






 本文介绍基于用户协同的过滤统计算法,涵盖收集用户偏好、找相似用户或物品、计算推荐等相关知识。阐述相似度计算、距离选择、邻居选择方法,分析基于用户和物品的协同过滤,还提及隐语义模型。最后给出准确率、召回率等评估标准,并可直接调用代码实现。
本文介绍基于用户协同的过滤统计算法,涵盖收集用户偏好、找相似用户或物品、计算推荐等相关知识。阐述相似度计算、距离选择、邻居选择方法,分析基于用户和物品的协同过滤,还提及隐语义模型。最后给出准确率、召回率等评估标准,并可直接调用代码实现。


基于用户协同的过滤统计算法


相关知识:
1.收集用户偏好
2.找到相似用户或物品
3.计算推荐
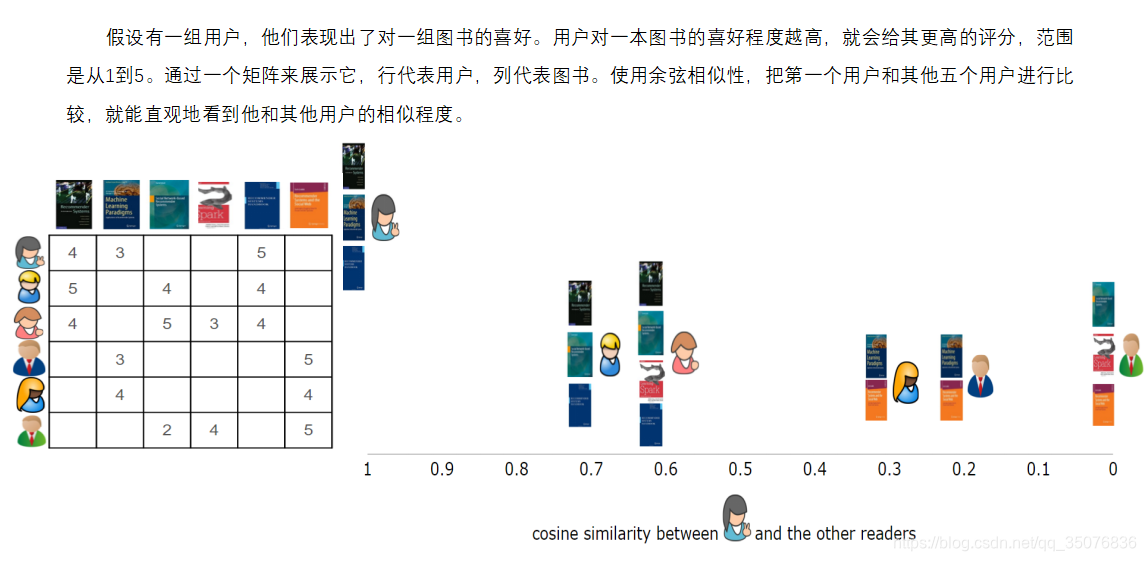
相似度计算:
\\\\\\\\ 商品1 商品2
用户A
用户B
用户C
距离的选择:
1.欧式距离
2.皮尔逊相关系数: 协方差除以两个变量的标准差得到的
3.Cosine相似度:
邻居的选择:
A:固定数量的邻居
B:基于相似度门槛的邻居
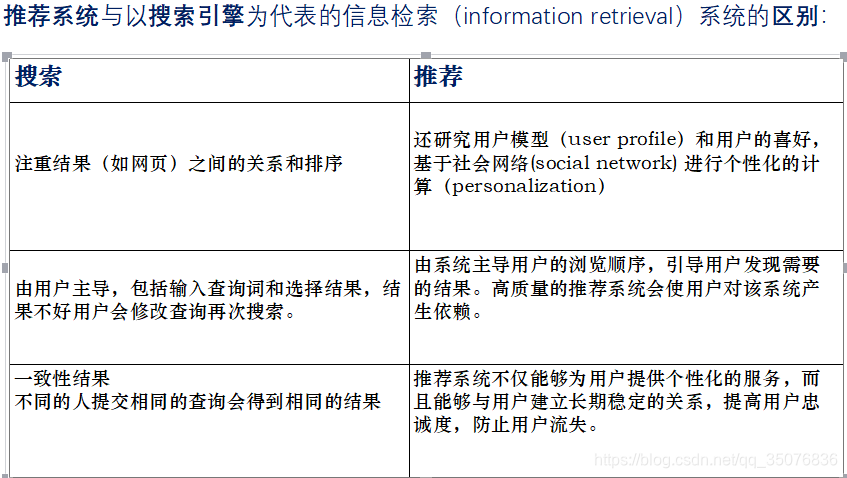
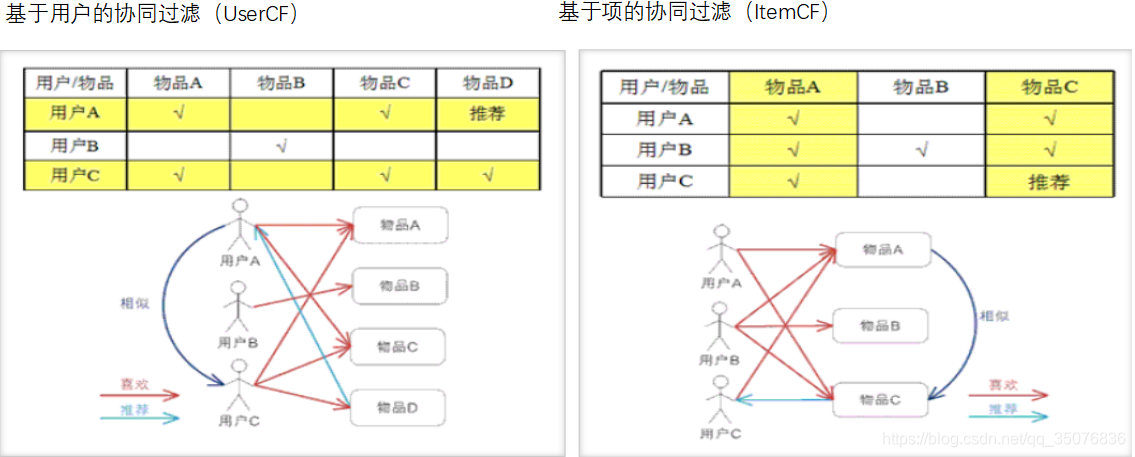
基于用户的协同过滤:
已知用户评分矩阵Matrix R 一般都是非常稀疏的
推断矩阵中空格empty中的值
存在问题:对于一个新用户,很难找到新邻居
基于物品的协同过滤
通常用户数量远大于物品数量
先计算相似度指标,物品1与其他 物品的相似度 slim(1, m) 取最高的两个
隐语义模型
从数据出发,进行个性化推荐
用户和物品之间有着隐含的联系
分解–组合 R=Q*P
Rating Matrix(N*M) = User Feature Matrix(N*F)*Movie Feature Matrix(F*M)
隐特征的个数F 通常F=100
正/负样本比例ratio
协同过滤基于统计 隐语义基于建模
评估标准
准确率RMSE
召回率Recall
覆盖率Coverage
多样性Diversity
直接调用代码实现:
from surprise import KNNBasic,SVD //协同过滤,矩阵分解
from surprise import Dataset
from surprise import evaluate,print_perf
data = Dataset.load_builtin('ml-100k')
data.split(n_folds=3)
algo = KNNBasic()
perf = evaluate(algo, data, measures=['RMSE', 'MAE']) #算法,数据,评估指标
print_perf(perf)
from surprise import GridSearch
param_grid = {'n_epochs':[5,10], 'lr_all':[0.002,0.005] #学习率 ,'reg_all':[1.4,0.6] #正则化惩罚项强度}
grid_search = GridSearch(SVD, param_grid, measures=['RMSE', 'FCP'])
