




 文章探讨了CPU作为计算机核心组件的功能、结构及与内存的互动,包括CPU的寄存器、控制单元、ALU等关键部件,以及内存的工作原理、数据存储和访问过程。进一步讲解了编程中内存管理、数据类型、指针、数组、栈和队列的应用,还涉及函数调用机制和指令执行流程。
文章探讨了CPU作为计算机核心组件的功能、结构及与内存的互动,包括CPU的寄存器、控制单元、ALU等关键部件,以及内存的工作原理、数据存储和访问过程。进一步讲解了编程中内存管理、数据类型、指针、数组、栈和队列的应用,还涉及函数调用机制和指令执行流程。
一、操作系统CPU
1、CPU简介
CPU的全称是CentrolProcessingUnit,它是你的电脑中最硬核的组件,这种说法一点不为过。
CPU是能够让你的计算机叫 计算机 的核心组件,但是它却不能代表你的电脑,CPU 与计算机的关系就相当于大脑和人的关系。它是一种小型的计算机芯片,它嵌入在台式机、笔记本电脑或者平板电脑的主板上。
通过在单个计算机芯片上放置数十亿个微型晶体管来构建CPU,这些晶体管使它能够执行运行存储在系统内存中的程序所需的计算,也就是说CPU决定了你电脑的计算能力。

2、CPU 实际做什么
CPU的核心是从程序或应用程序获取指令并执行计算。此过程可以分为三个关键阶段:提取,解码和执行。CPU从系统的RAM中提取指令,然后解码该指令的实际内容,然后再由CPU的相关部分执行该指令。
RAM:随机存取存储器(英语:Random Access Memory,缩写:RAM),也叫主存,是与CPU直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储介质。
3、CPU的内部结构
说了这么多 CPU 的重要性,那么 CPU 的内部结构是什么呢?又是由什么组成的呢?
下图展示了一般程序的运行流程(以C语言为例),可以说了解程序的运行流程是掌握程序运行机制的基础和前提。
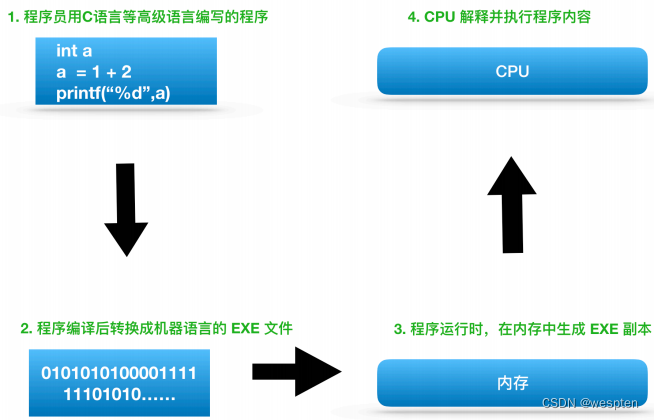
程序编译执行的过程
在这个流程中,CPU负责的就是解释和运行最终转换成机器语言的内容。
CPU主要由两部分构成:控制单元和算术逻辑单元(ALU)
- 控制单元:从内存中提取指令并解码执行;
- 算数逻辑单元(ALU):处理算数和逻辑运算;
CPU是计算机的心脏和大脑,它和内存都是由许多晶体管组成的电子部件。它接收数据输入,执行指令并处理信息。它与输入/输出(I/O)设备进行通信,这些设备向 CPU 发送数据和从CPU接收数据。
从功能来看,CPU的内部由寄存器、控制器、运算器和时钟四部分组成,各部分之间通过电信号连通。
CPU 内部结构图:
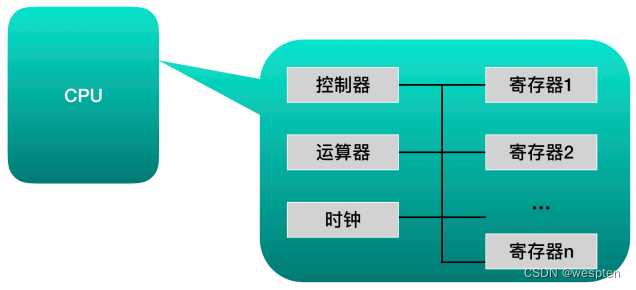
- 寄存器:是中央处理器内的组成部分。它们可以用来暂存指令、数据和地址。可以将其看作是内存的一种。根据种类的不同,一个CPU内部会有20-100个寄存器;
- 控制器:负责把内存上的指令、数据读入寄存器,并根据指令的结果控制计算机;
- 运算器:负责运算从内存中读入寄存器的数据;
- 时钟:负责发出 CPU开始计时的时钟信号;
接下来简单解释一下内存,为什么说CPU需要讲一下内存呢,因为内存是与CPU进行沟通的桥梁。
计算机所有程序的运行都是在内存中运行的,内存又被称为主存 ,其作用是存放 CPU中的运算数据,以及与硬盘等外部存储设备交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到主存中进行运算,当运算完成后CPU再将结果传送出来,主存的运行也决定了计算机的稳定运行。
主存通过控制芯片与CPU进行相连,由可读写的元素构成,每个字节(1byte=8bits)都带有一个地址编号,注意是一个字节,而不是一个位。CPU通过地址从主存中读取数据和指令,也可以根据地址写入数据。
