







 本文总结了吴恩达教授在Coursera上的机器学习课程,涵盖确定优先级、误差分析、偏斜类误差度量、查准率与查全率权衡及数据策略。适合初学者配合课程视频学习。
本文总结了吴恩达教授在Coursera上的机器学习课程,涵盖确定优先级、误差分析、偏斜类误差度量、查准率与查全率权衡及数据策略。适合初学者配合课程视频学习。
吴恩达机器学习笔记(十)机器学习系统设计
本文章是笔者根据Coursera上吴恩达教授的机器学习课程来整理的笔记。如果是初学者,建议大家首先观看吴恩达教授的课程视频,然后再来看博文的要点总结。两者一起食用,效果更佳。

一、确定执行的优先级(Prioritizing What to Work On)
想构建一个垃圾邮件的分类器,有很多改善模型的方法可以执行,怎样排序优先级呢?本章我们将介绍。
取100个频繁出现的词,作为特征,若邮件中含有该词则值为1,若不含有则值为0。

要做的事情:

二、误差分析(Error Analysis)
在拿到一个问题之后,吴恩达教授建议大家先用一个最简单的算法来实现,然后绘制出学习曲线。而不要浪费大量的时间设计非常复杂的算法。虽然最简单的算法可能效果不是很好,但是我们能通过学习曲线来决定下一步的策略,是增加特征还是减小特征,还是找更多的训练数据。此外,通过人工地进行误差分析,找到误差产生的原因,分析出哪种情况下算法的预测会出错,这是一件非常有助益的事情。

例如之前讲到的垃圾邮件分类器的例子中,我们可以首先实现一个非常简单的算法。尽管错误率非常高,500个中有100个分类错误。接下来要做的事,就是对这100个分类错误的邮件进行误差分析。分析一下哪种错误最多,是什么导致的出错,从而更有针对性地对算法进行优化。

数值化评估的重要性:在犹豫要不要加入词根模型时,可以将加入前和加入后的错误率进行比较,如果加入后错误率降低了很多,那么就应该加入词根模型。

三、偏斜类的误差度量(Error Metrics for Skewed Classes)
在分类问题中,如果两个类别的样本数量差别非常悬殊,称为“偏斜类”。
在偏斜类中,使用一个数值来表示预测准确率,是不太合适的。

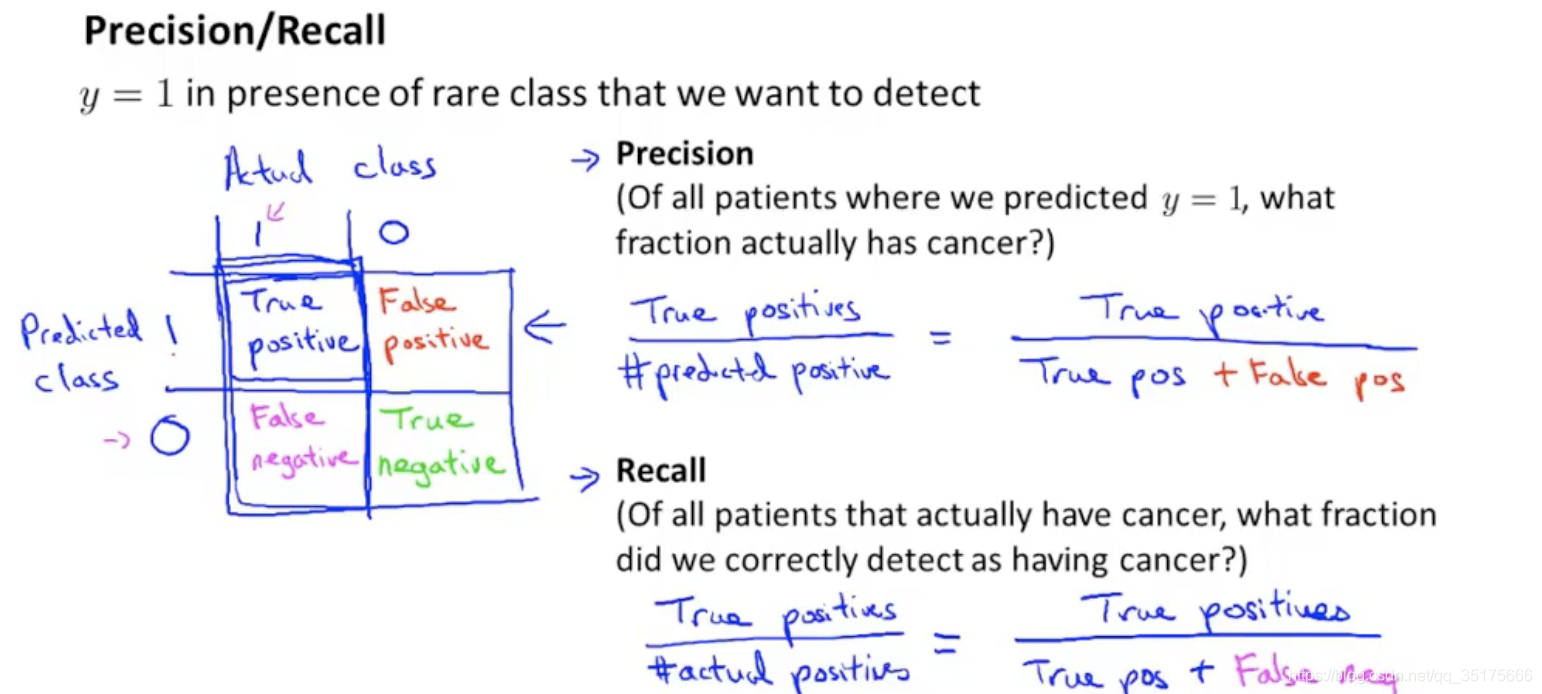
因此提出查准率(Precision)和召回率(查全率)(Recall)的两个概念,如下图.
Precision = true positive / predicted positive = TP/(TP+FP)
Recall = true positive / actual positive = TP/(TP+FN)
四、查准率和查全率的权衡(Trading Off Precision and Recall)
在之前的课程中,我们谈到查准率和召回率,作为遇到偏斜类问题的评估度量值。在很多应用中,我们希望能够保证查准率和召回率的相对平衡。
在这节课中,我将告诉你应该怎么做,同时也向你展示一些查准率和召回率作为算法评估度量值的更有效的方式。继续沿用刚才预测肿瘤性质的例子。假使,我们的算法输出的结果在0-1 之间,我们使用阀值0.5 来预测真和假。
查准率(Precision)=TP/(TP+FP) 例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率(Recall)=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
如果我们希望只在非常确信的情况下预测为真(肿瘤为恶性),即我们希望更高的查准率,我们可以使用比0.5更大的阀值,如0.7,0.9。这样做我们会减少错误预测病人为恶性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。
如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比0.5更小的阀值,如0.3。
我们可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数据的不同而不同:

我们希望有一个帮助我们选择这个阀值的方法。一种方法是计算F1 值(F1 Score),其计算公式为:
F
1
S
c
o
r
e
=
2
P
R
/
(
P
+
R
)
F_1Score = 2PR/(P+R)
F1Score=2PR/(P+R)
我们选择使得F1值最高的阀值。

五、机器学习数据(Data for Machine Learning)
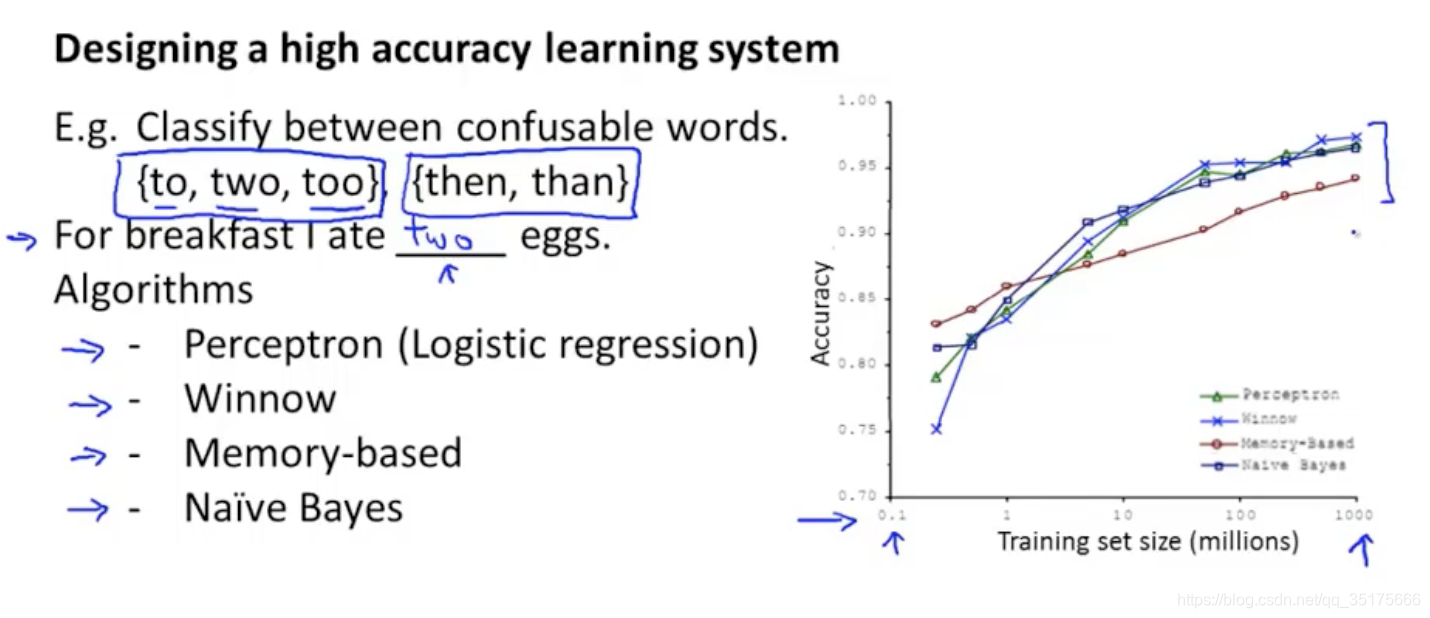
在满足某些条件的情况下,数据集越大,算法的效果越好。下图是随着数据集的增大,算法准确率的变化趋势,可以看出是逐渐上升的。
要满足的第一个条件:
所选取的特征已经包含了预测y值最需要的全部信息。例如,问自己,如果把这些特征告诉一个语言学的专家或者一个房价的专家,他能准确地预测出y值么?如果能,说明特征已经包含了足够多的信息。

要满足的第二个条件:
当选取了一个参数很复杂的算法时(特征很多的回归模型或隐藏层单元数量很多的神经网络),偏差较小,方差可能较大。此时如果选用了很大很大的数据集,数据集的样本数量远大于参数的数量,那么就能避免过拟合的问题。使算法达到很好的效果。


















 4411
4411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









