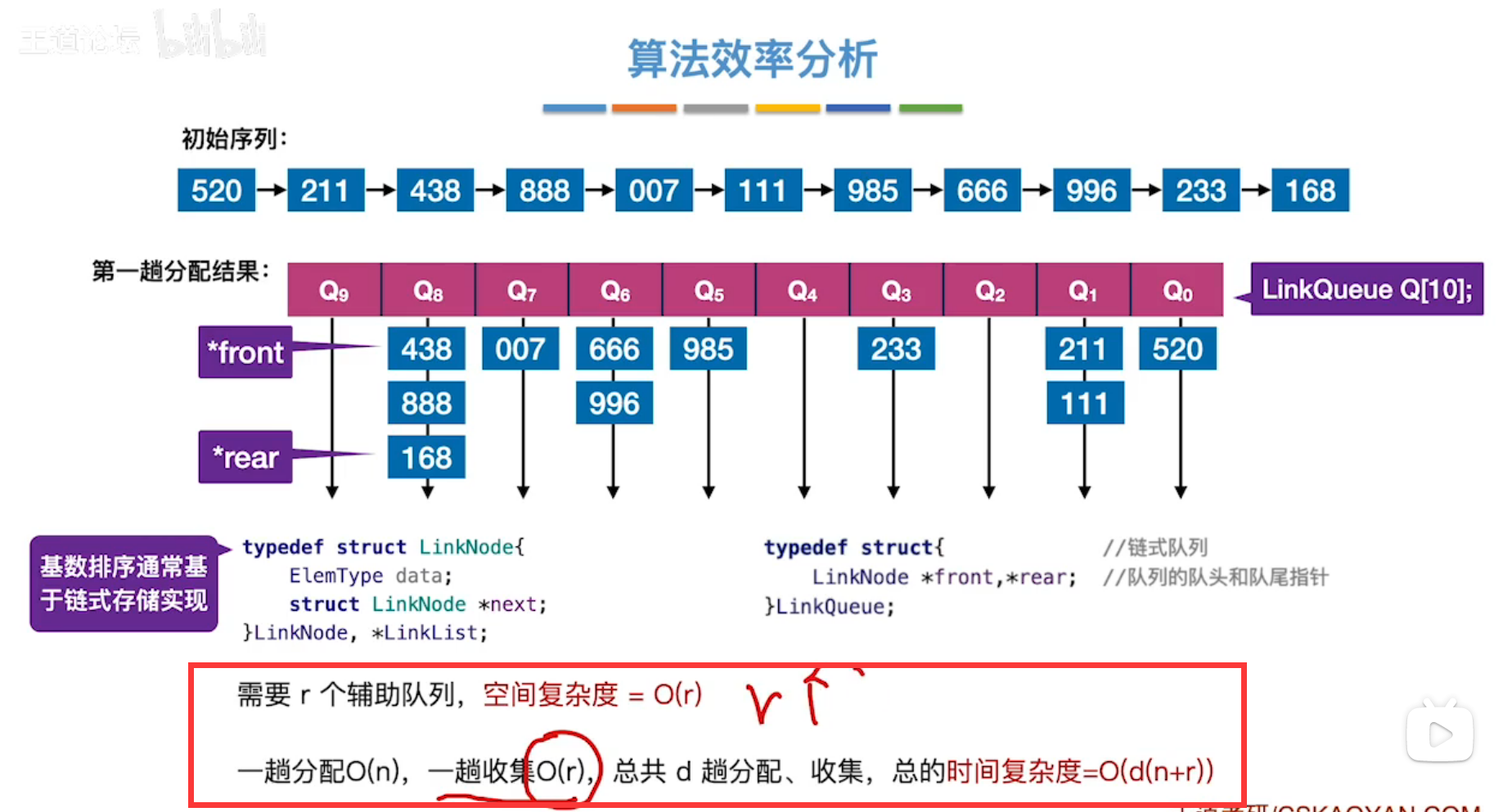
n表示待排序列中关键字个数。
r表示辅助队列的数列(上图0~9,10个辅助队列)。
d表示d趟分配、回收(其实就是最大关键字的”个十百千……“位有多少位,上图最大关键字996,只有"个十百",则d=3)。
所以时间复杂度:O(d*(n+r))。
当n越大、r和d越小的前提下,基数排序的时间复杂度远低于其他排序算法。
-
扩展:用于日期的排序。