注意一点:当计算机关机时,内存中的指令和数据也会被清除。
4、CPU是寄存器的集合体
在CPU的四个结构中,我们程序员只需要了解 寄存器 就可以了,其余三个不用过多关注,为什么这么说?因为程序是把寄存器作为对象来描述的。
说到寄存器,就不得不说到汇编语言,我大学是学信息管理与信息系统的,我就没有学过汇编这门课(就算有这门课也不会好好学hhhh),出来混总是要还的,要想作为一个硬核程序员,不能不了解这些概念。说到汇编语言,就不得不说到高级语言,说到高级语言就不得不牵扯出语言这个概念。
1. 计算机语言
我们生而为人最明显的一个特征是我们能通过讲话来实现彼此的交流,但是计算机听不懂你说的话,你要想和他交流必须按照计算机指令来交换,这就涉及到语言的问题,计算机是由二进制构成的,它只能听的懂二进制也就是 机器语言,但是普通人是无法看懂机器语言的,这个时候就需要一种电脑既能识别,人又能理解的语言,最先出现的就是 汇编语言。但是汇编语言晦涩难懂,所以又出现了像是C、C++、Java的这种高级语言。
所以计算机语言一般分为两种:低级语言(机器语言,汇编语言)和高级语言。使用高级语言编写的程序,经过编译转换成机器语言后才能运行,而汇编语言经过汇编器才能转换为机器语言。
2. 汇编语言
首先来看一段用汇编语言表示:
mov eax, dword ptr [ebp-8] /*把数值从内存复制到 eax */
add eax, dword ptr [ebp-0Ch] /* 把 eax 的数值和内存的数值相加 */
mov dword ptr [ebp-4], eax /* 把 eax 的数值(上一步的结果)存储在内存中*/这是采用汇编语言(assembly)编写程序的一部分。汇编语言采用 助记符(memonic)来编写程序,每一个原本是电信号的机器语言指令会有一个与其对应的助记符,例如 mov,odd 分别是数据的存储(move)和相加(addition)的简写。汇编语言和机器语言是——对应的。这一点和高级语言有很大的不同,通常我们将汇编语言编写的程序转换为机器语言的过程称为 汇编 ;反之,机器语言转化为汇编语言的过程称为 反汇编。
汇编语言能够帮助你理解计算机做了什么工作、机器语言级别的程序是通过寄存器来处理的,上面代码中的 eax,ebp 都是表示的寄存器,是CPU内部寄存器的名称,所以可以说 CPU是一系列寄存器的集合体。在内存中的存储通过地址编号来表示,而寄存器的种类则通过名字来区分。
不同类型的 CPU,其内部寄存器的种类,数量以及寄存器存储的数值范围都是不同的。
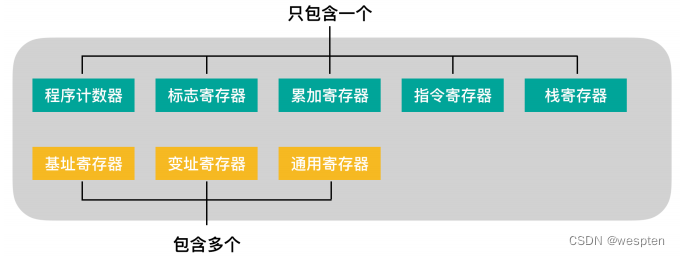
不过,根据功能的不同,可以将寄存器划分为下面这几类:

其中程序计数器、累加寄存器、标志寄存器、指令寄存器和栈寄存器都只有一个,其他寄存器一般有多个。
程序员眼中的CPU:
5、程序计数器
程序计数器(Program Counter)是用来存储下一条指令所在单元的地址。
程序执行时,PC的初值为程序第一条指令的地址,在顺序执行程序时,控制器首先按程序计数器所指出的指令地址从内存中取出一条指令,然后分析和执行该指令,同时将PC的值加1指向下一条要执行的指令。
我们还是以一个事例为准来详细的看一下程序计数器的执行过程。
内存中配置程序示例:
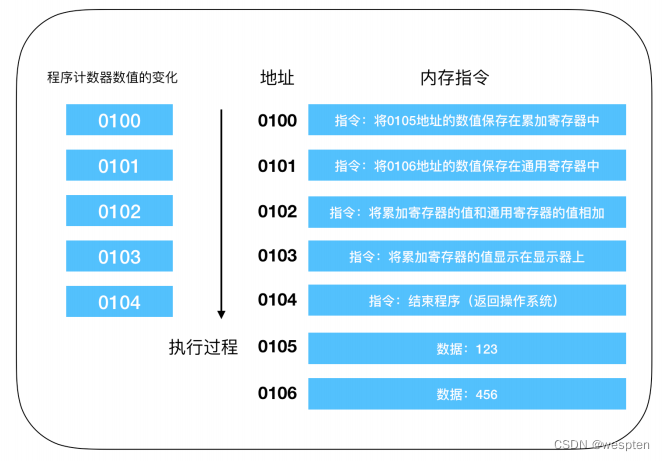
这是一段进行相加的操作,程序启动,在经过编译解析后会由操作系统把硬盘中的程序复制到内存中,示例中的程序是将123和456执行相加操作,并将结果输出到显示器上。由于使用机器语言难以描述,所以这是经过翻译后的结果,实际上每个指令和数据都可能分布在不同的地址上,但为了方便说明,把组成一条指令的内存和数据放在了一个内存地址上。
