







 本文详细介绍了如何在RabbitMQ中配置Federation,包括联邦交换器(Federated Exchange)和联邦队列(Federated Queue)。Federation插件允许不同Broker节点间的消息传递,无需建立集群。通过配置联邦交换器和联邦队列,实现了消息的路由和负载均衡,确保在节点间的消息流动和消费。
本文详细介绍了如何在RabbitMQ中配置Federation,包括联邦交换器(Federated Exchange)和联邦队列(Federated Queue)。Federation插件允许不同Broker节点间的消息传递,无需建立集群。通过配置联邦交换器和联邦队列,实现了消息的路由和负载均衡,确保在节点间的消息流动和消费。
Federation插件可以使RabbitMq不同的Broker节点进行消息传递而不必建立集群,Federation插件能够运行在不同版本的RabbitMq上。
Federation插件可以让多个交换器或者队列建立联邦关系,联邦交换器或联邦队列接收上游(交换器或队列)的消息。联邦交换器将原本发送给上游交换器的信息路由到本地某个队列上,而联邦队列允许本地的消费者消费到上游队列的消息。
一、联邦交换器(Federated Exchange)
联邦交换器链接到上游交换器,发送到上游交换器的消息被路由到联邦交换器上,就好像消息被直接发送到联邦交换器一样。下图展示了一个联邦交换器与其他两个Broker节点上上游交换器建立了联邦关系。
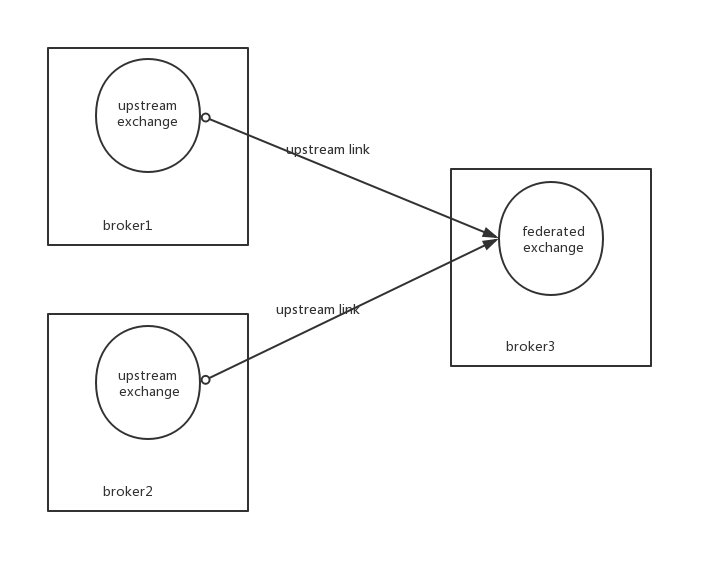
Federated Exchange实现:
这里我在单机上启动了两个RabbitMq节点,rabbitmq1@hadoop和rabbitmq2@hadoop。

(1)开启Federation插件功能
rabbitmq1@hadoop和rabbitmq2@hadoop两个节点都需要开启,如果是多机单节点部署可以去掉-n选项。
开启Federation插件功能之后,可以在web管理界面看到如下显示:
(2)在rabbitmq2@hadoop上定义一个upstream

指定rabbitmq1@hadoop为上游节点。也可以通过web管理界面添加:
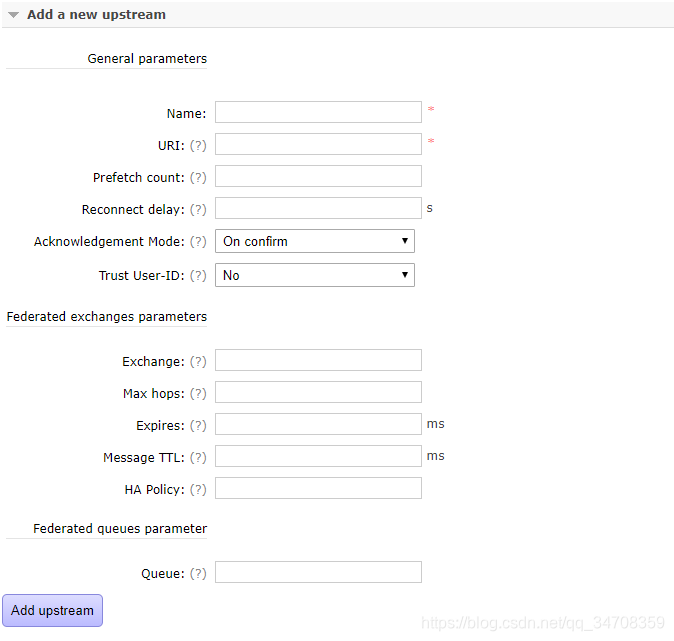
各项参数如下所述:
- Name:upstream的名称。
- URI(uri):upstram的amqp连接。