-
总共进行三趟分类、回收,分别对应日、月、年,故d=3。
-
按年分类时,年份分布于1991~2005,此时辅助队列数量r=15。
-
按月份分类时,辅助队列数量r=12。
-
按日(号数)分类时,辅助队列数列r=31。
-
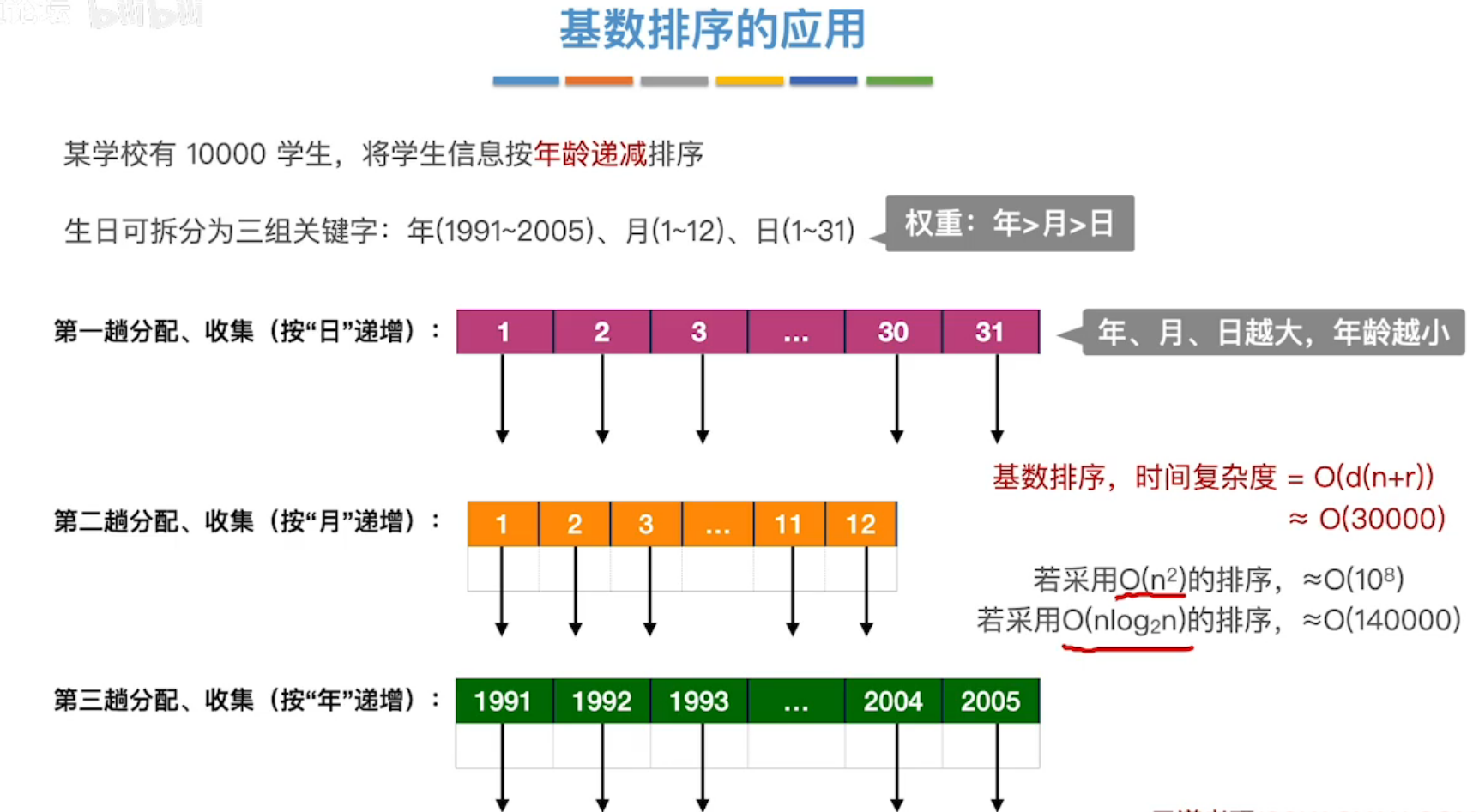
此时,如果待排序列(学生数量)很多时,基数排序比其他算法(O(nlog2n))优秀。
9、计数排序

