









一、消息中间件介绍
消息中间件的产生,个人认为是解决端对端通信问题,基于tcp/ip协议的长连接的工具,例如websocket已经做到了端对端通信,那么消息中间件的出现要解决哪些端对端问题呢?
- 消息量积压问题,大数据量高并发下,数据量太大
- 解决多端对多端问题,同个业务中消息源和消费源现实中有很多个,除了端不同,其它没有差别,所以需要无差别通信,急需要一个中间组件让多个端共享
- 解决消息安全问题,实际生产中要保证消息有效消费,需要一个组件来管理消息,让消息的得与失稳定可控。
- 简化上下游应用开发成本,即插即用的模块化思想,做到了上下游应用的松耦合
- 区别于通信的消息处理能力,可以魔法式的完成消息处理,还想花点心思赚点外快。
具体可以读读JMS规范,大差不差基于此规范开发的消息中间件。
二、消息中间件现在常用的场景
- 异步处理
- 应用解耦
- 流量削峰
- 日志处理
- 分布式消息处理
- 流式计算
三、常用消息中间件对比
| 特性 | activeMQ | rabbitMQ | rocketMQ | kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比rocketMQ和kafka低一个数量级 | 同activeMQ | 10万级,支撑高吞吐 | 10万级,高吞吐量,常用于大数据生态 |
| topic数量对吞吐量的影响 | 可以达到几百/几千的级别,吞吐量会有较小幅度下降,在同等机器下,可以支撑大量的topic | topic从几十到几百时,吞吐量会大幅度下降,在同等机器下,kafka尽量保证topic数量不要过多,如果要支持大规模的topic,需要增加机器数 | ||
| 时效性 | ms级 | 微秒级,延迟最低 | ms级 | 延迟在ms级以内 |
| 可用性 | 高,主从架构实现高可用 | 同activeMQ | 非常高,基于分布式架构 | 非常高,分布式,一个partition多个副本,少数机器宕机不会丢失数据,高可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,做到0丢失 | 同rocketMQ |