- Prefetch count(prefetch_count):Federation内部缓存的消息条数,即在接收到上游消息之后且在发送到下游之前缓存的消息条数。
- Reconnect delay(reconnect-delay):Federation link连接断开后,需要等待多少秒开始连接。
- Acknowledgement Mode(ack-mode):Federation link消息确认方式,一共有三种,on-confirm表示在接收到下游的确认消息之后再向上游发送消息确认;on-publish表示消息发送到下游后,再向上游发送消息确认;no-ack表示不发送消息确认。默认使用on-confirm。
- Trust User-ID(trust-user-id):设置Federation是否使用Validated User-ID这个功能,如果设置为false,表示不使用Validated User-ID功能,Federation会忽略消息的user-id这个属性,如果设置为true,则Federation只会转发user_id为上游任意有效的用户的消息。
只适用Federated Exchange的属性:
- Exchange(exchange):指定上游交换器(upstream exchange),默认与federated exchange同名。
- Max hops(max-hops):指定消息在丢弃前在federation link中流转的次数,默认为1。
- Expires(expires):设置federation link断开后,上游队列(upstream queue)的过期时间,相当于普通队列的x-expires属性,默认为none,表示不删除队列。这个属性可以预防因federation link断开,生产者推送到上游队列的消息无法被转发消费而造成上游队列消息堆积的现象。
- Message TTL(message-ttl):设置上游队列(upstram queue)中消息的过期时间,相当于x-message-ttl属性,默认为none表示不过期。
- HA Policy(ha-policy):为上游队列(upstream queue)设置,相当于普通队列的x-ha-policy属性。
只适用Federated Queue的属性:
- Queue(queue):设置上游队列(upstream queue)的名称,默认与federated queue同名。
upstream创建完如下图所示:
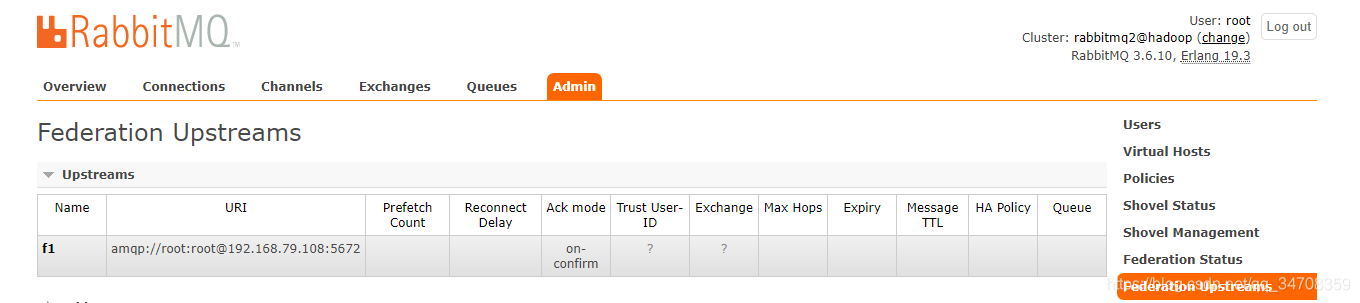