重点是这里多了一个累计数组
细节原理可以看这个视频:排序算法:计数排序【图解+代码】
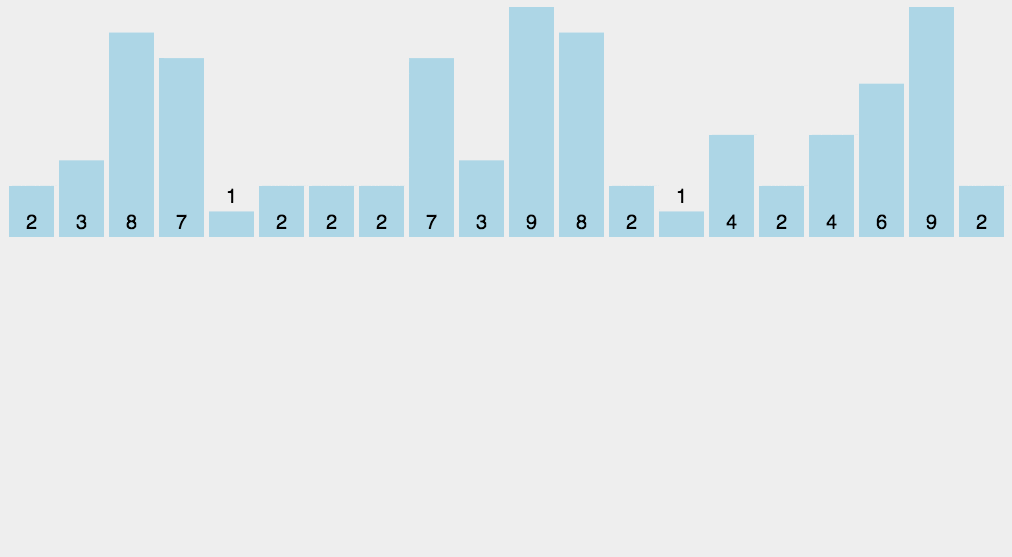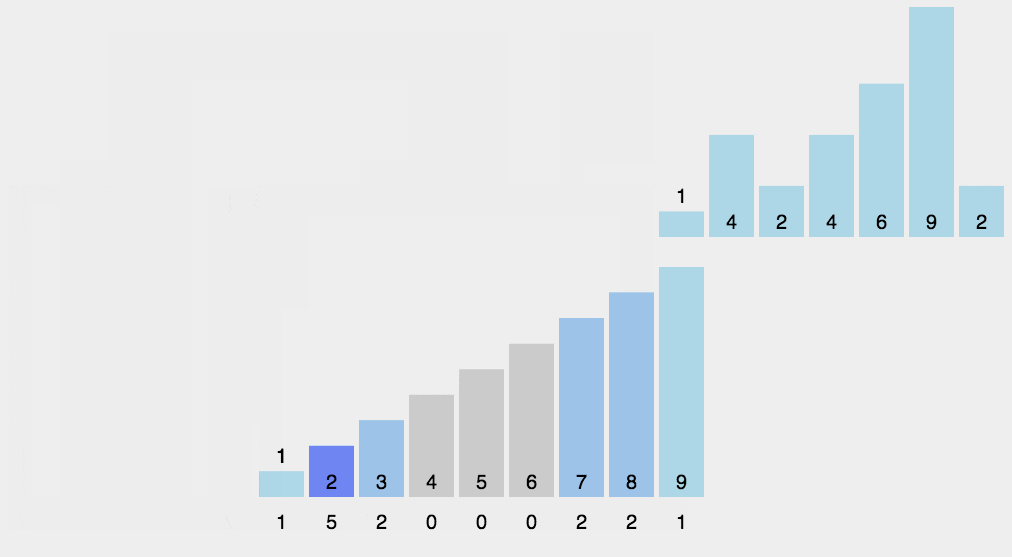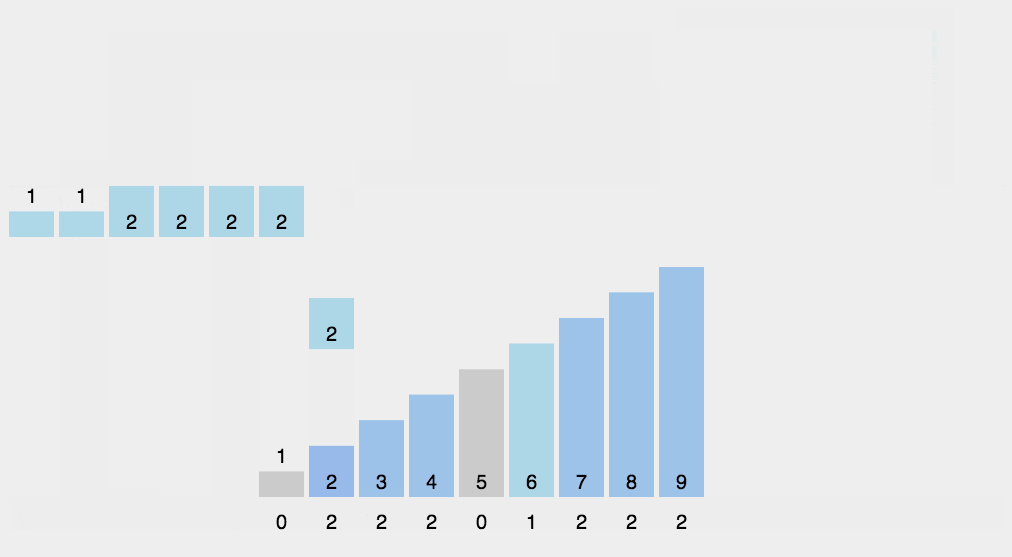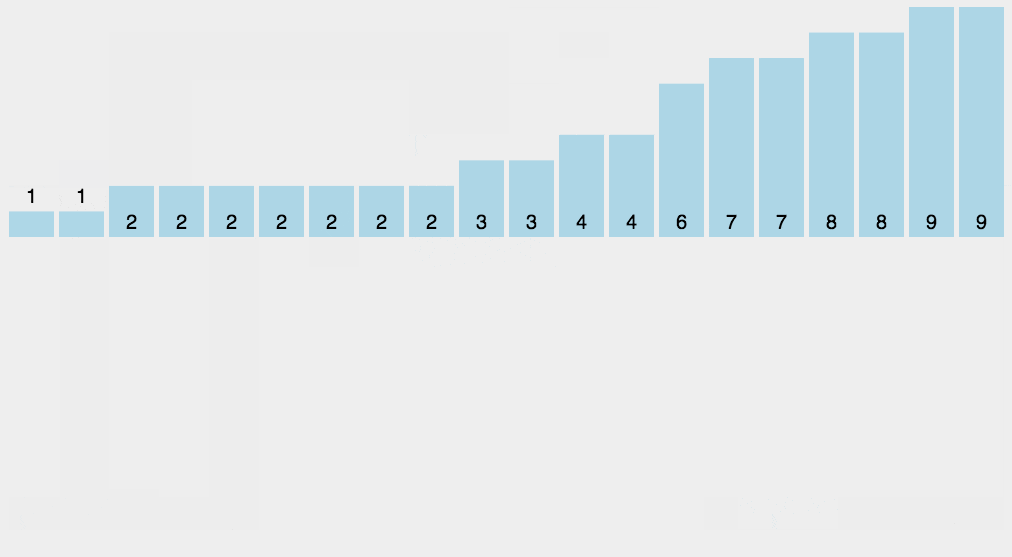
10、桶排序
