









 本文介绍如何使用sklearn库将非线性回归模型转换为线性模型进行训练,通过实例展示了从数据预处理到模型训练的全过程,并对比了一元线性模型与多项式回归模型的拟合效果。
本文介绍如何使用sklearn库将非线性回归模型转换为线性模型进行训练,通过实例展示了从数据预处理到模型训练的全过程,并对比了一元线性模型与多项式回归模型的拟合效果。
sklearn实现非线性回归模型
前言: sklearn实现非线性回归模型的本质是通过线性模型实现非线性模型,如何实现呢?sklearn就是先将非线性模型转换为线性模型,再利用线性模型的算法进行训练模型。
一、线性模型解决非线性模型的思想
1、样本数据如下
| x | y |
|---|---|
| 1 | 45000 |
| 2 | 50000 |
| 3 | 60000 |
| 4 | 80000 |
| 5 | 110000 |
| 6 | 150000 |
| 7 | 200000 |
| 8 | 300000 |
| 9 | 500000 |
| 10 | 1000000 |
2、假设样本数据符合线性模型 y = a0 + a1x,则可以直接利用sklearn的线性回归模型方法训练该模型
3、但是假设样本数据符合非线性模型 y = a0x0 + a1x1 + a2x2 + a3x3 ,(其中x0=1)那么我们如何将该非线性模型转为线性模型呢?sklearn的解释思路是从样本数据中的自变量下手的,它首先通过计算将样本数据修改为下表
x0 x1 x2 x3 y
[[ 1. 1. 1. 1.]
[ 1. 2. 4. 8.]
[ 1. 3. 9. 27.]
[ 1. 4. 16. 64.]
[ 1. 5. 25. 125.]
[ 1. 6. 36. 216.]
[ 1. 7. 49. 343.]
[ 1. 8. 64. 512.]
[ 1. 9. 81. 729.]
[ 1. 10. 100. 1000.]]
4、根据上面的样本数据,也就把 y = a0x0 + a1x1 + a2x2 + a3x3 ^非线性回归模型转换为了y = a0x0 + a01x1 + a2x2 + a3x3的线性回归模型了,这样就可以利用sklearn的线性回归模型算法进行训练非线性回归模型了
二、 具体实现代码如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 读取数据
data = np.genfromtxt('job.csv', delimiter=',')
x_data = data[1:, 1]
y_data = data[1:, 2]
# 一维数据通过增加维度转为二维数据
x_2data = x_data[:, np.newaxis]
y_2data = data[1:, 2, np.newaxis]
# 训练一元线性模型
model = LinearRegression()
model.fit(x_2data, y_2data)
plt.plot(x_2data, y_2data, 'b.')
plt.plot(x_2data, model.predict(x_2data), 'r')
# 定义多项式回归:其本质是将变量x,根据degree的值转换为相应的多项式(非线性回归),eg: degree=3,则回归模型
# 变为 y = theta0 + theta1 * x + theta2 * x^2 + theta3 * x^3
poly_reg = PolynomialFeatures(degree=3)
# 特征处理
x_ploy = poly_reg.fit_transform(x_2data) # 这个方法实质是把非线性的模型转为线性模型进行处理,
# 处理方法就是把多项式每项的样本数据根据幂次数计算出相应的样本值(详细理解可以参考我的博文:https://blog.youkuaiyun.com/qq_34720818/article/details/103349452)
# 训练线性模型(其本质是非线性模型,是由非线性模型转换而来)
lin_reg_model = LinearRegression()
lin_reg_model.fit(x_ploy, y_2data)
plt.plot(x_2data, y_2data, 'b.')
plt.plot(x_2data, lin_reg_model.predict(x_ploy), 'r')
plt.show()
三、实现结果
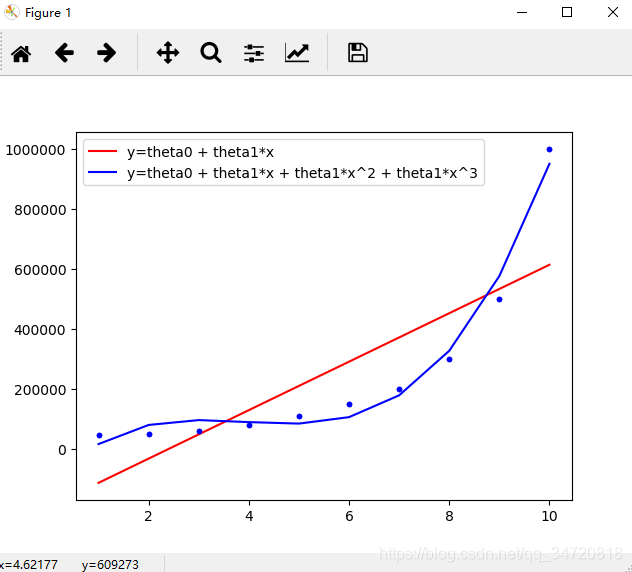
可以很明显的看错曲线比直线的拟合效果好
四、数据下载
链接:https://pan.baidu.com/s/1YoUUJkbSGQsyy50m-LQJYw
提取码:rwek


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











