







1. 需求背景
1.1. 概述
随着数据科技的进步,数据分析师早已不再满足于传统的T+1式报表或需要提前设置好维度与指标的OLAP查询。数据分析师更希望使用可以支持任意指标、任意维度并秒级给出反馈的大数据Ad-hoc查询系统。这对大数据技术来说是一项非常大的挑战,传统的大数据查询引擎根本无法做到这一点。由俄罗斯的Yandex公司开源的ClickHouse脱颖而出。在第一届易观OLAP大赛中,在用户行为分析转化漏斗场景里,ClickHouse比Spark快了近10倍。在随后几年的大赛中,面对各类新的大数据引擎的挑战,ClickHouse一直稳稳地坐在冠军宝座上。同时在各种OLAP查询引擎评测中,ClickHouse单表查询的速度力压现在流行的各大数据库引擎,尤其是Ad-hoc查询速度一直遥遥领先,因此被国内大量用户和爱好者广泛用在即席查询场景当中。
ClickHouse的性能测试:https://clickhouse.tech/benchmark/dbms/
1.2. 用户轨迹行为分析
架构目标:
- 海量数据
- 实时导入
- 实时查询
- 多维聚合分析
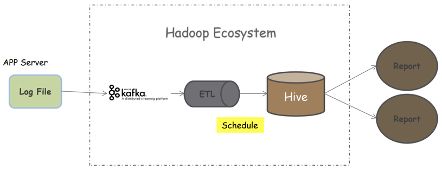
1.3. 架构分析
- 数据的实效性:中间过程经过Kafka、ETL、调度处理,报表的实效性不理想
- 即席分析性能:Hive存储是hdfs文件系统,查询效率不高,不适合即席查询
- 涉及Hadoop组件多:涉及Flume、Kafka、HDFS等等,数据冗余过多,同时需要深厚的知识储备
- 数据链路长:数据链路处理流程长,繁琐容错也不好
1.4. 美好愿望

2. OLAP详解
OLTP + OLAP: T:transaction 事务处理 侧重于增删改 A : analysis 分析 Select大批量数据的聚合查询事务处理作用:保证数据的一致性,如果涉及到事务操作,这个操作的执行效率必然不高
OLAP + OLTP =====> 同时满足,很难涉及
MySQL: insert update delete Hive ClickHouse: Select 查询分析的高效
读模式 +
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7226
7226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