| 功能支持 | MQ领域功能完备 | 基于erlang开发,并发能力强,性能极好,延迟很低 | MQ功能较为完善,分布式,扩展性好 | 功能较为简单,支持简单MQ功能,在大数据领域的实时计算和日志采集被大规模使用 |
| 社区活跃度 | 低 | 中 | 高 | 高 |
四、kafka介绍
kafka是一个分布式,支持分区(partition),多副本(replica),基于类似zk协调的分布式消息系统。常用于实时处理大数据量场景,比如日志收集、用户活动追踪、运营指标分析报告和报警。是大数据生态中的常客。
1. kafka架构图
kafka集群一般需要一个分布式协调框架,常用zookeeper。kafka分布式体现在partition上,可以配置多个分区副本,但只有leader分区参与读写。controller在kafka集群中参与分区管理,包括分区故障恢复以及集群元数据同步分发。
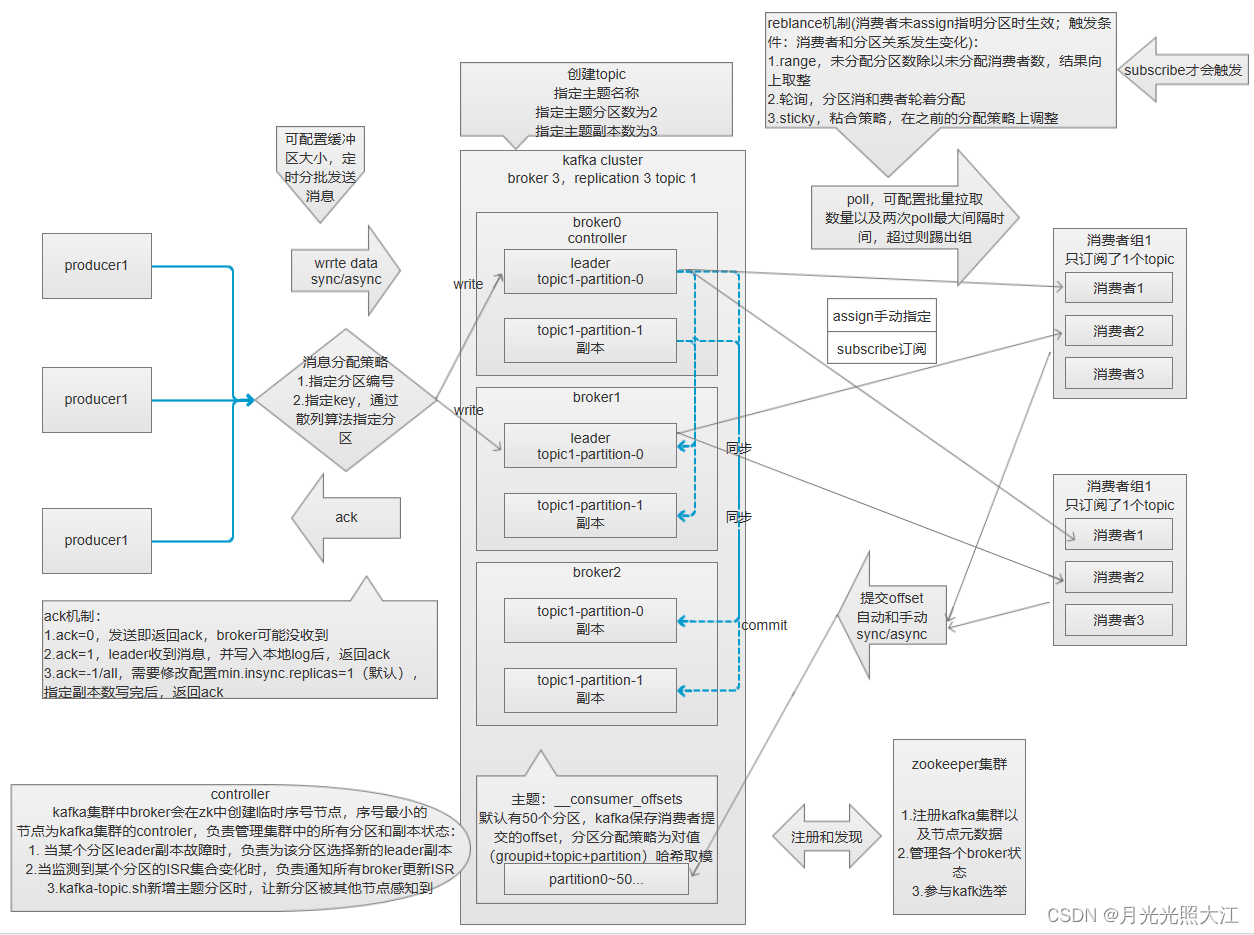
2. 消费流程
生产者指定分区或key来发送消息,发送完会受到ack,但不表示发送成功,具体需要参考ack配置策略。
kafka集群,会将消息提交到leader中的partition,partition维护segement文件,支持消息的顺序读写,并将消息同步到其它副本分区。在读写消息时,支持零拷贝,大大提高读写性能。kafka基于磁盘文件存储,顺序读写和零拷贝保证读写性能大大提高,可以比肩内存存储的读写。
消费者通过消费者组来订阅topic,topic对消费组是多播,对消费组中的各个消费者是单播。单播得益于rebalance机制,每个分区只能绑定消费组内的一个消费者,topic下分区和组内消费者只存在多对一的关系。消费者需要自己维护分区的offset,消费消息后需要提交offset到kafka,保存最后一个消费消息的偏移量。