地址 0100 是程序运行的起始位置。Windows 等操作系统把程序从硬盘复制到内存后,会将程序计数器作为设定为起始位置0100,然后执行程序,每执行一条指令后,程序计数器的数值会增加1(或者直接指向下一条指令的地址)。然后,CPU就会根据程序计数器的数值,从内存中读取命令并执行,也就是说,程序计数器控制着程序的流程。
6、条件分支和循环机制
我们都学过高级语言,高级语言中的条件控制流程主要分为三种:顺序执行、条件分支、循环判断 三种。顺序执行是按照地址的内容顺序的执行指令。条件分支是根据条件执行任意地址的指令,循环是重复执行同一地址的指令。
- 顺序执行的情况比较简单,每执行一条指令程序计数器的值就是+1。
- 条件和循环分支会使程序计数器的值指向任意的地址,这样一来,程序便可以返回到上一个地址来重复执行同一个指令,或者跳转到任意指令。
下面以条件分支为例来说明程序的执行过程(循环也很相似):
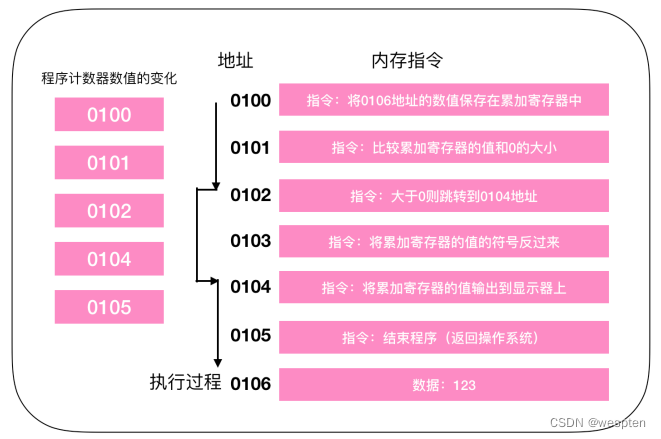
程序的开始过程和顺序流程是一样的,CPU 从0100处开始执行命令,在0100和01都是顺序执行,PC的值顺序+1,执行到0102地址的指令时,判断0106寄存器的数值大于0,跳转(jump)到0104地址的指令,将数值输出到显示器中,然后结束程序,0103的指令被跳过了。
这就和我们程序中的 if() 判断是一样的,在不满足条件的情况下,指令会直接跳过。所以PC的执行过程也就没有直接+1,而是下一条指令的地址。
7、标志寄存器
条件和循环分支会使用到 jump (跳转指令) ,会根据当前的指令来判断是否跳转,上面我们提到了标志寄存器,无论当前累加寄存器的运算结果是正数、负数还是零,标志寄存器都会将其保存(也负责溢出和奇偶校验)。
- 溢出(overflow):是指运算的结果超过了寄存器的长度范围;
- 奇偶校验(parity check):是指检查运算结果的值是偶数还是奇数;
CPU 在进行运算时,标志寄存器的数值会根据当前运算的结果自动设定,运算结果的正、负和零三种状态由标志寄存器的三个位表示。标志寄存器的第一个字节位、第二个字节位、第三个字节位各自的结果都为1时,分别代表着正数、零和负数。
比较运算的标志寄存器示意图:

CPU的执行机制比较有意思,假设累加寄存器中存储的XXX和通用寄存器中存储的YYY做比较,执行比较的背后,CPU的运算机制就会做减法运算。而无论减法运算的结果是正数、零还是负数,都会保存到标志寄存器中。结果为正表示XXX比YYY大,结果为零表示XXX和YYY相等,结果为负表示XXX比YYY小。程序比较的指令,实际上是在CPU内部做减法运算。
8、函数调用机制
接下来,我们继续介绍函数调用机制,哪怕是高级语言编写的程序,函数调用处理也是通过把程序计数器的值设定成函数的存储地址来实现的。函数执行跳转指令后,必须进行返回处理,单纯的指令跳转没有意义,下面是一个实现函数跳转的例子。
程序调用示意图:
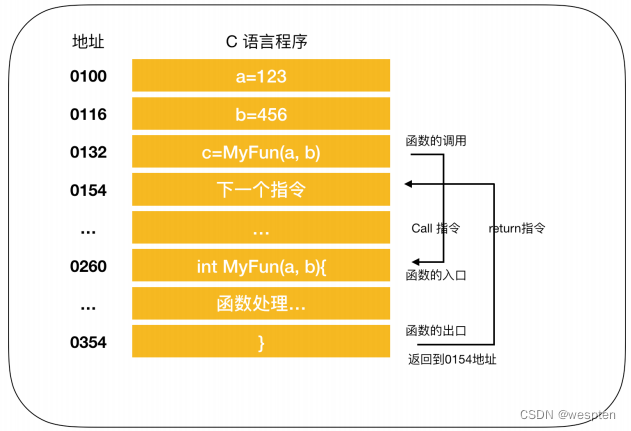
图中将变量 a 和 b 分别赋值为123和 456,调用 MyFun(a,b)方法,进行指令跳转。图中的地址是将C 语言编译成机器语言后运行时的地址,由于1行C程序在编译后通常会变为多行机器语言,所以图中的地址是分散的。在执行完 MyFun(a.b)指令后,程序会返回到 MyFun(a,b) 的下一条指令,CPU继续执行下面的指令。
函数的调用和返回很重要的两个指令是coll和return指令,再将函数的入口地址设定到程序计数器之前,call指令会把调用函数后要执行的指令地址存储在名为栈的主存内。函数处理完毕后,再通过函数的出口来执行return指令。return指令的功能是把保存在栈中的地址设定到程序计数器。
MyFun 函数在被调用之前,0154地址保存在栈中,MyFun函数处理完成后,会把0154的地址保存在程序计数器中。
这个调用过程如下:
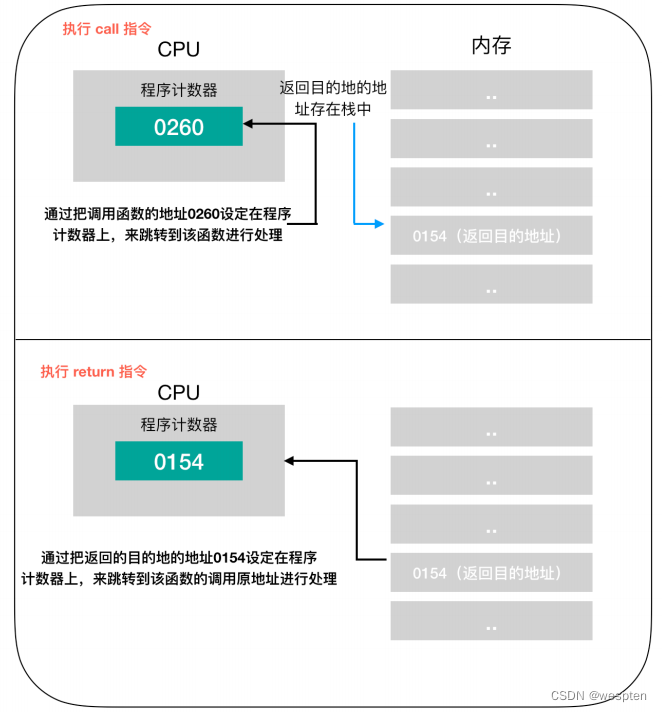
函数调用中程序计数器和栈的职能.
