



重点内容
Hadoop DataNode的读和写流程 选择datanode方法 机架感知
从上一篇文章中我们已经晓得了NameNode和Secondary NameNode的职责,这篇文章我们首要讲讲我们怎样往DataNode上写数据和读数据。
DataNode的写操纵流程
DataNode的写操纵流程可以分为两部分,第一部分是写操纵之前的预备工作,包括与NameNode的通讯等;第二部分是实在的写操纵。我们先看第一部分。
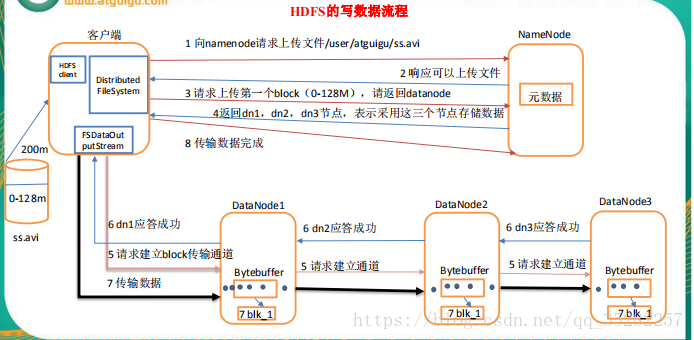
首先,HDFS client会去询问NameNode,看哪些DataNode可以存储Block A-file.txt文件的拆分是在HDFS client中完成的,拆分了3个Block (A,B,C)。由于NameNode存储着全部文件系统的元数据,它晓得哪个DataNode上有空间可以存储这个Block A。
NameNode经过检察它的元数据信息,发现DataNode1,2,7上有空间可以存储Block A,因而将此信息告诉HDFS Client。
HDFS Client接到NameNode返回的DataNode列表信息后,它会间接联系第一个DataNode-DataNode1,让它预备好接收Block A - 现实上就是建立彼其间的TCP毗连。然后将Block A和NameNode返回的一切关于DataNode的元数据一并传给DataNode1。
在DataNode1与HDFS Client建立好TCP毗连后,它会把HDFS Client要写Block A的请求顺序传给DataNode2(在与HDFS Client建立好TCP毗连后从HDFS Client获得的DataNode信息),要求DataNode2也预备好接收Block A(建立DataNode2到DataNode1的TCP毗连)。
同上,建立DataNode2到DataNode7的TCP毗连。
当DataNode7预备好以后,它会告诉DataNode2,表白可以起头接收Block A。
同理,当DataNode2预备好以后,它会告诉DataNode1,表白可以起头接收Block A。
当HDFS Client接到DataNode1的成功反应信息后,说明这3个DataNode都预备好了,HDFS Client就会起头往这三个DataNode写入Block A。
在DataNode1,2,7都预备好接收数据后,HDFS Client起头往DataNode1写入Block A数据。同预备工作一样,当DataNode1接收完Block A数据后,它会顺序将Block A数据传输给DataNode2,然后DataNode2再传输给DataNode7. 每个DataNode在接收完Block A数据后,会发消息给NameNode,告诉它Block数据已经接收终了,NameNode同时会按照它接收到的消息更新它保存的文件系统元数据信息。当Block A成功写入3个DataNode以后,DataNode1会发送一个成功信息给HDFS Client,同时HDFS Client也会发一个Block A成功写入的信息给NameNode。以后,HDFS Client才能起头继续处置下一个Block-Block B。
机架感知
在NameNode在挑选合适的DataNode去存储Block的时辰,不但仅斟酌了DataNode的存储空间够不够,还会斟酌这些DataNode在不在同一个机架上。这就需要NameNode必须晓得一切的DataNode别离位于哪个机架上(所以也称为机架感知)。固然,默许情况下NameNode是不会晓得机架的存在的,也就是说,默许情况下,NameNode会以为一切的DataNode都在同一个机架上(/defaultRack)。除非我们在hdfs-site.xml里面设置topology.script.file.name选项,这个选项的值是一个可履行文件的位置,而该只履行文件的感化是将输入的DataNode的ip地址依照一定例则计较,然后输出它地点的机架的名字,如/rack1, /rack2之类。借助这个文件,NameNode就具有了机架感知了。当它在挑选DataNode去存储Block的时辰,它会遵守以下原则:
(低版本 Hadoop 副本节点选择)
首先挑选跟HDFS Client地点的DataNode作为寄存第一个Block副本的位置,假如HDFS Client不在任何一个DataNode上,比如说Hadoop集群外你自己的电脑,那么就肆意拔取一个DataNode。
其次,会借助NameNode的机架感知特征,拔取跟第一个Block副本地点DataNode分歧的机架上的肆意一个DataNode来寄存Block的第二个副本,比如说/rack2。Block的第三个副本也会存在这个/rack2上,可以是是别的一个DataNode
最初,假如我们设备的副本的数目大于3,那末剩下的副本则随意存储在集群中。
Hadoop2.7.2 副本节点选择
第一个副本在 client 所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
DataNode的读数据流程
最初,我们来看看HDFS Client是若何从DataNode读取数据的。
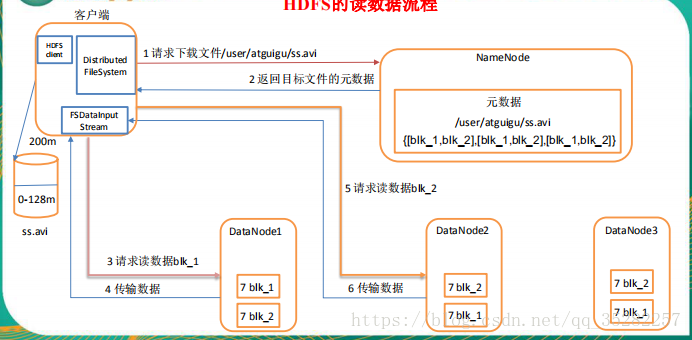
如上图所示,首先,HDFS Client会先去联系NameNode,询问file.txt总共分为几个Block而且这些Block分别寄存在哪些DataNode上。由于每个Block存在几个副本,所以NameNode会把file.txt文件组成的Block所对应的一切DataNode列表都返回给HDFS Client。然后HDFS Client会挑选DataNode列内的第一个DataNode(就近原则,然后随机)去读取对应的Block,比如由于Block A存储在DataNode1,2,7,那末HDFS Client会到DataNode1去读取Block A;Block C存储在DataNode,7,8,9,那么HDFS Client就回到DataNode7去读取Block C。
客户端以 packet 为单位接收,先在本地缓存,然后写入目标文件。

















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