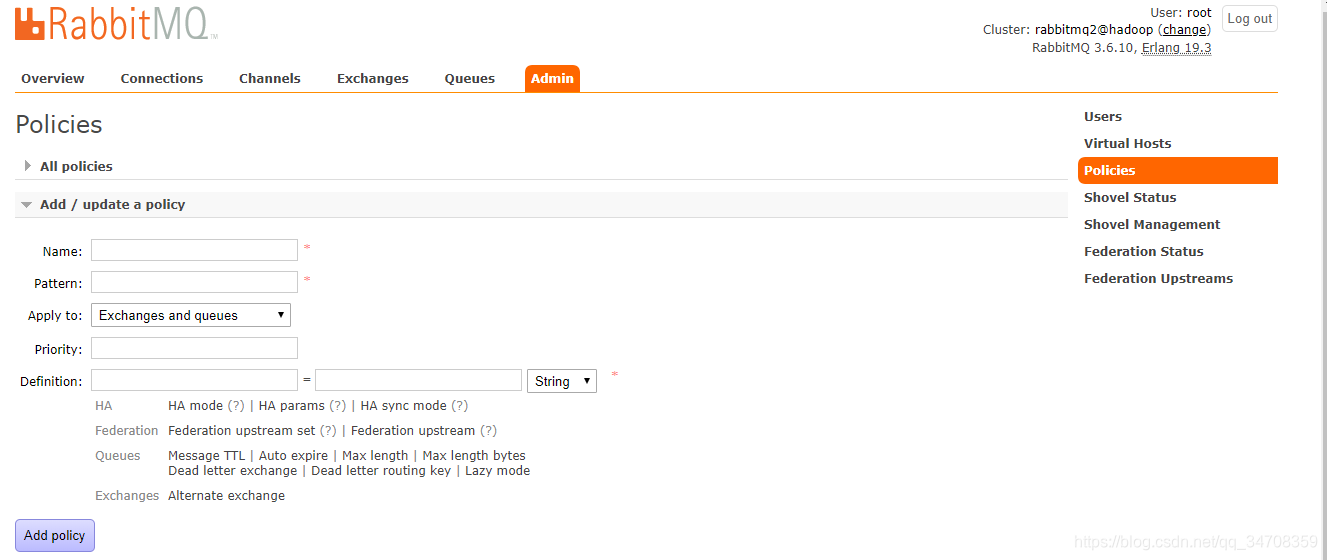
(3)在rabbitmq2hadoop上定义一个policy,用于匹配交换器,并使用第二步创建的upstream

指定所有以fede_开头的交换器为federated exchange。也可以通过web管理界面添加:
policy创建完成如下图所示:
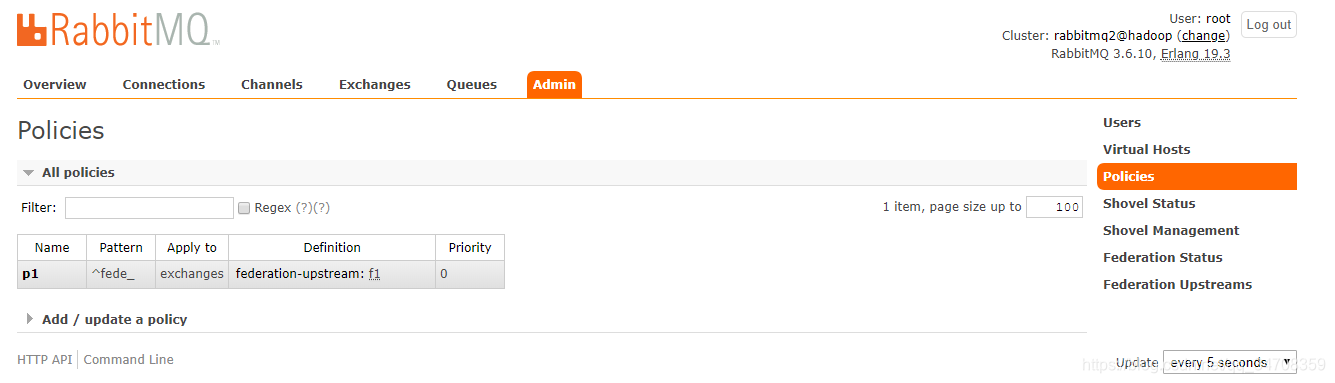
(4)在rabbitmq2@hadoop上创建fede_exchange,匹配第三步创建的policy
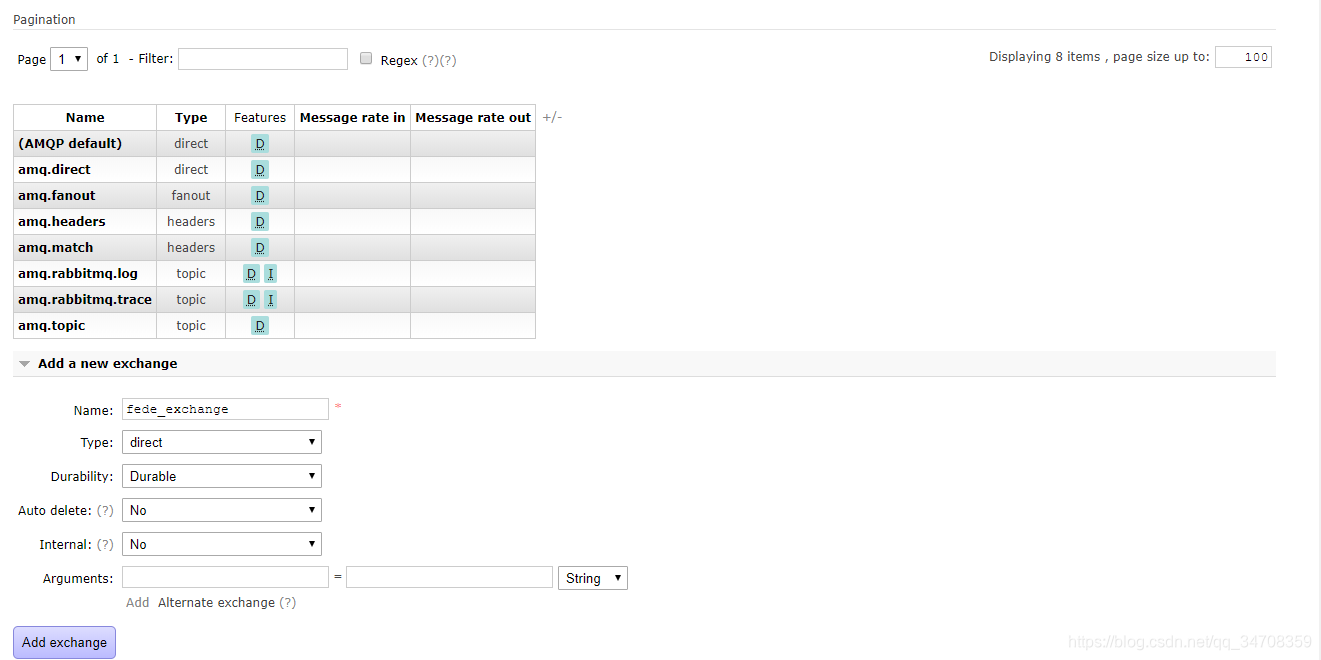
fede_exchange创建完成后,可以看到fede_exchange匹配上了p1,
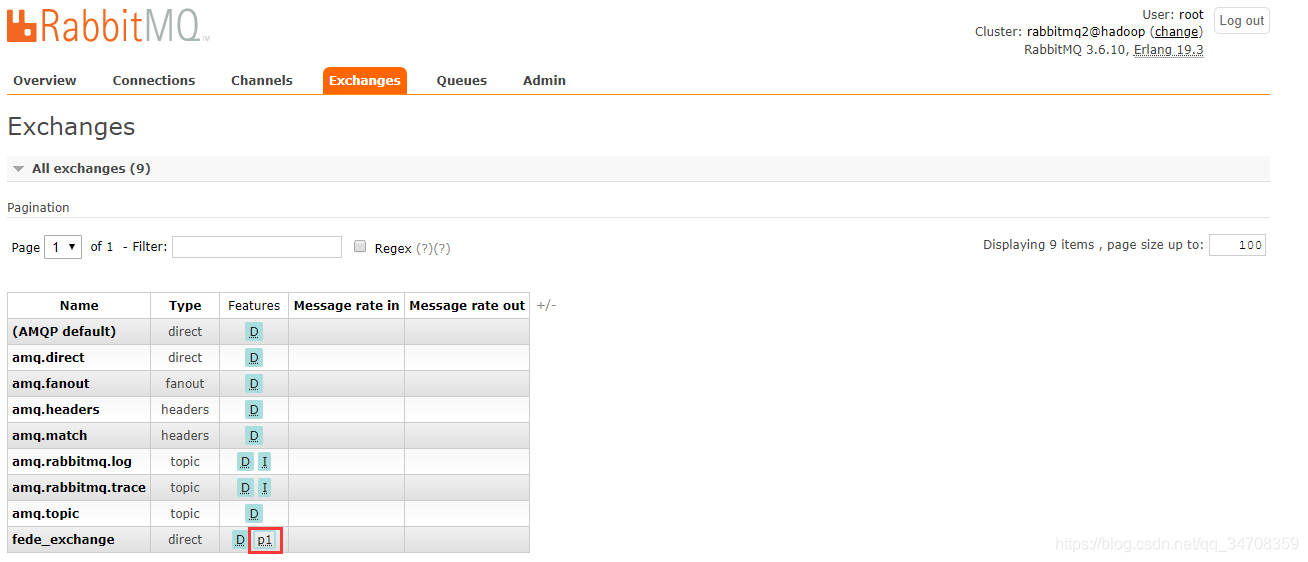
并且与rabbitmq1@hadoop建立了一条federation link。
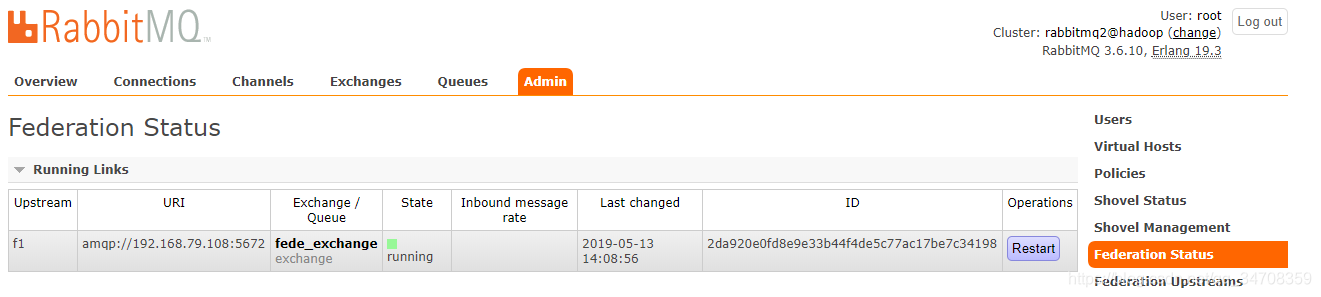
而在rabbitmq1@hadoop上,将会自动创建同名的fede_exchange上游交换器,federation: fede_exchange -> rabbitmq2@hadoop B内部交换器和federation: fede_exchange -> rabbitmq2@hadoop上游队列。