在计数排序的基础上优化。
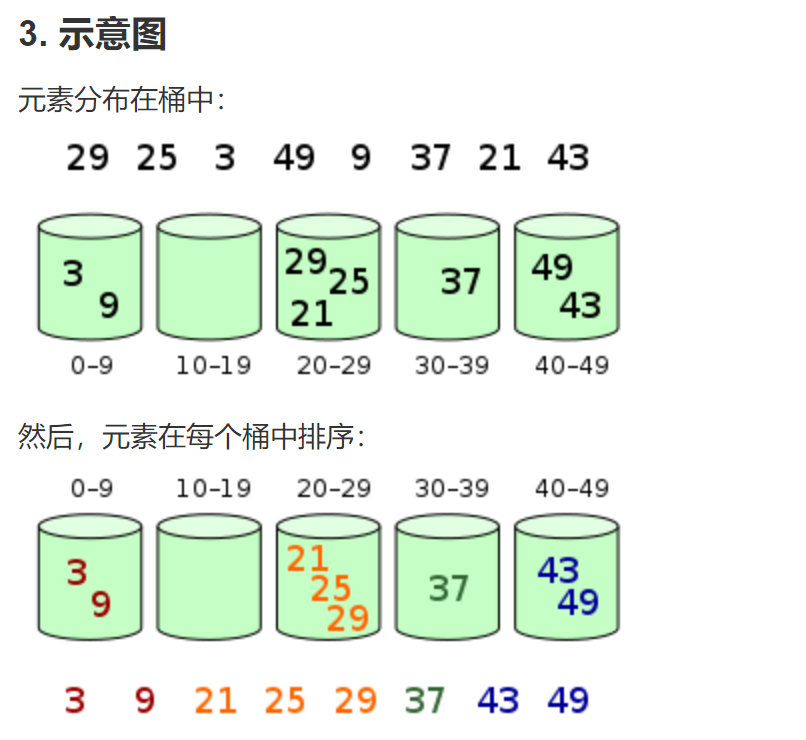
即:初始多个桶,将待排序列进行预先分类,例如:0~30为放入一号桶中, 31~60放入二号桶中, 61~100放入三号桶中……再分别对各个桶内进行排序,最后依次输入一号通序列,二号桶序列、三号桶序列……最终得到有序序列。(桶内排序可以使用任意算法)。
11、外部排序
(1)外部排序
将数据从外部磁盘读取到内存的输入缓冲区。
