







 本文详细介绍SQOOP工具在Hadoop与关系型数据库间的数据迁移过程,包括安装配置、基本命令使用,以及如何将MySQL数据导入HDFS、Hive和HBase,实现大数据平台与传统数据库的无缝对接。
本文详细介绍SQOOP工具在Hadoop与关系型数据库间的数据迁移过程,包括安装配置、基本命令使用,以及如何将MySQL数据导入HDFS、Hive和HBase,实现大数据平台与传统数据库的无缝对接。
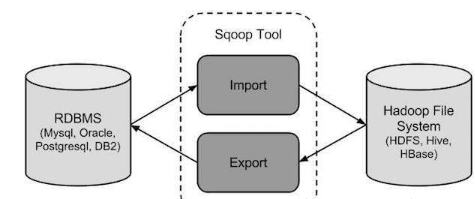
1.sqoop是一个用于在hadoop和关系型数据库之间传输数据的工具,用于从关系数据库(mysql、oracle)导入数据到HDFS。
2.当大数据存储和hadoop生态系统的MapReduce、hive、HBASE、Pig分析器出现时,它们就需要一种工具来与 关系型数据库服务器进行交互,以导入和导出驻留在其中的大数据。

sqoop在是使用的时候会和哪些系统打交道?
HDFS、MapReduce、Yarn、Zookeeper、Hive、Hbase、Mysql
安装sqoop
1.解压安装包

2.vi sqoop.env.sh
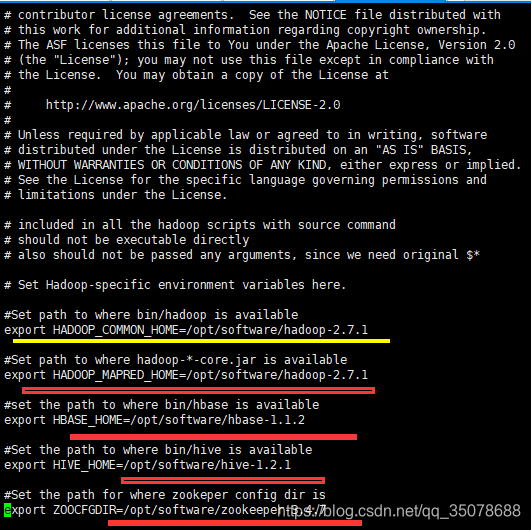
3.配置环境变量

4.让环境生效
source /etc/profile
5.测试
sqoop help
sqoop version

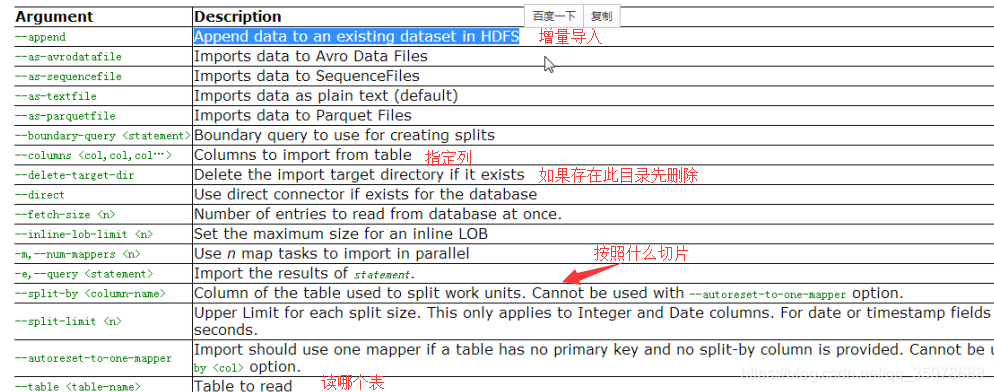
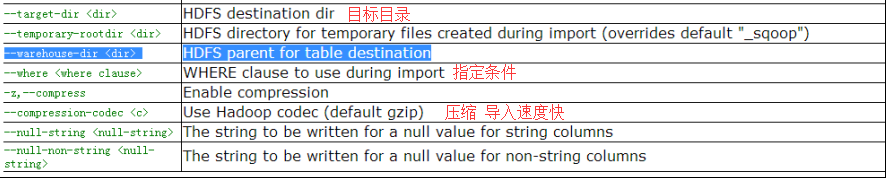

1.将mysql中的 emp中的数据导入HDFS
sqoop import
–connect jdbc:mysql://hadoop1:3306/gp1814
–username root
–password 123456
–table emp
-m 1
-m(指定mr的数量)
2.指定split,路径(集群):–split-by id
sqoop import
–connect jdbc:mysql://hadoop1:3306/gp1814
–username root
–password 123456
–split-by id
–table emp
–target-dir hdfs://mycluster/sqoopdata/emp1
3.指定查询语句
sqoop import
–connect jdbc:mysql"//hadoop1:3306/gp1814
–username root
–password 123456
–query ‘select id,name,salary from emp where id < 1204 and $CONDITIONS’
–target-dir hdfs://mycluster/sqoopdata/emp1
-m 1
4.把 mysql的数据导入到hive中
sqoop import
–connect jdbc:mysql://hadoop1:3306/gp1814
–username root
–password 123456
–table emp
-hive-import
-m 1
–target-dir hdfs://mycluster/sqoopdata/emp1
5.导出数据export
sqoop import
–connect jdbc:mysql://hadoop1:3306/gp1814
–username root
–password 123456
–table emp
–export-dir hdfs://mycluster/sqoopdata/emp1
6.导入所有表到hdfs中
sqoop import-all-tables
–connect jdbc:mysql://hadoop1:3306/gp1814
–username root
–password 123456
-m 1
7.指定分隔符和导入路径
sqoop import
–connetct jdbc:mysql"//hadoop1/gp1814
–username root
–password 123456
–table emp
–target-dir /user/hadoop1/myemp
–fields-terminated-by ‘\t’
-m 2
8.把mysql数据库中的表数据导入到hbase
普通导入
sqoop import
–connect jdbc:mysql://hadoop1/gp1814
–username root
–password 123456
–table emp
–hbase-table new_emp
–column-family person
–hbase-row-key new_emp_id
此时报错,因为需要先创建hbase里面的表,再执行导入的语句
create ‘new_emp’,‘base_info’

















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