在一些高级语言的条件或者循环语句中,函数调用的处理会转换成call指令,函数结束后的处理则会转换成return指令。
9、通过地址和索引实现数组
接下来我们看一下基址寄存器和变址寄存器,通过这两个寄存器,我们可以对主存上的特定区域进行划分,来实现类似数组的操作,首先,我们用十六进制数将计算机内存上的0000000-FFFFFF的地址划分出来。那么,凡是该范围的内存地址,只要有一个32位的寄存器,便可查看全部地址。
但如果想要想数组那样分割特定的内存区域以达到连续查看的目的的话,使用两个寄存器会更加方便。
例如,我们用两个寄存器(基址寄存器和变址寄存器)来表示内存的值。
基址寄存器和变址寄存器:

这种表示方式很类似数组的构造,数组是指同样长度的数据在内存中进行连续排列的数据构造。用数组名表示数组全部的值,通过索引来区分数组的各个数据元素,例如:a[0] -a[4] ,[] 内的0-4就是数组的下标。
10、CPU指令执行过程
那么CPU是如何执行一条条的指令的呢?
几乎所有的冯·诺伊曼型计算机的CPU,其工作都可以分为5个阶段:取指令、指令译码、执行指令、访存取数、结果写回。
- 取指令阶段,是将内存中的指令读取到 CPU中寄存器的过程,程序寄存器用于存储下一条指令所在的地址;
- 指令译码阶段,在取指令完成后,立马进入指令译码阶段,在指令译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法;
- 执行指令阶段,译码完成后,就需要执行这一条指令了,此阶段的任务是完成指令所规定的各种操作,具体实现指令的功能;
- 访问取数阶段,根据指令的需要,有可能需要从内存中提取数据,此阶段的任务是:根据指令地址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运算;
- 结果写回阶段,作为最后一个阶段,结果写回(Write Back,WB)阶段把执行指令阶段的运行结果数据"写回"到某种存储形式:结果数据经常被写到CPU的内部寄存器中,以便被后续的指令快速地存取;
二、操作系统内存
1、内存简介
内存(Memory)是计算机中最重要的部件之一,它是程序与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存对计算机的影响非常大,内存又被称为主存,其作用是存放CPU中的运算数据,以及与硬盘等外部存储设备交换的数据。
只要计算机在运行中,CPU就会把需要运算的数据调到主存中进行运算,当运算完成后CPU再将结果传送出来,主存的运行也决定了计算机的稳定运行。
2、内存物理结构
在了解一个事物之前,你首先得先需要见过它,你才会有印象,才会有想要了解的兴趣,所以我们首先需要先看一下什么是内存以及它的物理结构是怎样的。
512M内存的物理结构:

内存的内部是由各种IC电路组成的,它的种类很庞大,但是其主要分为三种存储器
- 随机存储器(RAM):内存中最重要的一种,表示既可以从中读取数据,也可以写入数据。当机器关闭时,内存中的信息会 丢失。
- 只读存储器(ROM): ROM一般只能用于数据的读取,不能写入数据,但是当机器停电时,这些数据不会丢失。
- 高速缓存(Cache):Cache也是我们经常见到的,它分为一级缓存(L1 Cache)、二级缓存(L2 Cache)、三级缓存(L3 Cache)这些数据,它位于内存和 CPU之间,是一个读写速度比内存 更快 的存储器。当 CPU 向内存写入数据时,这些数据也会被写入高速缓存中。当 CPU需要读取数据时,会直接从高速缓存中直接读取,当然,如需要的数据在Cache中没有,CPU会再去读取内存中的数据。
内存IC是一个完整的结构,它内部也有电源、地址信号、数据信号、控制信号和用于寻址的IC引脚来进行数据的读写。
下面是一个虚拟的内存IC引脚示意图:
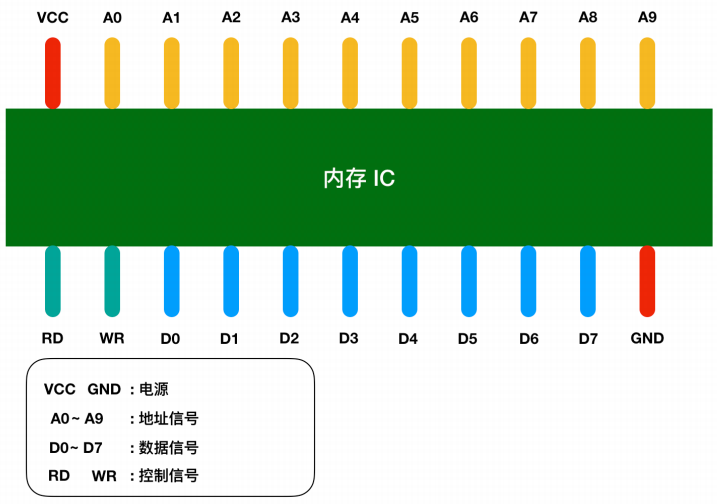
图中VCC和GND表示电源,A0-A9是地址信号的引脚,D0-D7表示的是控制信号、BD和WR都是好控制信号,我用不同的颜色进行了区分,将电源连接到VCC和GND后,就可以对其他引脚传递0和1的信号,大多数情况下,+5V表示1,0V表示0.