3. HW和LEO
HW为高水位,取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW,consumer最多只能消费到HW所在的位置。每个副本都有HW,leader和follower各自负责更新自己的HW状态。对于leader新写入的消息,consumer不能立即消费,leader会等消息被ISR中所有replicas同步更新后更新HW,此时消息才能被消费者消费。这样做保证leader所在broker宕机后,该消息仍然可以从新选出来的leader中获取到。
五、kafka集群搭建
1. 环境配置
1.搭建三台虚拟机,节点分别为192.168.47.128、192.168.47.129、192.168.47.130
2.安装好jdk环境
3.下载apache-zookeeper-3.8.3-bin.tar.gz并解压,搭建zk集群并启动
4.下载kafka_2.12-3.6.0版本到三台虚拟机,并添加到系统环境中
2. 修改配置
修改 config/server.properties文件,在三台虚拟机中都需要修改。
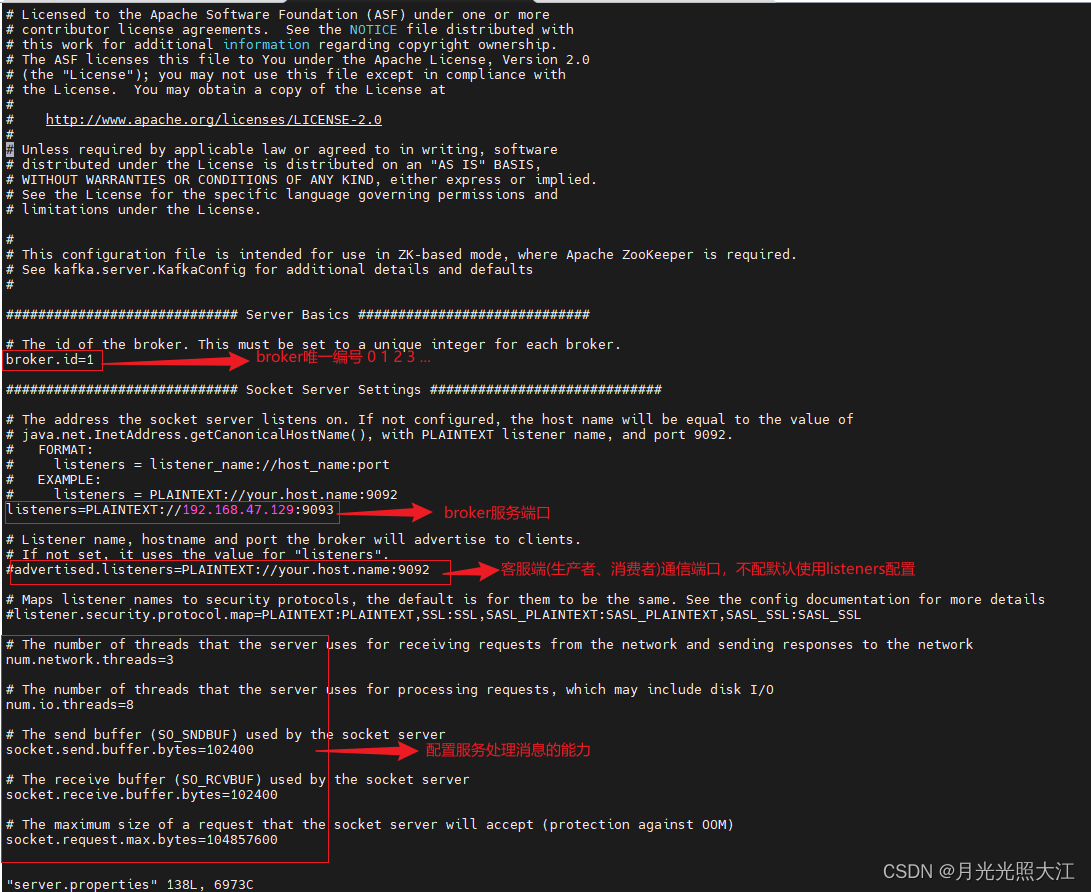
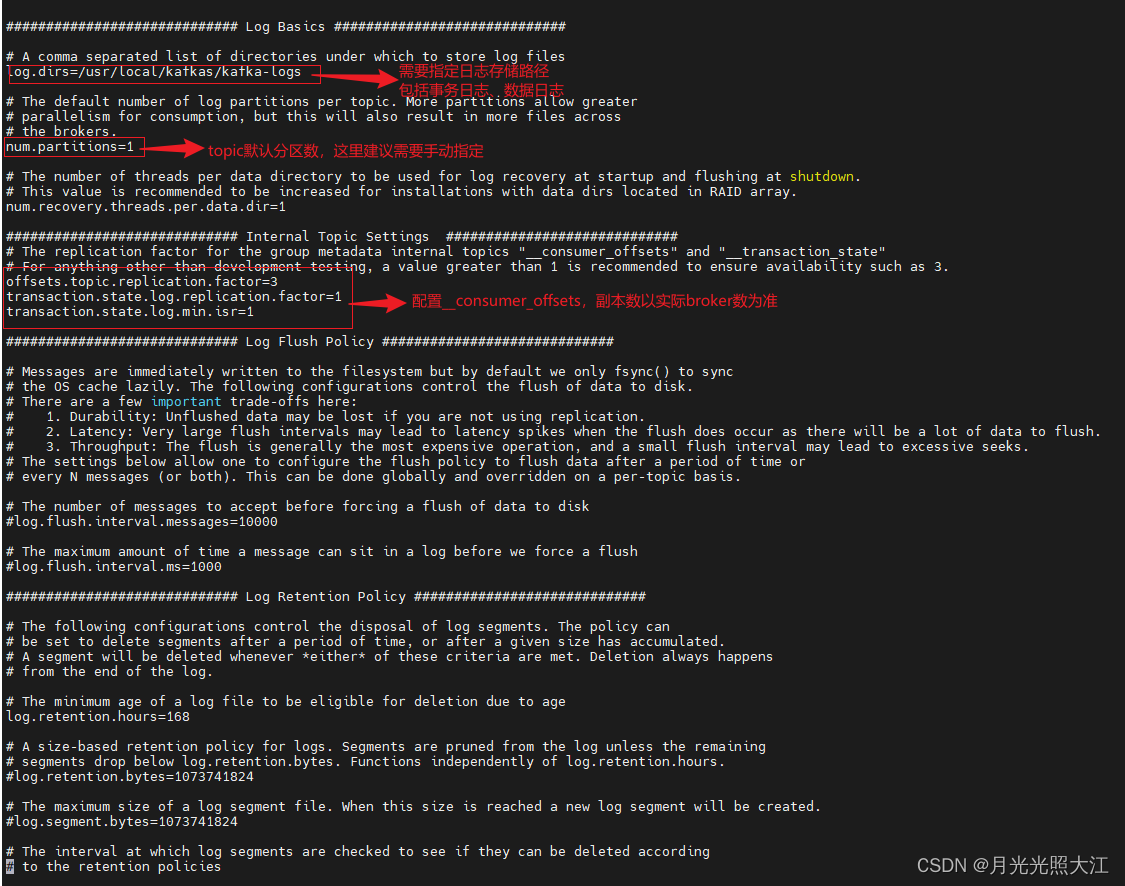
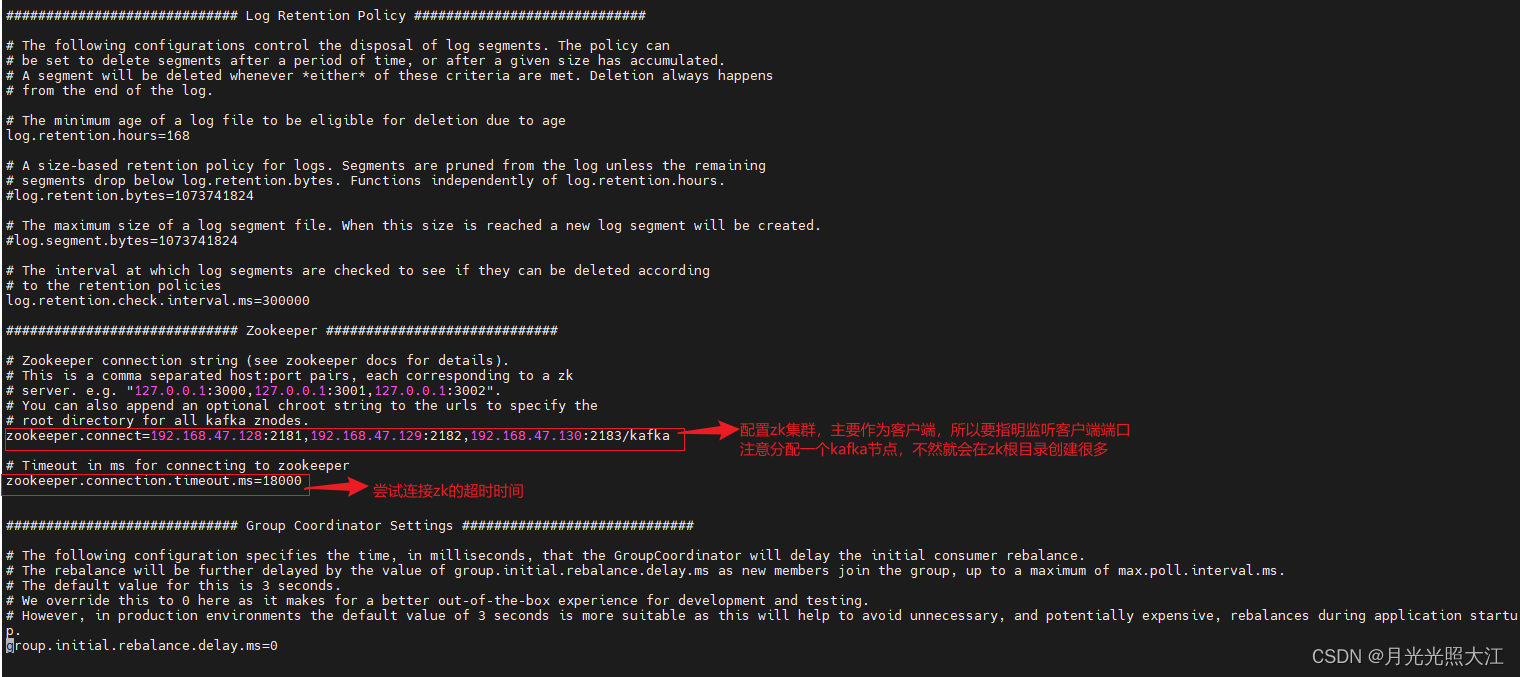
3. 启动kafka集群
在每台虚拟机上执行 kafka-server-start.sh -daemon ../config/server.properties,启动kafka集群
查看kafka集群是否启动成功,可以连接zk集群 zkCli.sh -server master1:2181,worker1:2182,worker2:2183 查看如下,表示成功:

六、kafka 客户端配置
1. java客户端配置
1.1 引入依赖
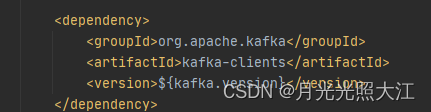