data = Dataset.load_builtin(' ')
data.split(n_folds=3)
grid_search.evaluate(data)
#输出最佳分数值,参数值等
print(grid_search.best_score['RMSE'])
print(grid_search.best_params['RMSE'])
print(grid_search.best_score['FCP'])
print(grid_search.best_params['FCP'])
def read_item_names():
file_name = ('')
rid_to_name = {}
name_to_rid = {}
with io.open(file_name, "r", encoding="ISO-8859-1") as f:
for line in f:
line = line.split('|')
rid_to_name[line[0]] = line[1]
name_to_rid[line[1]] = line[0]
return rid_to_name, name_to_rid
data = Dataset.load_builtin('ml-100k')
trainset = data.bulid_full_trainset() #构建为原始矩阵
sim_options = {'name':'pearson_baseline', 'user_based':False} #相似度计算方法
algo = KNNBaseline(sim_options=sim_options)
algo.train(trainset)
#原始数据ID
rid to name, name to rid = read_item_names()
toy_story_raw_id = name_to_rid[' 电影名 '] #将原始数据 name 转换得到 数据ID
#矩阵ID
toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id) #得到 矩阵ID
toy_story_neighbors = algo.get_neighbors(toy_story_inner_id,k=10) #得到 矩阵ID最相近的 K个邻居
toy_story_neighbors =(algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors)
toy_story_neighbors =(rid_to_name[rid] for rid in toy_story_neighbors)
print()
print('The 10 nearest neighbors of Toy Story are:')
for movie in toy_story_neighbors:
print(movie)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