我们都知道内存是用来存储数据,那么这个内存IC中能存储多少数据呢?D0-D7表示的是数据信号,也就是说,一次可以输入输出8bit=1byte的数据。A0-A9是地址信号共十个,表示可以指定00000 00000-1111111111共2的 10次方= 1024个地址。每个地址都会存放1byte 的数据,因此我们可以得出内存 IC 的容量就是1KB。
如果我们使用的是512 MB的内存,这就相当于是512000(512*1000)个内存IC。当然,一台计算机不太可能有这么多个内存IC,然而,通常情况下,一个内存IC会有更多的引脚,也就能存储更多数据。
3、内存的读写过程
让我们把关注点放在内存IC对数据的读写过程上来吧,我们来看一个对内存IC进行数据写入和读取的模型。
从内存IC读取和写入数据:
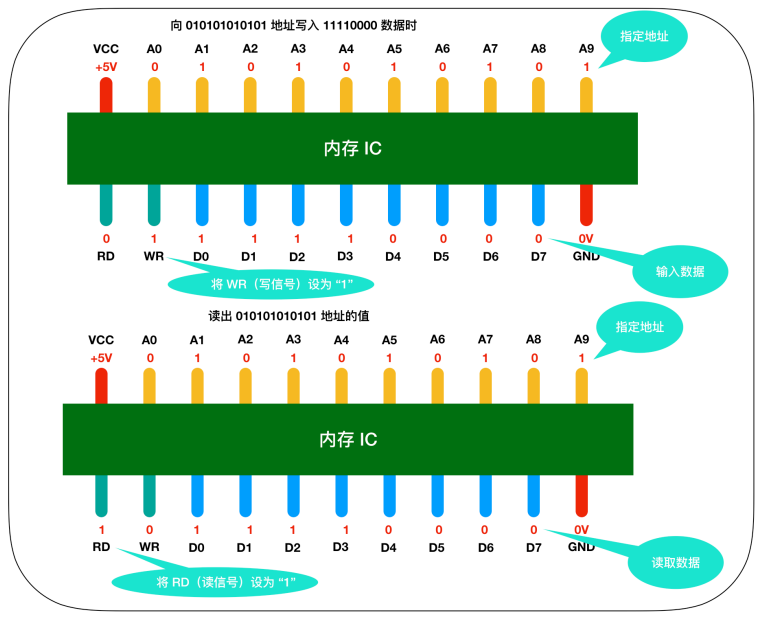
来详细描述一下这个过程,假设我们要向内存IC中写入1byte的数据的话,它的过程是这样的:
- 首先给 VCC接通 +5V的电源,给 GND接通 0V的电源,使用 A0 - A9 来指定数据的存储场所、然后再把数据的值输入给 D0- D7 的数据信号,并把 WR(write) 的值置为1,执行完这些操作后,即可以向内存 IC 写入数据
- 读出数据时,只需要通过A0-A9的地址信号指定数据的存储场所,然后再将RD的值置为1即可。
- 图中的 RD和WR又被称为控制信号。其中当WR和 RD都为0时,无法进行写入和读取操作。
4、内存的现实模型
为了便于记忆,我们把内存模型映射成为我们现实世界的模型,在现实世界中,内存的模型很想我们生活的楼房。在这个楼房中,1层可以存储一个字节的数据,楼层号就是地址。下面是内存和楼层整合的模型图。
1KB 内存模型图:
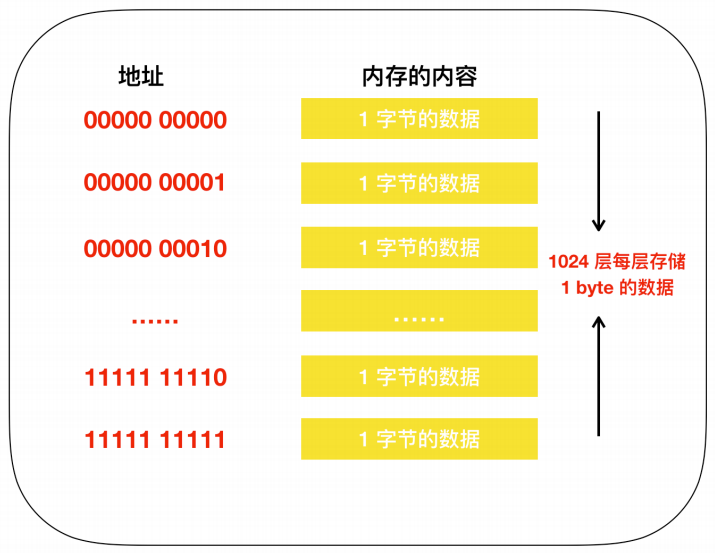
我们知道,程序中的数据不仅只有数值,还有 数据类型 的概念,从内存上来看,就是占用内存大小(占用楼层数)的意思。即使物理上强制以1个字节为单位来逐一读写数据的内存,在程序中,通过指定其数据类型,也能实现以特定字节数为单位来进行读写。
下面是一个以特定字节数为例来读写指令字节的程序的示例:
//定义变量
char a;
short b;
long c;
//变量赋值
a = 123;
b = 123;