至此,Federated Exchange创建完毕。消息在federation link中的流转如下图所示:
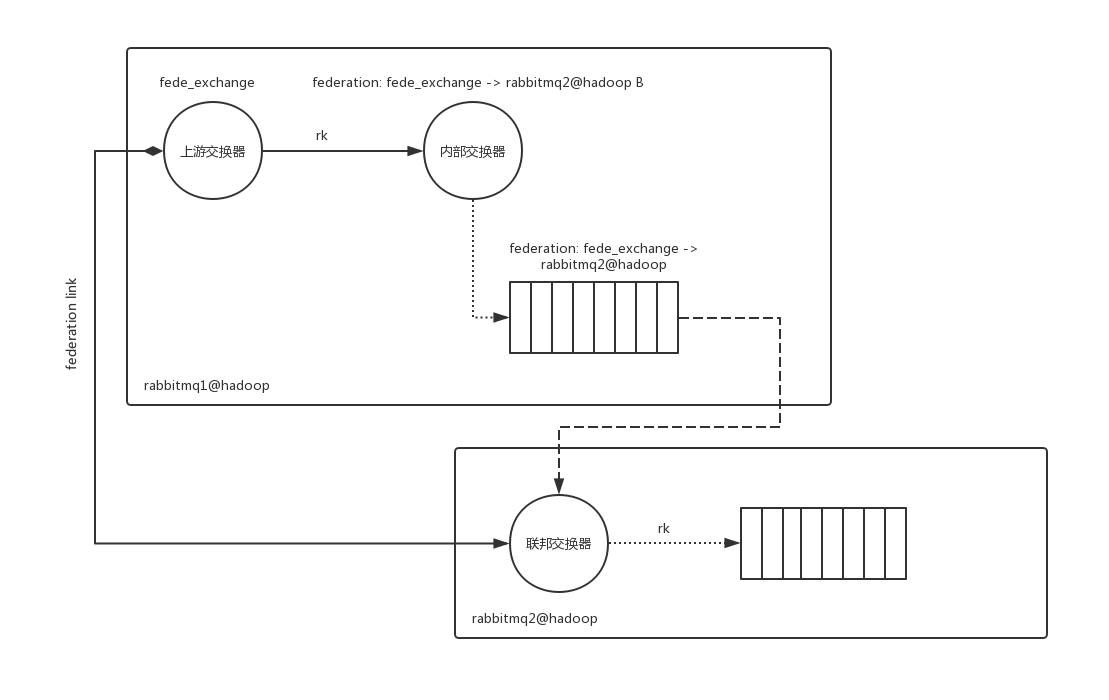
经过federation link转发的消息会带有特殊的headers属性标记。

二、联邦队列(Federated Queue)
除了联邦交换器,RabbitMq还支持联邦队列。联邦队列可以在其他节点或集群之间为单个节点提供负载均衡。联邦队列可以连接多个上游队列,并夺取小心供本地消费者消费。下图展示了两个节点之间联邦队列与非联邦队列。
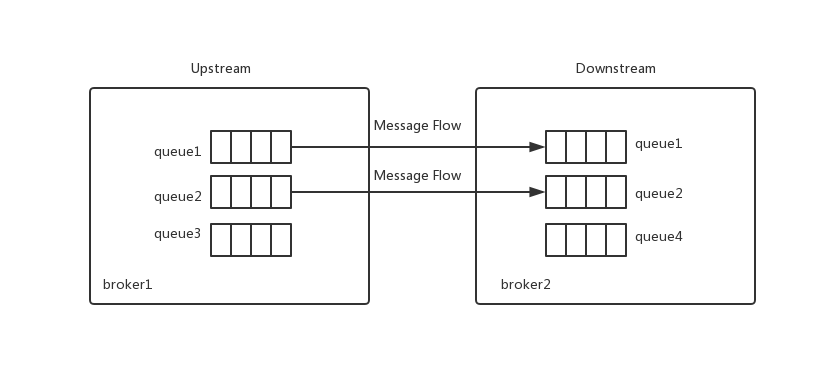
queue1和queue2是联邦队列,queue3和queue4是非联邦队列。消费者既可以消费broker1中队列的消息,也可以消费broker2中的消息。如果broker1上的消费者来不及消费队列中的消息,那么broker2上的消费者可以为其分担消费,从而达到负载均衡的目的。与联邦交换器不同的是,联邦队列中消息可以在上游队列和下游队列中来回流转。