1.2 配置生产者和消费者
package com.spring.zkkafka.conf;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Properties;
@Configuration
public class ConfigKafka {
@Bean
Producer<String, String> kafkaProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.47.128:9092,192.168.47.129:9093,192.168.47.130:9094");
props.put(ProducerConfig.ACKS_CONFIG, "1"); // ack 确认机制
props.put(ProducerConfig.RETRIES_CONFIG, 3); // 重试次数
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 3000); // 每次重试之间间隔时间
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); // 生产者本地缓冲区大小,可以提高发送性能,默认32MB
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 批量发送消息量大小,默认16384,即16KB
props.put(ProducerConfig.LINGER_MS_CONFIG, 10); // 发送消息的延迟时间,默认为0,有消息就发送,设置10ms发送,但如果batch够了也发送
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 设置key序列化工具
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 设置value序列化工具
return new KafkaProducer<>(props);
}
@Bean
KafkaConsumer<String, String> kafkaConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.47.128:9092,192.168.47.129:9093,192.168.47.130:9094");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "testGroup_2"); // 消费者组
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 改为手动提交,默认自动提交(poll之后就提交offset了)
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); // key值反序列化(二进制转成字符串)
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); // value值反序列化(二进制转成字符串)
/*
当消费主题的是一个新的消费组,或者offset不存在,怎么消费
latest(默认):只消费自己启动之后发送到主题的消息
earliest:第一次从头开始消费,之后按照offset记录继续消费,这个区别于consumer.seekToBeginning(每次都从头消费)
*/
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000); // consumer给broker发送的心跳间隔时间毫秒
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000); // kafka如果10s没有收到消费者心跳,则会把消费者剔除消费组,进行rebalance.