c = 123;我们分别声明了三个变量a,b,c,并给每个变量赋上了相同的123,这三个变量表示内存的特定区域。通过变量,即使不指定物理地址,也可以直接完成读写操作,操作系统会自动为变量分配内存地址。
这三个变量分别表示1个字节长度的char,2个字节长度的short,表示4个字节的long。因此,虽然数据都表示的是123,但是其存储时所占的内存大小是不一样的。
变量存储示意图:
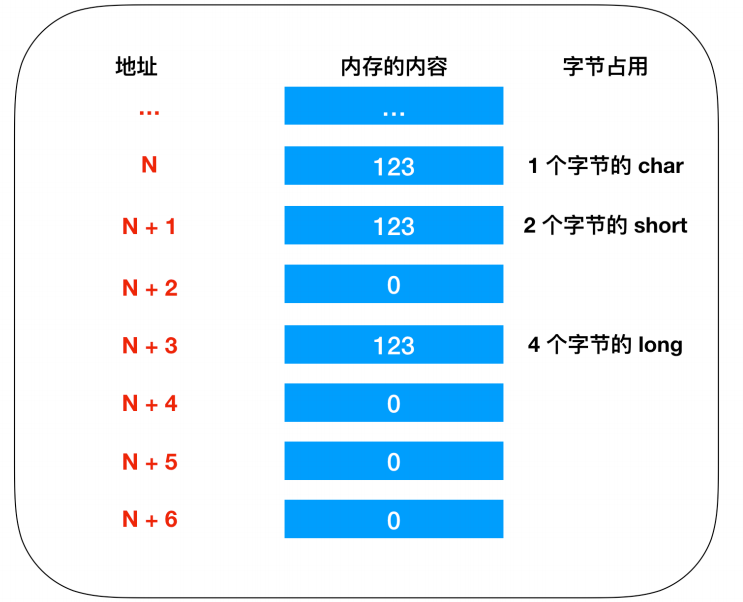
这里的123都没有超过每个类型的最大长度,所以short和long类型为所占用的其他内存空间分配的数值是0,这里我们采用的是 低字节序列 的方式存储
- 低字节序列:将数据低位存储在内存低位地址。
- 高字节序列:将数据的高位存储在内存地位的方式称为高字节序列。
5、内存的使用
1. 指针
指针是C语言非常重要的特征,指针也是一种变量,只不过它所表示的不是数据的值,而是内存的地址。通过使用指针,可以对任意内存地址的数据进行读写。
在了解指针读写的过程前,我们先需要了解如何定义一个指针,和普通的变量不同,在定义指针时,我们通常会在变量名前加一个 * 号。
例如我们可以用指针定义如下的变量:
char *d; // char类型的指针d定义
short *e; // short类型的指针e定义
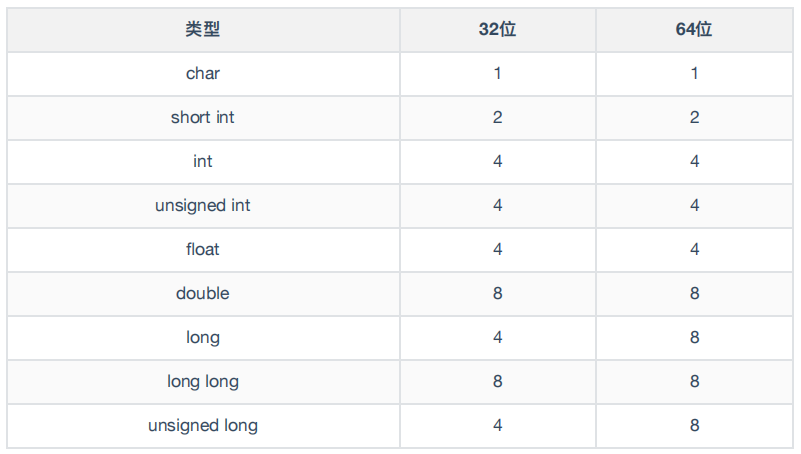
long *f; // long类型的指针f定义我们以32位计算机为例,32位计算机的内存地址是4字节,在这种情况下,指针的长度也是32位。然而,变量def却代表了不同的字节长度,这是为什么呢?
实际上,这些数据表示的是从内存中一次读取的字节数,比如 d e f的值都为100,那么使用char类型时就能够从内存中读写1byte的数据,使用short类型就能够从内存读写2字节的数据,使用long 就能够读写4字节的数据。
下面是一个完整的类型字节表:
我们可以用图来描述一下这个读写过程:
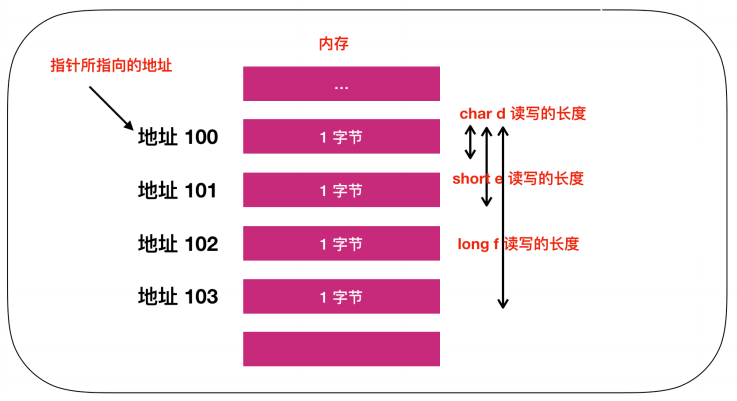
数据类型读写长度示意图。
2. 数组是内存的实现
数组是指多个 相同 的数据类型在内存中连续排列的一种形式。作为数组元素的各个数据会通过下标编号来区分,这个编号也叫做 索引,如此一来,就可以对指定索引的元素进行读写操作。