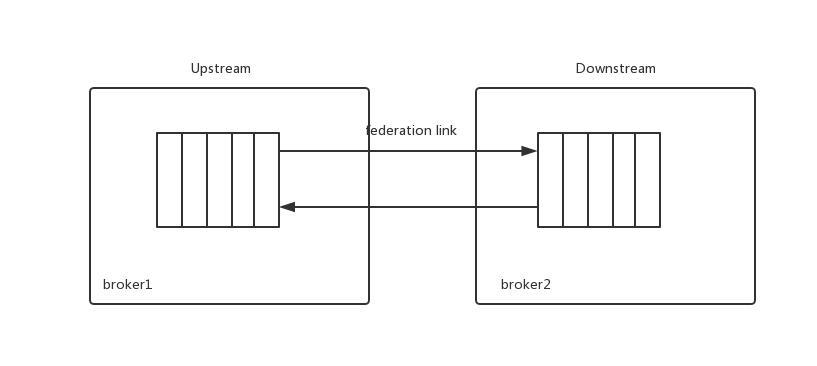
队列中的消息不仅可以被消费,还可以被转发到具有多余消费能力的一方,如果这种能力在broker1和broker2中来回切换,那么消费将会在broker1和broker2中来回流转。
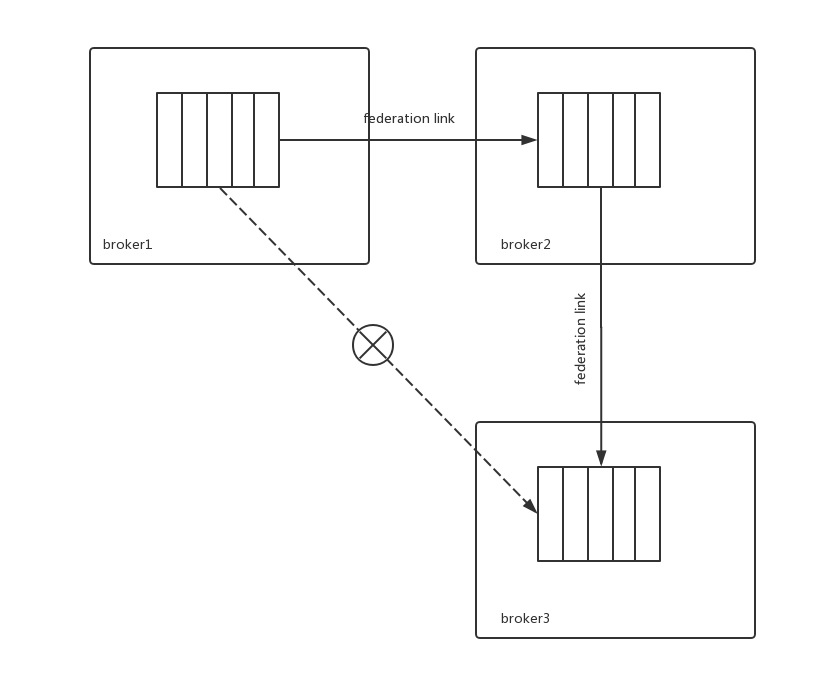
联邦队列不具有传递性。如下图,broker作为broker2的upstream,broker2作为broker3的upstream。如果broker1中有消费堆积,broker3上的消费者都不会消费到broker1上的消息。
Federated Queue实现:
与Federated Exchange实现不同的是在第三步policy的定义上,以下是Federated Queue的policy定义。

policy创建完成后显示如下:

之后定义fede_queue匹配p2。

同样在rabbitmq1@hadoop会创建同名的queue。
至此Federated Queue创建完毕。

















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