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 10); // 一次poll能拉的最大消息条数,根据消费能力设定. 默认值500
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000); // 两次poll的时间超过30s,kafka认为消费能力低,剔除消费组,触发rebalance
return new KafkaConsumer<>(props);
}
}1.3 测试用例
package com.spring.zkkafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.TopicPartition;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.time.Duration;
import java.util.Collections;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
@SpringBootTest
public class KafkaTest {
@Autowired
private Producer<String, String> kafkaProducer;
@Autowired
private KafkaConsumer<String, String> kafkaConsumer;
private String topic = "testt";
@Test
public void sendMessage() throws ExecutionException, InterruptedException {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, "my",
"client-test11");
RecordMetadata metadata = kafkaProducer.send(producerRecord).get();
System.out.printf("发送消息成功:message-%s, topic-%s, partition-%s, offset-%d%n", "client-test11", metadata.topic(),
metadata.partition(), metadata.offset());
kafkaProducer.close();
}
@Test
public void sendAsyncMessage() throws IOException {
for (int i = 0; i < 10; i++) {
String mess = "kkkk" + i;
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, 1, "myzff",
mess);
kafkaProducer.send(producerRecord, (recordMetadata, e) -> {
if (e != null) {
System.out.printf("消息 %s 发送失败,报异常 %s%n", mess, e.getMessage());
} else {
System.out.printf("发送消息成功:message-%s, topic-%s, partition-%s, offset-%d%n", mess,
recordMetadata.topic(), recordMetadata.partition(), recordMetadata.offset());
}
});
}
System.out.println("主线程 -------------------");
System.in.read();
}
@Test
public void testConsumer() throws InterruptedException {
kafkaConsumer.subscribe(Collections.singletonList(topic)); // 内部算法,自动分给分区给消费组中的消费者(range、轮询、sticky)
// 手动指定分区消费,手动指定分区后,消费者自动分区就会失效(如果不提交offset,不影响subscribe的消费者)
// kafkaConsumer.assign(Collections.singletonList(new TopicPartition(topic, 1)));
// kafkaConsumer.seekToBeginning(Collections.singletonList(new TopicPartition(topic, 1))); // 指定分区消费后,可以从头0开始消费,消费者启动后每次都从0开始消费
// 手动指定分区偏移量消费,消费者自动分区就会失效(如果不提交offset,不影响subscribe的消费offset)
// kafkaConsumer.assign(Collections.singletonList(new TopicPartition(topic, 1)));