在内存缓冲区中进行K路归并,放到输出缓冲区中,由输出缓冲区输出到外部磁盘。
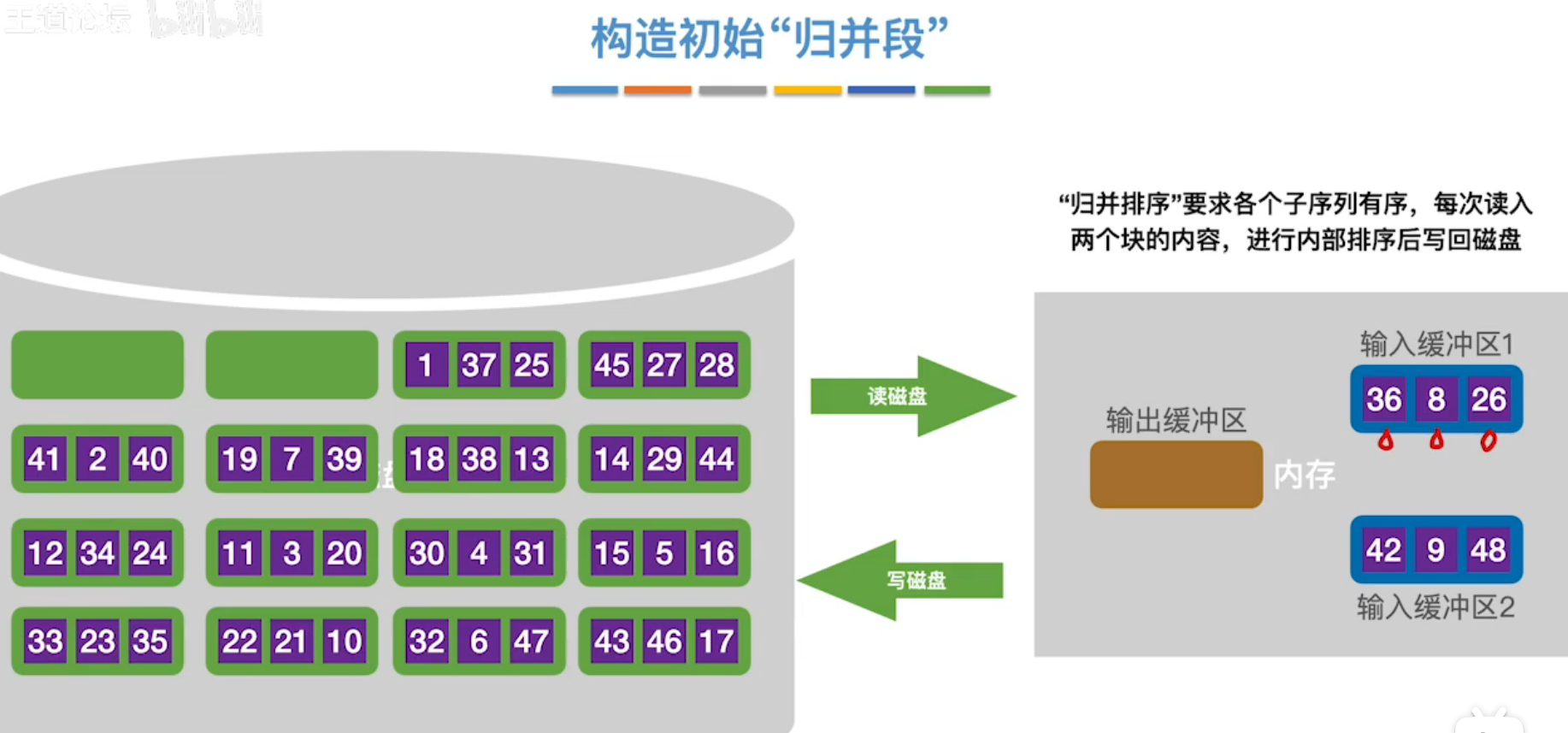
时间开销:主要来源于读写磁盘的次数。
所以,优化思路:增加一次性读取磁盘的内容到内存中,进行k路归并(k越大),或者增大输入输出缓冲区的大小。
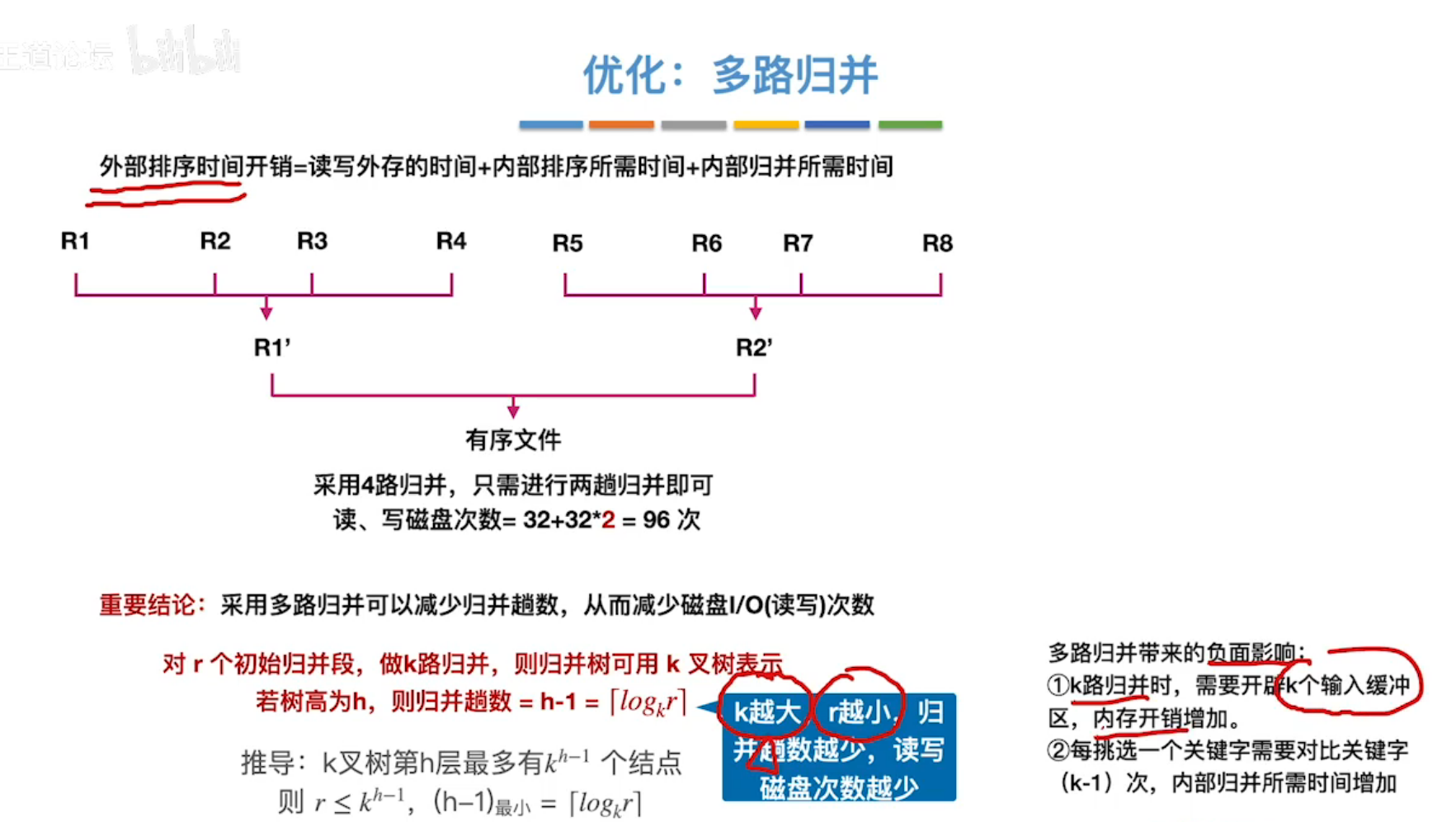
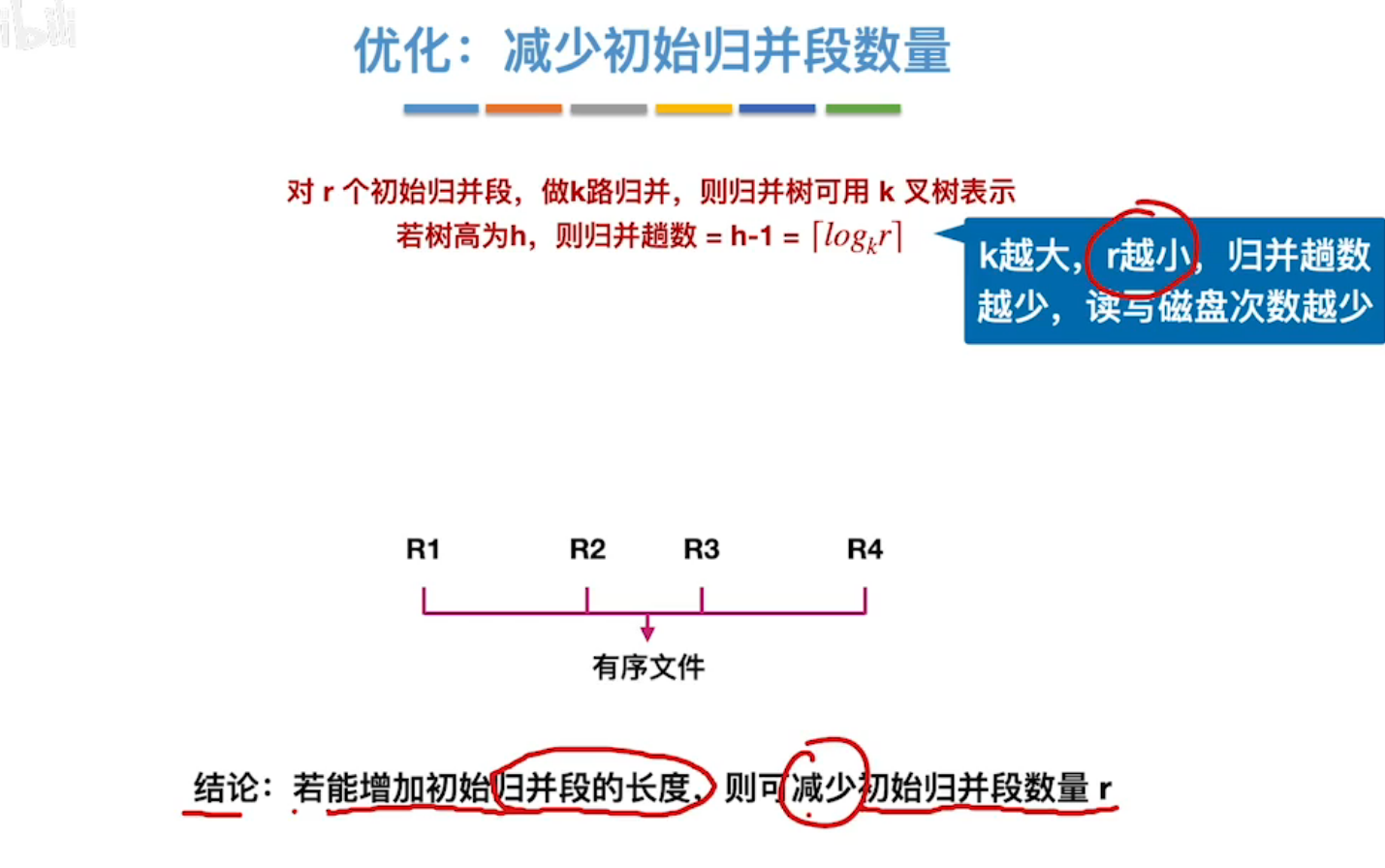