首先先来认识一下数组,我们还是用 char、short、long 三种元素来定义数组,数组的元素[value]扩起来,里面的值代表的是数组的长度,就像下面的定义:
char g[100];
short h[100];
long i[100];数组定义的数据类型,也表示一次能够读写的内存大小,char、short、long分别以1、2、4个字节为例进行内存的读写。
数组是内存的实现,数组和内存的物理结构完全一致,尤其是在读写1个字节的时候,当字节数超过1 时,只能通过逐个字节来读取。
下面是内存的读写过程:
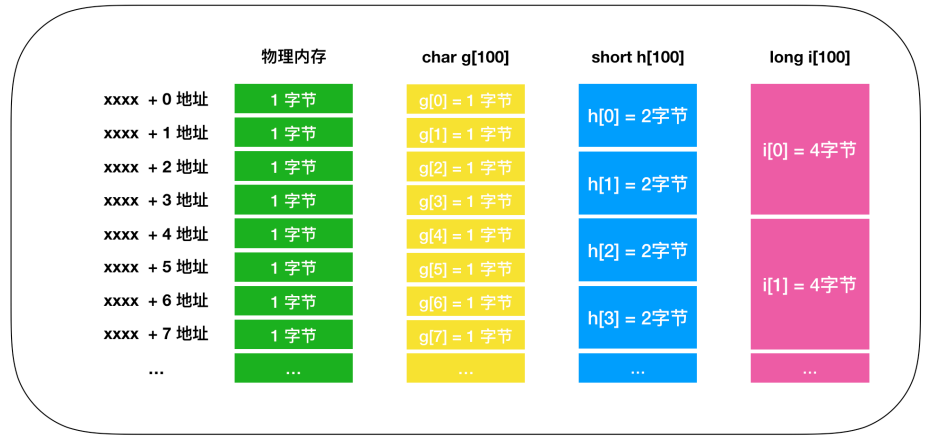
不同数据类型的数组。
3. 栈和队列
我们上面提到数组是内存的一种实现,使用数组能够使编程更加高效,下面我们就来认识一下其他数据结构,通过这些数据结构也可以操作内存的读写。
1)栈
栈(stack)是一种很重要的数据结构,栈采用LIFO(Last In First Out)即 后入先出 的方式对内存进行操作。它就像一个大的收纳箱,你可以往里面放相同类型的东西,比如书,最先放进收纳箱的书在最下面,最后放进收纳箱的书在最上面,如果你想拿书的话,必须从最上面开始取,否则是无法取出最下面的书籍的。
栈的数据结构就是这样,你把书籍压入收纳箱的操作叫做 压入(push),你把书籍从收纳箱取出的操作叫做弹出(pop),它的模型图大概是这样。
栈的数据结构:
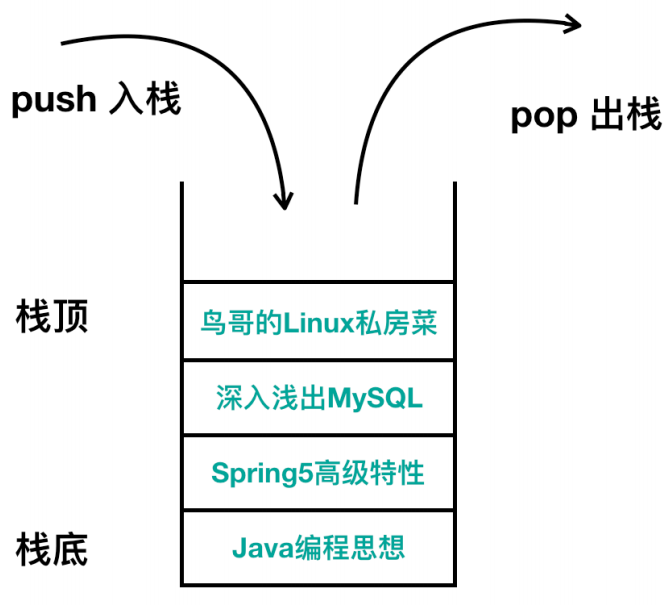
入栈相当于是增加操作,出栈相当于是删除操作,只不过叫法不一样。栈和内存不同,它不需要指定元素的地址。它的大概使用如下:
// 压入数据2
Push(123);
Push(456);
Push(456);
// 弹出数据
j = Pop();
k = Pop();
l = Pop();在栈中,LIFO方式表示栈的数组中所保存的最后面的数据(Last In)会被最先读取出来(First On)。
运行时栈的变化:
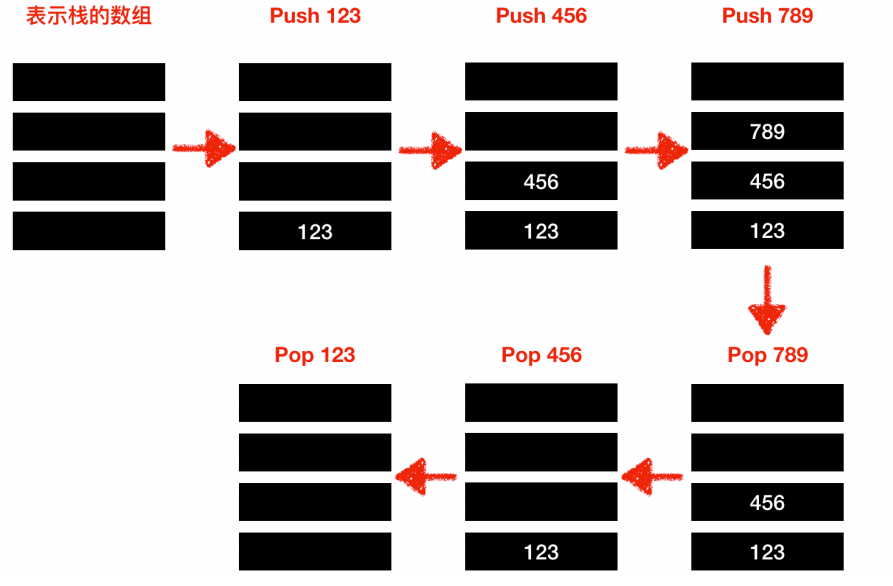
2)队列
队列和栈很相似但又不同,相同之处在于队列也不需要指定元素的地址,不同之处在于队列是一种先入先出(First In First Out)的数据结构。队列在我们生活中的使用很像是我们去景区排队买票一样,第一个排队的人最先买到票,以此类推,俗话说:先到先得。
它的使用如下:
//往队列中写入数据
EnQueue(123);
EnQueue(456);
EnQueue(789);
// 从队列中读出数据
m = DeQueue();
n = DeQueue();
o = DeQueue();向队列中写入数据称为 EnQueue()入列,从队列中读出数据称为 DeQueue()。
队列的数据结构:
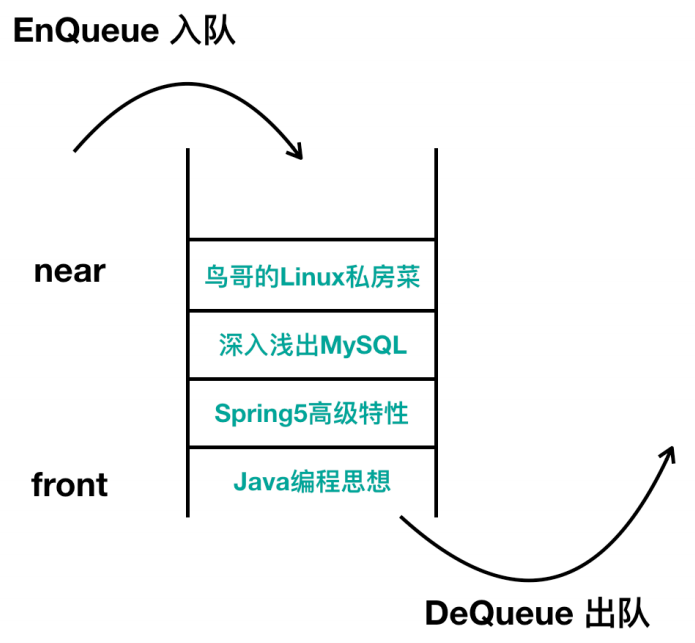
与栈相对,FIFO的方式表示队列中最先所保存的数据会优先被读取出来。
运行时队列的变化:
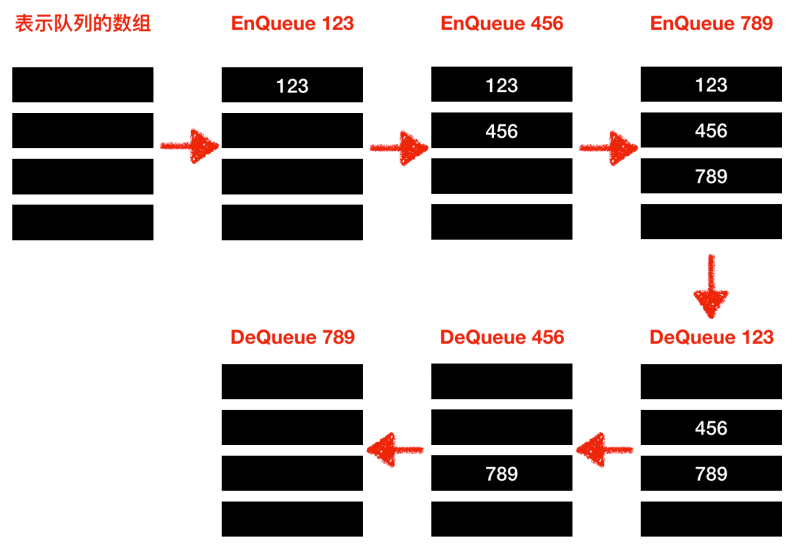
队列的实现一般有两种:顺序队列和循环队列,我们上面的事例使用的是顺序队列,那么下面我们看一下循环队列的实现方式。
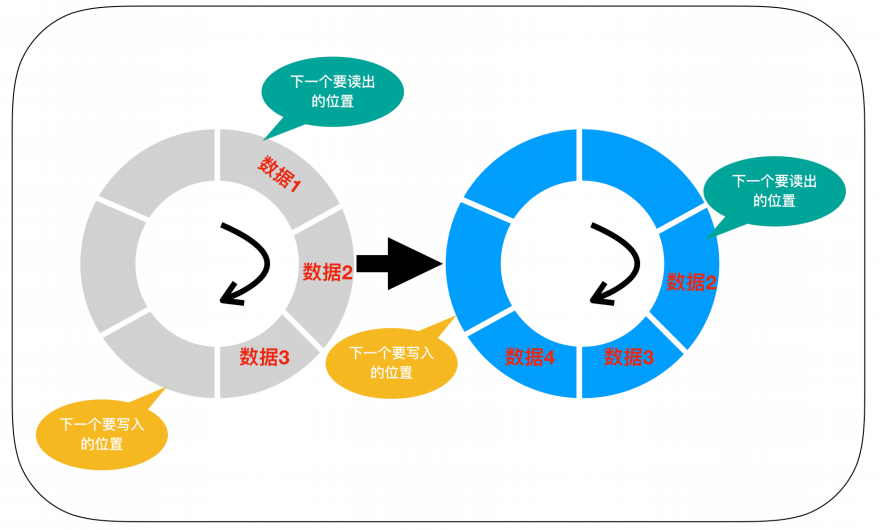
环形缓冲区:
循环队列一般是以 环状缓冲区(ring buffer)的方式实现的,它是一种用于表示一个固定尺寸、头尾相连的缓冲区的数据结构,适合缓存数据流。假如我们要用6个元素的数组来实现一个环形缓冲区,这时可以从起始位置开始有序的存储数据,然后再按照存储时的顺序把数据读出。在数组的末尾写入数据后,后一个数据就会从缓冲区的头开始写。这样,数组的末尾和开头就连接了起来。
环形缓冲区模型:
3)链表
下面我们来介绍一下链表和二叉树,它们都是可以不用考虑索引的顺序就可以对元素进行读写的方式。通过使用链表,可以高效的对数据元素进行 添加 和 删除 操作。而通过使用二叉树,则可以更高效的对数据进行检索。
在实现数组的基础上,除了数据的值之外,通过为其附带上下一个元素的索引,即可实现 链表。数据的值和下一个元素的地址(索引)就构成了一个链表元素,如下所示:

链表的数据结构:
对链表的添加和删除都是非常高效的,我们来叙述一下这个添加和删除的过程,假如我们要删除地址为p[2]的元素,链表该如何变化呢?

链表的删除:
我们可以看到,删除地址为p[2]的元素后,直接将链表剔除,并把p[2]前一个位置的元素p[1]的指针域指向p[2]下一个链表元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1712
1712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