// kafkaConsumer.seek(new TopicPartition(topic, 1),75); // 指定分区开始消费的offset
// 手动指定时间开始消费,这里消费topic中所偶分区,消费者自动分区就会失效(如果不提交offset,不影响subscribe的消费offset)
// List<PartitionInfo> partitions = kafkaConsumer.partitionsFor(topic); // 获取所有分区
// long millis = System.currentTimeMillis() - 1000 * 60 * 20;
// Map<TopicPartition, Long> tPTime = new HashMap<>(partitions.size());
// for (PartitionInfo p : partitions) {
// tPTime.put(new TopicPartition(p.topic(), p.partition()), millis);
// }
// Map<TopicPartition, OffsetAndTimestamp> tPOffsetMap = kafkaConsumer.offsetsForTimes(tPTime);
// // 这种方式有问题,assign方法使用一次,后面的会覆盖前面指派的分区,所以要指派分区后消费完,再指派
// for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : tPOffsetMap.entrySet()) {
// TopicPartition topicPartition = entry.getKey();
// OffsetAndTimestamp offsetAndTimestamp = entry.getValue();
// if (topicPartition == null || offsetAndTimestamp == null) continue;
// kafkaConsumer.assign(Collections.singletonList(topicPartition)); // 手动指定分区偏移量,只能指定一个分区后消费完,再指定另外的分区消费
// kafkaConsumer.seek(topicPartition, offsetAndTimestamp.offset());
// // 消费逻辑,一个分区一个分区消费
// }
// 长轮训消费
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(1000)); // poll在1s内是长轮询poll
for (ConsumerRecord<String, String> record : records) {
System.out.printf("收到消息:topic-%s, partition-%s, offset-%d, key-%s, value-%s%n", record.topic(),
record.partition(), record.offset(), record.key(), record.value());
}
if (!records.isEmpty()) {
// TimeUnit.SECONDS.sleep(40); // 这里是模拟 两次poll间隔超过30s,kafka会把该消费者剔除消费者组
kafkaConsumer.commitSync(); // 阻塞 每批相同分区的offset只需要提交一次(顺序消费,每个分区提交最后消费的消息,即为最大的offset)
kafkaConsumer.commitAsync((map, e) -> { // 异步 每批相同分区的offset只需要提交一次
if (e != null) {
System.out.println(e.getMessage());
} else {
for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : map.entrySet()) {
System.out.printf("已提交offset : partition-%s,offset-%s.%n", entry.getKey().partition(),
entry.getValue().offset());
}
}
});
}
if (records.isEmpty()) {
TimeUnit.SECONDS.sleep(2);
}
}
}
}2. springboot 配置
2.1 引入依赖
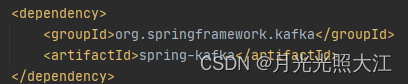
2.2 参数配置
server.port=8080
#### ZK ####
curator.retryCount=5
curator.elapsedTimeMs=5000
curator.server=192.168.47.128:2181,192.168.47.129:2182,192.168.47.130:2183
curator.sessionTimeoutMs=600000
curator.connectTimeoutMs=5000