对于r个初始归并段(r个存储待排序关键字的磁盘块),做k路归并,则归并树可用k叉树表示,若树高为h,则归并趟数=h-1=[logkr]
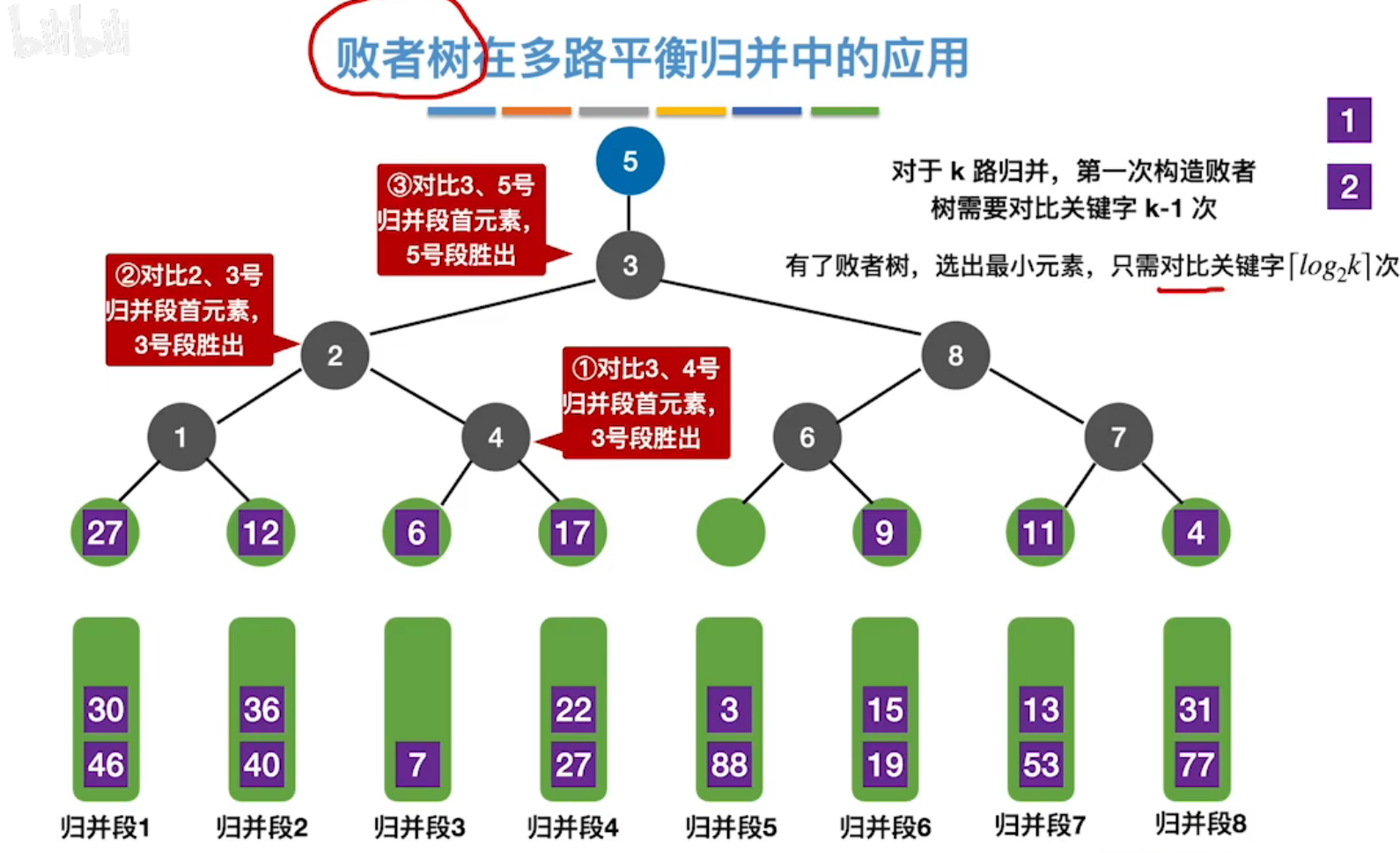
(2)败者树
k路归并,若有了败者树,每轮关键字对比,只需要**[log2k]**次。
(3)置换选择排序
用于构造更长的初试归并段。
(4)最佳归并树