#### kafka ####
### producer ####
spring.kafka.bootstrapServers=192.168.47.128:9092,192.168.47.129:9093,192.168.47.130:9094
spring.kafka.producer.acks=1
spring.kafka.producer.batchSize=16384
spring.kafka.producer.bufferMemory=33554432
spring.kafka.producer.retries=3
spring.kafka.producer.keySerializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.valueSerializer=org.apache.kafka.common.serialization.StringSerializer
### consumer ####
spring.kafka.consumer.groupId=testGroup_2
spring.kafka.consumer.enableAutoCommit=false
spring.kafka.consumer.autoOffsetReset=earliest
spring.kafka.consumer.heartbeatInterval=1000
spring.kafka.consumer.maxPollRecords=5
spring.kafka.consumer.keyDeserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.valueDeserializer=org.apache.kafka.common.serialization.StringDeserializer
### listener ####
## MANUAL_IMMEDIATE(调用ack..方法就提交了,MANUAL(批量提交,消费端本地暂存offset(每个分区最大Offset),poll的数据消费完后,在下次poll时提交(惰性提交))) ##
spring.kafka.listener.ackMode=MANUAL_IMMEDIATE2.3 客户端消费者配置
package com.spring.zkkafka.conf;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
@Configuration
@ConditionalOnClass(ConfigKafka.MyConsumer.class)
public class ConfigKafka {
@Bean
@ConditionalOnMissingBean(MyConsumer.class)
MyConsumer myConsumer() {
return new MyConsumer();
}
static class MyConsumer {
@KafkaListener(topics = "testt", groupId = "testGroup_2")
void listenGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.printf("消费成功:%s.%n", value);
ack.acknowledge(); // 手动提交
}
}
}2.4 生产者调用
package com.spring.zkkafka;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
@SpringBootTest
public class KafkaTest {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
private String topic = "testt";
@Test
public void sendMessageSpringBoot() throws ExecutionException, InterruptedException, IOException {
SendResult<String, String> res = kafkaTemplate.send(topic, 1, "key", "springboot发送消息了").get();
System.out.printf("发送成功:%s%n", res.getProducerRecord().value());
System.in.read();
}
}七、kafka监听kafka-eagle的搭建
1. 环境准备
下载efak-web-3.0.1-bin.tar.gz到本地任意一台虚拟机,解压缩,添加系统环境配置
2. 修改配置文件
vi conf/system-config.properties
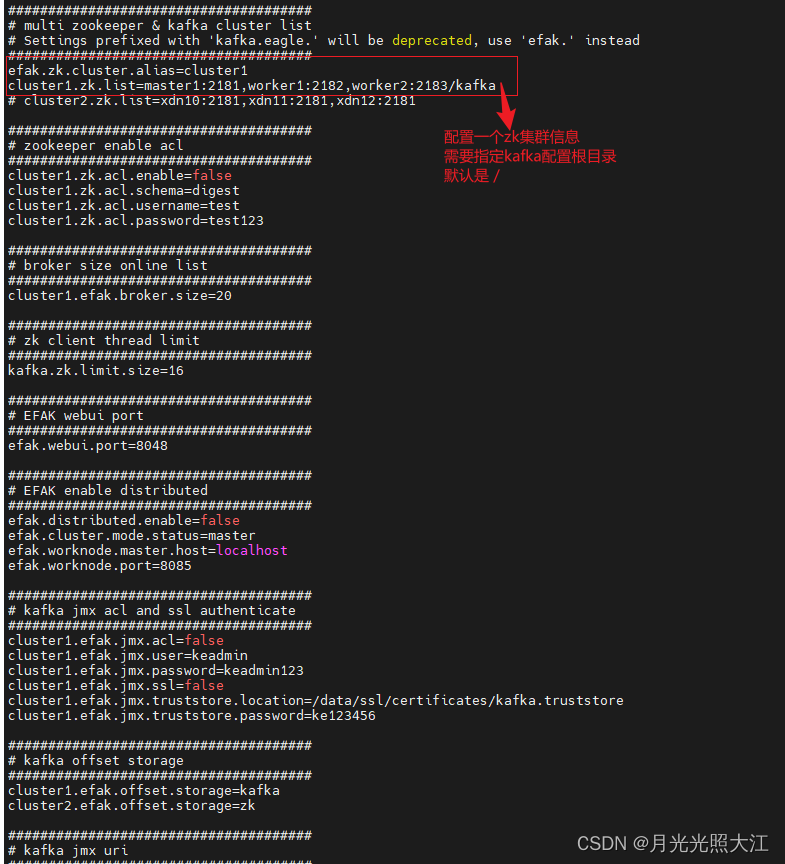
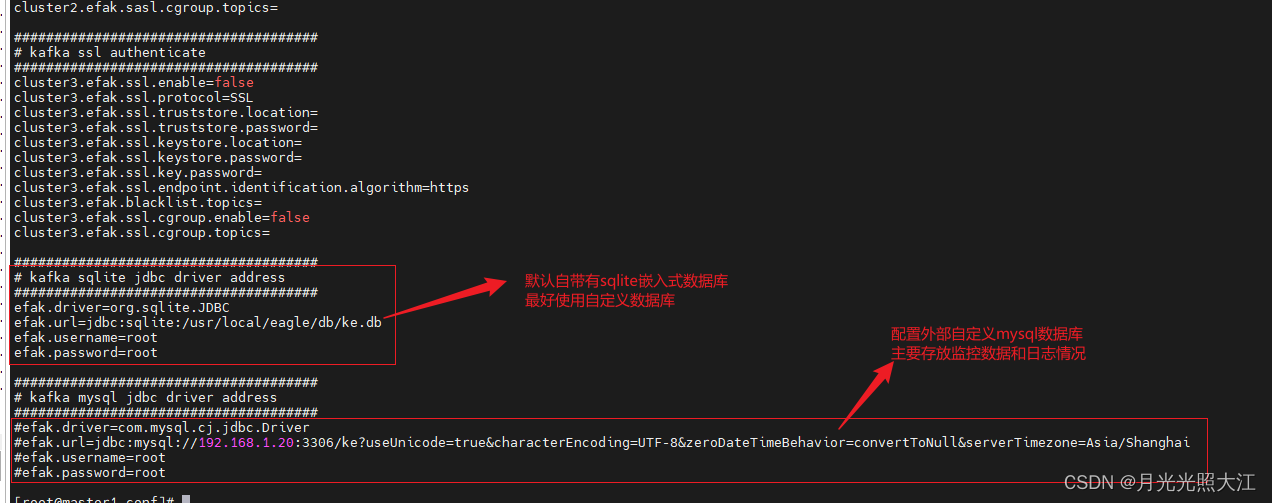
3. 启动并访问监控页面
ke.sh start

















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