最佳归并树,用于优化外部排序中的读写磁盘的I/O时间,类似哈夫曼树的思想。
绿色结点的权值代表存储待排序关键字的磁盘块数量。合并为蓝色结点,代表k路归并之后的结果。
使权值最低的放在底层叶节点,最终计算的带权路径长度最佳。
这里的带权路径长度相当于磁盘I/O次数
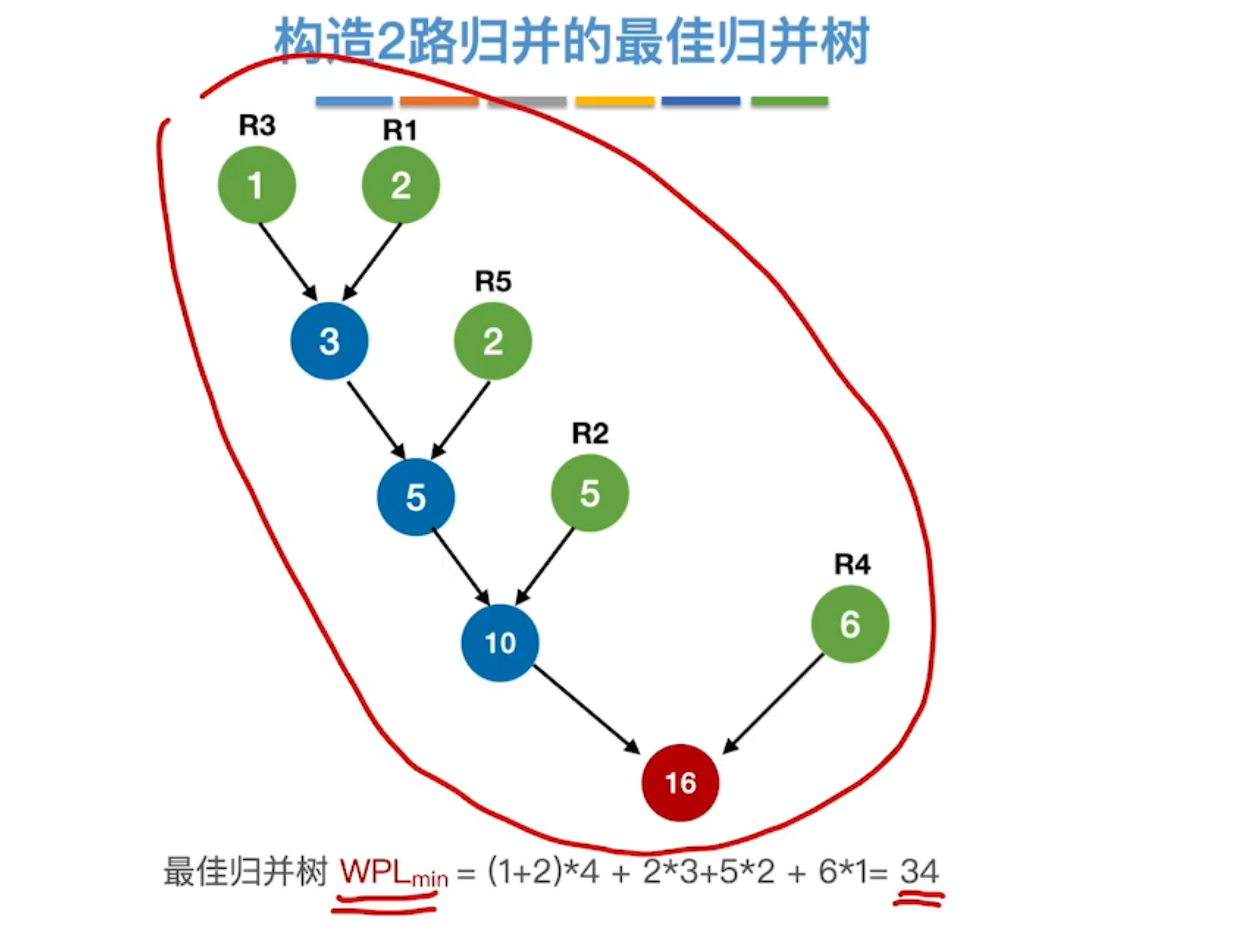
以上是2路归并的最佳归并树,还可以构造k路归并的最佳归并树。
例如:3路归并
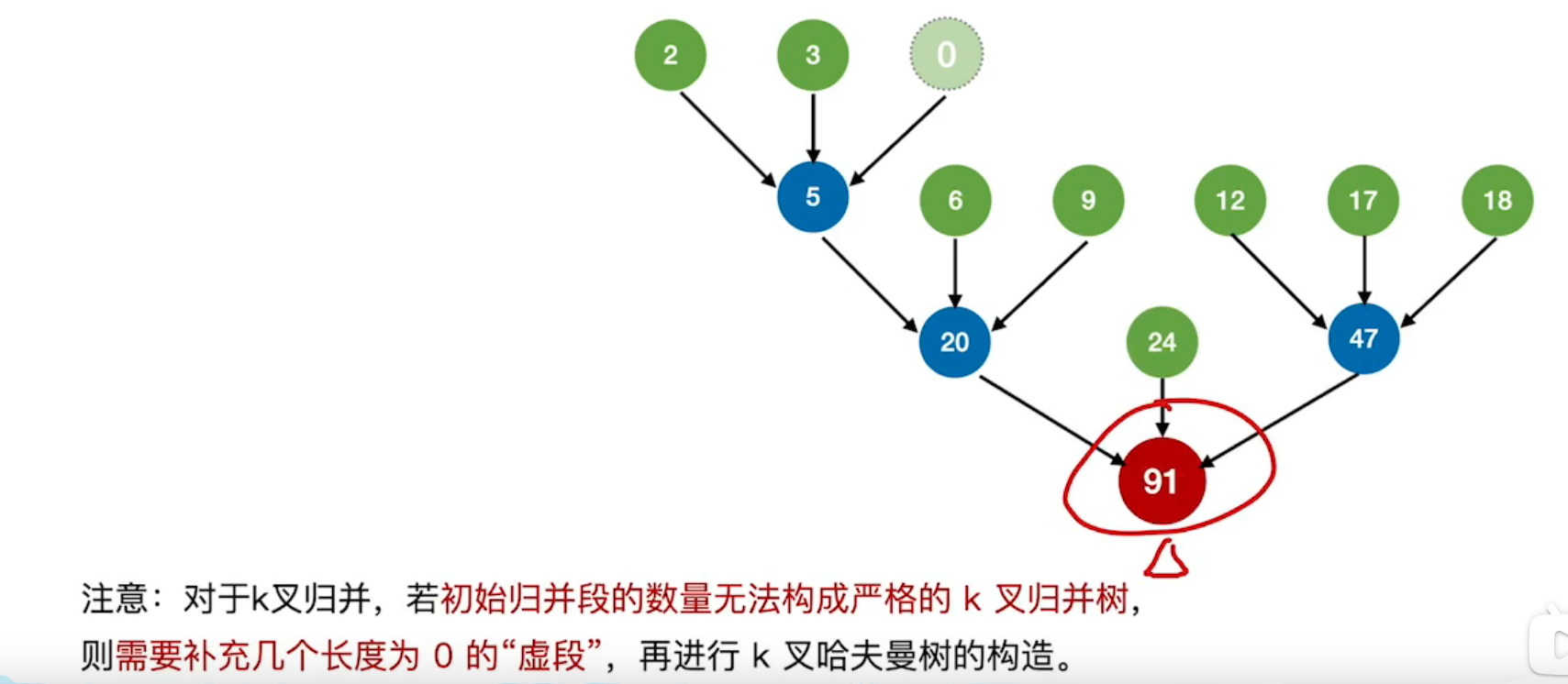
注意:对于k叉归并,若初始归并段的数量无法构成严格的k叉归并树(即所有根结点都有三个子结点),则需补充几个长度为0的“虚短”,在进行k叉哈夫曼树的构造。

不懂,这是一个数学问题。。。
完结!撒花~

















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









